Nel mio post precedente ho spiegato come fare un backup logico usando le utilità della shell mysql. In questo post, confronteremo la velocità del processo di backup e ripristino.
Test di velocità della shell MySQL
Faremo un confronto tra la velocità di backup e ripristino di mysqldump e gli strumenti di utilità della shell MySQL.
Di seguito vengono utilizzati gli strumenti per il confronto della velocità:
- mysqldump
- util.dumpInstance
- util.loadDump
Configurazione hardware
Due server standalone con configurazioni identiche.
Server 1
* IP:192.168.33.14
* CPU:2 core
* RAM:4 GB
* DISCO:SSD da 200 GB
Server 2
* IP:192.168.33.15
* CPU:2 core
* RAM:4 GB
* DISCO:SSD da 200 GB
Preparazione del carico di lavoro
Sul server 1 (192.168.33.14), abbiamo caricato circa 10 GB di dati.
Ora, vogliamo ripristinare i dati dal Server 1 (192.168.33.14) al Server 2 (192.168.33.15).
Impostazione MySQL
Versione MySQL:8.0.22
Dimensioni del pool di buffer InnoDB:1 GB
Dimensione del file di registro di InnoDB:16 MB
Registrazione binaria:attivata
Abbiamo caricato 50 milioni di record utilizzando sysbench.
[example@sqldat.com sysbench]# sysbench oltp_insert.lua --table-size=5000000 --num-threads=8 --rand-type=uniform --db-driver=mysql --mysql-db=sbtest --tables=10 --mysql-user=root --mysql-password=****** prepare
WARNING: --num-threads is deprecated, use --threads instead
sysbench 1.0.20 (using bundled LuaJIT 2.1.0-beta2)
Initializing worker threads...
Creating table 'sbtest3'...
Creating table 'sbtest4'...
Creating table 'sbtest7'...
Creating table 'sbtest1'...
Creating table 'sbtest2'...
Creating table 'sbtest8'...
Creating table 'sbtest5'...
Creating table 'sbtest6'...
Inserting 5000000 records into 'sbtest1'
Inserting 5000000 records into 'sbtest3'
Inserting 5000000 records into 'sbtest7
.
.
.
Creating a secondary index on 'sbtest9'...
Creating a secondary index on 'sbtest10'...Caso di prova uno
In questo caso faremo un backup logico usando il comando mysqldump.
Esempio
[example@sqldat.com vagrant]# time /usr/bin/mysqldump --defaults-file=/etc/my.cnf --flush-privileges --hex-blob --opt --master-data=2 --single-transaction --triggers --routines --events --set-gtid-purged=OFF --all-databases |gzip -6 -c > /home/vagrant/test/mysqldump_schemaanddata.sql.gzora_inizio =09-11-2020 17:40:02
ora_fine =09-11-2020 37:19:08
Ci sono voluti quasi 20 minuti e 19 secondi per eseguire un dump di tutti i database con una dimensione totale di circa 10 GB.
Caso di prova due
Ora proviamo con l'utilità della shell MySQL. Useremo dumpInstance per eseguire un backup completo.
Esempio
MySQL localhost:33060+ ssl JS > util.dumpInstance("/home/vagrant/production_backup", {threads: 2, ocimds: true,compatibility: ["strip_restricted_grants"]})
Acquiring global read lock
Global read lock acquired
All transactions have been started
Locking instance for backup
Global read lock has been released
Checking for compatibility with MySQL Database Service 8.0.22
NOTE: Progress information uses estimated values and may not be accurate.
Data dump for table `sbtest`.`sbtest1` will be written to 38 files
Data dump for table `sbtest`.`sbtest10` will be written to 38 files
Data dump for table `sbtest`.`sbtest3` will be written to 38 files
Data dump for table `sbtest`.`sbtest2` will be written to 38 files
Data dump for table `sbtest`.`sbtest4` will be written to 38 files
Data dump for table `sbtest`.`sbtest5` will be written to 38 files
Data dump for table `sbtest`.`sbtest6` will be written to 38 files
Data dump for table `sbtest`.`sbtest7` will be written to 38 files
Data dump for table `sbtest`.`sbtest8` will be written to 38 files
Data dump for table `sbtest`.`sbtest9` will be written to 38 files
2 thds dumping - 36% (17.74M rows / ~48.14M rows), 570.93K rows/s, 111.78 MB/s uncompressed, 50.32 MB/s compressed
1 thds dumping - 100% (50.00M rows / ~48.14M rows), 587.61K rows/s, 115.04 MB/s uncompressed, 51.79 MB/s compressed
Duration: 00:01:27s
Schemas dumped: 3
Tables dumped: 10
Uncompressed data size: 9.78 GB
Compressed data size: 4.41 GB
Compression ratio: 2.2
Rows written: 50000000
Bytes written: 4.41 GB
Average uncompressed throughput: 111.86 MB/s
Average compressed throughput: 50.44 MB/s Ci sono voluti un totale di 1 minuto e 27 secondi per eseguire un dump dell'intero database (gli stessi dati usati per mysqldump) e mostra anche i suoi progressi, il che sarà davvero utile per sapere quanta parte del backup è stata completata. Fornisce il tempo necessario per eseguire il backup.
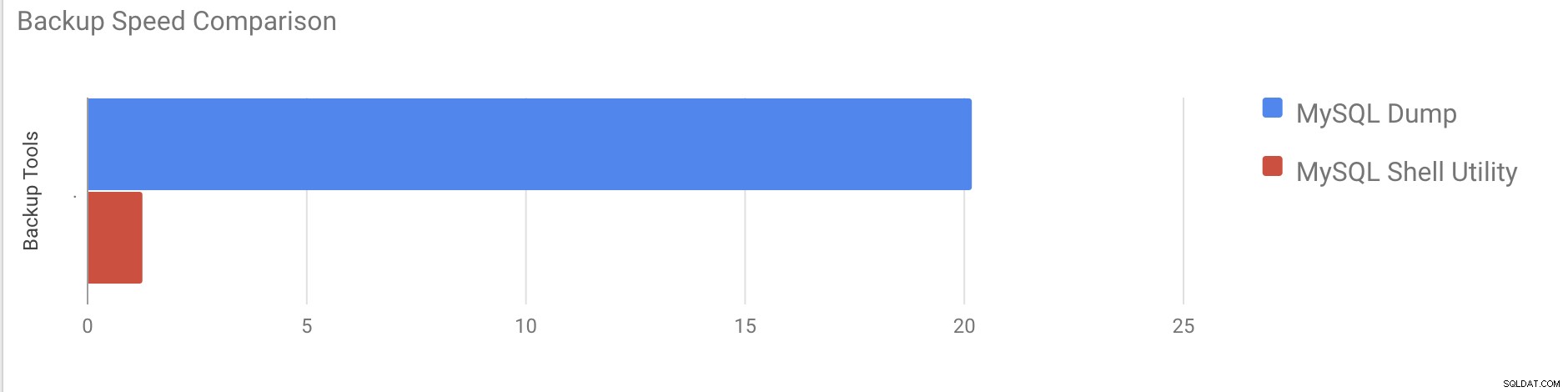
Il parallelismo dipende dal numero di core nel server. Aumentare approssimativamente il valore non sarà utile nel mio caso. (La mia macchina ha 2 core).
Test di velocità del restauro
Nella parte di ripristino, ripristineremo il backup di mysqldump su un altro server autonomo. Il file di backup è stato già spostato sul server di destinazione utilizzando rsync.
Caso di prova 1
Esempio
[example@sqldat.com vagrant]#time gunzip < /mnt/mysqldump_schemaanddata.sql.gz | mysql -u root -pCi sono voluti circa 16 minuti e 26 secondi per ripristinare i 10 GB di dati.
Caso di prova 2
In questo caso stiamo usando l'utilità della shell mysql per caricare il file di backup su un altro host autonomo. Abbiamo già spostato il file di backup sul server di destinazione. Iniziamo il processo di ripristino.
Esempio
MySQL localhost:33060+ ssl JS > util.loadDump("/home/vagrant/production_backup", {progressFile :"/home/vagrant/production_backup/log.json",threads :2})
Opening dump...
Target is MySQL 8.0.22. Dump was produced from MySQL 8.0.22
Checking for pre-existing objects...
Executing common preamble SQL
Executing DDL script for schema `cluster_control`
Executing DDL script for schema `proxydemo`
Executing DDL script for schema `sbtest`
.
.
.
2 thds loading \ 1% (150.66 MB / 9.78 GB), 6.74 MB/s, 4 / 10 tables done
2 thds loading / 100% (9.79 GB / 9.79 GB), 1.29 MB/s, 10 / 10 tables done
[Worker001] example@sqldat.com@@37.tsv.zst: Records: 131614 Deleted: 0 Skipped: 0 Warnings: 0
[Worker002] example@sqldat.com@@37.tsv.zst: Records: 131614 Deleted: 0 Skipped: 0 Warnings: 0
Executing common postamble SQL
380 chunks (50.00M rows, 9.79 GB) for 10 tables in 2 schemas were loaded in 40 min 6 sec (avg throughput 4.06 MB/s)Ci sono voluti circa 40 minuti e 6 secondi per ripristinare i 10 GB di dati.
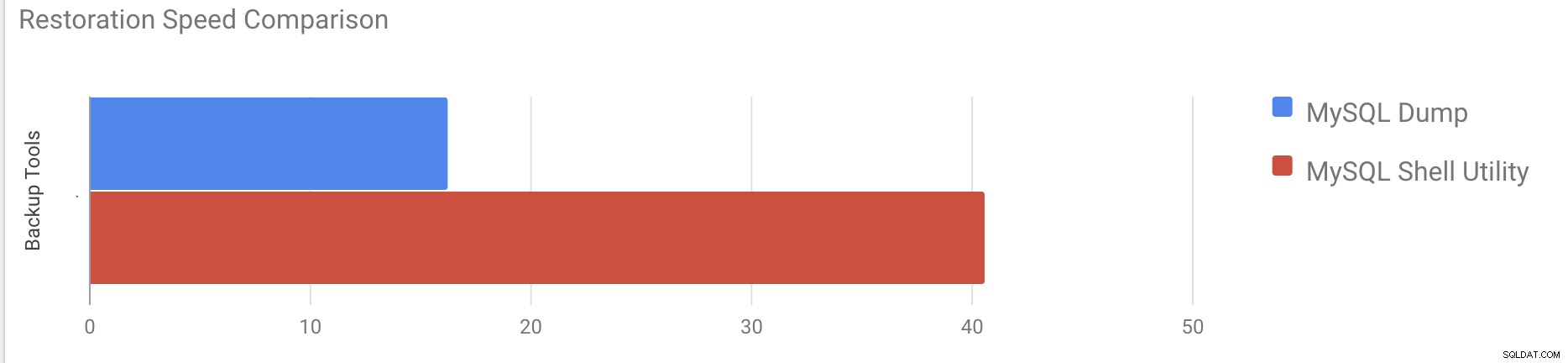
Ora proviamo a disabilitare il redo log e ad avviare l'importazione dei dati tramite mysql utilità della shell.
mysql> alter instance disable innodb redo_log;
Query OK, 0 rows affected (0.00 sec)
MySQL localhost:33060+ ssl JS >util.loadDump("/home/vagrant/production_backup", {progressFile :"/home/vagrant/production_backup/log.json",threads :2})
Opening dump...
Target is MySQL 8.0.22. Dump was produced from MySQL 8.0.22
Checking for pre-existing objects...
Executing common preamble SQL
.
.
.
380 chunks (50.00M rows, 9.79 GB) for 10 tables in 3 schemas were loaded in 19 min 56 sec (avg throughput 8.19 MB/s)
0 warnings were reported during the load.Dopo aver disabilitato il log di ripristino, il throughput medio è stato aumentato fino a 2 volte.
Nota:non disabilitare la registrazione di ripristino su un sistema di produzione. Consente l'arresto e il riavvio del server mentre la registrazione di ripetizione è disabilitata, ma un arresto imprevisto del server mentre la registrazione di ripetizione è disabilitata può causare la perdita di dati e il danneggiamento dell'istanza.
Backup fisici
Come avrai notato, i metodi di backup logici, anche se multithread, richiedono molto tempo anche per un piccolo set di dati con cui li abbiamo testati. Questo è uno dei motivi per cui ClusterControl fornisce un metodo di backup fisico basato sulla copia dei file - in tal caso non siamo limitati dal livello SQL che elabora il backup logico ma piuttosto dall'hardware - quanto velocemente il disco può leggere i file e la velocità con cui la rete può trasferire i dati tra il nodo del database e il server di backup.
ClusterControl viene fornito con diversi modi per implementare i backup fisici, il metodo disponibile dipenderà dal tipo di cluster e talvolta anche dal fornitore. Diamo un'occhiata all'Xtrabackup eseguito da ClusterControl che creerà un backup completo dei dati nel nostro ambiente di test.
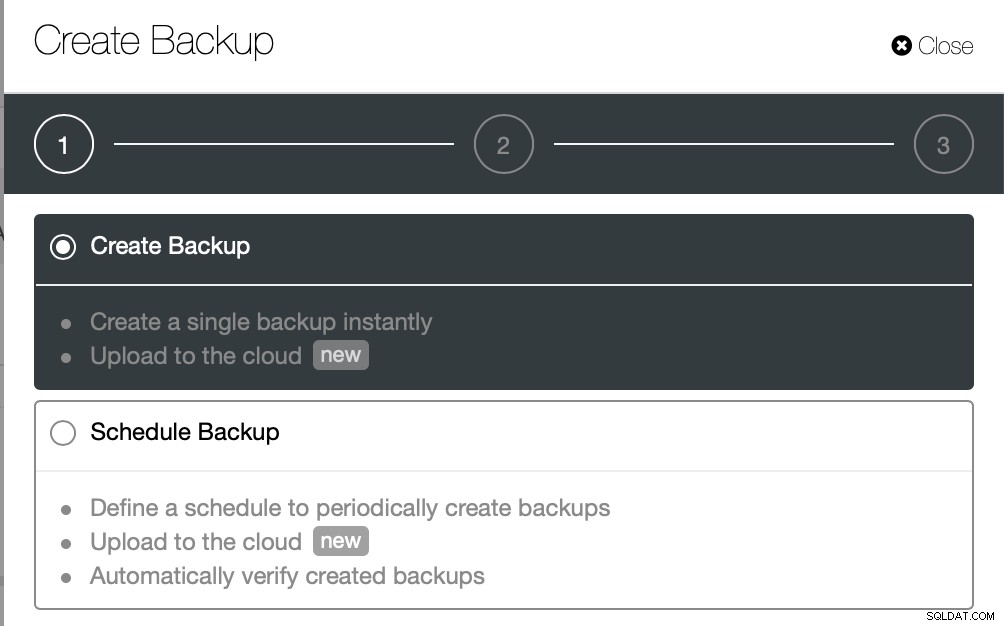
Questa volta creeremo un backup ad hoc ma ClusterControl consente crei anche una pianificazione di backup completa.
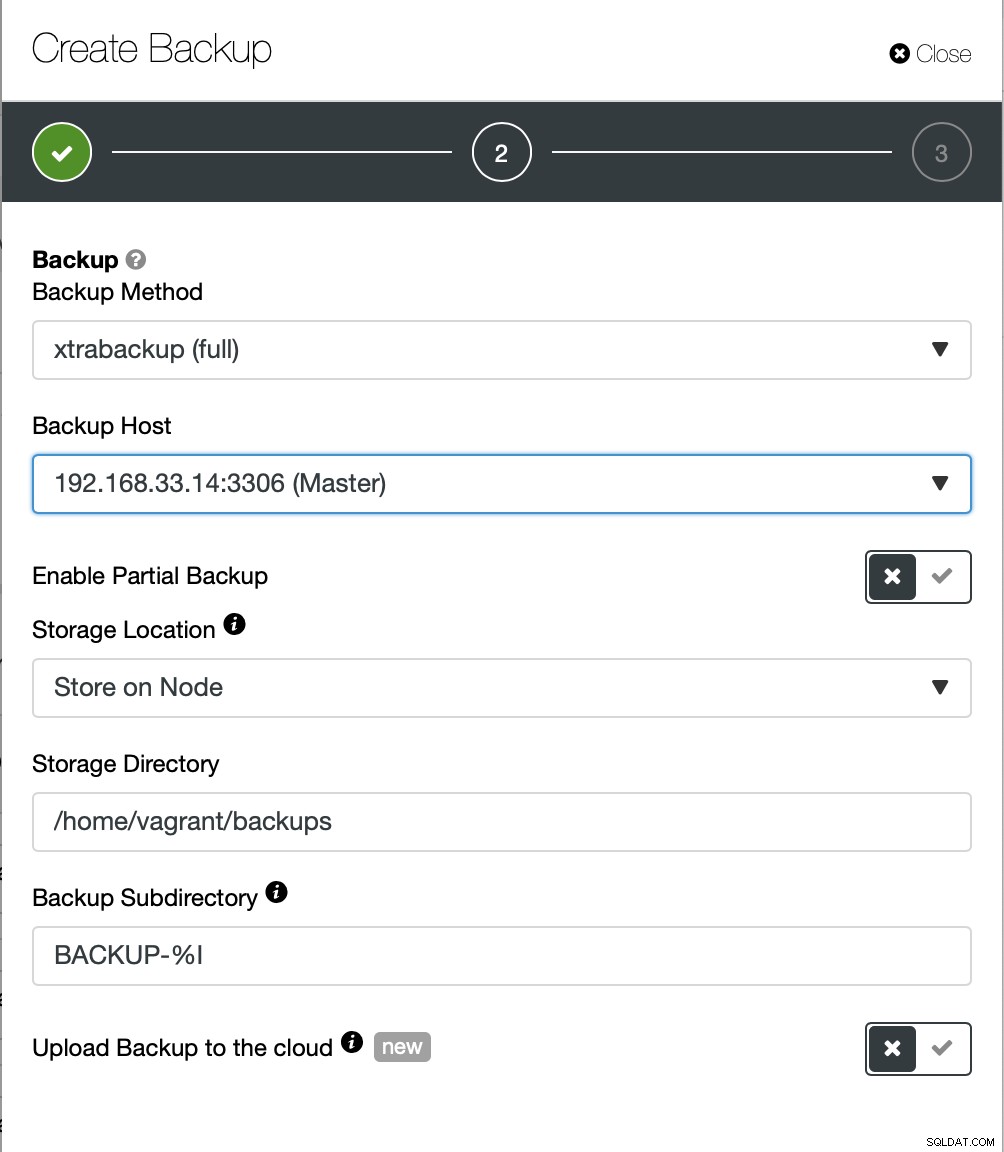
Qui scegliamo il metodo di backup (xtrabackup) e l'host che prenderanno il backup da. Possiamo anche archiviarlo localmente sul nodo o può essere trasmesso in streaming a un'istanza ClusterControl. Inoltre, puoi caricare il backup nel cloud (sono supportati AWS, Google Cloud e Azure).
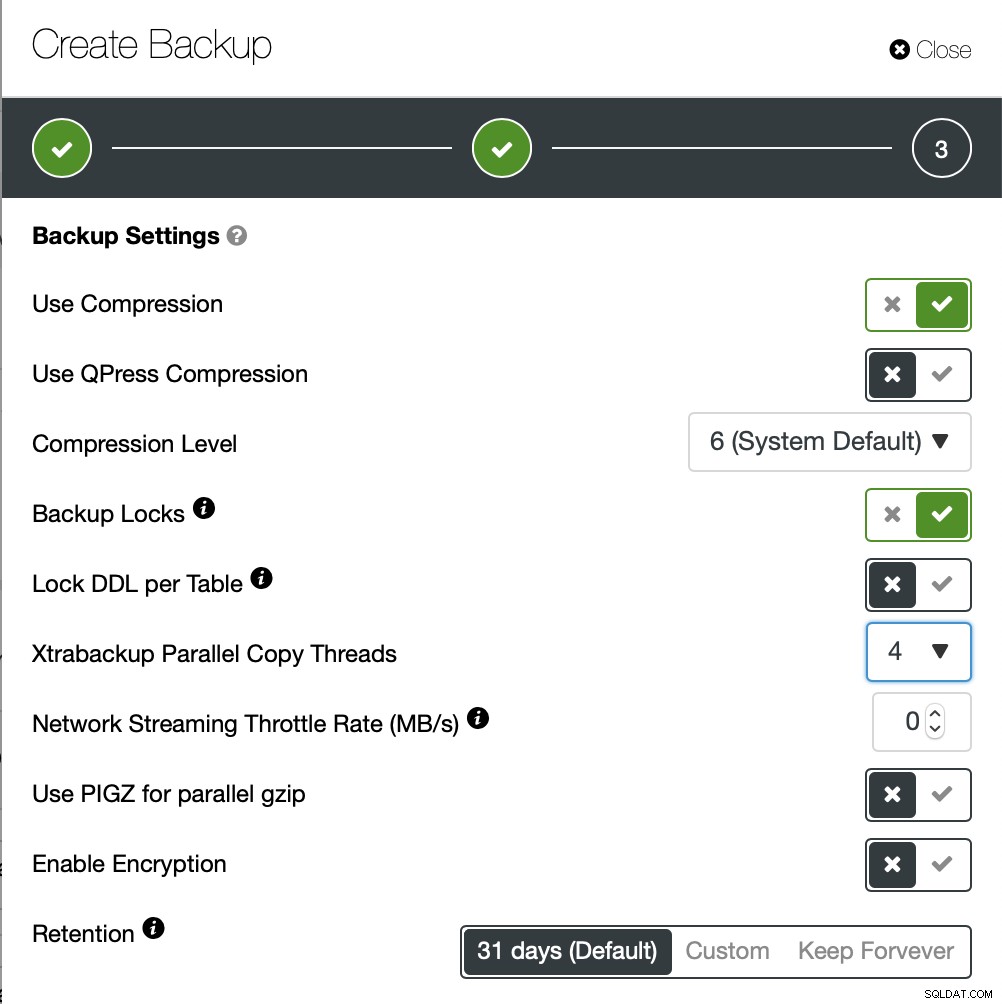
Il completamento del backup ha richiesto circa 10 minuti. Qui i log del file cmon_backup.metadata.
[example@sqldat.com BACKUP-9]# cat cmon_backup.metadata
{
"class_name": "CmonBackupRecord",
"backup_host": "192.168.33.14",
"backup_tool_version": "2.4.21",
"compressed": true,
"created": "2020-11-17T23:37:15.000Z",
"created_by": "",
"db_vendor": "oracle",
"description": "",
"encrypted": false,
"encryption_md5": "",
"finished": "2020-11-17T23:47:47.681Z"
}Ora proviamo lo stesso per ripristinare utilizzando ClusterControl. ClusterControl> Backup> Ripristina backup
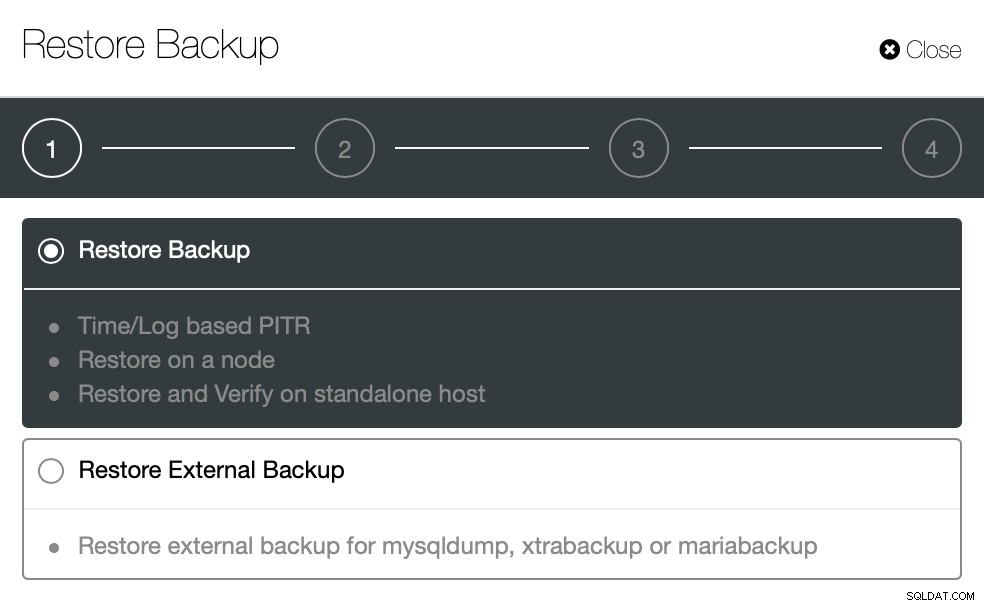
Qui scegliamo l'opzione di ripristino del backup, supporterà il tempo e il registro anche il recupero.
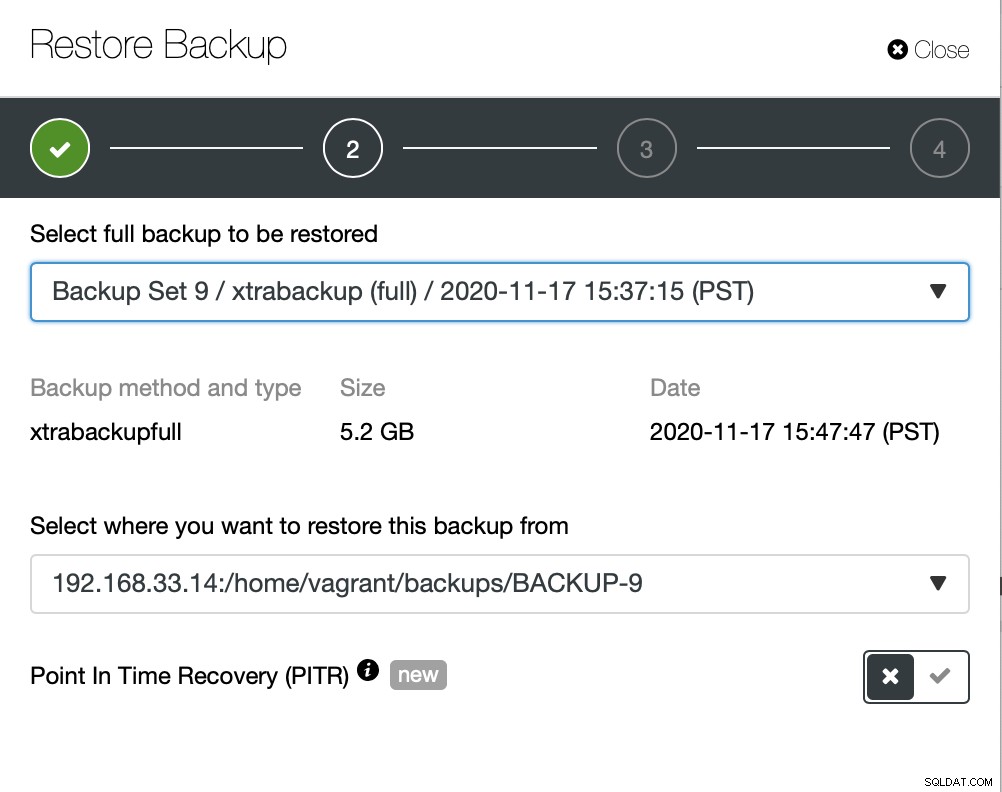
Qui scegliamo il percorso di origine del file di backup e quindi il server di destinazione. Devi anche assicurarti che questo host possa essere raggiunto dal nodo ClusterControl usando SSH.
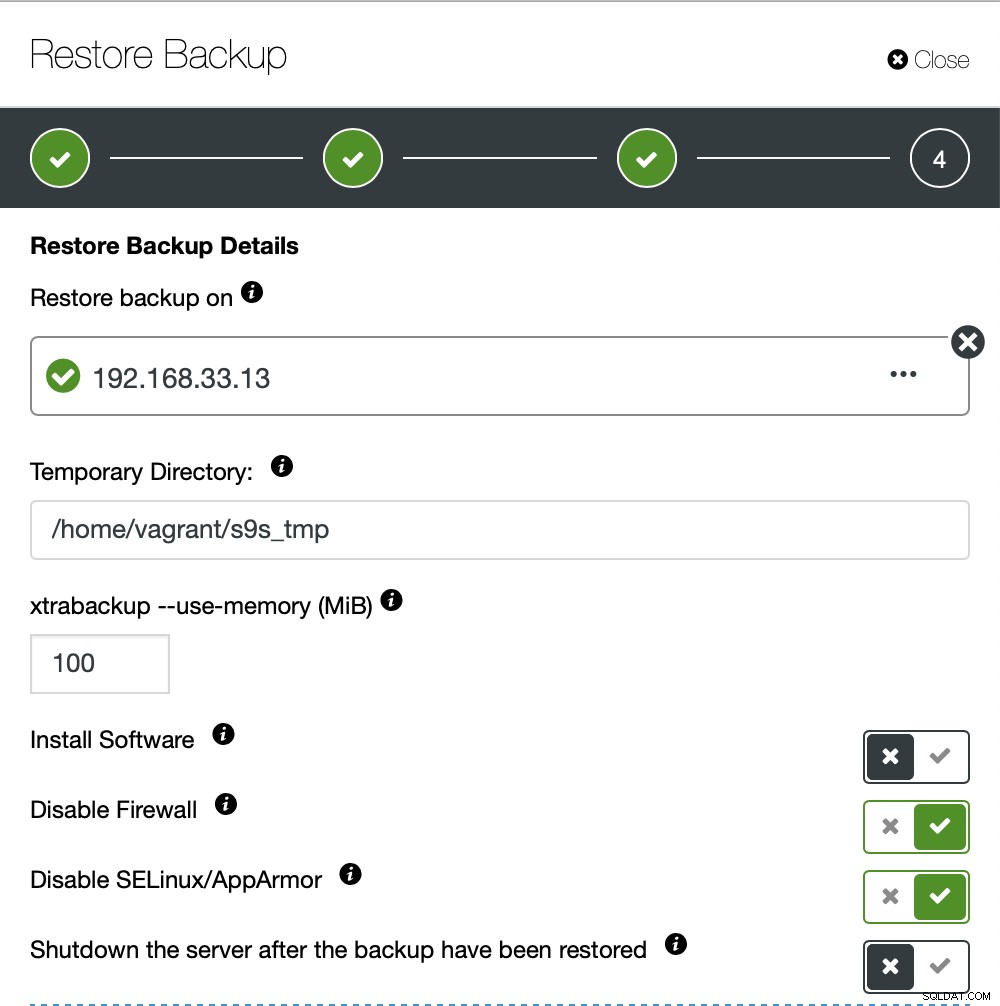
Non vogliamo che ClusterControl imposti il software, quindi abbiamo disabilitato questa opzione. Dopo il ripristino, manterrà il server in funzione.
Ci sono voluti circa 4 minuti e 18 secondi per ripristinare i 10 GB di dati. Xtrabackup non blocca il database durante il processo di backup. Per database di grandi dimensioni (oltre 100 GB), fornisce tempi di ripristino molto migliori rispetto all'utilità mysqldump/shell. Anche lustreControl supporta il backup e il ripristino parziali, come ha spiegato uno dei miei colleghi nel suo blog:Backup e ripristino parziali.
Conclusione
Ogni metodo ha i suoi pro e contro. Come abbiamo visto, non esiste un metodo che funzioni meglio per tutto ciò che devi fare. Dobbiamo scegliere il nostro strumento in base al nostro ambiente di produzione e fissare il tempo per il ripristino.