Come avrai notato dal mio blog precedente, gli ultimi mesi sono stati impegnati nell'aggiornamento di Postgres-XL con l'ultima versione 9.5 di PostgreSQL. Una volta ottenuta una versione ragionevolmente stabile di Postgres-XL 9.5, abbiamo spostato la nostra attenzione per misurare le prestazioni di questa nuovissima versione di Postgres-XL. La nostra scelta del benchmark è in gran parte influenzata dal lavoro in corso sul progetto AXLE, finanziato dall'Unione Europea nell'ambito della convenzione di sovvenzione 318633. Poiché stiamo utilizzando TPC BENCHMARK™ H per misurare le prestazioni di tutti gli altri lavori svolti nell'ambito di questo progetto, abbiamo deciso di utilizzare lo stesso benchmark per valutare Postgres-XL. Si adatta anche a Postgres-XL perché TPC-H cerca di misurare i carichi di lavoro OLAP, cosa che Postgres-XL dovrebbe fare bene.
1. Configurazione del cluster Postgres-XL
Una volta deciso il benchmark, un'altra grande sfida è stata trovare le risorse giuste per i test. Non avevamo accesso a un grande cluster di macchine fisiche. Quindi abbiamo fatto quello che la maggior parte avrebbe fatto. Abbiamo deciso di utilizzare Amazon AWS per configurare il cluster Postgres-XL. AWS offre un'ampia gamma di istanze, con ogni tipo di istanza che offre potenza di elaborazione o IO diversa.
Questa pagina su AWS mostra i vari tipi di istanze disponibili, le risorse disponibili e i relativi prezzi per le diverse regioni. Va notato che i prezzi e la disponibilità possono variare da regione a regione, quindi è importante controllare tutte le regioni. Poiché Postgres-XL richiede una bassa latenza e un elevato throughput tra i suoi componenti, è anche importante creare un'istanza di tutte le istanze nella stessa regione. Per il nostro TPC-H da 3 TB abbiamo deciso di scegliere un cluster a 16 nodi di dati di istanze AWS i2.xlarge. Queste istanze hanno 4 vCPU, 30 GB di RAM e 800 GB di SSD ciascuna, spazio di archiviazione sufficiente per mantenere tutte le tabelle distribuite, le tabelle replicate (che occupano più spazio con l'aumentare delle dimensioni del cluster), gli indici su di esse e lasciando comunque spazio libero sufficiente nella tablespace temporanea per CREATE INDEX e altre query.
2. Impostazione del benchmark
2.1 Benchmark TPC™ H
Il benchmark contiene 22 query con lo scopo di esaminare grandi volumi di dati, eseguire query con un elevato grado di complessità e fornire risposte a domande aziendali critiche. Vorremmo notare che la specifica TPC Benchmark™ H completa si occupa di una varietà di test come carico, potenza e throughput prove. Per i nostri test, abbiamo eseguito solo query singole e non la suite di test completa. TPC Benchmark™ H comprende una serie di query aziendali progettate per esercitare le funzionalità del sistema in modo rappresentativo di complesse applicazioni di analisi aziendale. A queste domande è stato assegnato un contesto realistico, che descrive l'attività di un fornitore all'ingrosso per aiutare il lettore a relazionarsi intuitivamente con i componenti del benchmark.
2.2 Entità del database, relazioni e caratteristiche
I componenti del database TPC-H sono definiti come costituiti da otto tabelle separate e individuali (le Tabelle di base). Le relazioni tra le colonne di queste tabelle sono illustrate nel diagramma seguente. 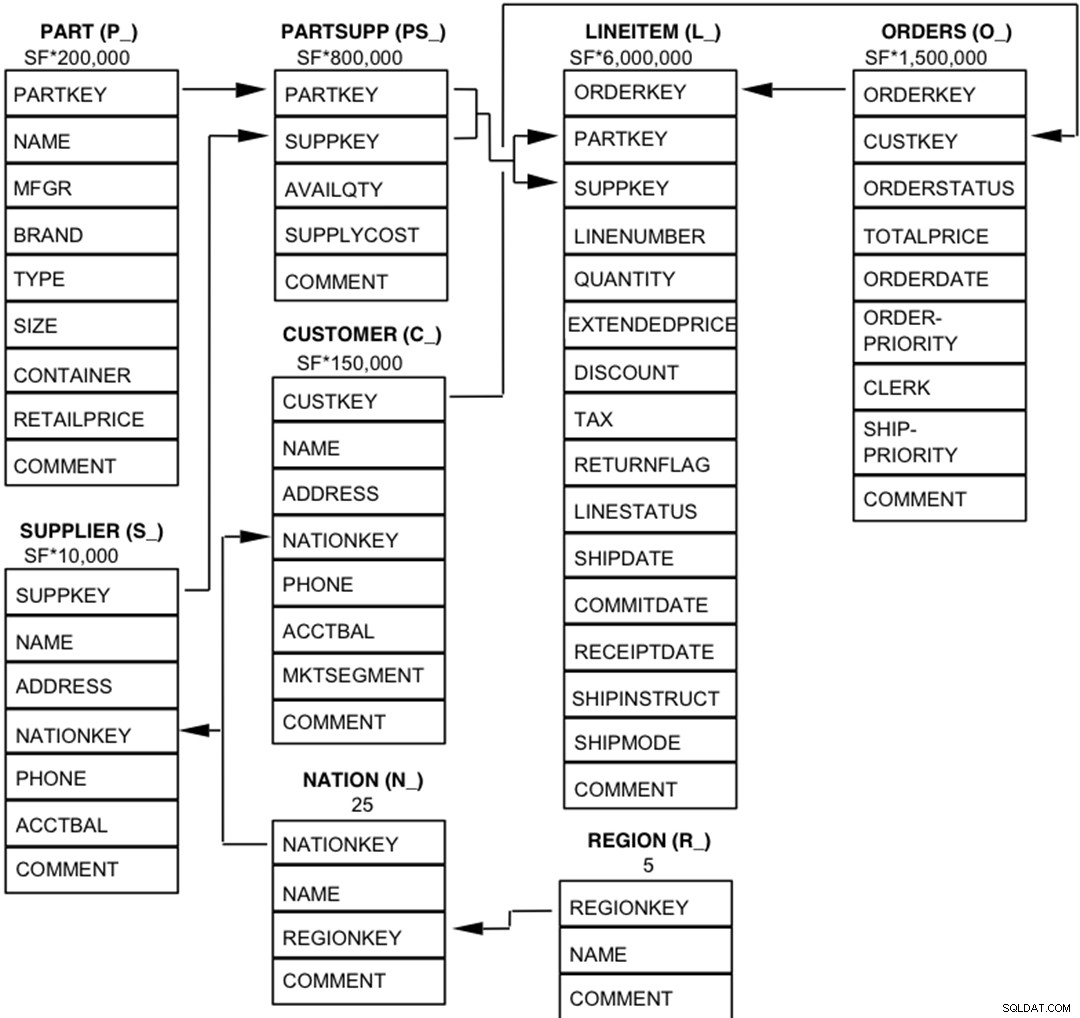 Leggenda :
Leggenda :
- Le parentesi che seguono ogni nome di tabella contengono il prefisso dei nomi di colonna per quella tabella;
- Le frecce puntano nella direzione delle relazioni uno a molti tra le tabelle
- Il numero/formula sotto ogni nome di tabella rappresenta la cardinalità (numero di righe) della tabella. Alcuni sono fattorizzati da SF, il fattore di scala, per ottenere la dimensione del database scelta. La cardinalità per la tabella LINEITEM è approssimativa
2.3 Distribuzione dei dati per Postgres-XL
Abbiamo analizzato tutte le 22 query nel benchmark e abbiamo elaborato la seguente strategia di distribuzione dei dati per varie tabelle del benchmark.
| Nome tabella | Strategia di distribuzione |
| ARTICOLO LINEA | HASH (l_orderkey) |
| ORDINI | HASH (o_orderkey) |
| PARTE | HASH (p_partkey) |
| PARTSUPP | HASH (ps_partkey) |
| CLIENTE | REPLICATO |
| FORNITORE | REPLICATO |
| NAZIONE | REPLICATO |
| REGIONE | REPLICATO |
Si noti che LINEITEM e ORDERS, che sono le tabelle più grandi nel benchmark, sono spesso unite in ORDERKEY. Quindi ha molto senso collocare queste tabelle in ORDERKEY. Allo stesso modo, PART e PARTSUPP sono spesso uniti su PARTKEY e quindi sono collocati nella colonna PARTKEY. Il resto delle tabelle viene replicato per garantire che possano essere unite localmente, quando necessario.
3. Risultati benchmark
3.1 Test di carico
Abbiamo confrontato i risultati ottenuti eseguendo un test di carico TPC-H da 3 TB su PostgreSQL 9.6 con il cluster Postgres-XL a 16 nodi. I seguenti grafici mostrano le caratteristiche prestazionali di Postgres-XL.
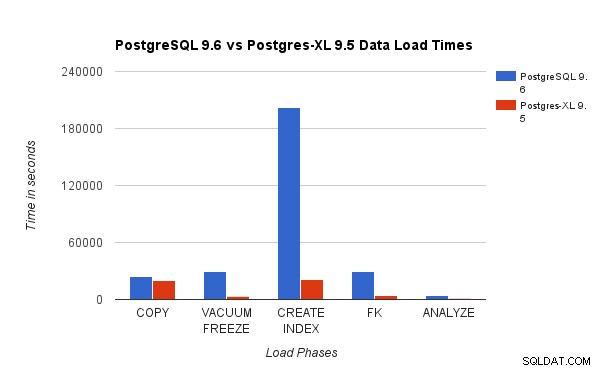 Il grafico sopra mostra il tempo impiegato per completare le varie fasi di un test di carico con PostgreSQL e Postgres-XL. Come visto, Postgres-XL ha prestazioni leggermente migliori per COPY e molto meglio per tutti gli altri casi. Nota :Abbiamo osservato che il coordinatore richiede molta potenza di calcolo durante la fase COPY, specialmente quando più di un flusso COPY è in esecuzione contemporaneamente. Per risolvere questo problema, il coordinatore è stato eseguito su un'istanza AWS ottimizzata per il calcolo con 16 vCPU. In alternativa, avremmo anche potuto eseguire più coordinatori e distribuire il carico di calcolo tra di loro.
Il grafico sopra mostra il tempo impiegato per completare le varie fasi di un test di carico con PostgreSQL e Postgres-XL. Come visto, Postgres-XL ha prestazioni leggermente migliori per COPY e molto meglio per tutti gli altri casi. Nota :Abbiamo osservato che il coordinatore richiede molta potenza di calcolo durante la fase COPY, specialmente quando più di un flusso COPY è in esecuzione contemporaneamente. Per risolvere questo problema, il coordinatore è stato eseguito su un'istanza AWS ottimizzata per il calcolo con 16 vCPU. In alternativa, avremmo anche potuto eseguire più coordinatori e distribuire il carico di calcolo tra di loro.
3.2 Test di potenza
Abbiamo anche confrontato i tempi di esecuzione delle query per il benchmark da 3 TB su PostgreSQL 9.6 e Postgres-XL 9.5. Il grafico seguente mostra le caratteristiche delle prestazioni dell'esecuzione della query nelle due configurazioni.
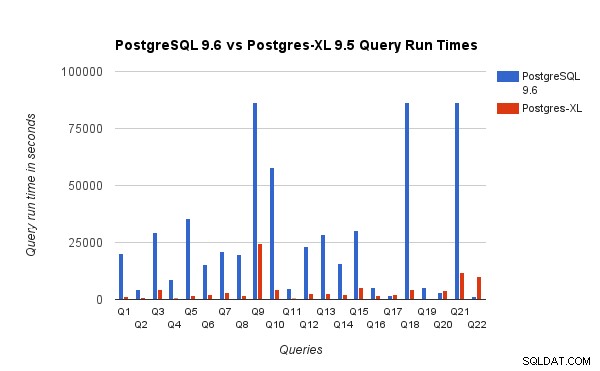 Abbiamo osservato che in media le query sono state eseguite circa 6,4 volte più velocemente su Postgres-XL e almeno il 25% delle query hanno mostrato un miglioramento quasi lineare delle prestazioni, in altre parole si sono comportati quasi 16 volte più velocemente su questo cluster Postgres-XL a 16 nodi. Inoltre almeno il 50% delle query ha mostrato un miglioramento delle prestazioni di 10 volte. Abbiamo ulteriormente analizzato le prestazioni delle query e concluso che le query che sono ben partizionate su tutti i datanode disponibili, in modo tale che vi sia uno scambio minimo di dati tra i nodi e senza ripetute chiamate di esecuzione remota, si adattano molto bene in Postgres-XL. Tali query in genere hanno un nodo Remote Subquery Scan nella parte superiore e la sottostruttura sotto il nodo viene eseguita su uno o più nodi in parallelo. È anche comune avere altri nodi come un nodo Limit o un nodo Aggregate sopra il nodo Remote Subquery Scan. Anche tali query funzionano molto bene su Postgres-XL. Query Q1 è un esempio di una query che dovrebbe scalare molto bene con Postgres-XL. D'altra parte, le query che richiedono molti scambi di tuple tra datanode-datanode e/o coordinator-datanode potrebbero non funzionare bene in Postgres-XL. Allo stesso modo, anche le query che richiedono molte connessioni tra nodi possono mostrare scarse prestazioni. Ad esempio, noterai che le prestazioni di Q22 sono pessime rispetto a un server PostgreSQL a nodo singolo. Quando abbiamo analizzato il piano di query per il Q22, abbiamo osservato che ci sono tre livelli di nodi Remote Subquery Scan nidificati nel piano di query, in cui ogni nodo apre un numero uguale di connessioni ai datanode. Inoltre, Nest Loop Anti Join ha una relazione interna con un nodo Remote Subquery Scan di livello superiore e quindi per ogni tupla della relazione esterna deve eseguire una subquery remota. Ciò si traduce in scarse prestazioni di esecuzione delle query.
Abbiamo osservato che in media le query sono state eseguite circa 6,4 volte più velocemente su Postgres-XL e almeno il 25% delle query hanno mostrato un miglioramento quasi lineare delle prestazioni, in altre parole si sono comportati quasi 16 volte più velocemente su questo cluster Postgres-XL a 16 nodi. Inoltre almeno il 50% delle query ha mostrato un miglioramento delle prestazioni di 10 volte. Abbiamo ulteriormente analizzato le prestazioni delle query e concluso che le query che sono ben partizionate su tutti i datanode disponibili, in modo tale che vi sia uno scambio minimo di dati tra i nodi e senza ripetute chiamate di esecuzione remota, si adattano molto bene in Postgres-XL. Tali query in genere hanno un nodo Remote Subquery Scan nella parte superiore e la sottostruttura sotto il nodo viene eseguita su uno o più nodi in parallelo. È anche comune avere altri nodi come un nodo Limit o un nodo Aggregate sopra il nodo Remote Subquery Scan. Anche tali query funzionano molto bene su Postgres-XL. Query Q1 è un esempio di una query che dovrebbe scalare molto bene con Postgres-XL. D'altra parte, le query che richiedono molti scambi di tuple tra datanode-datanode e/o coordinator-datanode potrebbero non funzionare bene in Postgres-XL. Allo stesso modo, anche le query che richiedono molte connessioni tra nodi possono mostrare scarse prestazioni. Ad esempio, noterai che le prestazioni di Q22 sono pessime rispetto a un server PostgreSQL a nodo singolo. Quando abbiamo analizzato il piano di query per il Q22, abbiamo osservato che ci sono tre livelli di nodi Remote Subquery Scan nidificati nel piano di query, in cui ogni nodo apre un numero uguale di connessioni ai datanode. Inoltre, Nest Loop Anti Join ha una relazione interna con un nodo Remote Subquery Scan di livello superiore e quindi per ogni tupla della relazione esterna deve eseguire una subquery remota. Ciò si traduce in scarse prestazioni di esecuzione delle query.
4. Alcune lezioni di AWS
Durante il benchmarking di Postgres-XL abbiamo appreso alcune lezioni sull'utilizzo di AWS. Abbiamo pensato che sarebbero stati utili per chiunque desideri utilizzare/testare Postgres-XL su AWS.
- AWS offre diversi tipi di istanze. È necessario valutare attentamente il carico di lavoro e la quantità di spazio di archiviazione richiesta prima di scegliere un tipo di istanza specifico.
- La maggior parte delle istanze ottimizzate per lo storage dispone di dischi temporanei collegati. Non è necessario pagare nulla in più per quei dischi, sono collegati all'istanza e spesso funzionano meglio di EBS. Ma devi montarli esplicitamente per poterli usare. Tieni presente, tuttavia, che i dati archiviati su questi dischi non sono permanenti e verranno cancellati se l'istanza viene interrotta. Quindi assicurati di essere pronto a gestire quella situazione. Poiché utilizzavamo AWS principalmente per il benchmarking, abbiamo deciso di utilizzare questi dischi temporanei.
- Se utilizzi EBS, assicurati di scegliere l'IOPS con provisioning appropriato. Un valore troppo basso causerà un IO molto lento, ma un valore molto alto può aumentare notevolmente la fattura AWS, soprattutto quando si ha a che fare con un numero elevato di nodi.
- Assicurati di avviare le istanze nella stessa zona per ridurre la latenza e migliorare il throughput per le connessioni tra di esse.
- Assicurati di configurare le istanze in modo che utilizzino la rete privata per comunicare tra loro.
- Guarda le istanze spot. Sono relativamente più economici. Poiché AWS può terminare le istanze spot a piacimento, ad esempio, se il prezzo spot supera il prezzo massimo di offerta, preparati a questo. Postgres-XL potrebbe diventare parzialmente o completamente inutilizzabile a seconda di quali nodi vengono terminati. AWS supporta un concetto di launch_group. Se più istanze sono raggruppate nello stesso gruppo_di_lancio, se AWS decide di terminare un'istanza, tutte le istanze verranno terminate.
5. Conclusione
Siamo in grado di dimostrare, attraverso vari benchmark, che Postgres-XL può scalare molto bene per un ampio set di query complesse del mondo reale. Questi benchmark ci aiutano a dimostrare le capacità di Postgres-XL come soluzione efficace per i carichi di lavoro OLAP. I nostri esperimenti mostrano anche che ci sono alcuni problemi di prestazioni con Postgres-XL, specialmente per cluster molto grandi e quando il pianificatore fa una scelta sbagliata di un piano. Abbiamo anche osservato che quando c'è un numero molto elevato di connessioni simultanee a un nodo di dati, le prestazioni peggiorano. Continueremo a lavorare su questi problemi di prestazioni. Vorremmo anche testare le capacità di Postgres-XL come soluzione OLTP utilizzando carichi di lavoro appropriati.