La gestione del traffico verso il database può diventare sempre più difficile man mano che aumenta di quantità e il database è effettivamente distribuito su più server. I client PostgreSQL di solito parlano con un singolo endpoint. Quando un nodo primario si guasta, i client del database continueranno a riprovare con lo stesso IP. In caso di failover su un nodo secondario, l'applicazione deve essere aggiornata con il nuovo endpoint. È qui che vorresti inserire un servizio di bilanciamento del carico tra le applicazioni e le istanze del database. Può indirizzare le applicazioni a nodi di database disponibili/integri e eseguire il failover quando richiesto. Un altro vantaggio sarebbe aumentare le prestazioni di lettura utilizzando le repliche in modo efficace. È possibile creare una porta di sola lettura che bilancia le letture tra le repliche. In questo blog tratteremo HAProxy. Vedremo cos'è, come funziona e come distribuirlo per PostgreSQL.
Cos'è HAProxy?
HAProxy è un proxy open source che può essere utilizzato per implementare alta disponibilità, bilanciamento del carico e proxy per applicazioni basate su TCP e HTTP.
In qualità di bilanciamento del carico, HAProxy distribuisce il traffico da un'origine a una o più destinazioni e può definire regole e/o protocolli specifici per questa attività. Se una qualsiasi delle destinazioni smette di rispondere, viene contrassegnata come offline e il traffico viene inviato alle altre destinazioni disponibili.
Come installare e configurare HAProxy manualmente
Per installare HAProxy su Linux è possibile utilizzare i seguenti comandi:
Su sistema operativo Ubuntu/Debian:
$ apt-get install haproxy -ySu sistema operativo CentOS/RedHat:
$ yum install haproxy -yE poi dobbiamo modificare il seguente file di configurazione per gestire la nostra configurazione HAProxy:
$ /etc/haproxy/haproxy.cfgConfigurare il nostro HAProxy non è complicato, ma dobbiamo sapere cosa stiamo facendo. Abbiamo diversi parametri da configurare, a seconda di come vogliamo che HAProxy funzioni. Per ulteriori informazioni, possiamo seguire la documentazione sulla configurazione di HAProxy.
Diamo un'occhiata a un esempio di configurazione di base. Supponiamo di avere la seguente topologia di database:
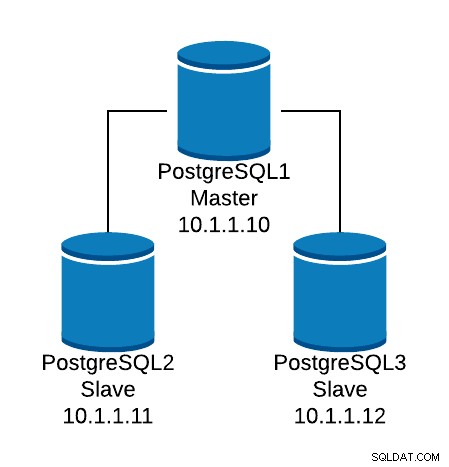 Esempio di topologia del database
Esempio di topologia del database Vogliamo creare un listener HAProxy per bilanciare il traffico di lettura tra i tre nodi.
listen haproxy_read
bind *:5434
balance roundrobin
server postgres1 10.1.1.10:5432 check
server postgres2 10.1.1.11:5432 check
server postgres3 10.1.1.12:5432 checkCome accennato in precedenza, ci sono diversi parametri da configurare qui e questa configurazione dipende da cosa vogliamo fare. Ad esempio:
listen haproxy_read
bind *:5434
mode tcp
timeout client 10800s
timeout server 10800s
tcp-check expect string is\ running
balance leastconn
option tcp-check
default-server port 9201 inter 2s downinter 5s rise 3 fall 2 slowstart 60s maxconn 64 maxqueue 128 weight 100
server postgres1 10.1.1.10:5432 check
server postgres2 10.1.1.11:5432 check
server postgres3 10.1.1.12:5432 checkCome funziona HAProxy su ClusterControl
Per PostgreSQL, HAProxy è configurato da ClusterControl con due porte diverse per impostazione predefinita, una di lettura-scrittura e una di sola lettura.
 Informazioni sulla distribuzione di ClusterControl Load Balancer 1
Informazioni sulla distribuzione di ClusterControl Load Balancer 1 Nella nostra porta di lettura-scrittura, abbiamo il nostro server master online e il resto dei nostri nodi offline, e nella porta di sola lettura abbiamo sia il master che gli slave online.
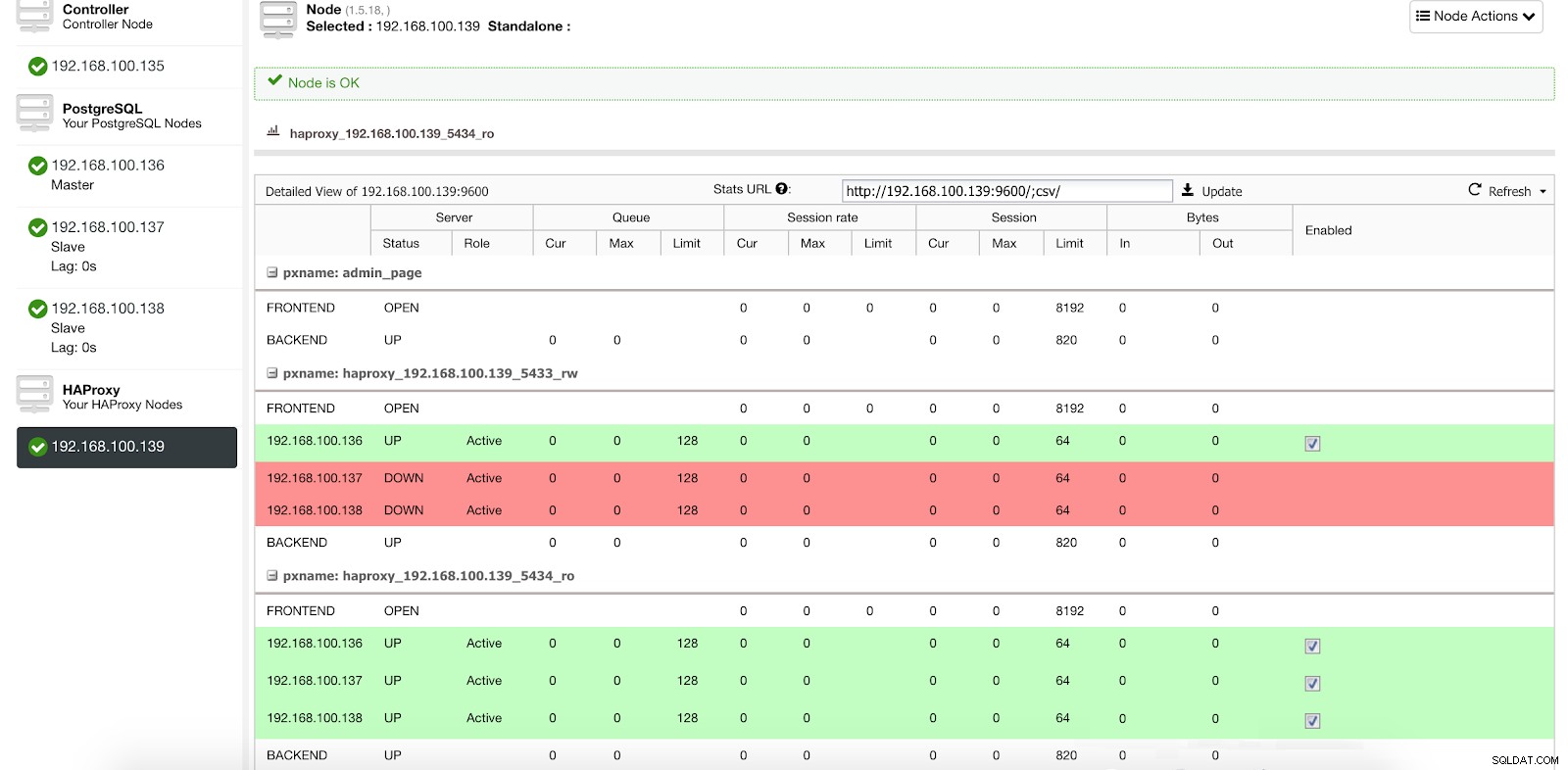 Statistiche del bilanciamento del carico ClusterControl 1
Statistiche del bilanciamento del carico ClusterControl 1 Quando HAProxy rileva che uno dei nostri nodi, master o slave, non è accessibile, lo contrassegna automaticamente come offline e non ne tiene conto durante l'invio del traffico. Il rilevamento viene eseguito dagli script di controllo dello stato configurati da ClusterControl al momento della distribuzione. Questi controllano se le istanze sono attive, se sono in fase di ripristino o sono di sola lettura.
Quando ClusterControl promuove uno slave a master, HAProxy contrassegna il vecchio master come offline (per entrambe le porte) e mette il nodo promosso online (nella porta di lettura-scrittura).
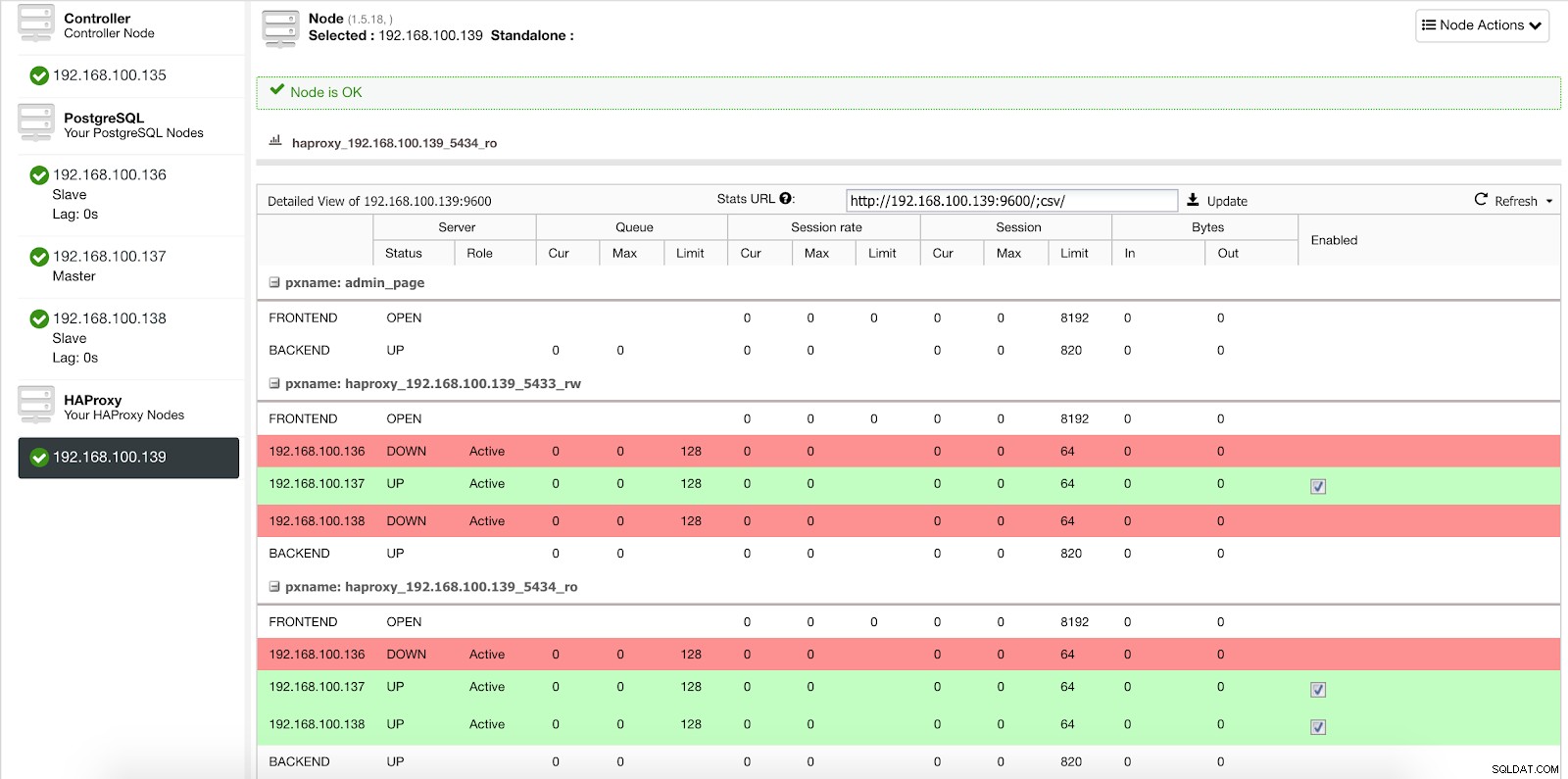 ClusterControl Load Balancer Stats 2
ClusterControl Load Balancer Stats 2 In questo modo, i nostri sistemi continuano a funzionare normalmente e senza il nostro intervento.
Come distribuire HAProxy con ClusterControl
Nel nostro esempio, abbiamo creato un ambiente con 1 master e 2 slave:vedere uno screenshot della Topology View in ClusterControl. Ora aggiungeremo il nostro sistema di bilanciamento del carico HAProxy.
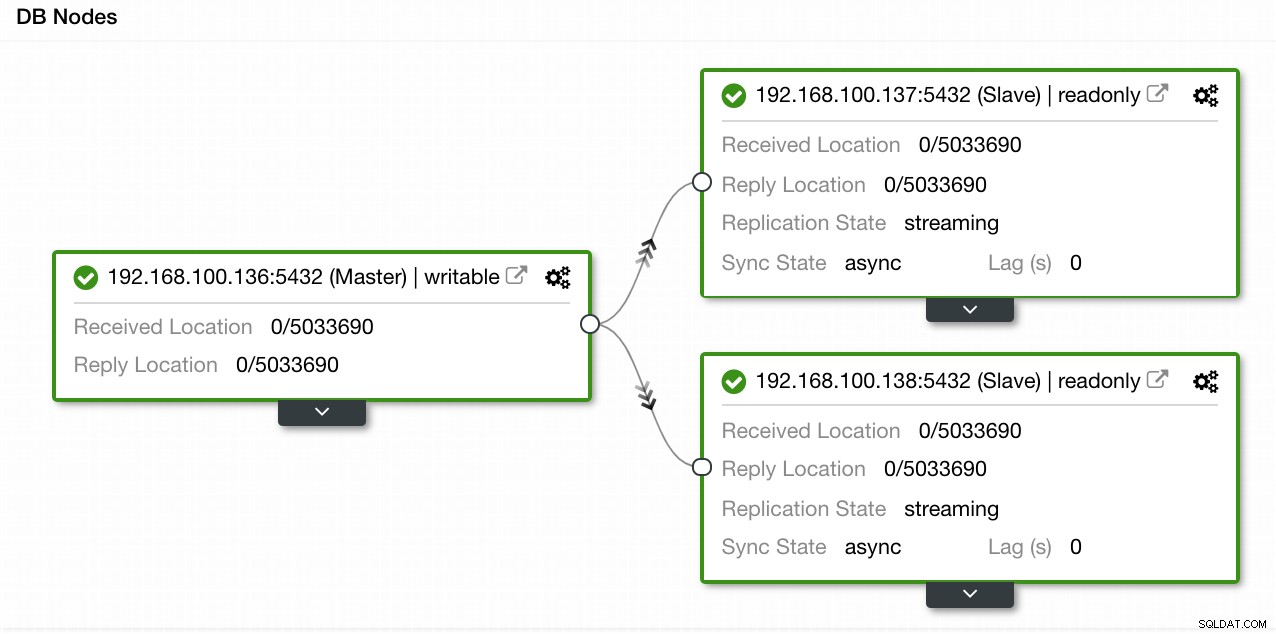 ClusterControl Topology View 1
ClusterControl Topology View 1 Per questa attività dobbiamo andare su ClusterControl -> PostgreSQL Cluster Actions -> Aggiungi Load Balancer
 Menu Azioni ClusterControl Cluster
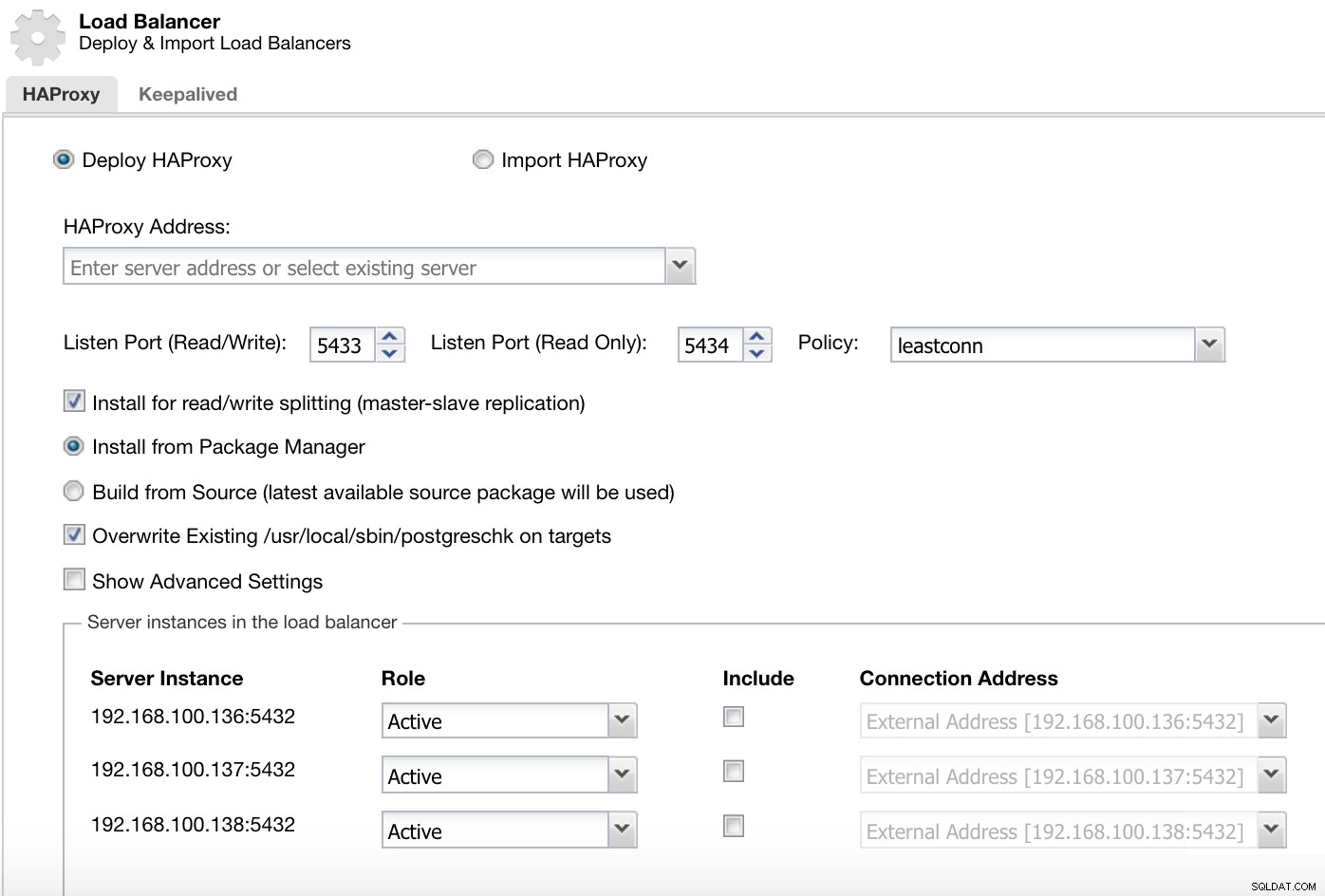
Menu Azioni ClusterControl Cluster Qui dobbiamo aggiungere le informazioni che ClusterControl utilizzerà per installare e configurare il nostro sistema di bilanciamento del carico HAProxy.
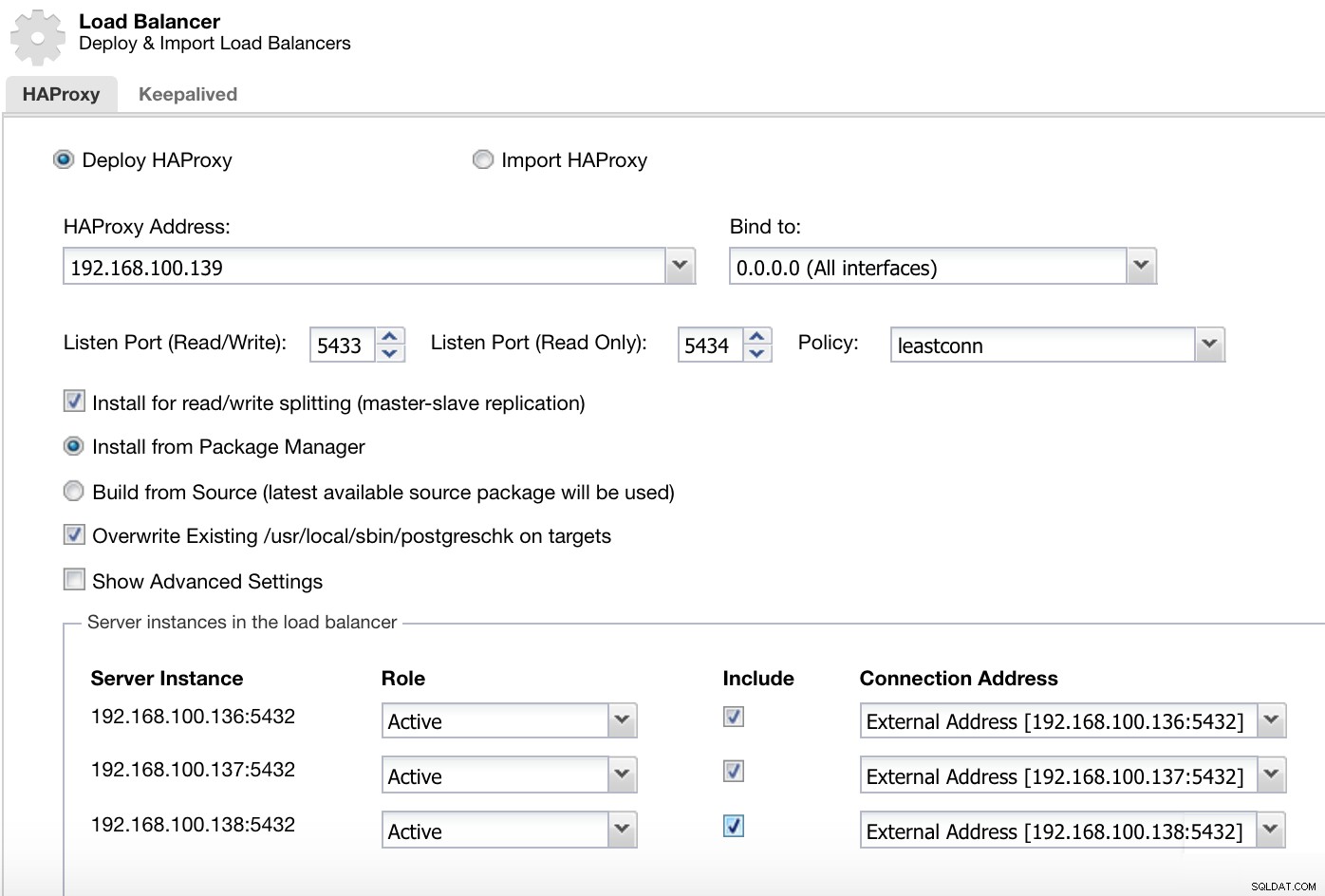 Informazioni sulla distribuzione di ClusterControl Load Balancer 2
Informazioni sulla distribuzione di ClusterControl Load Balancer 2 Le informazioni che dobbiamo introdurre sono:
Azione:distribuisci o importa.
Indirizzo HAProxy:Indirizzo IP per il nostro server HAProxy.
Associa a:interfaccia o indirizzo IP su cui HAProxy ascolterà.
Porta di ascolto (lettura/scrittura):porta per la modalità di lettura/scrittura.
Porta di ascolto (sola lettura):porta per la modalità di sola lettura.
Politica:può essere:
- leastconn:il server con il minor numero di connessioni riceve la connessione.
- roundrobin:ogni server viene utilizzato a turno, in base al loro peso.
- fonte:l'indirizzo IP di origine viene sottoposto a hash e diviso per il peso totale dei server in esecuzione per designare quale server riceverà la richiesta.
Installa per la suddivisione in lettura/scrittura:per la replica master-slave.
Sorgente:possiamo scegliere Installa da un gestore di pacchetti o compila dal sorgente.
Sovrascrivi postgreschk esistente sui target.
E dobbiamo selezionare quali server si desidera aggiungere alla configurazione HAProxy e alcune informazioni aggiuntive come:
Ruolo:può essere attivo o di backup.
Includi:Sì o No.
Informazioni sull'indirizzo di connessione.
Inoltre, possiamo configurare Impostazioni avanzate come Utente amministratore, Nome backend, Timeout e altro.
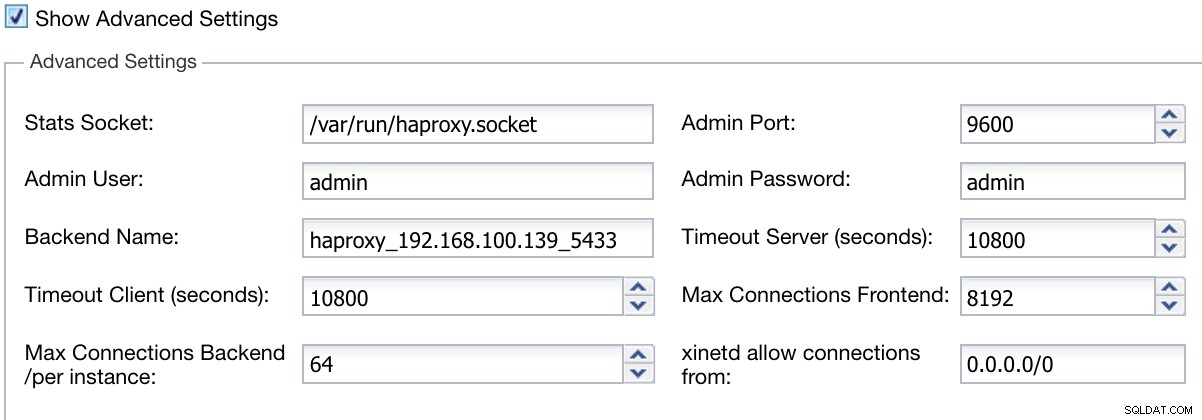 ClusterControl Load Balancer Informazioni sulla distribuzione Avanzate
ClusterControl Load Balancer Informazioni sulla distribuzione Avanzate Una volta completata la configurazione e confermato la distribuzione, possiamo seguire l'avanzamento nella sezione Attività sull'interfaccia utente di ClusterControl.
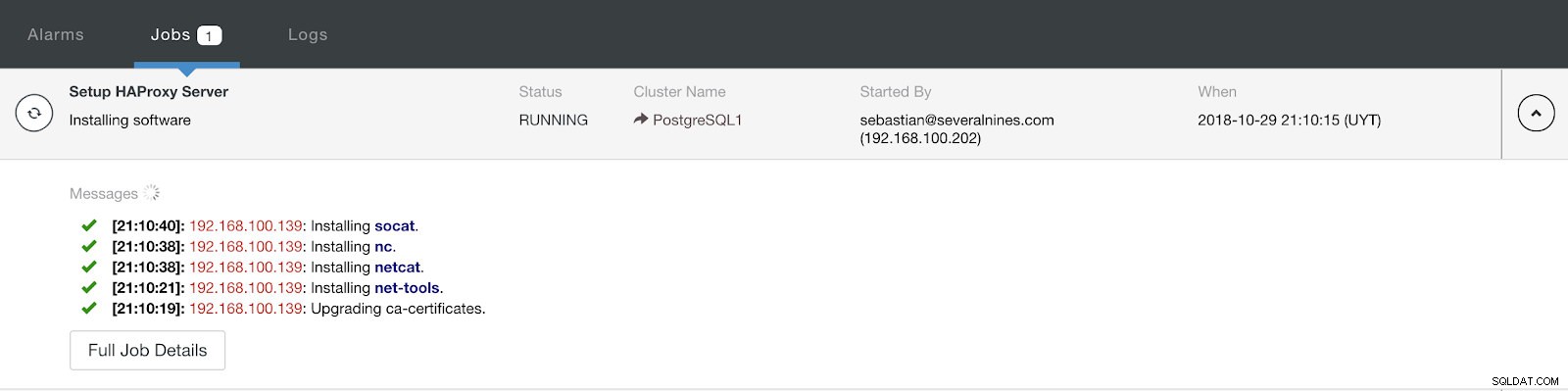 Sezione attività ClusterControl
Sezione attività ClusterControl Al termine, dovremmo avere la seguente topologia:
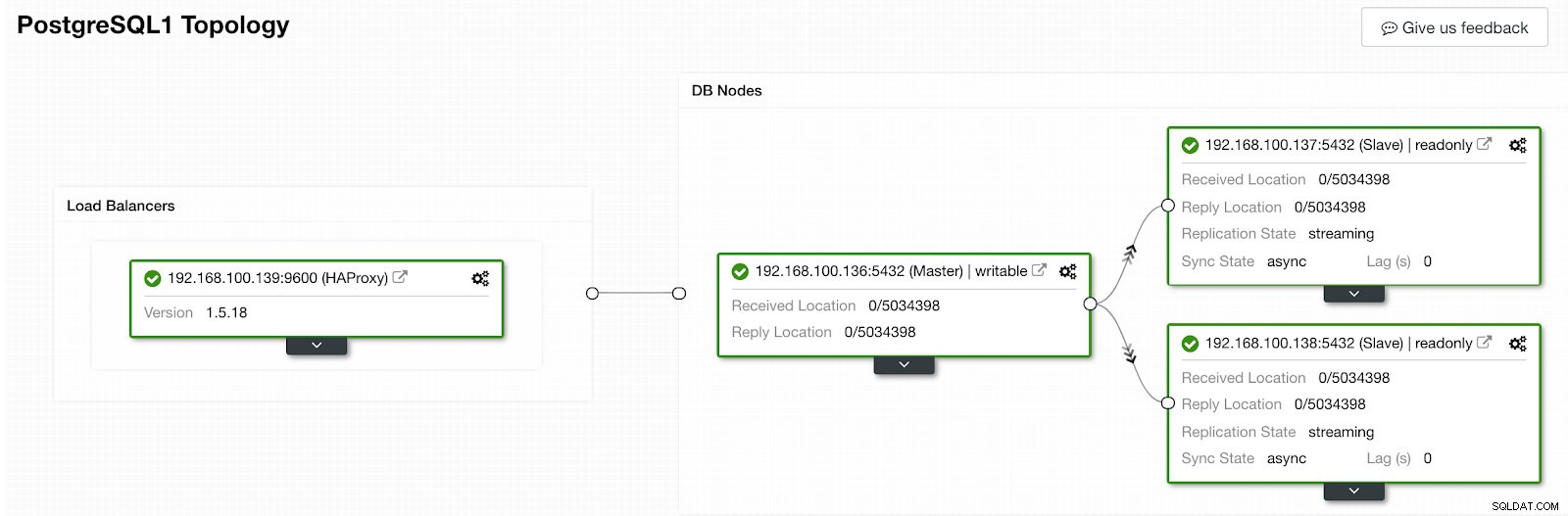 ClusterControl Topology View 2
ClusterControl Topology View 2 Possiamo migliorare il nostro design HA aggiungendo un nuovo nodo HAProxy e configurando il servizio Keepalived tra di loro. Tutto questo può essere eseguito da ClusterControl. Per ulteriori informazioni, puoi consultare il nostro precedente blog su PostgreSQL e HA.
Utilizzo della CLI ClusterControl per aggiungere un bilanciamento del carico HAProxy
Conosciuto anche come s9s-tools, questo pacchetto opzionale è stato introdotto in ClusterControl versione 1.4.1, che contiene un file binario chiamato s9s. È uno strumento a riga di comando per interagire, controllare e gestire l'infrastruttura del database utilizzando ClusterControl. Il progetto della riga di comando di s9s è open source e può essere trovato su GitHub.
A partire dalla versione 1.4.1, lo script di installazione installerà automaticamente il pacchetto (s9s-tools) sul nodo ClusterControl.
ClusterControl CLI apre una nuova porta per l'automazione dei cluster in cui puoi integrarla facilmente con gli strumenti di automazione della distribuzione esistenti come Ansible, Puppet, Chef o Salt.
Diamo un'occhiata a un esempio di come creare un sistema di bilanciamento del carico HAProxy con indirizzo IP 192.168.100.142 su cluster ID 1:
[example@sqldat.com ~]# s9s cluster --add-node --cluster-id=1 --nodes="haproxy://192.168.100.142" --wait
Add HaProxy to Cluster
/ Job 7 FINISHED [██████████] 100% Job finished.E poi possiamo controllare tutti i nostri nodi dalla riga di comando:
[example@sqldat.com ~]# s9s node --cluster-id=1 --list --long
STAT VERSION CID CLUSTER HOST PORT COMMENT
coC- 1.7.0.2832 1 PostgreSQL1 192.168.100.135 9500 Up and running.
poS- 10.5 1 PostgreSQL1 192.168.100.136 5432 Up and running.
poM- 10.5 1 PostgreSQL1 192.168.100.137 5432 Up and running.
poS- 10.5 1 PostgreSQL1 192.168.100.138 5432 Up and running.
ho-- 1.5.18 1 PostgreSQL1 192.168.100.142 9600 Process 'haproxy' is running.
Total: 5Per ulteriori informazioni su s9s e su come usarlo, puoi controllare la documentazione ufficiale o questo how to blog di questo argomento.
Conclusione
In questo blog, abbiamo esaminato come HAProxy può aiutarci a gestire il traffico proveniente dall'applicazione nel nostro database PostgreSQL. Abbiamo verificato come può essere distribuito e configurato manualmente, quindi abbiamo visto come può essere automatizzato con ClusterControl. Per evitare che HAProxy diventi un singolo punto di errore (SPOF), assicurati di distribuire almeno due istanze HAProxy e di implementare qualcosa come Keepalived e Virtual IP su di esse.



