In questo post del blog, analizzeremo 6 diversi scenari di errore nei sistemi di database di produzione, che vanno dai problemi del server singolo ai piani di failover di più datacenter. Ti guideremo attraverso le procedure di ripristino e failover per il rispettivo scenario. Si spera che questo ti dia una buona comprensione dei rischi che potresti incontrare e delle cose da considerare durante la progettazione della tua infrastruttura.
Schema del database danneggiato
Iniziamo con l'installazione a nodo singolo:una configurazione del database nella forma più semplice. Facile da implementare, al minor costo. In questo scenario, si eseguono più applicazioni sull'unico server in cui ciascuno degli schemi di database appartiene alla diversa applicazione. L'approccio per il ripristino di un singolo schema dipende da diversi fattori.
- Ho dei backup?
- Ho un backup e quanto velocemente posso ripristinarlo?
- Che tipo di motore di archiviazione è in uso?
- Ho un backup compatibile con PITR (ripristino point in time)?
Il danneggiamento dei dati può essere identificato da mysqlcheck.
mysqlcheck -uroot -p <DATABASE>Sostituisci DATABASE con il nome del database e sostituisci TABLE con il nome della tabella che vuoi controllare:
mysqlcheck -uroot -p <DATABASE> <TABLE>Mysqlcheck controlla il database e le tabelle specificati. Se una tabella supera il controllo, mysqlcheck visualizza OK per la tabella. Nell'esempio seguente, possiamo vedere che la tabella stipendi richiede il recupero.
employees.departments OK
employees.dept_emp OK
employees.dept_manager OK
employees.employees OK
Employees.salaries
Warning : Tablespace is missing for table 'employees/salaries'
Error : Table 'employees.salaries' doesn't exist in engine
status : Operation failed
employees.titles OKPer un'installazione a nodo singolo senza server DR aggiuntivi, l'approccio principale sarebbe ripristinare i dati dal backup. Ma questa non è l'unica cosa che devi considerare. La presenza di più schemi di database nella stessa istanza causa un problema quando è necessario arrestare il server per ripristinare i dati. Un'altra domanda è se puoi permetterti di ripristinare tutti i tuoi database all'ultimo backup. Nella maggior parte dei casi, ciò non sarebbe possibile.
Ci sono alcune eccezioni qui. È possibile ripristinare una singola tabella o database dall'ultimo backup quando non è necessario il ripristino temporizzato. Tale processo è più complicato. Se hai mysqldump, puoi estrarre il tuo database da esso. Se esegui backup binari con xtradbackup o mariabackup e hai abilitato la tabella per file, è possibile.
Ecco come verificare se hai un'opzione tabella per file abilitata.
mysql> SET GLOBAL innodb_file_per_table=1; Con innodb_file_per_table abilitato, puoi archiviare le tabelle InnoDB in un file .ibd tbl_name. A differenza del motore di archiviazione MyISAM, con i suoi file tbl_name .MYD e tbl_name .MYI separati per gli indici e i dati, InnoDB memorizza i dati e gli indici insieme in un unico file .ibd. Per controllare il tuo motore di archiviazione devi eseguire:
mysql> select table_name,engine from information_schema.tables where table_name='table_name' and table_schema='database_name';o direttamente dalla console:
[example@sqldat.com ~]# mysql -u<username> -p -D<database_name> -e "show table status\G"
Enter password:
*************************** 1. row ***************************
Name: test1
Engine: InnoDB
Version: 10
Row_format: Dynamic
Rows: 12
Avg_row_length: 1365
Data_length: 16384
Max_data_length: 0
Index_length: 0
Data_free: 0
Auto_increment: NULL
Create_time: 2018-05-24 17:54:33
Update_time: NULL
Check_time: NULL
Collation: latin1_swedish_ci
Checksum: NULL
Create_options:
Comment: Per ripristinare le tabelle da xtradbackup, è necessario eseguire un processo di esportazione. Il backup deve essere preparato prima che possa essere ripristinato. L'esportazione viene eseguita nella fase di preparazione. Una volta creato un backup completo, esegui la procedura di preparazione standard con il flag aggiuntivo --export :
innobackupex --apply-log --export /u01/backupQuesto creerà file di esportazione aggiuntivi che utilizzerai in seguito nella fase di importazione. Per importare una tabella su un altro server, crea prima una nuova tabella con la stessa struttura di quella che verrà importata su quel server:
mysql> CREATE TABLE corrupted_table (...) ENGINE=InnoDB;scarta il tablespace:
mysql> ALTER TABLE mydatabase.mytable DISCARD TABLESPACE;Quindi copia i file mytable.ibd e mytable.exp nella home del database e importa il suo tablespace:
mysql> ALTER TABLE mydatabase.mytable IMPORT TABLESPACE;Tuttavia, per farlo in modo più controllato, la raccomandazione sarebbe quella di ripristinare un backup del database in un'altra istanza/server e copiare ciò che è necessario sul sistema principale. Per fare ciò, è necessario eseguire l'installazione dell'istanza mysql. Questa operazione può essere eseguita sulla stessa macchina, ma richiede uno sforzo maggiore per la configurazione in modo che entrambe le istanze possano essere eseguite sulla stessa macchina, ad esempio, ciò richiederebbe impostazioni di comunicazione diverse.
È possibile combinare sia il ripristino dell'attività che l'installazione utilizzando ClusterControl.
ClusterControl ti guiderà attraverso i backup disponibili in locale o nel cloud, ti consentirà di scegliere l'ora esatta per un ripristino o la posizione precisa del registro e, se necessario, installa una nuova istanza di database.
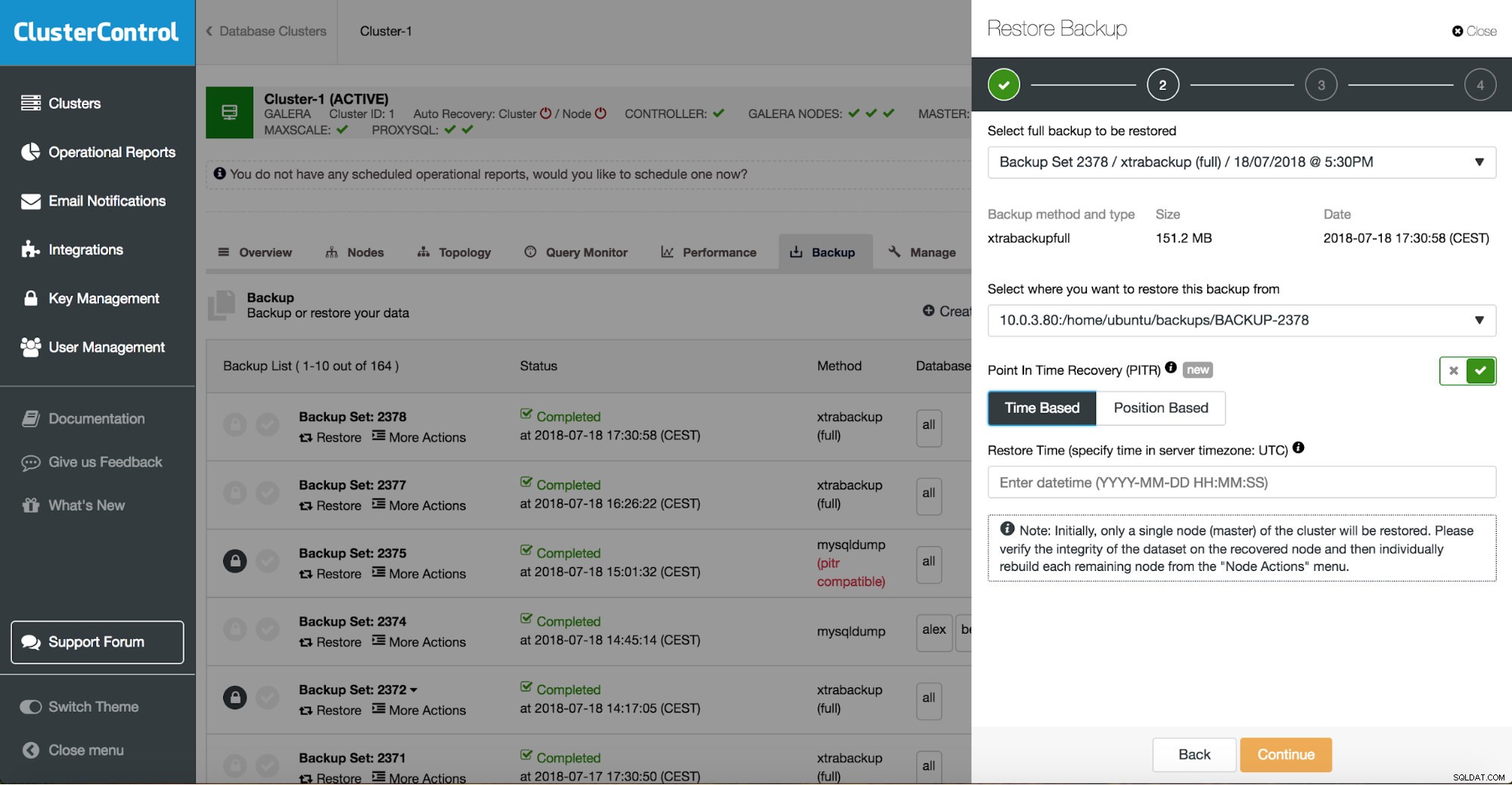 Recupero punto nel tempo di ClusterControl
Recupero punto nel tempo di ClusterControl 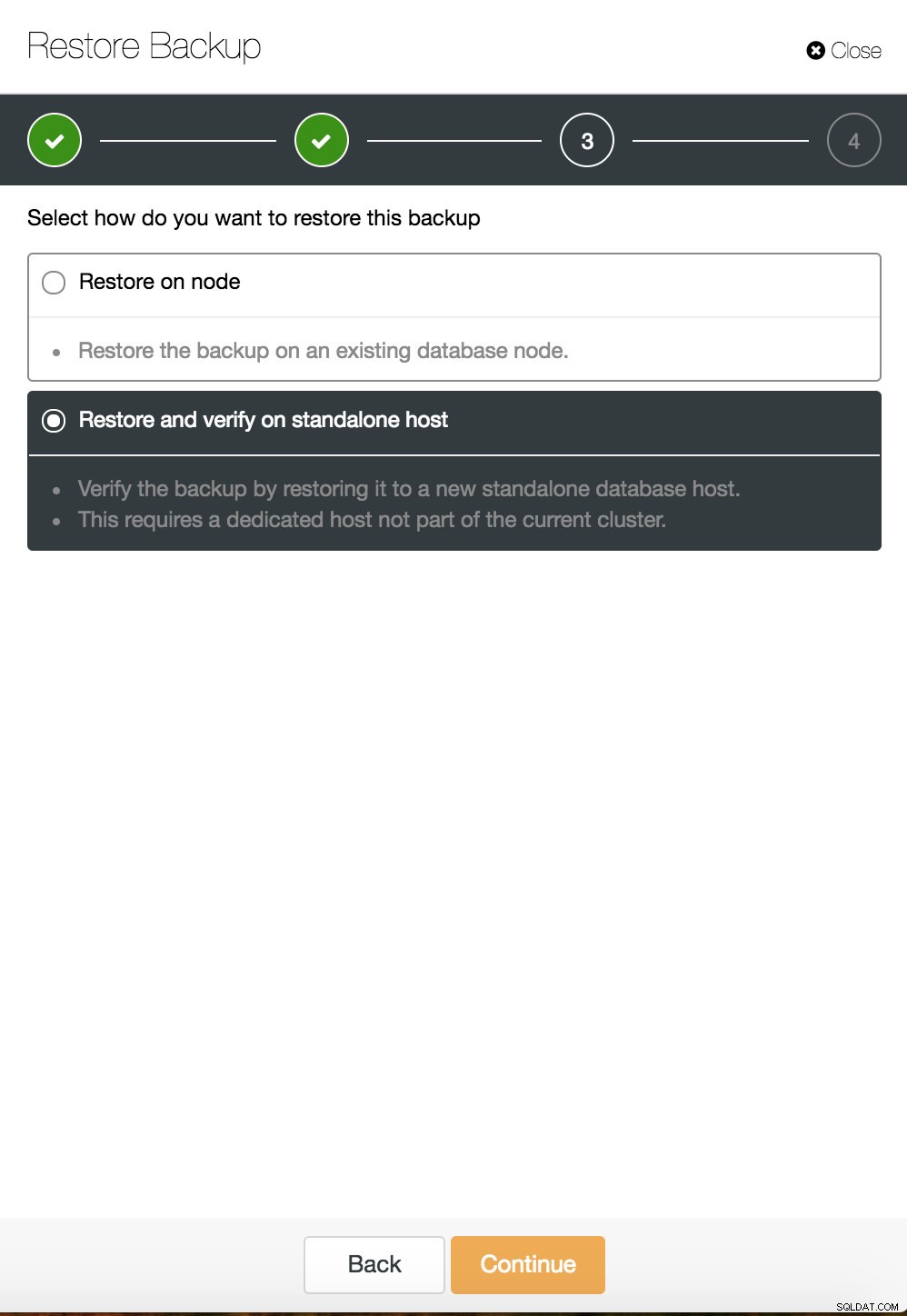 ClusterControl ripristina e verifica su un host autonomo
ClusterControl ripristina e verifica su un host autonomo 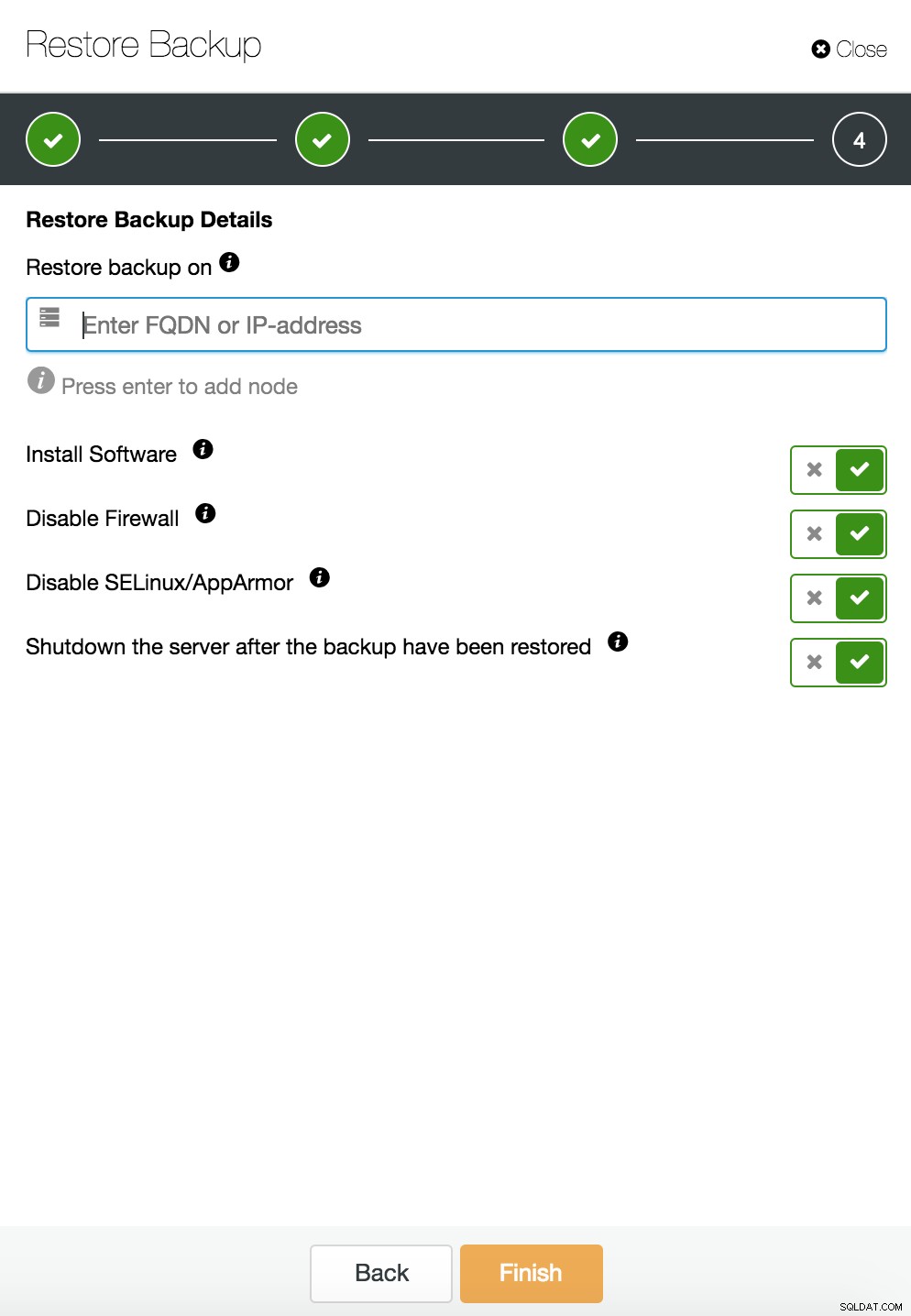 CusterControl ripristina e verifica su un host autonomo. Opzioni di installazione.
CusterControl ripristina e verifica su un host autonomo. Opzioni di installazione. Puoi trovare maggiori informazioni sul recupero dei dati nel blog Il mio database MySQL è danneggiato... Cosa faccio adesso?
Istanza database danneggiata sul server dedicato
I difetti nella piattaforma sottostante sono spesso la causa del danneggiamento del database. La tua istanza MySQL si basa su una serie di cose per archiviare e recuperare i dati:sottosistema del disco, controller, canali di comunicazione, driver e firmware. Un arresto anomalo può interessare parti dei tuoi dati, file binari mysql o persino file di backup che memorizzi sul sistema. Per separare diverse applicazioni, puoi posizionarle su server dedicati.
Schemi applicativi diversi su sistemi separati sono una buona idea se te li puoi permettere. Si può dire che si tratta di uno spreco di risorse, ma c'è la possibilità che l'impatto sul business sia minore se solo una di esse si riduce. Ma anche in questo caso, è necessario proteggere il database dalla perdita di dati. Archiviare il backup sullo stesso server non è una cattiva idea se ne hai una copia da qualche altra parte. Al giorno d'oggi, l'archiviazione su cloud è un'ottima alternativa al backup su nastro.
ClusterControl consente di mantenere una copia del backup nel cloud. Supporta il caricamento sui 3 principali fornitori di servizi cloud:Amazon AWS, Google Cloud e Microsoft Azure.
Una volta ripristinato il backup completo, potresti voler ripristinarlo in un determinato momento. Il ripristino point-in-time porterà il server aggiornato a un'ora più recente rispetto a quando è stato eseguito il backup completo. Per fare ciò, devi avere i log binari abilitati. Puoi controllare i log binari disponibili con:
mysql> SHOW BINARY LOGS;E il file di registro corrente con:
SHOW MASTER STATUS;Quindi puoi acquisire dati incrementali passando i log binari nel file sql. Le operazioni mancanti possono essere quindi rieseguite.
mysqlbinlog --start-position='14231131' --verbose /var/lib/mysql/binlog.000010 /var/lib/mysql/binlog.000011 /var/lib/mysql/binlog.000012 /var/lib/mysql/binlog.000013 /var/lib/mysql/binlog.000015 > binlog.outLo stesso può essere fatto in ClusterControl.
 Backup cloud di ClusterControl
Backup cloud di ClusterControl 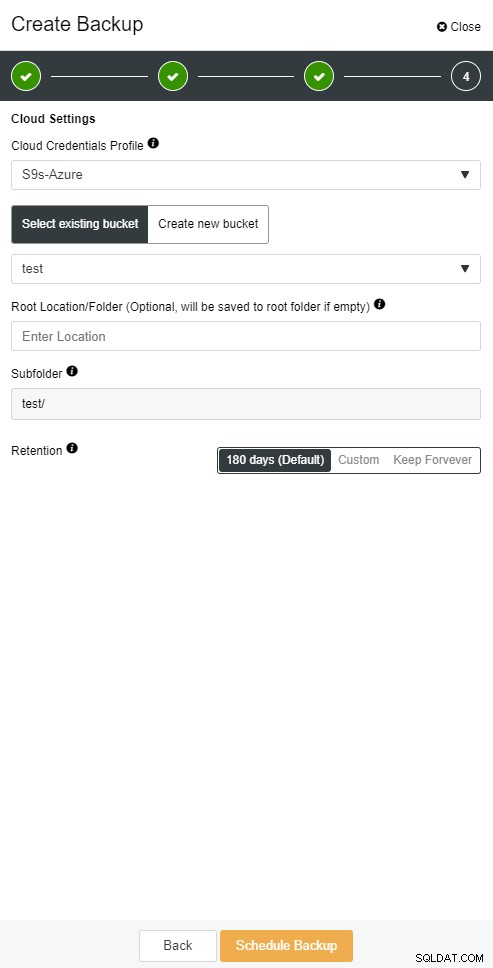 Backup cloud di ClusterControl
Backup cloud di ClusterControl Lo slave del database non funziona
Ok, quindi hai il tuo database in esecuzione su un server dedicato. Hai creato una pianificazione di backup sofisticata con una combinazione di backup completi e incrementali, li hai caricati sul cloud e hai archiviato l'ultimo backup su dischi locali per un ripristino rapido. Hai diverse politiche di conservazione dei backup:più brevi per i backup archiviati su driver del disco locali ed estese per i backup su cloud.
Sembra che tu sia ben preparato per uno scenario di disastro. Ma quando si tratta del tempo di ripristino, potrebbe non soddisfare le tue esigenze aziendali.
Hai bisogno di una rapida funzione di failover. Un server che sarà attivo e funzionante applicando i log binari dal master in cui avvengono le scritture. La replica master/slave avvia un nuovo capitolo nello scenario di failover. È un metodo rapido per riportare in vita la tua applicazione se il master non funziona.
Ma ci sono alcune cose da considerare nello scenario di failover. Uno è impostare uno slave di replica ritardato, in modo da poter reagire ai comandi fat finger che sono stati attivati sul server master. Un server slave può rimanere indietro rispetto al master di almeno un determinato periodo di tempo. Il ritardo predefinito è 0 secondi. Usa l'opzione MASTER_DELAY per CHANGE MASTER TO per impostare il ritardo su N secondi:
CHANGE MASTER TO MASTER_DELAY = N;Il secondo è abilitare il failover automatico. Esistono molte soluzioni di failover automatizzate sul mercato. È possibile impostare il failover automatico con strumenti a riga di comando come MHA, MRM, mysqlfailover o GUI Orchestrator e ClusterControl. Se impostato correttamente, può ridurre significativamente la tua interruzione.
ClusterControl supporta il failover automatizzato per le repliche MySQL, PostgreSQL e MongoDB, nonché le soluzioni cluster multi-master Galera e NDB.
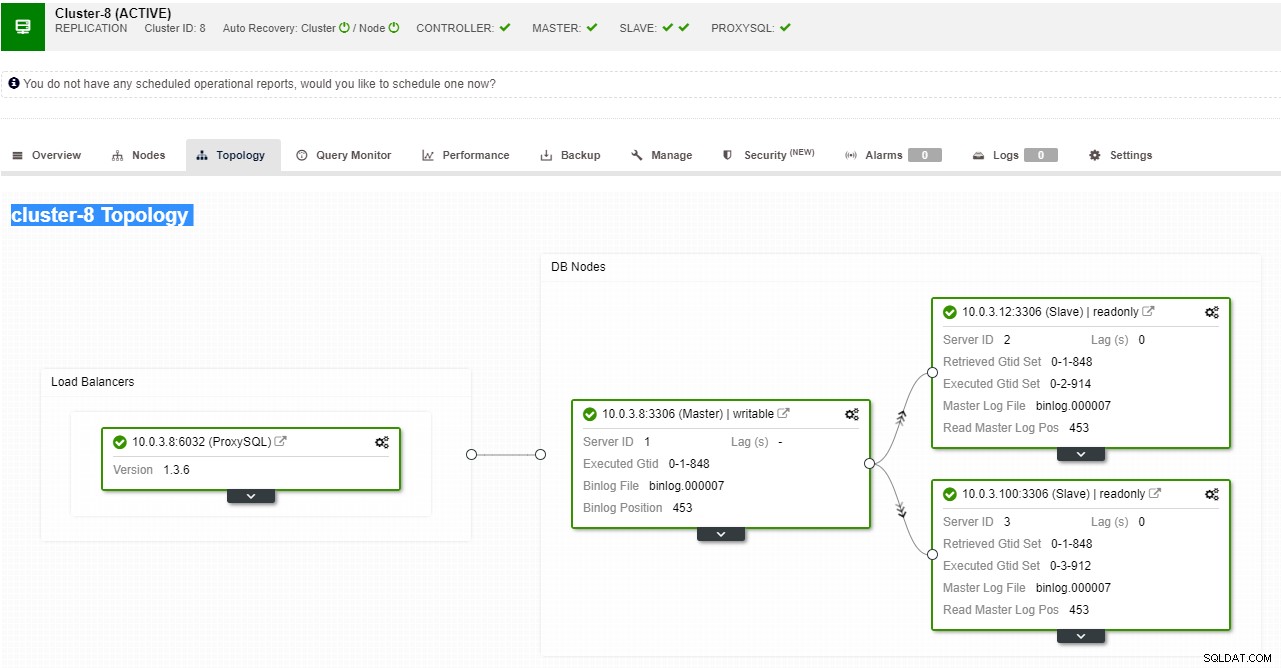 Vista della topologia della replica ClusterControl
Vista della topologia della replica ClusterControl Quando un nodo slave si arresta in modo anomalo e il server è in grave ritardo, potresti voler ricostruire il tuo server slave. Il processo di ricostruzione dello slave è simile al ripristino dal backup.
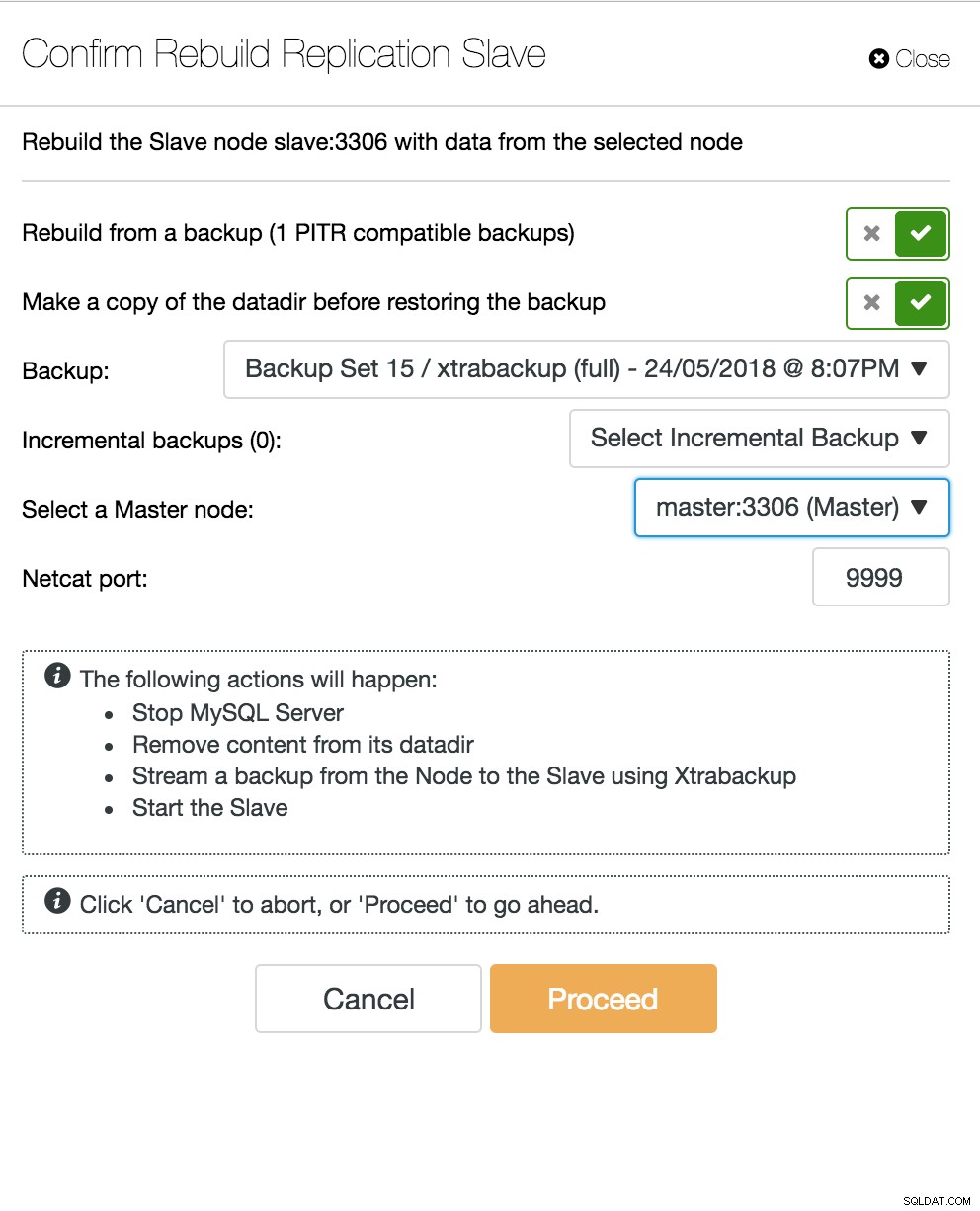 ClusterControl ricostruisce lo slave
ClusterControl ricostruisce lo slave Il server multimaster del database non funziona
Ora quando hai un server slave che funge da nodo DR e il tuo processo di failover è ben automatizzato e testato, la tua vita DBA diventa più confortevole. È vero, ma ci sono altri enigmi da risolvere. La potenza di calcolo non è gratuita e il tuo team aziendale potrebbe chiederti di utilizzare meglio il tuo hardware, potresti voler utilizzare il tuo server slave non solo come server passivo, ma anche per servire operazioni di scrittura.
Potresti quindi voler esaminare una soluzione di replica multi-master. Galera Cluster è diventata un'opzione mainstream per MySQL e MariaDB ad alta disponibilità. E sebbene sia ora noto come un sostituto credibile delle tradizionali architetture MySQL master-slave, non è un sostituto drop-in.
Il cluster Galera ha un'architettura nulla condivisa. Invece dei dischi condivisi, Galera utilizza la replica basata sulla certificazione con comunicazione di gruppo e ordinamento delle transazioni per ottenere la replica sincrona. Un cluster di database dovrebbe essere in grado di sopravvivere alla perdita di un nodo, sebbene ciò sia ottenuto in modi diversi. Nel caso di Galera, l'aspetto critico è il numero di nodi. Galera richiede un quorum per rimanere operativa. Un cluster a tre nodi può sopravvivere all'arresto anomalo di un nodo. Con più nodi nel tuo cluster, puoi sopravvivere a più errori.
Il processo di ripristino è automatizzato, quindi non è necessario eseguire operazioni di failover. Tuttavia, la buona pratica sarebbe quella di uccidere i nodi e vedere quanto velocemente puoi ripristinarli. Per rendere più efficiente questa operazione, puoi modificare la dimensione della cache di galera. Se la dimensione della cache di galera non è pianificata correttamente, il tuo prossimo nodo di avvio dovrà eseguire un backup completo invece di perdere solo i set di scrittura nella cache.
Lo scenario di failover è semplice come avviare l'istanza. Sulla base dei dati nella cache galera, il nodo di avvio eseguirà SST (ripristino dal backup completo) o IST (applica i set di scrittura mancanti). Tuttavia, questo è spesso legato all'intervento umano. Se desideri automatizzare l'intero processo di failover, puoi utilizzare la funzionalità di ripristino automatico di ClusterControl (a livello di nodo e cluster).
 Ripristino automatico del cluster ClusterControl
Ripristino automatico del cluster ClusterControl Stima della dimensione della cache di galera:
MariaDB [(none)]> SET @start := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); do sleep(60); SET @end := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); SET @gcache := (SELECT SUBSTRING_INDEX(SUBSTRING_INDEX(@@GLOBAL.wsrep_provider_options,'gcache.size = ',-1), 'M', 1)); SELECT ROUND((@end - @start),2) AS `MB/min`, ROUND((@end - @start),2) * 60 as `MB/hour`, @gcache as `gcache Size(MB)`, ROUND(@gcache/round((@end - @start),2),2) as `Time to full(minutes)`;Per rendere il failover più coerente, dovresti abilitare gcache.recover=yes in mycnf. Questa opzione farà rivivere la galera-cache al riavvio. Ciò significa che il nodo può fungere da donatore e il servizio manca di set di scritture (facilitando IST, invece di utilizzare SST).
2018-07-20 8:59:44 139656049956608 [Note] WSREP: Quorum results:
version = 4,
component = PRIMARY,
conf_id = 2,
members = 2/3 (joined/total),
act_id = 12810,
last_appl. = 0,
protocols = 0/7/3 (gcs/repl/appl),
group UUID = 49eca8f8-0e3a-11e8-be4a-e7e3fe48cb69
2018-07-20 8:59:44 139656049956608 [Note] WSREP: Flow-control interval: [28, 28]
2018-07-20 8:59:44 139656049956608 [Note] WSREP: Trying to continue unpaused monitor
2018-07-20 8:59:44 139657311033088 [Note] WSREP: New cluster view: global state: 49eca8f8-0e3a-11e8-be4a-e7e3fe48cb69:12810, view# 3: Primary, number of nodes: 3, my index: 1, protocol version 3Il nodo SQL proxy non funziona
Se hai una configurazione IP virtuale, tutto ciò che devi fare è puntare la tua applicazione all'indirizzo IP virtuale e tutto dovrebbe essere corretto dal punto di vista della connessione. Non è sufficiente avere le istanze del database che si estendono su più data center, hai comunque bisogno delle tue applicazioni per accedervi. Supponiamo di aver ridotto il numero di repliche di lettura, potresti voler implementare IP virtuali anche per ciascuna di queste repliche di lettura per motivi di manutenzione o disponibilità. Potrebbe diventare un ingombrante pool di IP virtuali che devi gestire. Se una di queste repliche di lettura subisce un arresto anomalo, è necessario riassegnare l'IP virtuale al diverso host, altrimenti l'applicazione si connetterà a un host inattivo o, nel peggiore dei casi, a un server in ritardo con dati non aggiornati.
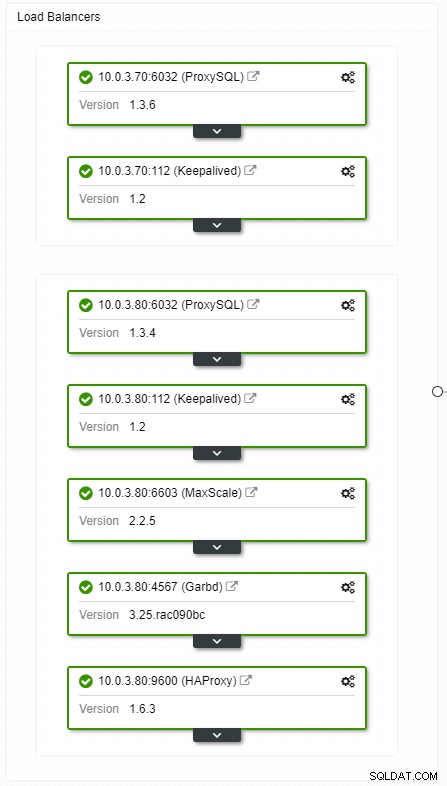 Vista della topologia dei bilanciatori di carico ClusterControl HA
Vista della topologia dei bilanciatori di carico ClusterControl HA Gli arresti anomali non sono frequenti, ma più probabili dei server che si interrompono. Se per qualsiasi motivo uno slave va in crash, qualcosa come ProxySQL reindirizzerà tutto il traffico al master, con il rischio di sovraccaricarlo. Quando lo slave si riprende, il traffico verrà reindirizzato ad esso. Di solito, tali tempi di inattività non dovrebbero richiedere più di un paio di minuti, quindi la gravità complessiva è media, anche se anche la probabilità è media.
Per avere i componenti del sistema di bilanciamento del carico ridondanti, puoi utilizzare keepalived.
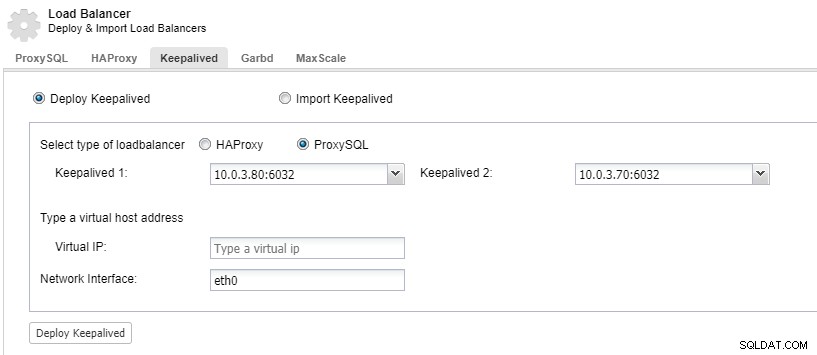 ClusterControl:distribuire keepalived per il sistema di bilanciamento del carico ProxySQL
ClusterControl:distribuire keepalived per il sistema di bilanciamento del carico ProxySQL Il datacenter non funziona
Il problema principale con la replica è che non esiste un meccanismo di maggioranza per rilevare un errore del data center e servire un nuovo master. Una delle risoluzioni è usare Orchestrator/Raft. L'orchestrator è un supervisore della topologia in grado di controllare i failover. Se utilizzato insieme a Raft, Orchestrator diventerà consapevole del quorum. Una delle istanze dell'orchestratore viene eletta come leader ed esegue attività di ripristino. La connessione tra il nodo dell'agente di orchestrazione non è correlata ai commit del database transazionale ed è scarsa.
Orchestrator/Raft può utilizzare istanze aggiuntive che eseguono il monitoraggio della topologia. Nel caso del partizionamento di rete, le istanze di Orchestrator partizionate non eseguiranno alcuna azione. La parte del cluster dell'orchestratore che ha il quorum eleggerà un nuovo master e apporterà le modifiche alla topologia necessarie.
ClusterControl viene utilizzato per la gestione, il ridimensionamento e, cosa più importante, il ripristino dei nodi:Orchestrator gestirà i failover, ma se uno slave si arresta in modo anomalo, ClusterControl si assicurerà che venga ripristinato. Orchestrator e ClusterControl sarebbero situati nella stessa zona di disponibilità, separati dai nodi MySQL, per assicurarsi che la loro attività non sia influenzata dalle divisioni di rete tra le zone di disponibilità nel data center.