I sistemi di bilanciamento del carico sono un componente essenziale nell'elevata disponibilità del database; soprattutto quando si rendono trasparenti le modifiche alla topologia alle applicazioni e si implementa la funzionalità di divisione in lettura e scrittura. ClusterControl fornisce una serie di funzionalità per distribuire, monitorare e configurare in modo sicuro le tecnologie di bilanciamento del carico open source leader del settore.
Nell'ultimo anno abbiamo aggiunto il supporto per ProxySQL e molti miglioramenti per HAProxy e Maxscale di MariaDB. Continuiamo questa tradizione con l'ultima versione di ClusterControl 1.5.
Sulla base del feedback ricevuto dai nostri utenti, abbiamo migliorato la gestione di ProxySQL. Abbiamo anche aggiunto il supporto per HAProxy e Keepalived per l'esecuzione su cluster PostgreSQL.
In questo post del blog daremo un'occhiata a questi miglioramenti...
ProxySQL - Miglioramenti alla gestione degli utenti
In precedenza, l'interfaccia utente permetteva solo di creare un nuovo utente o aggiungerne uno esistente, uno alla volta. Un feedback che abbiamo ricevuto dai nostri utenti è stato che è piuttosto difficile gestire un gran numero di utenti. Abbiamo ascoltato e in ClusterControl 1.5 è ora possibile importare grandi batch di utenti. Diamo un'occhiata a come puoi farlo. Prima di tutto, devi avere il tuo ProxySQL distribuito. Quindi, vai al nodo ProxySQL e nella scheda Utenti dovresti vedere un pulsante "Importa utenti".

Dopo aver fatto clic su di esso, si aprirà una nuova finestra di dialogo:

Qui puoi vedere tutti gli utenti che ClusterControl ha rilevato sul tuo cluster. Puoi scorrerli e scegliere quelli che desideri importare. Puoi anche selezionare o deselezionare tutti gli utenti da una vista corrente.

Una volta che inizi a digitare nella casella Cerca, ClusterControl filtrerà i risultati non corrispondenti, restringendo l'elenco solo agli utenti rilevanti per la tua ricerca.
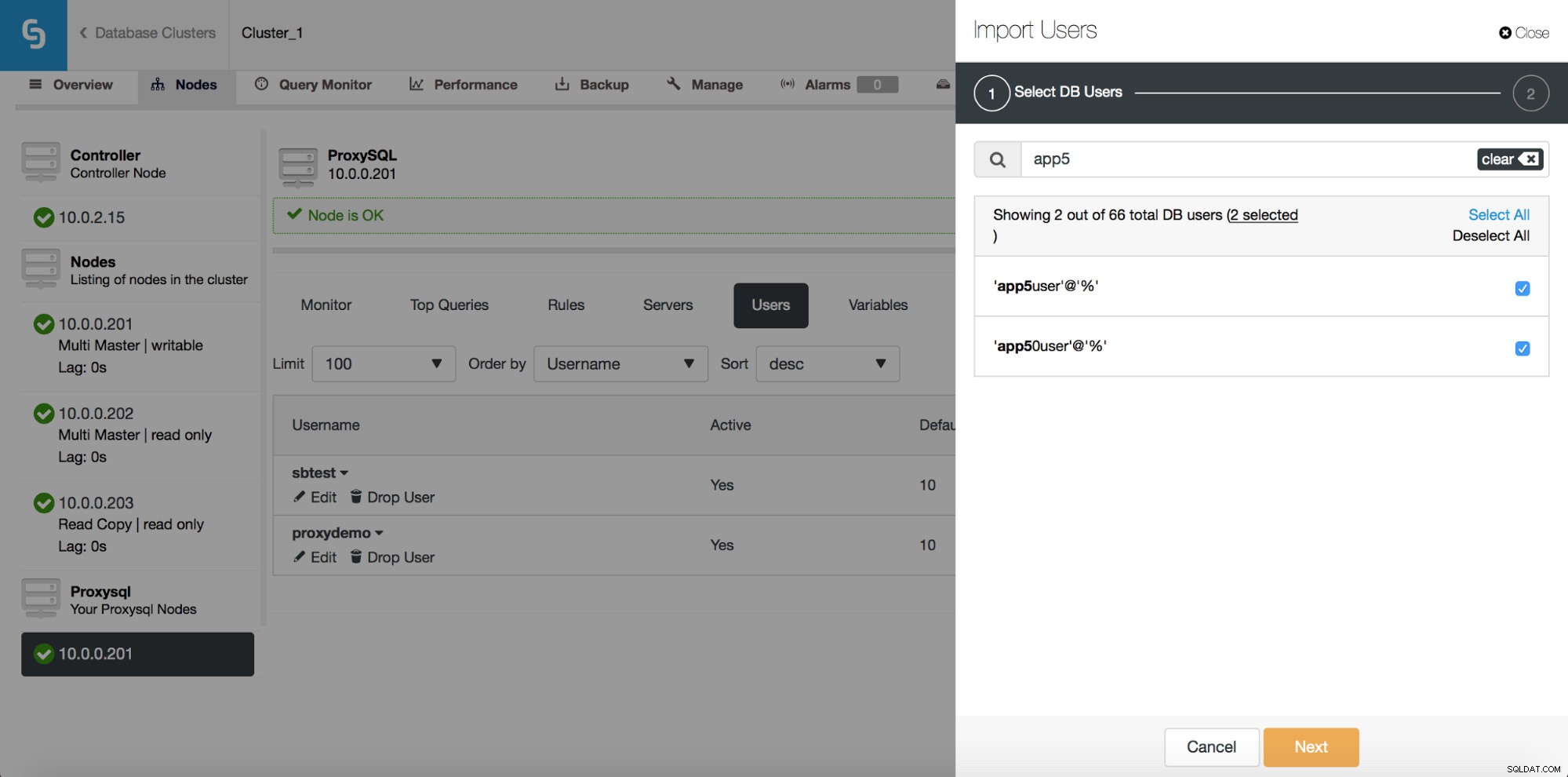
Puoi utilizzare il pulsante "Seleziona tutto" per selezionare tutti gli utenti che corrispondono alla tua ricerca. Ovviamente, dopo aver selezionato gli utenti che desideri importare, puoi deselezionare la casella di ricerca e iniziare un'altra ricerca:

Nota "(7 selezionati)" - ti dice quanti utenti, in totale (non solo da questa ricerca), hai selezionato per importare. Puoi anche fare clic su di esso per vedere solo gli utenti che hai selezionato per l'importazione.

Una volta che sei soddisfatto della tua scelta, puoi fare clic su "Avanti" per passare alla schermata successiva.

Qui devi decidere quale dovrebbe essere il gruppo host predefinito per ciascun utente. Puoi farlo in base all'utente o globalmente, per l'intero set o un sottoinsieme di utenti risultante da una ricerca.

Dopo aver fatto clic sul pulsante "Importa utenti", gli utenti verranno importati e verranno visualizzati nella scheda Utenti.
ProxySQL - Gestione dell'utilità di pianificazione
Lo scheduler di ProxySQL è un modulo simile a cron che consente a ProxySQL di avviare script esterni a intervalli regolari. La pianificazione può essere piuttosto granulare:fino a un'esecuzione ogni millisecondo. In genere, lo scheduler viene utilizzato per eseguire gli script di controllo Galera (come proxysql_galera_checker.sh), ma può anche essere utilizzato per eseguire qualsiasi altro script che ti piace. In passato, ClusterControl utilizzava lo scheduler per distribuire lo script di controllo Galera, ma questo non era esposto nell'interfaccia utente. A partire da ClusterControl 1.5, ora hai il pieno controllo.

Come puoi vedere, uno script è stato programmato per l'esecuzione ogni 2 secondi (2000 millisecondi):questa è la configurazione predefinita per il cluster Galera.

Lo screenshot sopra ci mostra le opzioni per modificare le voci esistenti. Tieni presente che ProxySQL supporta fino a 5 argomenti per gli script che eseguirà tramite lo scheduler.

Se desideri aggiungere un nuovo script allo scheduler, puoi fare clic sul pulsante "Aggiungi nuovo script" e ti verrà presentata una schermata come quella sopra. Puoi anche visualizzare in anteprima l'aspetto dello script completo una volta eseguito. Dopo aver compilato tutti i campi "Argomento" e definito l'intervallo, puoi fare clic sul pulsante "Aggiungi nuovo script".

Di conseguenza, uno script verrà aggiunto allo scheduler e sarà visibile nell'elenco degli script pianificati.
Scarica il whitepaper oggi Gestione e automazione di PostgreSQL con ClusterControlScopri ciò che devi sapere per distribuire, monitorare, gestire e ridimensionare PostgreSQLScarica il whitepaperPostgreSQL:creazione dello stack ad alta disponibilità
L'impostazione della replica con il failover automatico è buona, ma le applicazioni richiedono un modo semplice per tenere traccia del master scrivibile. Quindi abbiamo aggiunto il supporto per HAProxy e Keepalived in cima ai cluster PostgreSQL. Ciò consente ai nostri utenti PostgreSQL di distribuire uno stack completo ad alta disponibilità utilizzando ClusterControl.

Dalla sottoscheda Load Balancer, ora puoi distribuire HAProxy:se hai familiarità con come ClusterControl distribuisce la replica MySQL, è una configurazione molto simile. Installiamo HAProxy su un determinato host, due backend, legge sulla porta 3308 e scrive sulla porta 3307. Usa tcp-check, aspettandosi che una stringa particolare venga restituita. Per produrre quella stringa, i seguenti passaggi vengono eseguiti su tutti i nodi del database. Innanzitutto, xinet.d è configurato per eseguire un servizio sulla porta 9201 (per evitare confusione con la configurazione di MySQL, che utilizza la porta 9200).
# default: on
# description: postgreschk
service postgreschk
{
flags = REUSE
socket_type = stream
port = 9201
wait = no
user = root
server = /usr/local/sbin/postgreschk
log_on_failure += USERID
disable = no
#only_from = 0.0.0.0/0
only_from = 0.0.0.0/0
per_source = UNLIMITEDIl servizio esegue lo script /usr/local/sbin/postgreschk, che convalida lo stato di PostgreSQL e indica se un determinato host è disponibile e che tipo di host è (master o slave). Se tutto è a posto, restituisce la stringa attesa da HAProxy.
Proprio come con MySQL, i nodi HAProxy nei cluster PostgreSQL sono visualizzati nell'interfaccia utente ed è possibile accedere alla pagina di stato:

Qui puoi vedere entrambi i backend e verificare che solo il master sia attivo per il backend r/w e tutti i nodi siano accessibili tramite il backend di sola lettura. Puoi anche ottenere alcune statistiche sul traffico e sulle connessioni.
HAProxy aiuta a migliorare l'alta disponibilità, ma può diventare un singolo punto di errore. Dobbiamo fare il possibile e configurare la ridondanza con l'aiuto di Keepalived.

In Gestisci -> Bilanciatore del carico -> Keepalived, scegli gli host HAProxy che desideri utilizzare e Keepalived verrà distribuito su di essi con un IP virtuale collegato all'interfaccia di tua scelta.
D'ora in poi, tutta la connettività dovrebbe passare al VIP, che sarà collegato a uno dei nodi HAProxy. Se quel nodo si interrompe, Keepalived rimuoverà il VIP su quel nodo e lo porterà su un altro nodo HAProxy.
Questo è tutto per le funzionalità di bilanciamento del carico introdotte in ClusterControl 1.5. Provali e facci sapere come stai