Come abbiamo annunciato di recente, ClusterControl 1.7.4 ha una nuova funzionalità chiamata Replica da cluster a cluster. Ti consente di avere una replica in esecuzione tra due cluster autonomi. Per informazioni più dettagliate si rimanda al suddetto bando.
Deremo un'occhiata a come utilizzare questa nuova funzionalità per un cluster PostgreSQL esistente. Per questa attività, assumeremo che ClusterControl sia installato e che il cluster master sia stato distribuito utilizzandolo.
Requisiti per il Master Cluster
Ci sono alcuni requisiti per il Master Cluster per farlo funzionare:
- PostgreSQL 9.6 o successivo.
- Deve esserci un server PostgreSQL con il ruolo ClusterControl 'Master'.
- Quando si configura il Cluster Slave le credenziali di Admin devono essere identiche al Cluster Master.
Preparazione del cluster principale
Il Master Cluster deve soddisfare i requisiti sopra menzionati.
Riguardo al primo requisito, assicurati di utilizzare la versione PostgreSQL corretta nel Master Cluster e scegli la stessa cosa per il Cluster Slave.
$ psql
postgres=# select version();
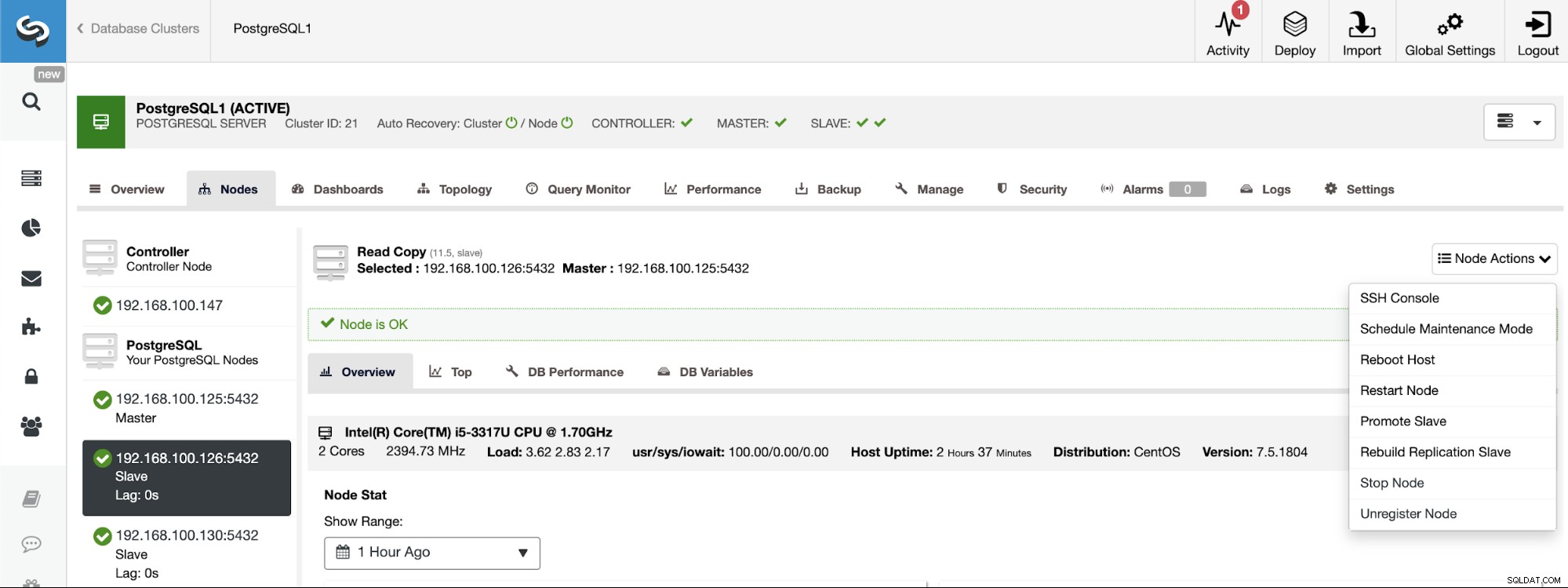
PostgreSQL 11.5 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-36), 64-bitSe è necessario assegnare il ruolo master a un nodo specifico, è possibile farlo dall'interfaccia utente di ClusterControl. Vai su ClusterControl -> Seleziona Master Cluster -> Nodi -> Seleziona il Nodo -> Azioni Nodo -> Promuovi Slave.
E infine, durante la creazione del Cluster Slave, devi utilizzare lo stesso admin credenziali attualmente in uso nel cluster master. Vedrai dove aggiungerlo nella sezione seguente.
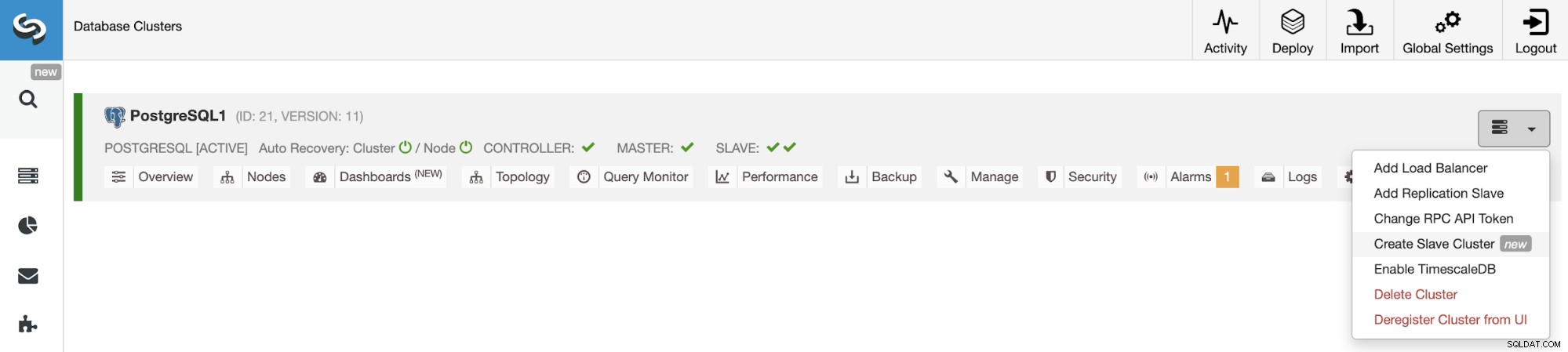
Creazione del cluster slave dall'interfaccia utente ClusterControl
Per creare un nuovo cluster slave, vai su ClusterControl -> Seleziona cluster -> Azioni cluster -> Crea cluster slave.
Il cluster slave verrà creato tramite lo streaming dei dati dal cluster master corrente.
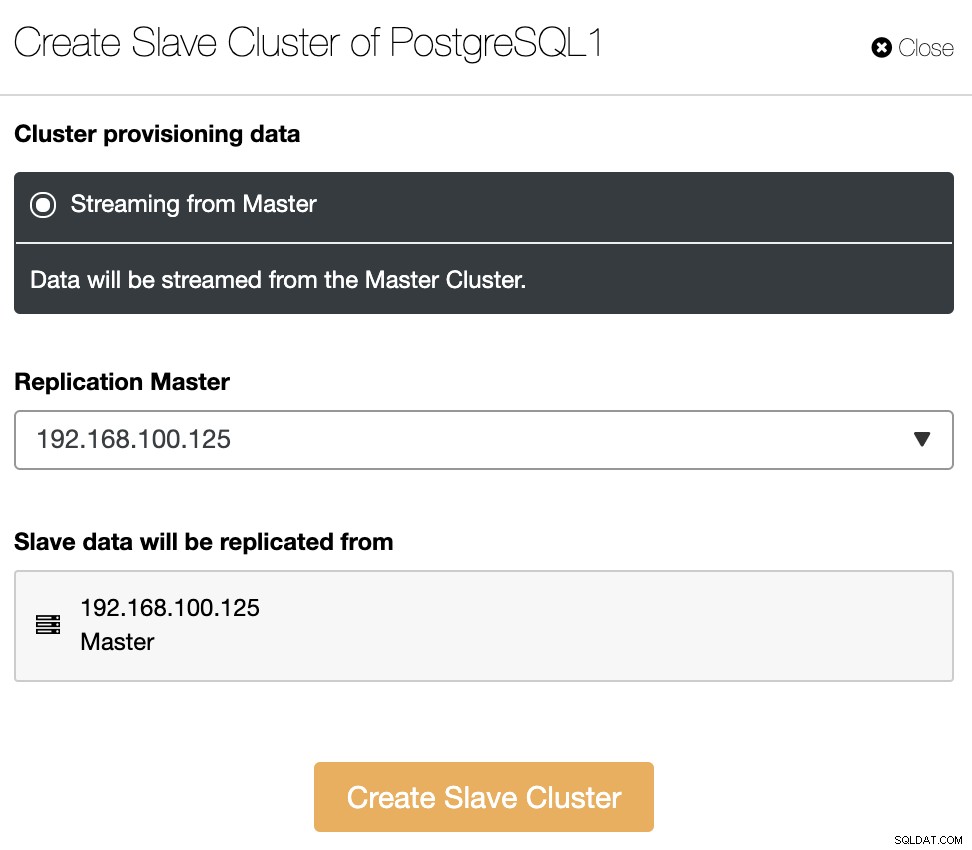
In questa sezione, devi anche scegliere il nodo master del cluster corrente da cui verranno replicati i dati.
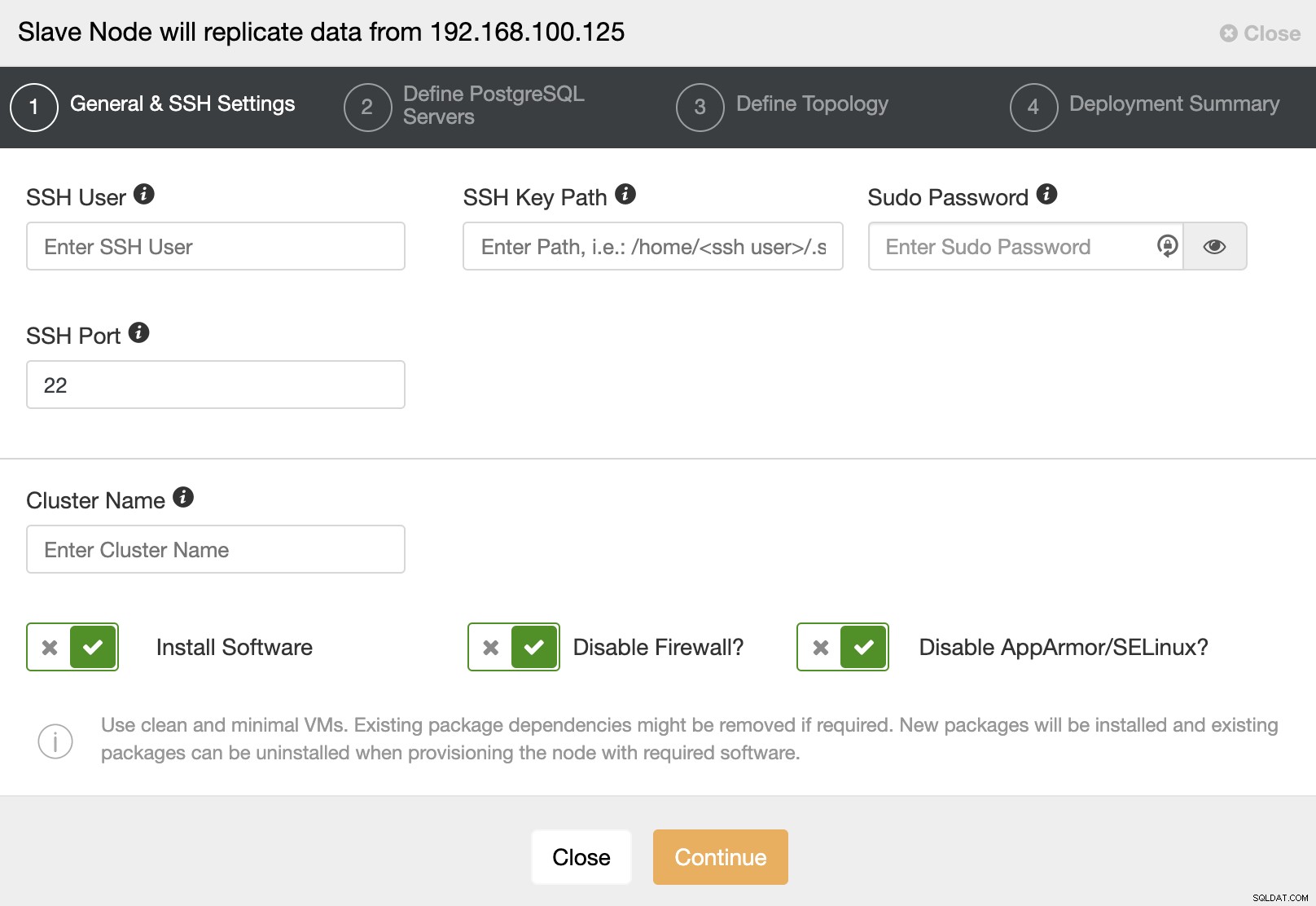
Quando vai al passaggio successivo, devi specificare Utente, Chiave o Password e porta per connetterti tramite SSH ai tuoi server. Hai anche bisogno di un nome per il tuo Cluster Slave e se vuoi che ClusterControl installi per te il software e le configurazioni corrispondenti.
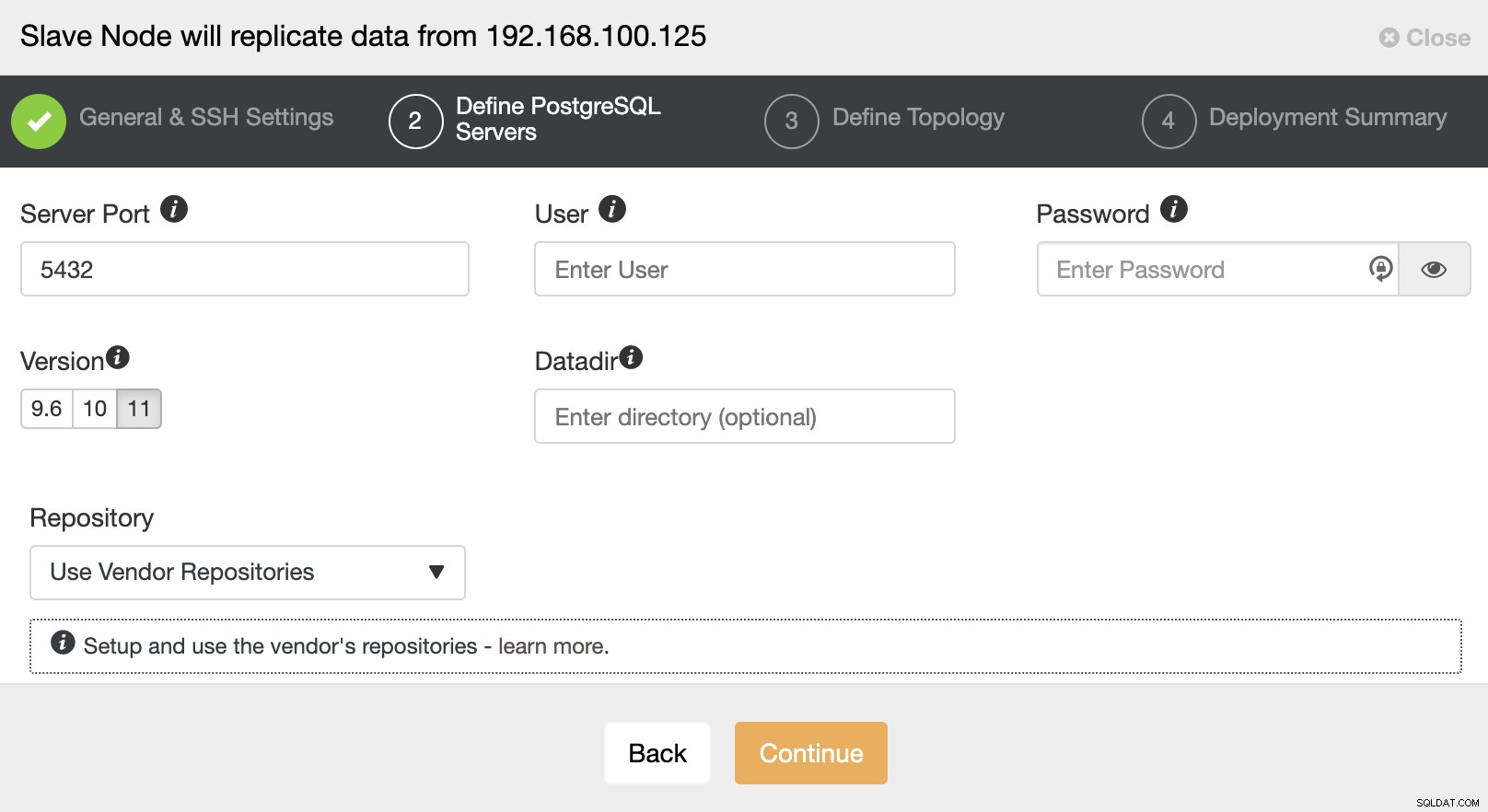
Dopo aver impostato le informazioni di accesso SSH, è necessario definire la versione del database, datadir, porta e credenziali di amministratore. Poiché utilizzerà la replica in streaming, assicurati di utilizzare la stessa versione del database e, come accennato in precedenza, le credenziali devono essere le stesse utilizzate dal Master Cluster. Puoi anche specificare quale repository utilizzare.
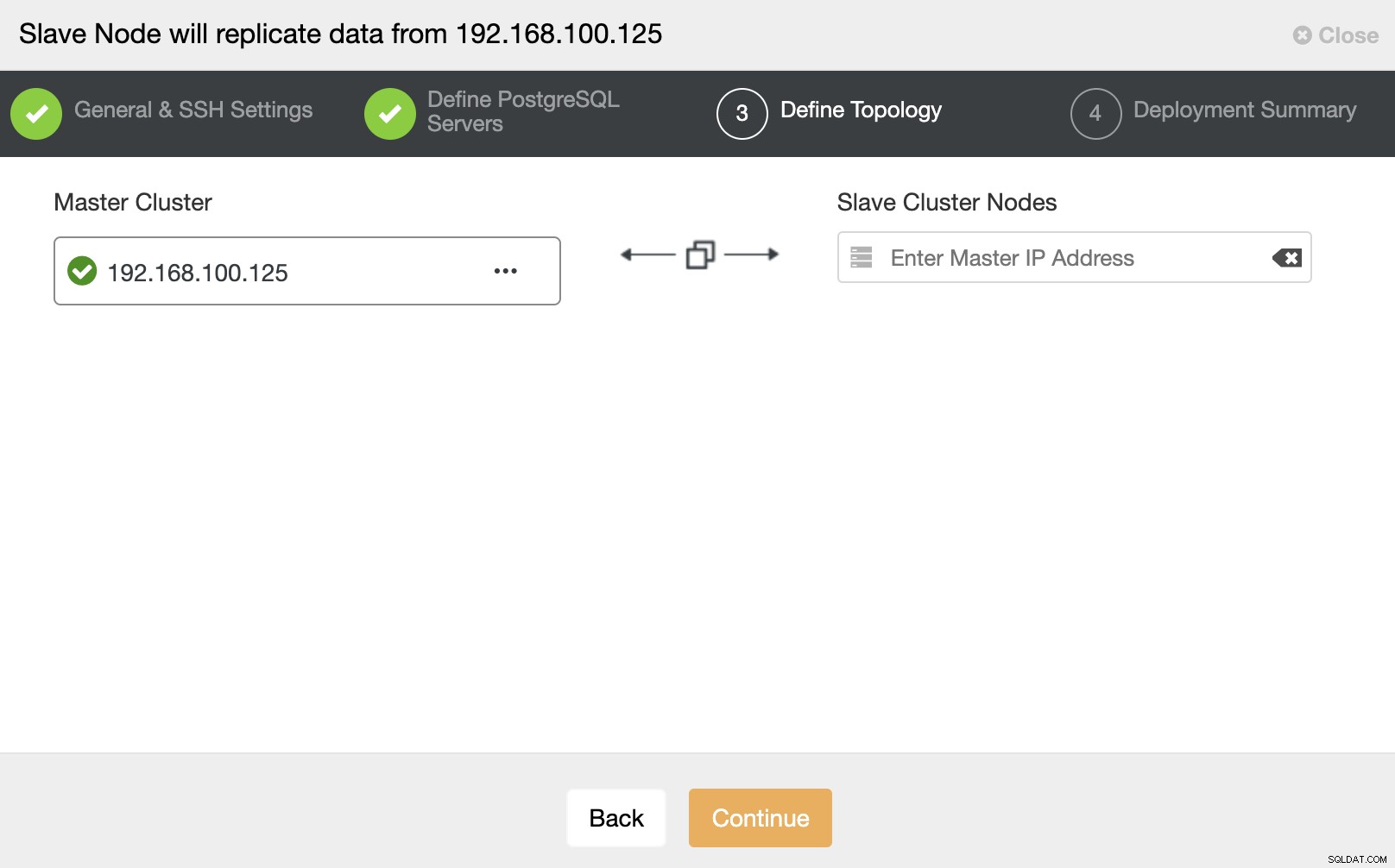
In questo passaggio, è necessario aggiungere il server al nuovo cluster slave . Per questa attività, puoi inserire sia l'indirizzo IP che il nome host del nodo del database.
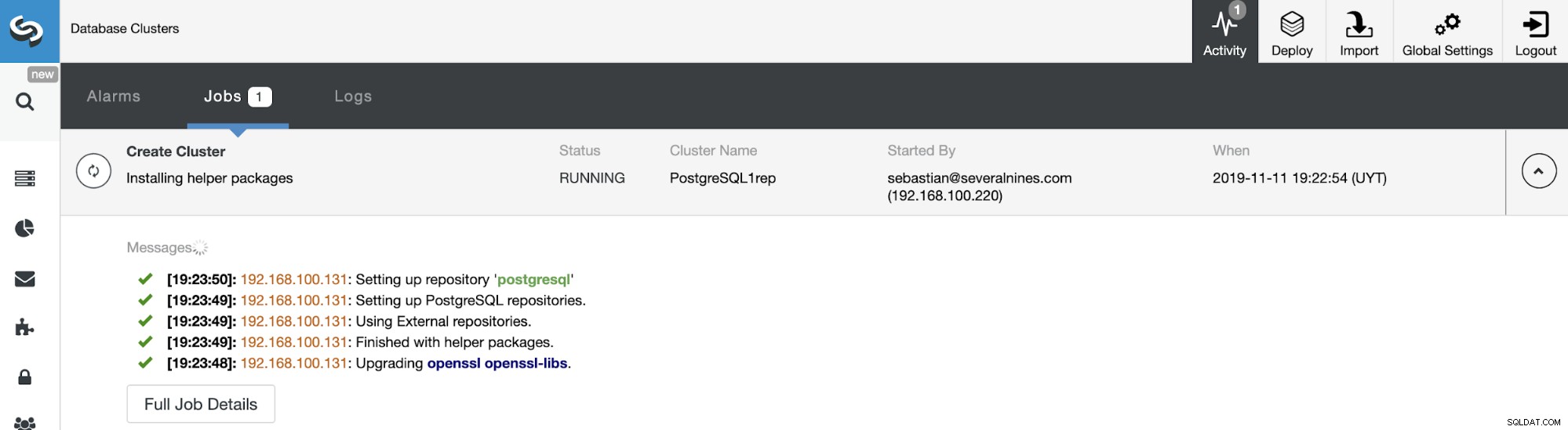
Puoi monitorare lo stato della creazione del tuo nuovo Slave Cluster dal Monitoraggio attività ClusterControl. Al termine dell'attività, puoi vedere il cluster nella schermata principale di ClusterControl.
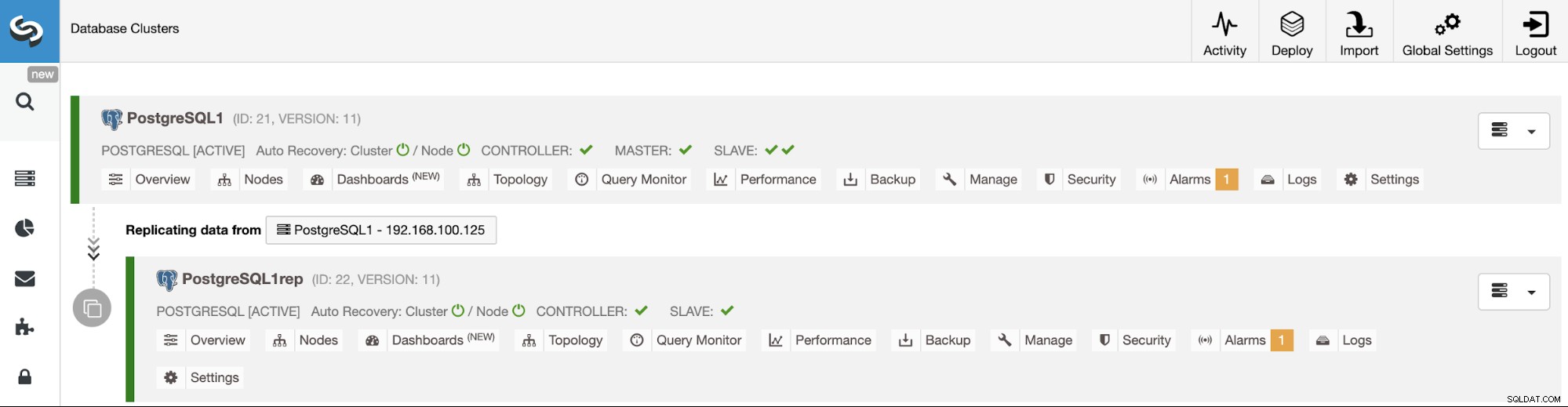
Gestione della replica da cluster a cluster utilizzando l'interfaccia utente ClusterControl
Ora che la replica da cluster a cluster è attiva e funzionante, ci sono diverse azioni da eseguire su questa topologia utilizzando ClusterControl.
Ricostruire un cluster di schiavi
Per ricostruire uno Slave Cluster, vai su ClusterControl -> Seleziona Slave Cluster -> Nodes -> Scegli il Nodo connesso al Master Cluster -> Node Actions -> Rebuild Replication Slave.
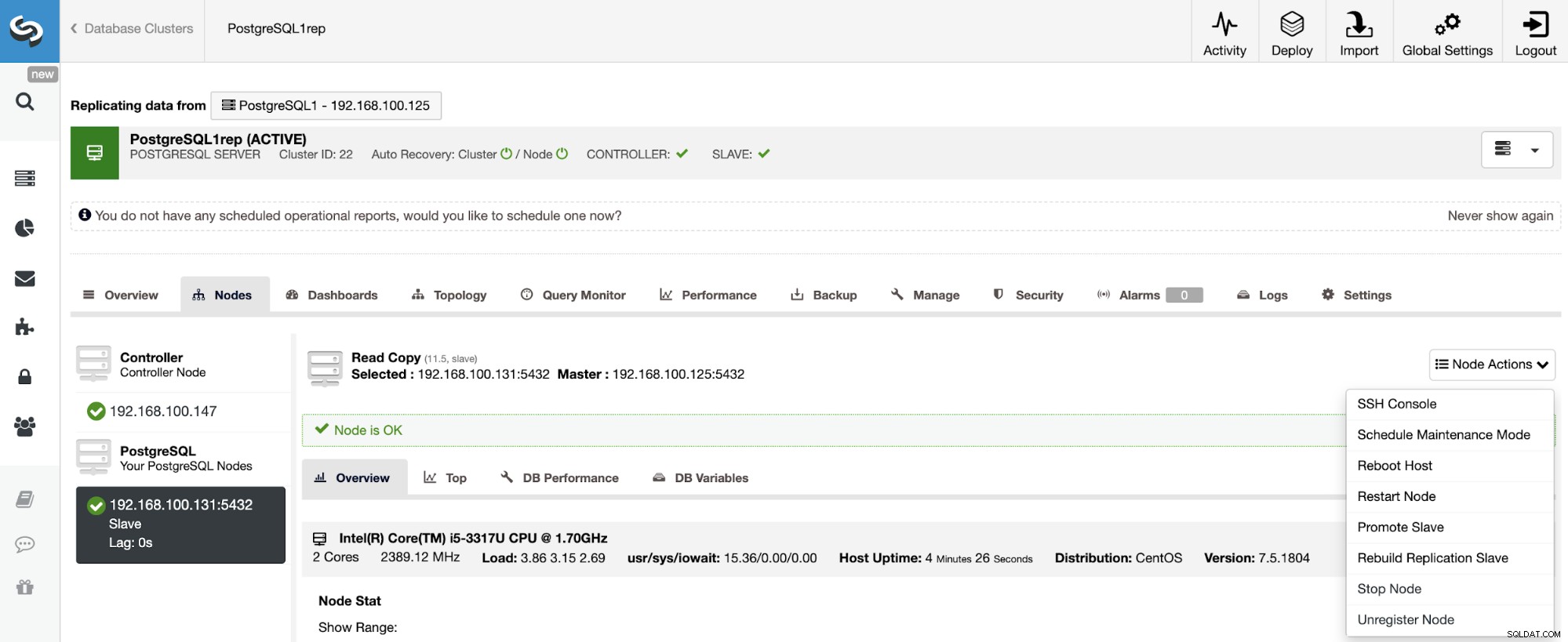
ClusterControl eseguirà i seguenti passaggi:
- Arresta PostgreSQL Server
- Rimuovi il contenuto dalla sua datadir
- Trasmetti in streaming un backup dal master allo slave utilizzando pg_basebackup
- Avvia lo Slave
Arresta/Avvia slave replica
La replica stop and start in PostgreSQL significa metterla in pausa e riprenderla, ma utilizziamo questi termini per essere coerenti con altre tecnologie di database che supportiamo.
Questa funzione sarà presto disponibile per l'uso dall'interfaccia utente di ClusterControl. Questa azione utilizzerà le funzioni pg_wal_replay_pause e pg_wal_replay_resume PostgreSQL per eseguire questa attività.
Nel frattempo, è possibile utilizzare una soluzione alternativa per arrestare e avviare lo slave di replica arrestando e avviando il nodo del database in modo semplice utilizzando ClusterControl.
Vai a ClusterControl -> Seleziona cluster slave -> Nodi -> Scegli il Nodo -> Azioni nodo -> Arresta nodo/Avvia nodo. Questa azione arresterà/avvierà direttamente il servizio database.
Gestione della replica da cluster a cluster tramite ClusterControl CLI
Nella sezione precedente, è stato possibile vedere come gestire una replica da cluster a cluster utilizzando l'interfaccia utente di ClusterControl. Ora, vediamo come farlo utilizzando la riga di comando.
Nota:come accennato all'inizio di questo blog, supponiamo che ClusterControl sia installato e che il cluster master sia stato distribuito utilizzandolo.
Crea il cluster slave
Per prima cosa, vediamo un comando di esempio per creare un Cluster Slave utilizzando ClusterControl CLI:
$ s9s cluster --create --cluster-name=PostgreSQL1rep --cluster-type=postgresql --provider-version=11 --nodes="192.168.100.133" --os-user=root --os-key-file=/root/.ssh/id_rsa --db-admin=admin --db-admin-passwd=********* --vendor=postgres --remote-cluster-id=21 --logOra hai il tuo processo di creazione slave in esecuzione, vediamo ogni parametro utilizzato:
- Cluster:per elencare e manipolare i cluster.
- Crea:crea e installa un nuovo cluster.
- Nome-cluster:il nome del nuovo cluster slave.
- Tipo di cluster:il tipo di cluster da installare.
- Versione del provider:la versione del software.
- Nodi:Elenco dei nuovi nodi nel Cluster Slave.
- Os-user:il nome utente per i comandi SSH.
- Os-key-file:il file chiave da utilizzare per la connessione SSH.
- Db-admin:il nome utente dell'amministratore del database.
- Db-admin-passwd:la password per l'amministratore del database.
- Remote-cluster-id:ID cluster principale per la replica da cluster a cluster.
- Registro:Attendi e monitora i messaggi di lavoro.
Utilizzando il flag --log, potrai vedere i log in tempo reale:
Verifying job parameters.
192.168.100.133: Checking ssh/sudo.
192.168.100.133: Checking if host already exists in another cluster.
Checking job arguments.
Found top level master node: 192.168.100.133
Verifying nodes.
Checking nodes that those aren't in another cluster.
Checking SSH connectivity and sudo.
192.168.100.133: Checking ssh/sudo.
Checking OS system tools.
Installing software.
Detected centos (core 7.5.1804).
Data directory was not specified. Using directory '/var/lib/pgsql/11/data'.
192.168.100.133:5432: Configuring host and installing packages if neccessary.
...
Cluster 26 is running.
Generated & set RPC authentication token.Ricostruire un cluster di schiavi
Puoi ricostruire un Cluster Slave usando il seguente comando:
$ s9s replication --stage --master="192.168.100.125" --slave="192.168.100.133" --cluster-id=26 --remote-cluster-id=21 --logI parametri sono:
- Replica:per monitorare e controllare la replica dei dati.
- Fase:elabora/ricostruisci uno slave di replica.
- Master:il master di replica nel cluster master.
- Slave:lo slave di replica nel cluster slave.
- Cluster-id:l'ID del cluster slave.
- Remote-cluster-id:l'ID del cluster principale.
- Registro:Attendi e monitora i messaggi di lavoro.
Il registro dei lavori dovrebbe essere simile a questo:
Rebuild replication slave 192.168.100.133:5432 from master 192.168.100.125:5432.
Remote cluster id = 21
192.168.100.125: Checking size of '/var/lib/pgsql/11/data'.
192.168.100.125: /var/lib/pgsql/11/data size is 201.13 MiB.
192.168.100.133: Checking free space in '/var/lib/pgsql/11/data'.
192.168.100.133: /var/lib/pgsql/11/data has 28.78 GiB free space.
192.168.100.125:5432(master): Verifying PostgreSQL version.
192.168.100.125: Verifying the timescaledb-postgresql-11 installation.
192.168.100.125: Package timescaledb-postgresql-11 is not installed.
Setting up replication 192.168.100.125:5432->192.168.100.133:5432
Collecting server variables.
192.168.100.125:5432: Using the pg_hba.conf contents for the slave.
192.168.100.125:5432: Will copy the postmaster.opts to the slave.
192.168.100.133:5432: Updating slave configuration.
Writing file '192.168.100.133:/var/lib/pgsql/11/data/postgresql.conf'.
192.168.100.133:5432: GRANT new node on members to do pg_basebackup.
192.168.100.125:5432: granting 192.168.100.133:5432.
192.168.100.133:5432: Stopping slave.
192.168.100.133:5432: Stopping PostgreSQL node.
192.168.100.133: waiting for server to shut down.... done
server stopped
…
192.168.100.133: waiting for server to start....2019-11-12 15:51:11.767 UTC [8005] LOG: listening on IPv4 address "0.0.0.0", port 5432
2019-11-12 15:51:11.767 UTC [8005] LOG: listening on IPv6 address "::", port 5432
2019-11-12 15:51:11.769 UTC [8005] LOG: listening on Unix socket "/var/run/postgresql/.s.PGSQL.5432"
2019-11-12 15:51:11.774 UTC [8005] LOG: listening on Unix socket "/tmp/.s.PGSQL.5432"
2019-11-12 15:51:11.798 UTC [8005] LOG: redirecting log output to logging collector process
2019-11-12 15:51:11.798 UTC [8005] HINT: Future log output will appear in directory "log".
done
server started
192.168.100.133:5432: Grant cluster members on the new node (for failover).
Grant connect access for new host in cluster.
Adding grant on 192.168.100.125:5432.
192.168.100.133:5432: Waiting until the service is started.
Replication slave job finished.Arresta/Avvia slave replica
Come accennato nella sezione dell'interfaccia utente, interrompere e avviare la replica in PostgreSQL significa metterla in pausa e riprenderla, ma usiamo questi termini per mantenere il parallelismo con altre tecnologie.
Puoi interrompere la replica dei dati dal Master Cluster in questo modo:
$ s9s replication --stop --slave="192.168.100.133" --cluster-id=26 --logVedrai questo:
192.168.100.133:5432: Pausing recovery of the slave.
192.168.100.133:5432: Successfully paused recovery on the slave using select pg_wal_replay_pause().E ora puoi ricominciare:
$ s9s replication --start --slave="192.168.100.133" --cluster-id=26 --logQuindi vedrai:
192.168.100.133:5432: Resuming recovery on the slave.
192.168.100.133:5432: Collecting replication statistics.
192.168.100.133:5432: Slave resumed recovery successfully using select pg_wal_replay_resume().Adesso controlliamo i parametri utilizzati.
- Replica:per monitorare e controllare la replica dei dati.
- Arresta/Avvia:per fare in modo che lo slave arresti/avvii la replica.
- Slave:il nodo slave di replica.
- Cluster-id:l'ID del cluster in cui si trova il nodo slave.
- Registro:Attendi e monitora i messaggi di lavoro.
Conclusione
Questa nuova funzionalità ClusterControl ti consentirà di configurare rapidamente la replica tra diversi cluster PostgreSQL e di gestire l'installazione in modo semplice e intuitivo. Il team di sviluppo di Multiplenines sta lavorando per migliorare questa funzionalità, quindi qualsiasi idea o suggerimento sarebbe il benvenuto.