Il cluster Galera impone una forte coerenza dei dati, in cui tutti i nodi del cluster sono strettamente accoppiati. Sebbene la segmentazione della rete sia supportata, le prestazioni di replica sono ancora vincolate da due fattori:
-
Il tempo di andata e ritorno (RTT) al nodo più lontano nel cluster dal nodo di origine.
-
La dimensione di un writeset da trasferire e certificare per il conflitto sul nodo ricevente.
Sebbene ci siano modi per aumentare le prestazioni di Galera, non è possibile aggirare questi due fattori limitanti.
Fortunatamente, Galera Cluster è stato costruito su MySQL, che include anche una funzione di replica incorporata (eh!). Sia la replica Galera che la replica MySQL esistono nello stesso software server in modo indipendente. Possiamo utilizzare queste tecnologie per lavorare insieme, in cui tutta la replica all'interno di un data center sarà su Galera, mentre la replica tra data center sarà su MySQL Replication standard. Il sito slave può fungere da sito hot-standby, pronto a fornire dati una volta che le applicazioni vengono reindirizzate al sito di backup. Ne abbiamo parlato in un precedente blog sulle architetture MySQL per il ripristino di emergenza.
La replica da cluster a cluster è stata introdotta in ClusterControl nella versione 1.7.4. In questo post del blog, mostreremo quanto sia semplice impostare la replica tra due Galera Cluster (PXC 8.0). Quindi esamineremo la parte più impegnativa:gestire gli errori a livello di nodo e cluster con l'aiuto di ClusterControl; le operazioni di failover e failback sono fondamentali per preservare l'integrità dei dati nel sistema.
Distribuzione cluster
Per il bene del nostro esempio, avremo bisogno di almeno due cluster e due siti, uno per il primario e un altro per il secondario. Funziona in modo simile alla tradizionale replica master-slave MySQL, ma su scala più ampia con tre nodi di database in ciascun sito. Con ClusterControl, otterresti questo risultato distribuendo un cluster primario, seguito dalla distribuzione del cluster secondario sul sito di ripristino di emergenza come cluster di replica, replicato da una replica asincrona bidirezionale.
Il diagramma seguente illustra la nostra architettura finale:

Abbiamo sei nodi di database in totale, tre sul sito principale e un altro tre sul sito di ripristino di emergenza. Per semplificare la rappresentazione del nodo, utilizzeremo le seguenti notazioni:
-
Sito principale:
-
galera1-P - 192.168.11.171 (master)
-
galera2-P - 192.168.11.172
-
galera3-P - 192.168.11.173
-
-
Sito di ripristino di emergenza:
-
galera1-DR - 192.168.11.181 (slave)
-
galera2-DR - 192.168.11.182
-
galera3-DR - 192.168.11.183
-
Per prima cosa, distribuisci semplicemente il primo cluster e lo chiamiamo PXC-Primary. Apri ClusterControl UI → Distribuisci → MySQL Galera e inserisci tutti i dettagli richiesti:
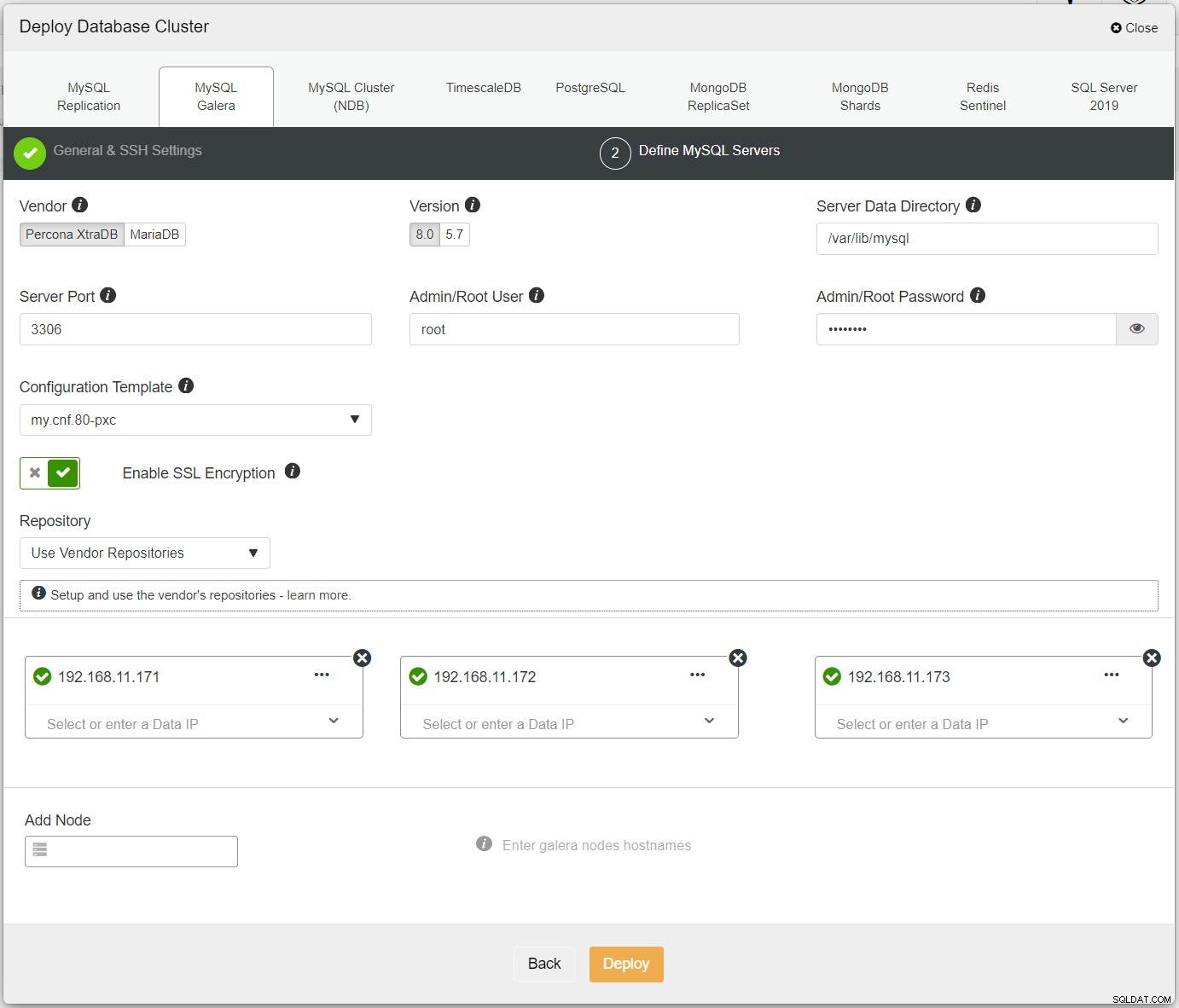
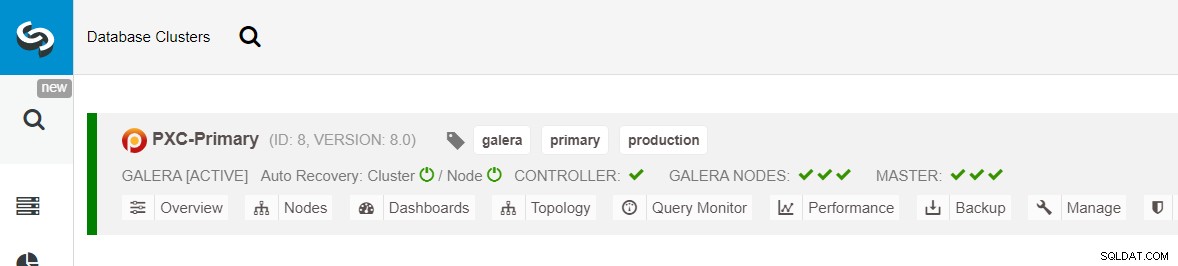
Assicurati che ogni nodo specificato abbia un segno di spunta verde accanto ad esso, a indicare che ClusterControl può connettersi all'host tramite SSH senza password. Fare clic su Distribuisci e attendere il completamento della distribuzione. Al termine, dovresti vedere il seguente cluster elencato nella pagina del dashboard del cluster:
Successivamente, utilizzeremo la funzione ClusterControl denominata Crea cluster di replica, accessibile da il menu a discesa Azione cluster:
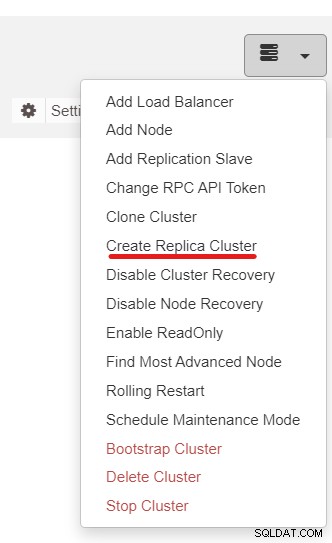
Ti verrà presentato il seguente popup della barra laterale:
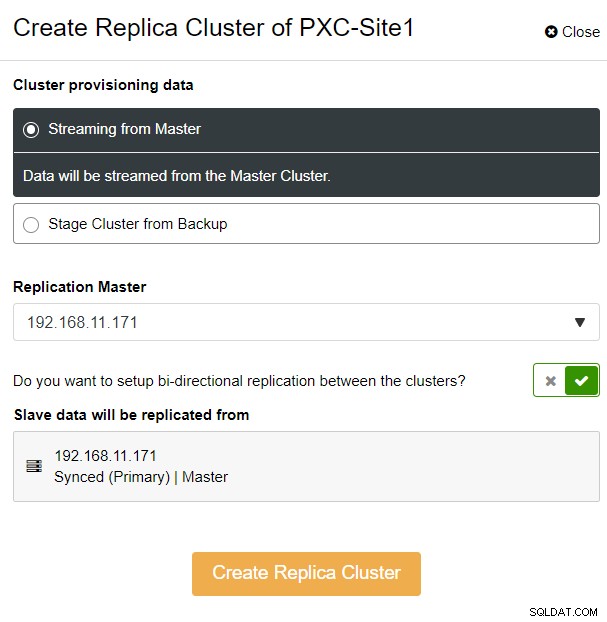
Abbiamo scelto l'opzione "Streaming dal master", dove ClusterControl utilizzerà il master scelto per sincronizzare il cluster di replica e configurare la replica. Prestare attenzione all'opzione di replica bidirezionale. Se abilitato, ClusterControl imposterà una replica bidirezionale tra entrambi i siti (replica circolare). Il master scelto eseguirà la replica dal primo master definito per il cluster di replica e viceversa. Questa configurazione ridurrà al minimo il tempo di gestione temporanea richiesto durante il ripristino dopo il failover o il failback. Fare clic su "Crea cluster di replica", dove ClusterControl apre una nuova procedura guidata di distribuzione per il cluster di replica, come mostrato di seguito:
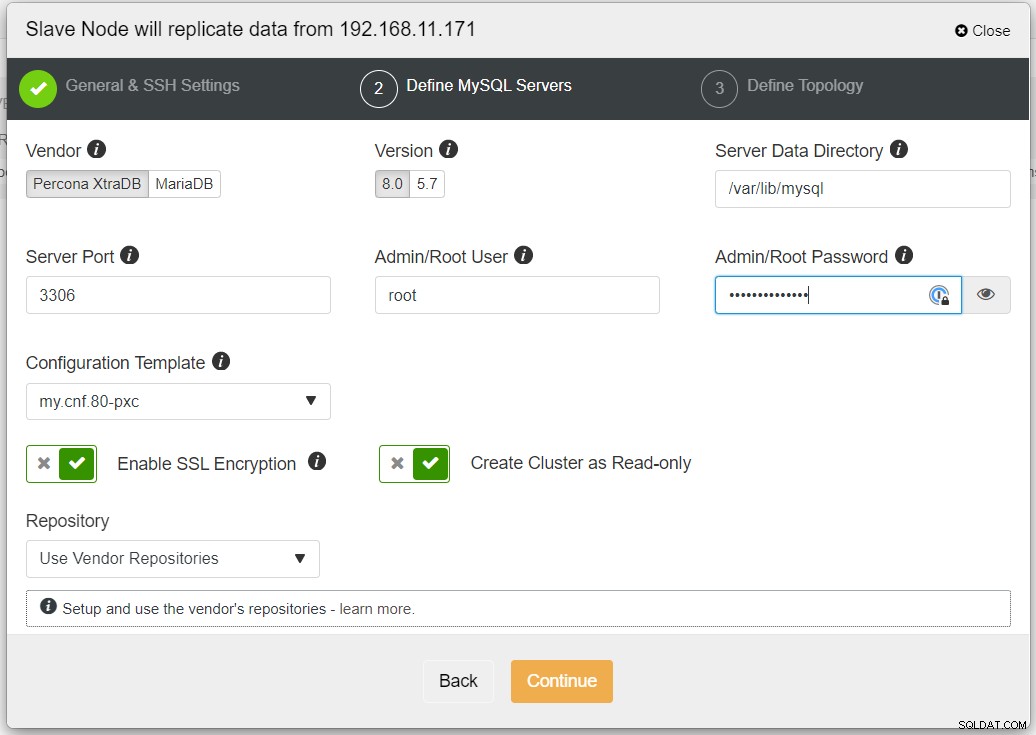
Si consiglia di abilitare la crittografia SSL se la replica coinvolge reti non attendibili come WAN, reti non tunnel o Internet. Inoltre, assicurati che "Crea cluster come di sola lettura" sia attivato; questa è la protezione contro le scritture accidentali e un buon indicatore per distinguere facilmente tra il cluster attivo (lettura-scrittura) e il cluster passivo (sola lettura).
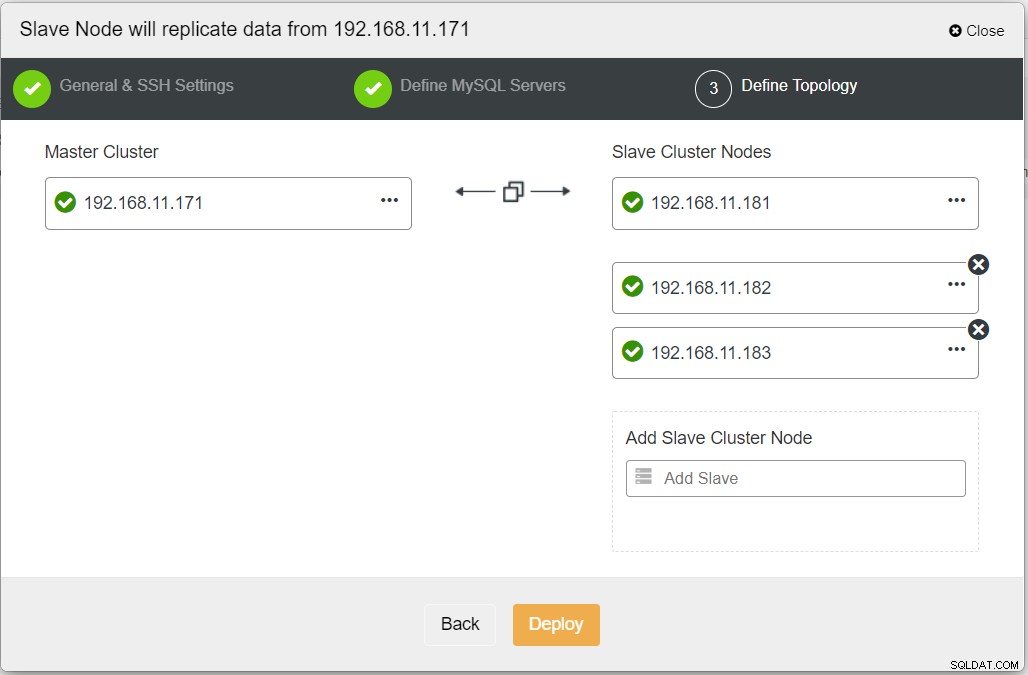
Durante la compilazione di tutte le informazioni necessarie, dovresti raggiungere la fase seguente per definire la topologia del cluster di replica:
Dalla dashboard ClusterControl, una volta completata la distribuzione, dovresti vedere il Il sito DR ha una freccia bidirezionale collegata al sito principale:
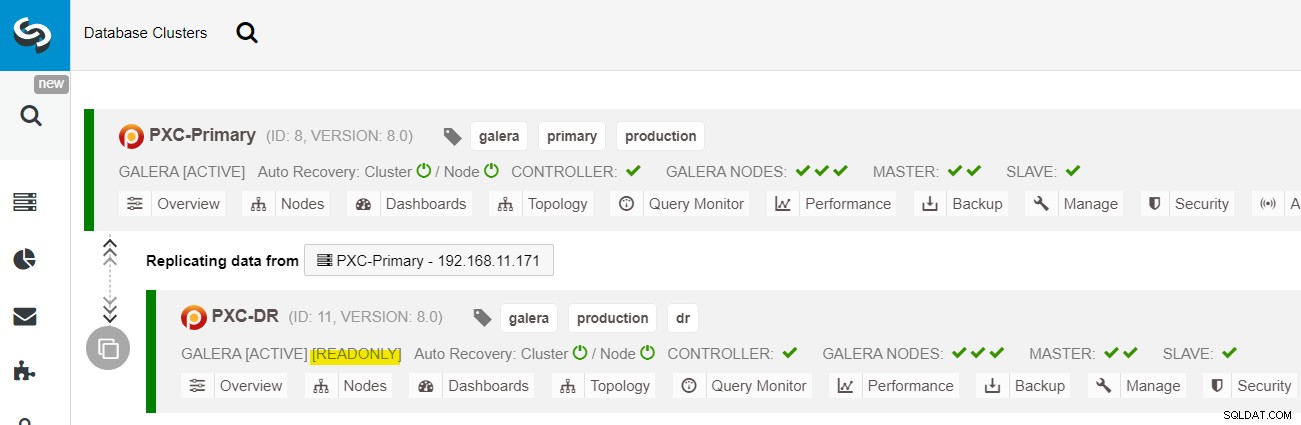
La distribuzione è ora completa. Le applicazioni devono inviare le scritture solo al sito principale poiché questo è il sito attivo e il sito di ripristino di emergenza è configurato per la sola lettura (evidenziato in giallo). Le letture possono essere inviate a entrambi i siti, sebbene il sito di ripristino di emergenza rischi di rimanere indietro a causa della natura della replica asincrona. Questa configurazione renderà i siti primari e di ripristino di emergenza indipendenti l'uno dall'altro, collegati in modo approssimativo con la replica asincrona. Uno dei nodi Galera nel sito DR sarà uno slave che si replica da uno dei nodi Galera (master) nel sito primario.
Ora abbiamo un sistema in cui un errore del cluster sul sito primario non influirà sul sito di backup. Dal punto di vista delle prestazioni, la latenza WAN non influirà sugli aggiornamenti sul cluster attivo. Questi vengono spediti in modo asincrono al sito di backup.
Come nota a margine, è anche possibile avere un'istanza slave dedicata come relè di replica invece di utilizzare uno dei nodi Galera come slave.
Procedura di failover del nodo Galera
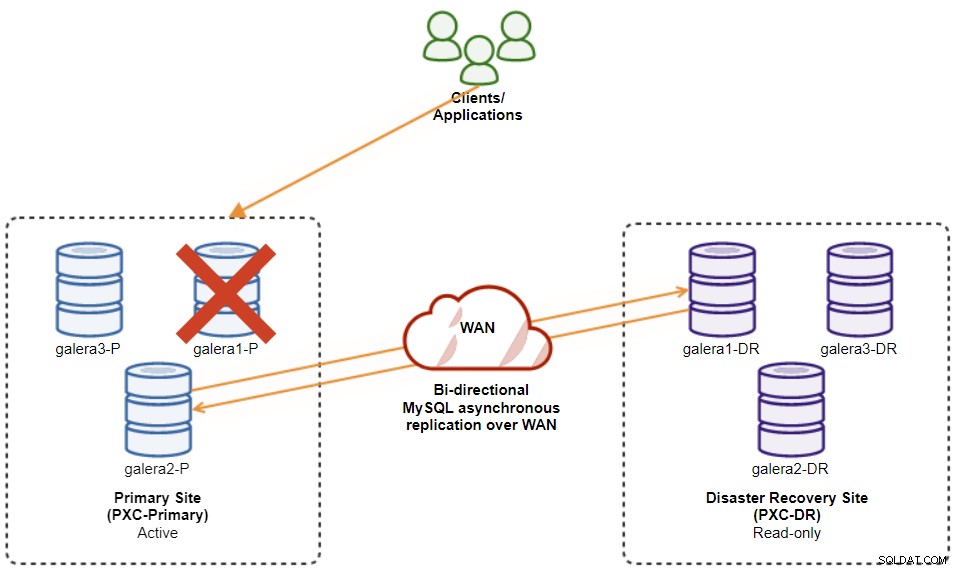
Nel caso in cui il master corrente (galera1-P) si guasta e i nodi rimanenti nel sito primario siano ancora attivi, lo slave sul sito di Disaster Recovery (galera1-DR) dovrebbe essere indirizzato a qualsiasi master disponibile sul Sito principale, come mostrato nel diagramma seguente:
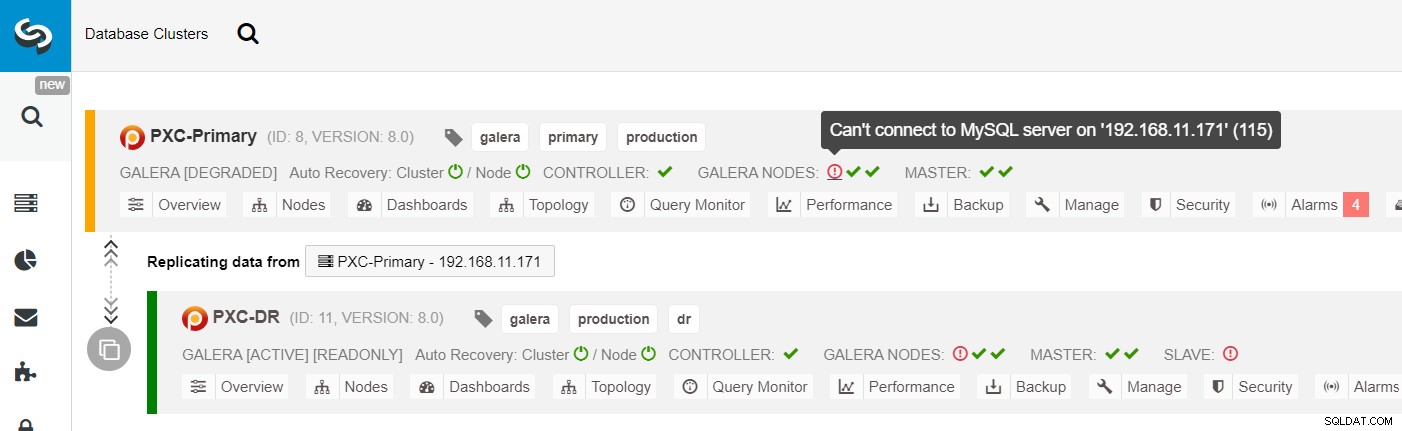
Dall'elenco dei cluster ClusterControl, puoi vedere che lo stato del cluster è degradato e se passi il mouse sull'icona del punto esclamativo, puoi vedere l'errore per quel particolare nodo (galera1-P):
Con ClusterControl, puoi semplicemente andare su PXC-DR cluster → Nodes → pick galera1-DR → Node Actions → Rebuild Replication Slave e ti verrà presentata la seguente finestra di dialogo di configurazione:
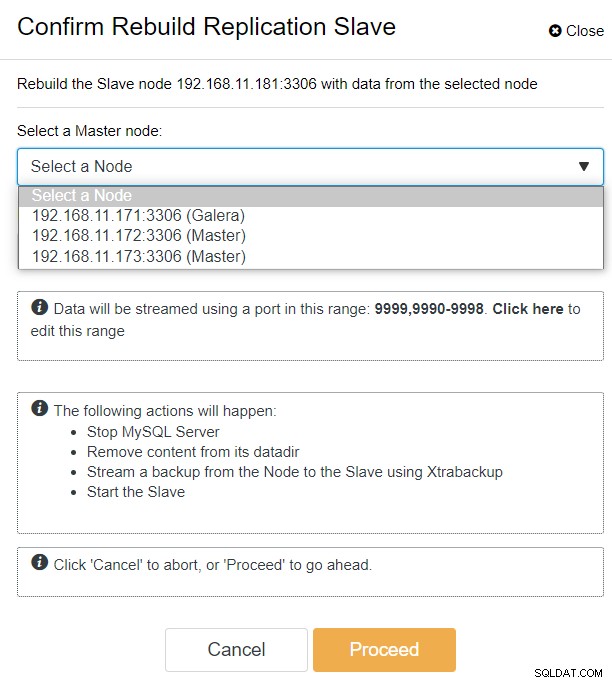
Possiamo vedere tutti i nodi Galera nel sito principale (192.168.11.17x ) dall'elenco a discesa. Scegli il nodo secondario, 192.168.11.172 (galera2-P), e fai clic su Procedi. ClusterControl configurerà quindi la topologia di replica come dovrebbe essere, impostando la replica bidirezionale da galera2-P a galera1-DR. Puoi confermarlo dalla pagina dashboard del cluster (evidenziata in giallo):
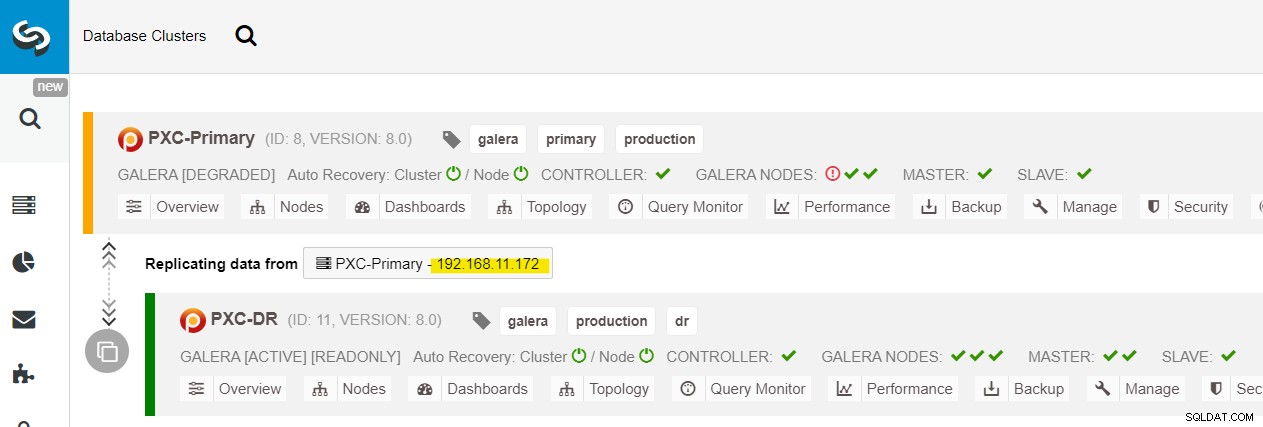
A questo punto, il cluster primario (PXC-Primary) è ancora in servizio come cluster attivo per questa topologia. Non dovrebbe influire sul tempo di attività del servizio database del cluster primario.
Procedura di failover del cluster Galera
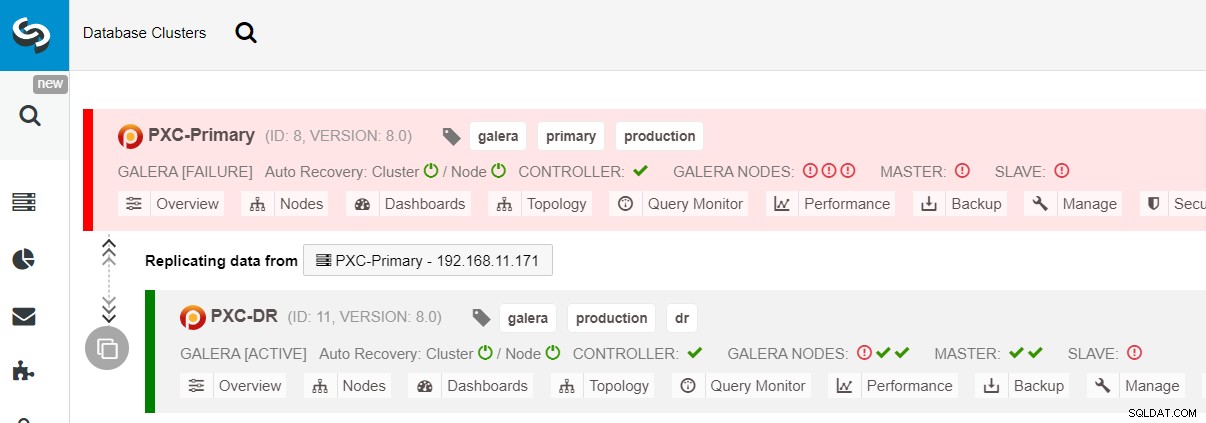
Se il cluster primario si interrompe, si arresta in modo anomalo o semplicemente perde la connettività dal punto di vista dell'applicazione, l'applicazione può essere indirizzata al sito DR quasi istantaneamente. SysAdmin deve semplicemente disabilitare la sola lettura su tutti i nodi Galera nel sito di ripristino di emergenza utilizzando la seguente istruzione:
mysql> SET GLOBAL read_only = 0; -- repeat on galera1-DR, galera2-DR, galera3-DRPer gli utenti ClusterControl, è possibile utilizzare ClusterControl UI → Nodi → selezionare il nodo DB → Azioni nodo → Disattiva sola lettura. ClusterControl CLI è inoltre disponibile, eseguendo i seguenti comandi sul nodo ClusterControl:
$ s9s node --nodes="192.168.11.181" --cluster-id=11 --set-read-write
$ s9s node --nodes="192.168.11.182" --cluster-id=11 --set-read-write
$ s9s node --nodes="192.168.11.183" --cluster-id=11 --set-read-writeIl failover al sito DR è ora completo e le applicazioni possono iniziare a inviare scritture al cluster PXC-DR. Dall'interfaccia utente di ClusterControl, dovresti vedere qualcosa di simile a questo:
Il diagramma seguente mostra la nostra architettura dopo il failover dell'applicazione nel sito DR :
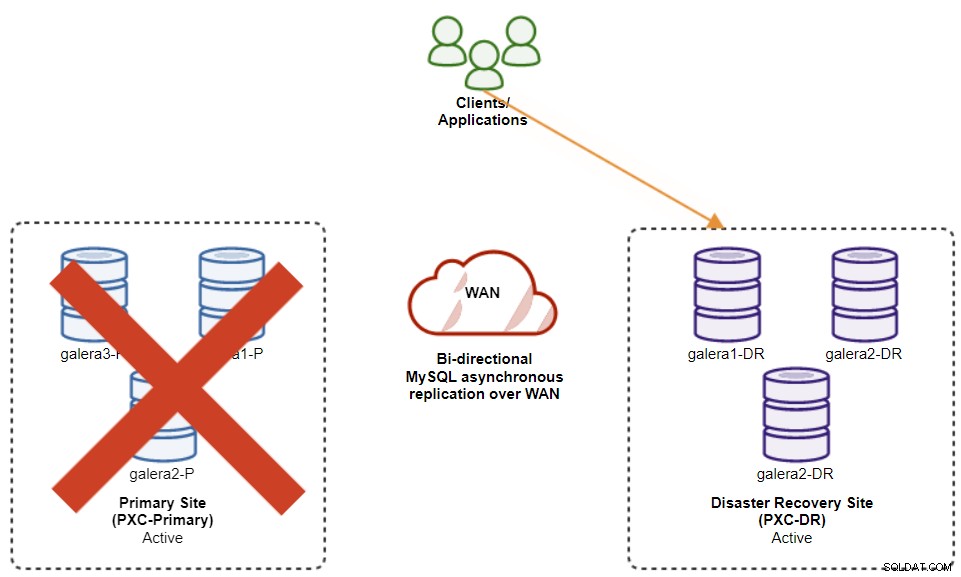
Supponendo che il sito principale sia ancora inattivo, a questo punto non c'è replica tra siti fino al ripristino del sito principale.
Procedura di failback del cluster Galera
Dopo che è stato visualizzato il sito principale, è importante notare che il cluster primario deve essere impostato su sola lettura, quindi sappiamo che il cluster attivo è quello nel sito di ripristino di emergenza. Da ClusterControl, vai al menu a discesa del cluster e scegli "Abilita sola lettura", che abiliterà la sola lettura su tutti i nodi nel cluster primario e riassume la topologia corrente come segue:
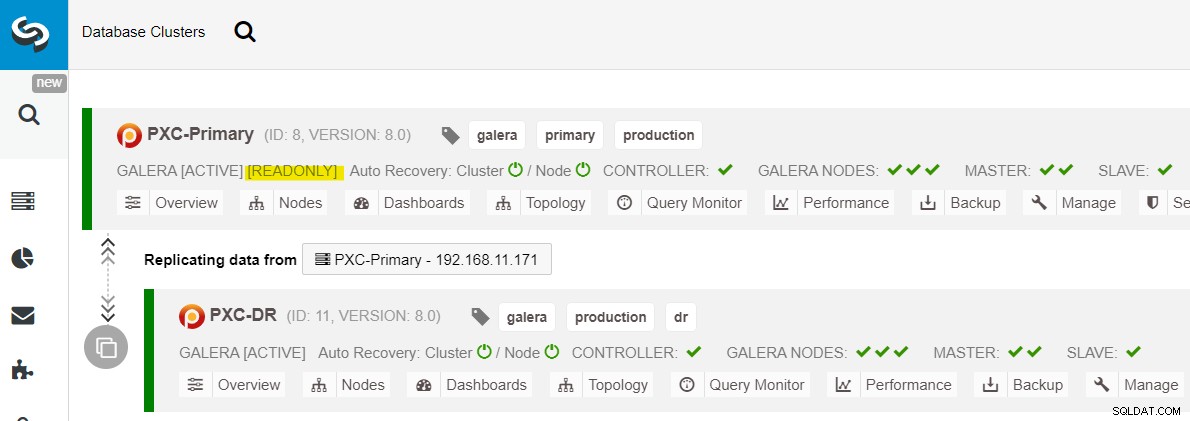
Assicurati che tutto sia verde prima di pianificare l'avvio della procedura di failback del cluster (verde significa che tutti i nodi sono attivi e sincronizzati tra loro). Se è presente un nodo in stato di degrado, ad esempio, il nodo di replica è ancora in ritardo o solo alcuni dei nodi del cluster primario erano raggiungibili, attendere che il cluster sia completamente ripristinato, o attendendo le procedure di ripristino automatico di ClusterControl da completare, o intervento manuale.
A questo punto, il cluster attivo è ancora il cluster del DR e il cluster primario funge da cluster secondario. Il diagramma seguente illustra l'architettura attuale:
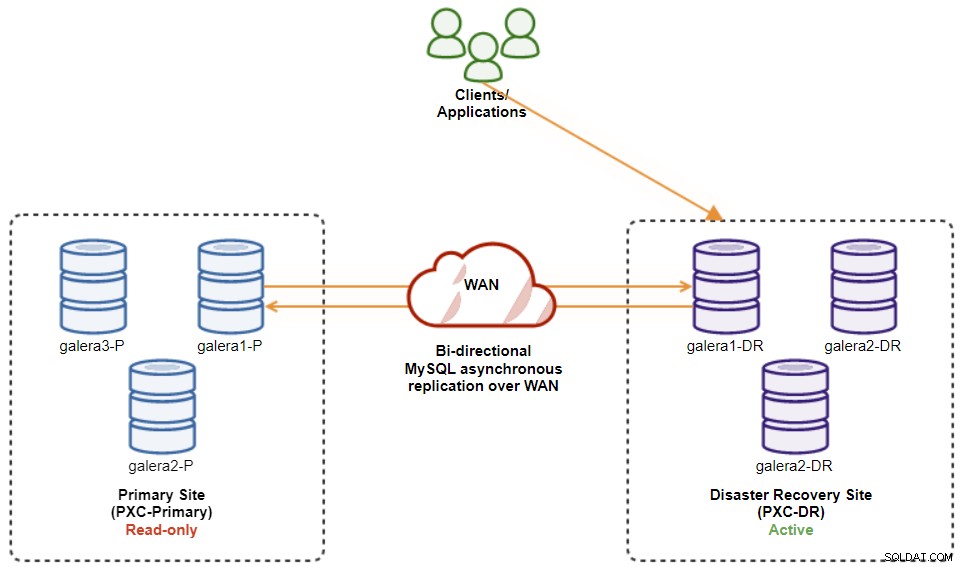
Il modo più sicuro per eseguire il failback sul sito principale è impostare la sola lettura nel cluster di DR, seguito dalla disabilitazione della sola lettura sul sito primario. Vai a ClusterControl UI → PXC-DR (menu a discesa) → Abilita sola lettura. Ciò attiverà un processo per impostare la sola lettura su tutti i nodi nel cluster di DR. Quindi, vai a ClusterControl UI → PXC-Primary → Nodes e disabilita la sola lettura su tutti i nodi del database nel cluster primario.
Puoi anche semplificare le procedure di cui sopra con ClusterControl CLI. In alternativa, eseguire i seguenti comandi sull'host ClusterControl:
$ s9s cluster --cluster-id=11 --set-read-only # enable cluster-wide read-only
$ s9s node --nodes="192.168.11.171" --cluster-id=8 --set-read-write
$ s9s node --nodes="192.168.11.172" --cluster-id=8 --set-read-write
$ s9s node --nodes="192.168.11.173" --cluster-id=8 --set-read-writeAl termine, la direzione della replica è tornata alla configurazione originale, dove PXC-Primary è il cluster attivo e PXC-DR è il cluster di standby. Il diagramma seguente illustra l'architettura finale dopo l'operazione di failback del cluster:
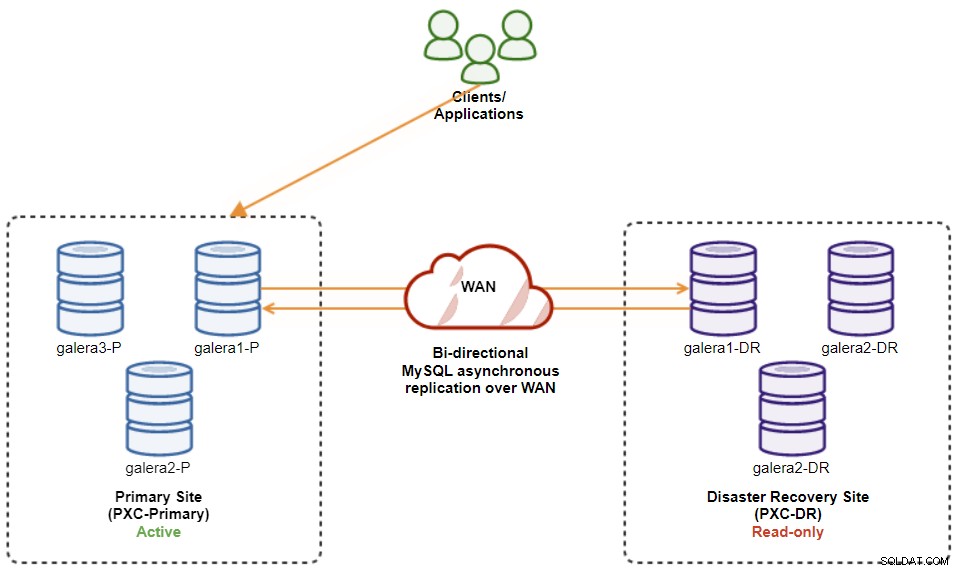
A questo punto, ora è possibile reindirizzare le applicazioni su cui scrivere il sito principale.
Vantaggi della replica asincrona da cluster a cluster
Il cluster-to-cluster con la replica asincrona presenta una serie di vantaggi:
-
Tempo di inattività minimo durante un'operazione di failover del database. Fondamentalmente, puoi reindirizzare la scrittura quasi istantaneamente al sito slave, solo se puoi proteggere le scritture per non raggiungere il sito master (poiché queste scritture non verrebbero replicate e probabilmente verranno sovrascritte durante la risincronizzazione dal sito DR).
-
Nessun impatto sulle prestazioni del sito principale poiché è indipendente dal sito di backup (DR). La replica da master a slave viene eseguita in modo asincrono. Il sito master genera log binari, il sito slave replica gli eventi e applica gli eventi in un secondo momento.
-
I siti di ripristino di emergenza possono essere utilizzati per altri scopi, ad esempio backup di database, backup di log binari e reportistica, o query analitiche pesanti (OLAP). Entrambi i siti possono essere utilizzati contemporaneamente, ad eccezione del ritardo di replica e delle operazioni di sola lettura sul lato slave.
-
Il cluster di ripristino di emergenza potrebbe potenzialmente essere eseguito su istanze più piccole in un ambiente cloud pubblico, purché possano tenere il passo con il cluster primario. È possibile aggiornare le istanze se necessario. In alcuni scenari, può farti risparmiare alcuni costi.
-
È necessario un solo sito aggiuntivo per il ripristino di emergenza rispetto alla configurazione di replica multisito Galera attiva-attiva, che richiede almeno tre siti attivi per funzionare correttamente.
Svantaggi della replica asincrona da cluster a cluster
Ci sono anche degli svantaggi in questa configurazione, a seconda che tu stia utilizzando la replica bidirezionale o unidirezionale:
-
C'è la possibilità di perdere alcuni dati durante il failover se lo slave era indietro, poiché la replica è asincrona. Questo potrebbe essere migliorato con la replica degli slave semi-sincrona e multi-thread, anche se ci sarà un'altra serie di sfide in attesa (overhead della rete, gap di replica, ecc.).
-
Nella replica unidirezionale, nonostante le procedure di failover siano abbastanza semplici, le procedure di failback possono essere complicate e soggette a errore. Richiede una certa esperienza sul passaggio del ruolo master/slave al sito principale. Si consiglia di mantenere le procedure documentate, provare regolarmente l'operazione di failover/failback e utilizzare strumenti di reporting e monitoraggio accurati.
-
Può essere piuttosto costoso, poiché devi configurare un numero simile di nodi sul sito di ripristino di emergenza . Questo non è in bianco e nero, poiché la giustificazione dei costi di solito deriva dai requisiti della tua attività. Con un po' di pianificazione, è possibile massimizzare l'utilizzo delle risorse del database in entrambi i siti, indipendentemente dai ruoli del database.
Conclusione
La configurazione della replica asincrona per i cluster MySQL Galera può essere un processo relativamente semplice, a patto di comprendere come gestire correttamente gli errori sia a livello di nodo che di cluster. In definitiva, le operazioni di failover e failback sono fondamentali per garantire l'integrità dei dati.
Per ulteriori suggerimenti sulla progettazione dei cluster Galera tenendo conto delle strategie di failover e failback, consulta questo post sulle architetture MySQL per il ripristino di emergenza. Se stai cercando aiuto per automatizzare queste operazioni, valuta ClusterControl gratuitamente per 30 giorni e segui i passaggi in questo post.
Non dimenticare di seguirci su Twitter o LinkedIn e iscriviti alla nostra newsletter per essere aggiornato sulle ultime novità e sulle best practice per la gestione delle tue infrastrutture di database open source.