A volte è difficile gestire una grande quantità di dati in un'azienda, soprattutto con l'incremento esponenziale dell'analisi dei dati e dell'utilizzo dell'IoT. A seconda delle dimensioni, questa quantità di dati potrebbe influire sulle prestazioni dei tuoi sistemi e probabilmente dovrai ridimensionare i tuoi database o trovare un modo per risolverlo. Esistono diversi modi per ridimensionare i database PostgreSQL e uno di questi è lo Sharding. In questo blog vedremo cos'è lo Sharding e come configurarlo in PostgreSQL utilizzando ClusterControl per semplificare l'attività.
Cos'è lo Sharding?
Il partizionamento orizzontale è l'azione di ottimizzazione di un database separando i dati da una tabella grande in più tabelle piccole. Le tabelle più piccole sono Shard (o partizioni). Partizionamento e partizionamento orizzontale sono concetti simili. La differenza principale è che il partizionamento orizzontale implica che i dati siano distribuiti su più computer mentre il partizionamento riguarda il raggruppamento di sottoinsiemi di dati all'interno di una singola istanza del database.
Ci sono due tipi di Sharding:
-
Sharding orizzontale:ogni nuova tabella ha lo stesso schema della tabella grande ma righe univoche. È utile quando le query tendono a restituire un sottoinsieme di righe che sono spesso raggruppate insieme.
-
Sharding verticale:ogni nuova tabella ha uno schema che è un sottoinsieme dello schema della tabella originale. È utile quando le query tendono a restituire solo un sottoinsieme di colonne dei dati.
Vediamo un esempio:
Tabella Originale
| ID | Nome | Età | Paese |
|---|---|---|---|
| 1 | James Smith | 26 | Stati Uniti |
| 2 | Mary Johnson | 31 | Germania |
| 3 | Robert Williams | 54 | Canada |
| 4 | Jennifer Brown | 47 | Francia |
Sharding verticale
| Shard1 | Shard2 | |||
|---|---|---|---|---|
| ID | Nome | Età | ID | Paese |
| 1 | James Smith | 26 | 1 | Stati Uniti |
| 2 | Mary Johnson | 31 | 2 | Germania |
| 3 | Robert Williams | 54 | 3 | Canada |
| 4 | Jennifer Brown | 47 | 4 | Francia |
Sharding orizzontale
| Shard1 | Shard2 | ||||||
|---|---|---|---|---|---|---|---|
| ID | Nome | Età | Paese | ID | Nome | Età | Paese |
| 1 | James Smith | 26 | Stati Uniti | 3 | Robert Williams | 54 | Canada |
| 2 | Mary Johnson | 31 | Germania | 4 | Jennifer Brown | 47 | Francia |
Ora che abbiamo esaminato alcuni concetti di sharding, procediamo al passaggio successivo.
Come distribuire un cluster PostgreSQL?
Utilizzeremo ClusterControl per questa attività. Se non stai ancora utilizzando ClusterControl, puoi installarlo e distribuire o importare il tuo attuale database PostgreSQL selezionando l'opzione "Importa" e segui i passaggi per sfruttare tutte le funzionalità di ClusterControl come backup, failover automatico, avvisi, monitoraggio e altro .
Per eseguire un deployment da ClusterControl, seleziona semplicemente l'opzione "Deploy" e segui le istruzioni che appaiono.
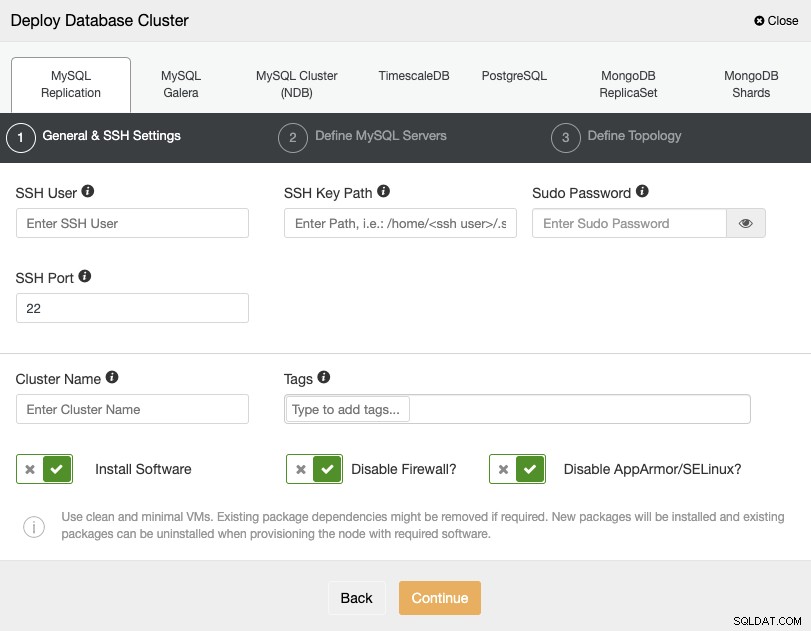
Quando si seleziona PostgreSQL, è necessario specificare Utente, Chiave o Password e Porta per connetterti tramite SSH ai tuoi server. Puoi anche aggiungere un nome per il tuo nuovo cluster e, se lo desideri, puoi anche utilizzare ClusterControl per installare il software e le configurazioni corrispondenti per te.
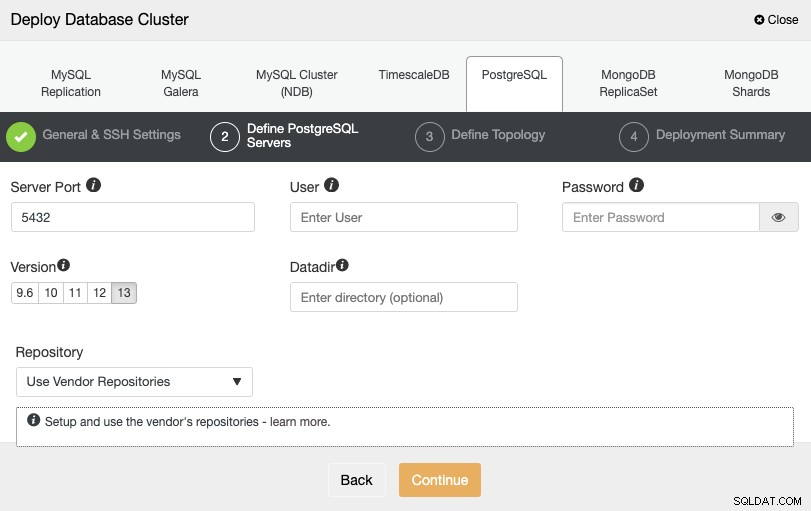
Dopo aver impostato le informazioni di accesso SSH, è necessario definire le credenziali del database , versione e datadir (opzionale). Puoi anche specificare quale repository utilizzare.
Per il passaggio successivo, devi aggiungere i tuoi server al cluster che creerai utilizzando l'indirizzo IP o il nome host.
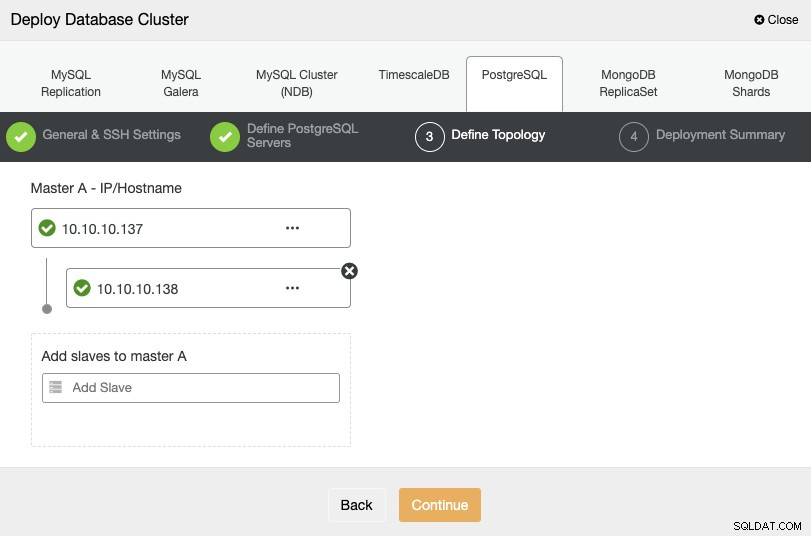
Nell'ultimo passaggio, puoi scegliere se la tua replica sarà Sincrona o Asincrono, quindi premi semplicemente su "Distribuisci".
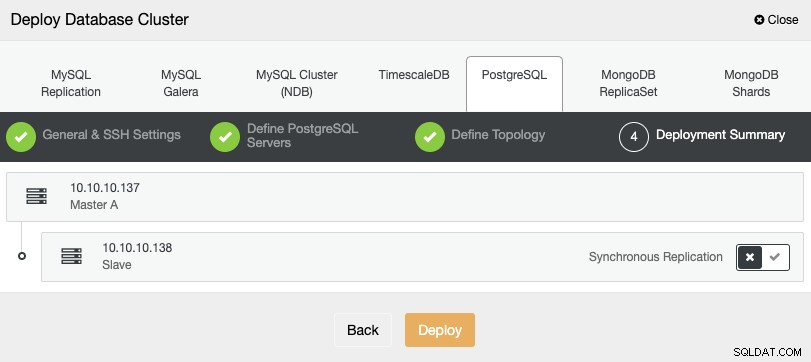
Una volta terminata l'attività, vedrai il tuo nuovo cluster PostgreSQL nel schermata principale di ClusterControl.

Ora che hai creato il tuo cluster, puoi eseguire diverse attività su di esso come aggiungere un sistema di bilanciamento del carico (HAProxy), un pool di connessioni (pgBouncer) o una nuova replica.
Ripeti il processo per avere almeno due cluster PostgreSQL separati per configurare lo Sharding, che è il passaggio successivo.
Come configurare lo sharding di PostgreSQL?
Ora configureremo lo Sharding usando le partizioni PostgreSQL e il Foreign Data Wrapper (FDW). Questa funzionalità consente a PostgreSQL di accedere ai dati archiviati in altri server. È un'estensione disponibile per impostazione predefinita nell'installazione comune di PostgreSQL.
Utilizzeremo il seguente ambiente:
Servers: Shard1 - 10.10.10.137, Shard2 - 10.10.10.138
Database User: admindb
Table: customersPer abilitare l'estensione FDW, devi solo eseguire il seguente comando nel tuo server principale, in questo caso, Shard1:
postgres=# CREATE EXTENSION postgres_fdw;
CREATE EXTENSIONOra creiamo la tabella clienti partizionata per data di registrazione:
postgres=# CREATE TABLE customers (
id INT NOT NULL,
name VARCHAR(30) NOT NULL,
registered DATE NOT NULL
)
PARTITION BY RANGE (registered);E le seguenti partizioni:
postgres=# CREATE TABLE customers_2021
PARTITION OF customers
FOR VALUES FROM ('2021-01-01') TO ('2022-01-01');
postgres=# CREATE TABLE customers_2020
PARTITION OF customers
FOR VALUES FROM ('2020-01-01') TO ('2021-01-01');Queste partizioni sono locali. Ora inseriamo alcuni valori di test e controlliamoli:
postgres=# INSERT INTO customers (id, name, registered) VALUES (1, 'James', '2020-05-01');
postgres=# INSERT INTO customers (id, name, registered) VALUES (2, 'Mary', '2021-03-01');Qui puoi interrogare la partizione principale per vedere tutti i dati:
postgres=# SELECT * FROM customers;
id | name | registered
----+-------+------------
1 | James | 2020-05-01
2 | Mary | 2021-03-01
(2 rows)O anche interrogare la partizione corrispondente:
postgres=# SELECT * FROM customers_2021;
id | name | registered
----+------+------------
2 | Mary | 2021-03-01
(1 row)
postgres=# SELECT * FROM customers_2020;
id | name | registered
----+-------+------------
1 | James | 2020-05-01
(1 row)
Come puoi vedere, i dati sono stati inseriti in partizioni diverse, in base alla data di registrazione. Ora, nel nodo remoto, in questo caso Shard2, creiamo un'altra tabella:
postgres=# CREATE TABLE customers_2019 (
id INT NOT NULL,
name VARCHAR(30) NOT NULL,
registered DATE NOT NULL);Devi creare questo server Shard2 in Shard1 in questo modo:
postgres=# CREATE SERVER shard2 FOREIGN DATA WRAPPER postgres_fdw OPTIONS (host '10.10.10.138', dbname 'postgres');E l'utente per accedervi:
postgres=# CREATE USER MAPPING FOR admindb SERVER shard2 OPTIONS (user 'admindb', password 'Passw0rd');Ora, crea la TABELLA ESTERA in Shard1:
postgres=# CREATE FOREIGN TABLE customers_2019
PARTITION OF customers
FOR VALUES FROM ('2019-01-01') TO ('2020-01-01')
SERVER shard2;E inseriamo i dati in questa nuova tabella remota da Shard1:
postgres=# INSERT INTO customers (id, name, registered) VALUES (3, 'Robert', '2019-07-01');
INSERT 0 1
postgres=# INSERT INTO customers (id, name, registered) VALUES (4, 'Jennifer', '2019-11-01');
INSERT 0 1Se tutto è andato bene, dovresti essere in grado di accedere ai dati sia da Shard1 che da Shard2:
Shard1:
postgres=# SELECT * FROM customers;
id | name | registered
----+----------+------------
3 | Robert | 2019-07-01
4 | Jennifer | 2019-11-01
1 | James | 2020-05-01
2 | Mary | 2021-03-01
(4 rows)
postgres=# SELECT * FROM customers_2019;
id | name | registered
----+----------+------------
3 | Robert | 2019-07-01
4 | Jennifer | 2019-11-01
(2 rows)Shard2:
postgres=# SELECT * FROM customers_2019;
id | name | registered
----+----------+------------
3 | Robert | 2019-07-01
4 | Jennifer | 2019-11-01
(2 rows)Ecco fatto. Ora stai usando Sharding nel tuo cluster PostgreSQL.
Conclusione
Il partizionamento e lo sharding in PostgreSQL sono buone caratteristiche. Ti aiuta nel caso in cui sia necessario separare i dati in una grande tabella per migliorare le prestazioni o anche per eliminare i dati in modo semplice, tra le altre situazioni. Un punto importante quando si utilizza Sharding è scegliere una buona chiave shard che distribuisca i dati tra i nodi nel modo migliore. Inoltre, puoi utilizzare ClusterControl per semplificare la distribuzione di PostgreSQL e sfruttare alcune funzionalità come monitoraggio, avvisi, failover automatico, backup, ripristino point-in-time e altro.



