Con Disaster Recovery, miriamo a configurare i sistemi per gestire tutto ciò che potrebbe andare storto con il nostro database. Cosa succede se il database si arresta in modo anomalo? Cosa succede se uno sviluppatore tronca accidentalmente una tabella? E se scoprissimo che alcuni dati sono stati cancellati la scorsa settimana ma non ce ne siamo accorti fino ad oggi? Queste cose accadono e avere un piano e un sistema solidi in atto farà sembrare il DBA un eroe quando i cuori di tutti gli altri si sono già fermati quando un disastro alza la sua brutta testa.
Qualsiasi database con qualsiasi tipo di valore dovrebbe avere un modo per implementare una o più opzioni di ripristino di emergenza. PostgreSQL ha un solido sistema di replica integrato ed è abbastanza flessibile da essere configurato in molte configurazioni per aiutare con il ripristino di emergenza, se qualcosa dovesse andare storto. Ci concentreremo su scenari come quelli sopra interrogati, su come impostare le nostre opzioni di ripristino di emergenza e sui vantaggi di ciascuna soluzione.
Alta disponibilità
Con la replica in streaming in PostgreSQL, l'alta disponibilità è semplice da configurare e mantenere. L'obiettivo è fornire un sito di failover che possa essere promosso a master se il database principale si interrompe per qualsiasi motivo, ad esempio un errore hardware, un errore software o persino un'interruzione della rete. Ospitare una replica su un altro host è fantastico, ma ospitarla in un altro data center è ancora meglio.
Per i dettagli sull'impostazione della replica in streaming, Diversinines ha un'analisi approfondita dettagliata disponibile qui. La documentazione ufficiale sulla replica in streaming di PostgreSQL contiene informazioni dettagliate sul protocollo di replica in streaming e su come funziona.
Una configurazione standard sarà simile a questa, un database master che accetta connessioni di lettura/scrittura, con un database di replica che riceve tutte le attività WAL quasi in tempo reale, riproducendo tutte le attività di modifica dei dati in locale.
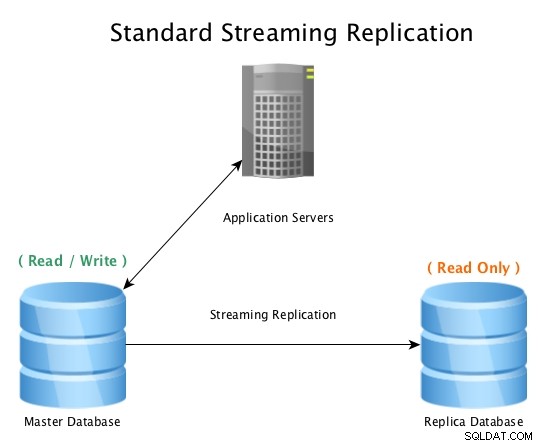 Replica streaming standard con PostgreSQL
Replica streaming standard con PostgreSQL Quando il database master diventa inutilizzabile, viene avviata una procedura di failover per portarlo offline e promuovere il database di replica a master, quindi puntando tutte le connessioni all'host appena promosso. Questo può essere fatto riconfigurando un sistema di bilanciamento del carico, la configurazione dell'applicazione, gli alias IP o altri modi intelligenti per reindirizzare il traffico.
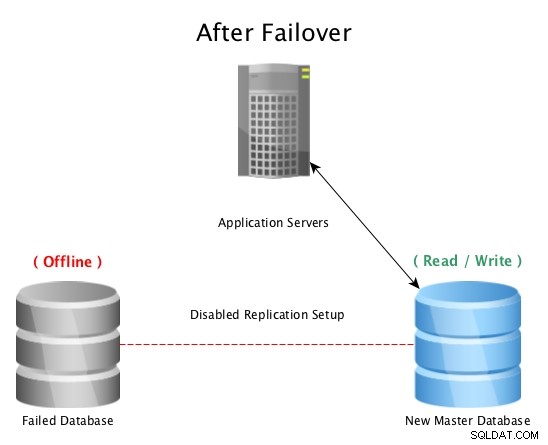 Dopo un failover con PostgreSQL Streaming Replication
Dopo un failover con PostgreSQL Streaming Replication Quando un'emergenza colpisce un database master (come un guasto del disco rigido, un'interruzione di corrente o qualsiasi altra cosa che impedisce al master di funzionare come previsto), il failover in hot standby è il modo più rapido per rimanere online e inviare query ad applicazioni o clienti senza problemi seri tempo di inattività. La corsa è quindi avviata per riparare l'host del database guasto o per portare una nuova replica online per mantenere la rete di sicurezza di avere uno standby pronto per l'uso. Avere più standby assicurerà che la finestra dopo un guasto disastroso sia pronta anche per un guasto secondario, per quanto improbabile possa sembrare.
Nota:quando si esegue il failover su una replica in streaming, riprenderà da dove si era interrotto il master precedente, quindi questo aiuta a mantenere il database online, ma non a recuperare i dati persi accidentalmente.
Recupero temporizzato
Un'altra opzione di ripristino di emergenza è Point in TIme Recovery (PITR). Con PITR, una copia del database può essere ripristinata in qualsiasi momento desideriamo, purché disponiamo di un backup di base di prima di quel momento e di tutti i segmenti WAL necessari fino a quel momento.
Un'opzione Point In Time Recovery non viene portata online così rapidamente come Hot Standby, tuttavia il vantaggio principale è la possibilità di recuperare uno snapshot del database prima di un grande evento come una tabella eliminata, dati errati inseriti o persino un danneggiamento dei dati inspiegabile . Tutto ciò che distruggerebbe i dati in modo tale da volerne ottenere una copia prima di tale distruzione, PITR salva la situazione.
Point in Time Recovery funziona creando snapshot periodici del database, solitamente utilizzando il programma pg_basebackup, e conservando copie archiviate di tutti i file WAL generati dal master
Configurazione del ripristino temporizzato
L'installazione richiede alcune opzioni di configurazione impostate sul master, alcune delle quali vanno bene per andare con i valori predefiniti sull'ultima versione corrente, PostgreSQL 11. In questo esempio, copieremo il file da 16 MB direttamente sul nostro host PITR remoto usando rsync e comprimendoli dall'altro lato con un processo cron.
Archiviazione WAL
Master postgresql.conf
wal_level = replica
archive_mode = on
archive_command = 'rsync -av -z %p example@sqldat.com:/mnt/db/wal_archive/%f'NOTA: L'impostazione archive_command può essere molte cose, l'obiettivo generale è inviare tutti i file WAL archiviati a un altro host per motivi di sicurezza. Se perdiamo file WAL, PITR oltre il file WAL perso diventa impossibile. Fai impazzire la tua creatività di programmazione, ma assicurati che sia affidabile.
[Facoltativo] Comprimi i file WAL archiviati:
Ogni configurazione varia leggermente, ma a meno che il database in questione non sia molto leggero negli aggiornamenti dei dati, l'accumulo di file da 16 MB occuperà lo spazio su disco abbastanza rapidamente. Un semplice script di compressione, impostato tramite cron, potrebbe apparire come di seguito.
compress_WAL_archive.sh:
#!/bin/bash
# Compress any WAL files found that are not yet compressed
gzip /mnt/db/wal_archive/*[0-F]NOTA: Durante qualsiasi metodo di ripristino, tutti i file compressi dovranno essere decompressi in un secondo momento. Alcuni amministratori scelgono di comprimere i file solo dopo che hanno raggiunto il numero X di giorni, mantenendo lo spazio complessivo basso, ma anche mantenendo i file WAL più recenti pronti per il ripristino senza lavoro aggiuntivo. Scegli l'opzione migliore per i database in questione per massimizzare la tua velocità di ripristino.
Backup di base
Uno dei componenti chiave di un backup PITR è il backup di base e la frequenza dei backup di base. Questi possono essere orari, giornalieri, settimanali, mensili, ma hanno scelto l'opzione migliore in base alle esigenze di ripristino e al traffico dei dati del database. Se disponiamo di backup settimanali ogni domenica e dobbiamo eseguire il ripristino fino al sabato pomeriggio, portiamo online il backup di base della domenica precedente con tutti i file WAL tra quel backup e il sabato pomeriggio. Se l'elaborazione di questo processo di ripristino richiede 10 ore, è probabile che sia troppo lungo, i backup di base giornalieri ridurranno il tempo di ripristino, poiché il backup di base risulterebbe da quella mattina, ma aumenteranno anche la quantità di lavoro sull'host per il backup di base stesso.
Se il ripristino di una settimana di file WAL richiede solo pochi minuti, poiché il database registra un tasso di abbandono ridotto, i backup settimanali vanno bene. Gli stessi dati esisteranno alla fine, ma la velocità con cui potrai accedervi è la chiave.
Nel nostro esempio, imposteremo un backup di base settimanale e, poiché stiamo utilizzando la replica in streaming per l'alta disponibilità, oltre a ridurre il carico sul master, creeremo il backup di base dal database di replica.
base_backup.sh:
#!/bin/bash
backup_dir="$(date +'%Y-%m-%d')_backup"
cd /mnt/db/backups
mkdir $backup_dir
pg_basebackup -h <replica host> -p <replica port> -U replication -D $backup_dir -Ft -zNOTA: Il comando pg_basebackup presuppone che questo host sia configurato per l'accesso senza password per la "replica" dell'utente sul master, che può essere eseguita tramite "trust" in pg_hba per questo host di backup PITR, password nel file .pgpass o altri modi più sicuri . Tieni a mente la sicurezza quando configuri i backup.
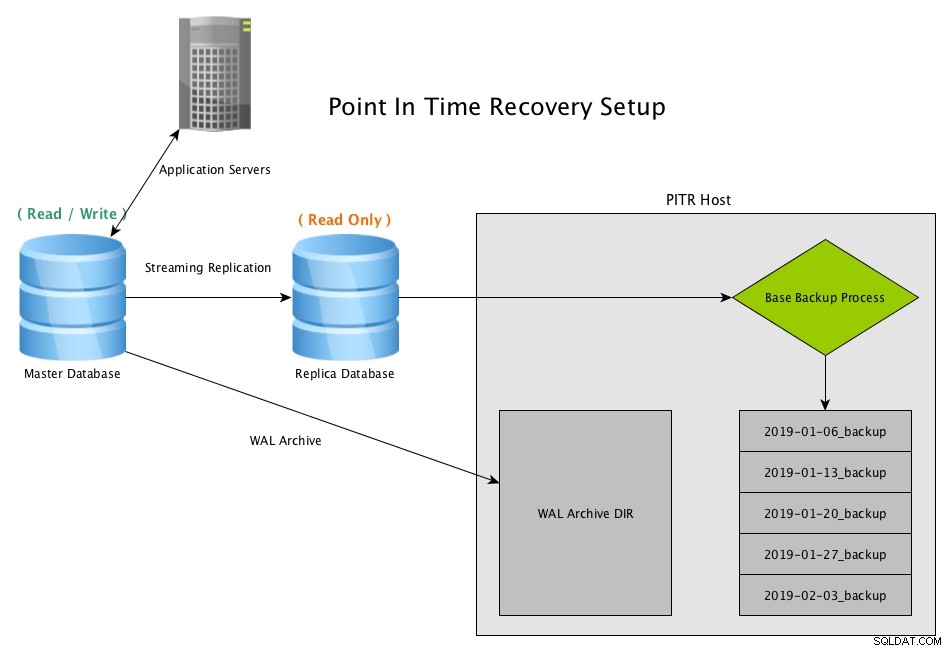 Point In Time Recovery (PITR) da una replica in streaming con PostgreSQLScarica oggi il whitepaper PostgreSQL Management &Automation con ClusterControlUlteriori informazioni cosa devi sapere per distribuire, monitorare, gestire e ridimensionare PostgreSQLScarica il whitepaper
Point In Time Recovery (PITR) da una replica in streaming con PostgreSQLScarica oggi il whitepaper PostgreSQL Management &Automation con ClusterControlUlteriori informazioni cosa devi sapere per distribuire, monitorare, gestire e ridimensionare PostgreSQLScarica il whitepaper Scenario di ripristino PITR
L'impostazione di Point In Time Recovery è solo una parte del lavoro, il dover recuperare i dati è l'altra parte. Con buona fortuna, questo potrebbe non accadere mai, tuttavia si consiglia vivamente di eseguire periodicamente un ripristino di un backup PITR per verificare che il sistema funzioni e per assicurarsi che il processo sia noto / programmato correttamente.
Nel nostro scenario di test, sceglieremo un punto nel tempo in cui eseguire il ripristino e avviare il processo di ripristino. Ad esempio:venerdì mattina, uno sviluppatore spinge una nuova modifica del codice in produzione senza passare attraverso una revisione del codice e distrugge una serie di dati importanti sui clienti. Poiché il nostro Hot Standby è sempre sincronizzato con il master, il failover su di esso non risolverebbe nulla, poiché sarebbero gli stessi dati. I backup PITR sono ciò che ci salverà.
Il push del codice è arrivato alle 11:00, quindi dobbiamo ripristinare il database appena prima di quell'ora, decidiamo alle 10:59, e fortunatamente eseguiamo backup giornalieri, quindi abbiamo un backup da mezzanotte di questa mattina. Dal momento che non sappiamo cosa sia stato distrutto, decidiamo anche di eseguire un ripristino completo di questo database sul nostro host PITR e di portarlo online come master, poiché ha le stesse specifiche hardware del master, nel caso in cui questo è successo lo scenario.
Spegni il Master
Dal momento che abbiamo deciso di ripristinare completamente da un backup e promuoverlo a master, non è necessario tenerlo online. Lo spegniamo, ma lo teniamo in giro nel caso in cui dovessimo prendere qualcosa da esso in seguito, per ogni evenienza.
Impostazione del backup di base per il ripristino
Successivamente, sul nostro host PITR, recuperiamo il nostro backup di base più recente prima dell'evento, ovvero il backup "2018-12-21_backup".
mkdir /var/lib/pgsql/11/data
chmod 700 /var/lib/pgsql/11/data
cd /var/lib/pgsql/11/data
tar -xzvf /mnt/db/backups/2018-12-21_backup/base.tar.gz
cd pg_wal
tar -xzvf /mnt/db/backups/2018-12-21_backup/pg_wal.tar.gz
mkdir /mnt/db/wal_archive/pitr_restore/Con questo, il backup di base, così come i file WAL forniti da pg_basebackup sono pronti per l'uso, se lo portiamo online ora, verrà ripristinato al punto in cui è stato eseguito il backup, ma vogliamo recuperare tutte le transazioni WAL tra mezzanotte e le 11:59, quindi abbiamo impostato il nostro file recovery.conf.
Crea recovery.conf
Poiché questo backup proviene effettivamente da una replica in streaming, è probabile che sia già presente un file recovery.conf con le impostazioni della replica. Lo sovrascriveremo con nuove impostazioni. Un elenco di informazioni dettagliate per tutte le diverse opzioni è disponibile nella documentazione di PostgreSQL qui.
Facendo attenzione con i file WAL, il comando di ripristino copierà i file compressi necessari nella directory di ripristino, li decomprimerà, quindi si sposterà dove PostgreSQL ne ha bisogno per il ripristino. I file WAL originali rimarranno dove sono nel caso necessario per qualsiasi altro motivo.
Nuovo recovery.conf:
recovery_target_time = '2018-12-21 11:59:00-07'
restore_command = 'cp /mnt/db/wal_archive/%f.gz /var/lib/pgsql/test_recovery/pitr_restore/%f.gz && gunzip /var/lib/pgsql/test_recovery/pitr_restore/%f.gz && mv /var/lib/pgsql/test_recovery/pitr_restore/%f "%p"'Avvia il processo di ripristino
Ora che tutto è impostato, avvieremo il processo di ripristino. Quando ciò accade, è una buona idea accodare il registro del database per assicurarsi che venga ripristinato come previsto.
Avvia il DB:
pg_ctl -D /var/lib/pgsql/11/data startCoda i registri:
Ci saranno molte voci di registro che mostrano che il database si sta ripristinando dai file di archivio e, a un certo punto, mostrerà una riga che dice "arresto del ripristino prima del commit della transazione..."
2018-12-22 04:21:30 UTC [20565]: [705-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000074" from archive
2018-12-22 04:21:30 UTC [20565]: [706-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000075" from archive
2018-12-22 04:21:31 UTC [20565]: [707-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000076" from archive
2018-12-22 04:21:31 UTC [20565]: [708-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000077" from archive
2018-12-22 04:21:31 UTC [20565]: [709-1] user=,db=,app=,client= LOG: recovery stopping before commit of transaction 611765, time 2018-12-21 11:59:01.45545+07A questo punto, il processo di ripristino ha ingerito tutti i file WAL, ma ha anche bisogno di essere rivisto prima che diventi online come master. In questo esempio, il registro rileva che la transazione successiva dopo l'ora di destinazione del ripristino di 11:59:00 era 11:59:01 e non è stata ripristinata. Per verificare, accedi al database e dai un'occhiata, il database in esecuzione dovrebbe essere uno snapshot esattamente alle 11:59.
Quando tutto sembra a posto, è tempo di promuovere la ripresa da maestro.
postgres=# SELECT pg_wal_replay_resume();
pg_wal_replay_resume
----------------------
(1 row)Ora, il database è online, ripristinato al punto da noi deciso e accetta connessioni di lettura/scrittura come nodo principale. Assicurati che tutti i parametri di configurazione siano corretti e pronti per la produzione.
Il database è online, ma il processo di ripristino non è ancora terminato! Ora che questo backup PITR è online come master, è necessario configurare una nuova configurazione di standby e PITR, fino ad allora questo nuovo master potrebbe essere online e servire applicazioni, ma non è al sicuro da un altro disastro finché non sarà tutto configurato di nuovo.
Altri scenari di recupero temporale
Il ripristino di un backup PITR per un intero database è un caso estremo, ma ci sono altri scenari in cui solo un sottoinsieme di dati è mancante, danneggiato o danneggiato. In questi casi, possiamo essere creativi con le nostre opzioni di recupero. Senza portare offline il master e sostituirlo con un backup, possiamo portare online un backup PITR all'ora esatta che vogliamo su un altro host (o un'altra porta se lo spazio non è un problema) ed esportare direttamente i dati recuperati dal backup nel database principale. Questo potrebbe essere utilizzato per recuperare una manciata di righe, una manciata di tabelle o qualsiasi configurazione di dati necessaria.
Con la replica in streaming e il Point In Time Recovery, PostgreSQL ci offre una grande flessibilità per assicurarci di poter recuperare tutti i dati di cui abbiamo bisogno, purché disponiamo di host in standby pronti per l'uso come master o backup pronti per il ripristino. Una buona opzione di Disaster Recovery può essere ulteriormente ampliata con altre opzioni di backup, più nodi di replica, più siti di backup in diversi data center e continenti, pg_dump periodici su un'altra replica, ecc.
Queste opzioni possono sommarsi, ma la vera domanda è "quanto sono preziosi i dati e quanto sei disposto a spendere per riaverli?". In molti casi la perdita dei dati è la fine di un'attività, quindi dovrebbero essere disponibili buone opzioni di ripristino di emergenza per evitare che accada il peggio.