Gli indici di SQL Server vengono usati per recuperare i dati più rapidamente e ridurre i colli di bottiglia che incidono sulle risorse critiche. Gli indici su una tabella di database servono come una tecnica di ottimizzazione delle prestazioni. Potresti chiederti:in che modo gli indici aumentano le prestazioni delle query? Esistono cose come indici buoni e cattivi? Supponiamo di avere una tabella con 50 colonne, è una buona idea creare indici su ciascuna delle colonne? Se creiamo più indici, aiuta le query SQL a essere eseguite più velocemente?
Tutte grandi domande, ma prima di approfondire, è essenziale sapere perché potrebbero essere richiesti gli indici in primo luogo.
Immagina di visitare una biblioteca cittadina che ha una collezione di migliaia di libri. Stai cercando un libro specifico, ma come lo troverai? Se esaminassi ogni libro, in ogni rack, potrebbero volerci giorni per trovarlo. Lo stesso vale per un database quando cerchi un record tra i milioni di righe archiviate in una tabella.
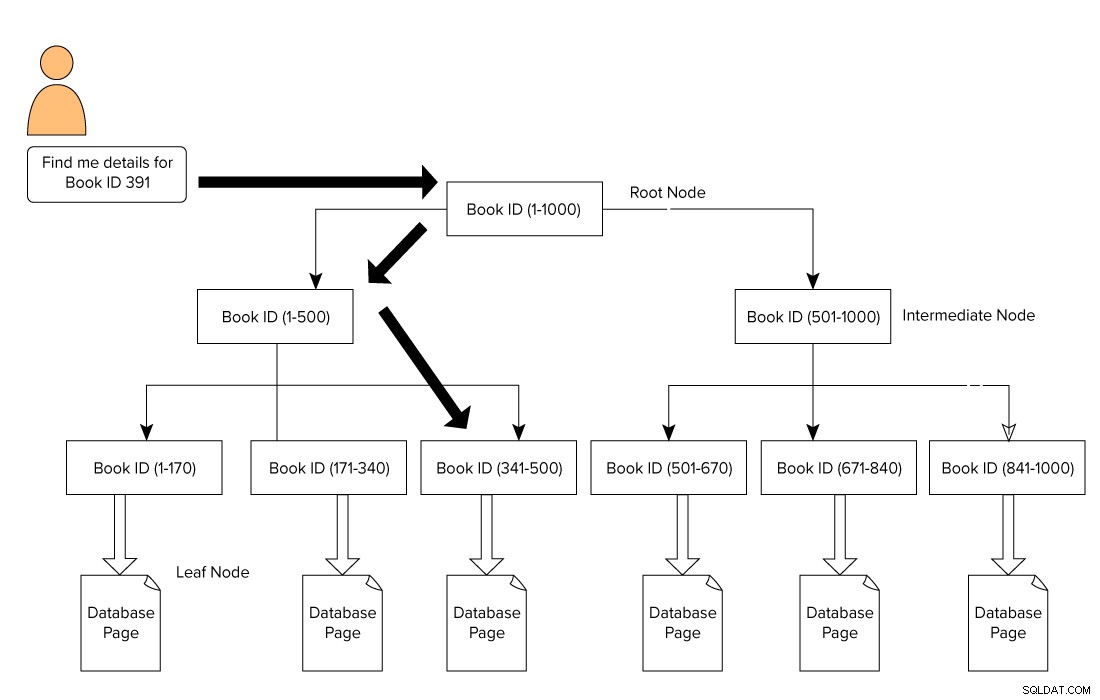
Un indice di SQL Server ha la forma di un formato B-Tree che consiste in un nodo radice nella parte superiore e un nodo foglia nella parte inferiore. Per il nostro esempio di libri della biblioteca, un utente invia una query per cercare un libro con l'ID 391. In questo caso, il motore di query inizia ad attraversare dal nodo radice e si sposta al nodo foglia.
Nodo radice –> nodo intermedio –> nodo foglia.
Il motore di query cerca la pagina di riferimento nel livello intermedio. In questo esempio, il primo nodo intermedio è costituito da ID libro da 1 a 500 e il secondo nodo intermedio è composto da 501-1000.
Sulla base del nodo intermedio, il motore di query attraversa il B-Tree per cercare il nodo intermedio corrispondente e il nodo foglia. Questo nodo foglia può essere costituito da dati effettivi o puntare alla pagina dati effettiva in base al tipo di indice. Nell'immagine seguente, vediamo come attraversare l'indice per cercare i dati utilizzando gli indici di SQL Server. In questo caso, SQL Server non deve scorrere ogni pagina, leggerla e cercare un contenuto specifico per l'ID libro.
Impatti degli indici sulle prestazioni di SQL Server
Nell'esempio della libreria precedente, abbiamo esaminato i potenziali impatti sulle prestazioni dell'indice. Diamo un'occhiata alle prestazioni della query con e senza un indice.
Supponiamo di richiedere i dati per [SalesOrderID] 56958 dalla tabella [SalesOrderDetail_Demo].
SELECT *
DA [AdventureWorks].[Sales].[SalesOrderDetail_Demo]
dove SalesOrderID=56958
Questa tabella non ha indici su di essa. Una tabella senza indici viene chiamata tabella heap in SQL Server.
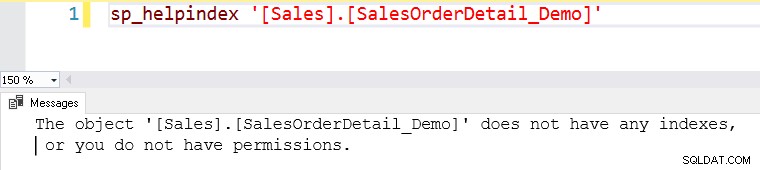
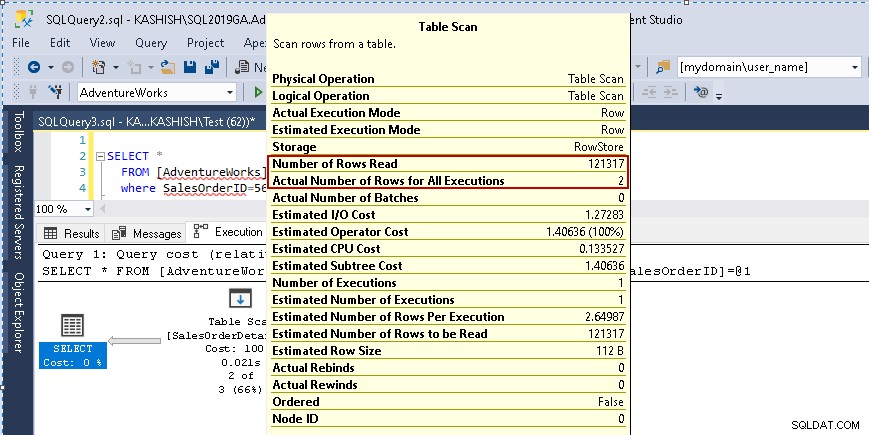
Da qui, vorresti eseguire l'istruzione select sopra e visualizzare il piano di esecuzione effettivo. Questa tabella contiene 121317 record. Esegue una scansione della tabella, il che significa che legge tutte le righe in una tabella per trovare il [SalesOrderID] specifico.
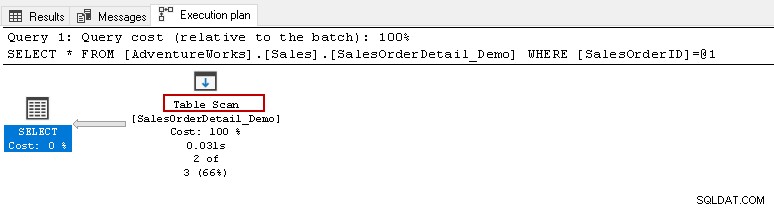
Quando passi il cursore sull'icona Scansione tabella, mostra che il set di risultati effettivo contiene 2 righe, ma a questo scopo legge tutte le righe in quella tabella.
- Numero di righe letto:121317
- Il numero effettivo di righe per l'esecuzione:2
Ora, pensa a una tabella con milioni o miliardi di righe. Non è consigliabile scorrere tutti i record nella tabella per filtrare alcune righe. In un ampio sistema di database di elaborazione delle transazioni online (OLTP), non utilizza le risorse del server (CPU, IO, memoria) in modo efficace, pertanto l'utente potrebbe incontrare problemi di prestazioni.
Ora, eseguiamo l'istruzione select sopra con la tabella con indici. Questa tabella ha un indice cluster di chiave primaria e due indici non cluster nelle colonne [ProductID] e [rowguid]. Parleremo più avanti dei diversi tipi di indici in SQL Server.
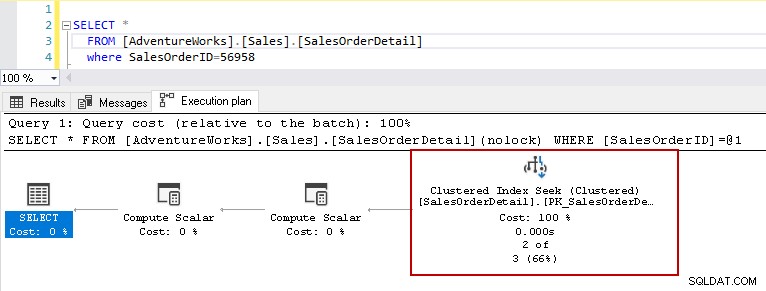
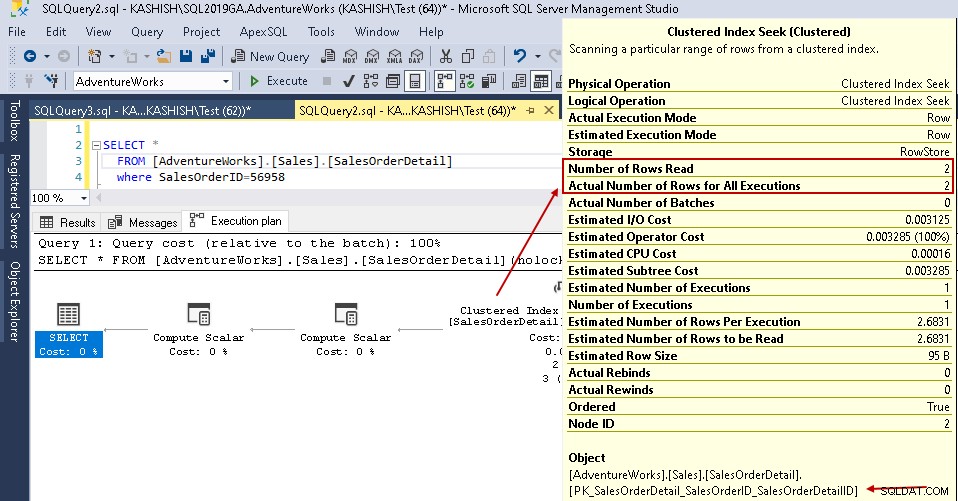
Ora, se esegui nuovamente l'istruzione select con lo stesso predicato, il piano di esecuzione mostra il problema di prestazioni. Query Optimizer decide di utilizzare la ricerca dell'indice cluster al posto di una scansione dell'indice cluster.
Nei dettagli di ricerca dell'indice cluster, mostra che Query Optimizer ha letto con precisione le righe che ha fornito nell'output.
Per fornirti un'analisi comparativa, confrontiamo il piano di esecuzione con e senza un indice di SQL Server. Puoi fare riferimento all'articolo di SQL Shack Come confrontare i piani di esecuzione delle query nell'articolo di SQL Server 2016 per ulteriori approfondimenti.
Per questo esempio, guarda i valori evidenziati nella ricerca dell'indice cluster e nella scansione della tabella:
- Letture logiche:il motore di database di SQL Server legge una pagina dalla cache del buffer e provoca una lettura logica. Di seguito, vediamo che le letture logiche vengono ridotte da 1715 a 3 una volta creato l'indice.
- Anche il costo stimato della CPU scende da 0,133527 a 0,00016
- Il costo di I/O stimato scende da 1,27283 a 0,003125
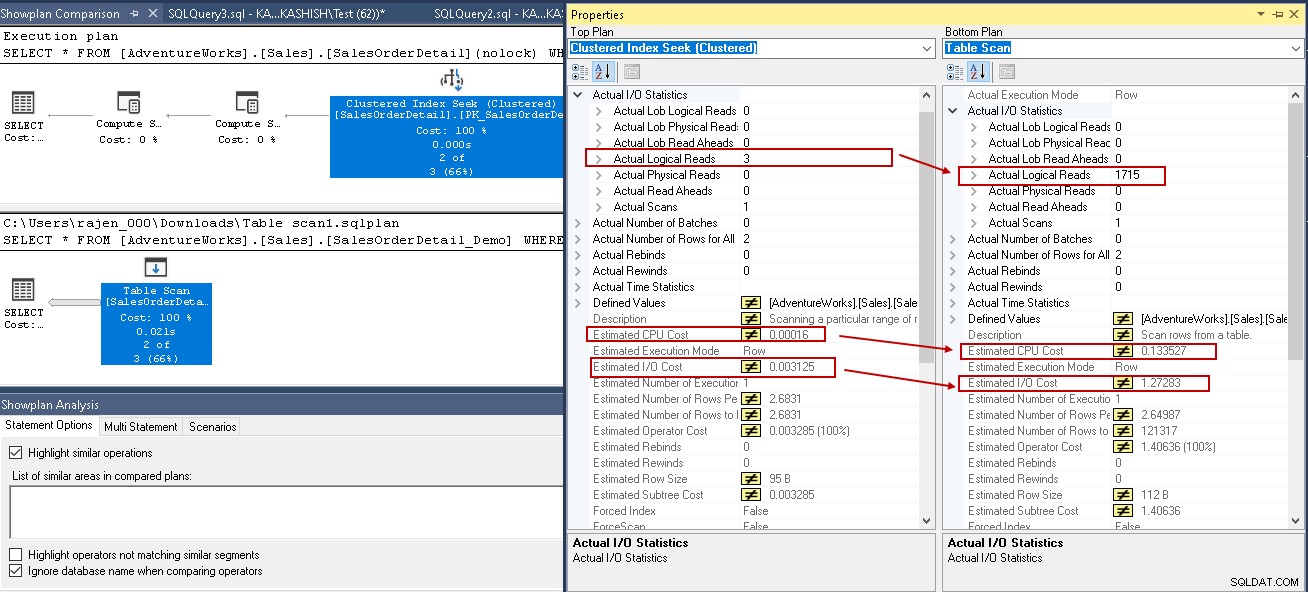
L'immagine seguente mostra una differenza tra una scansione tabella e una ricerca indice.
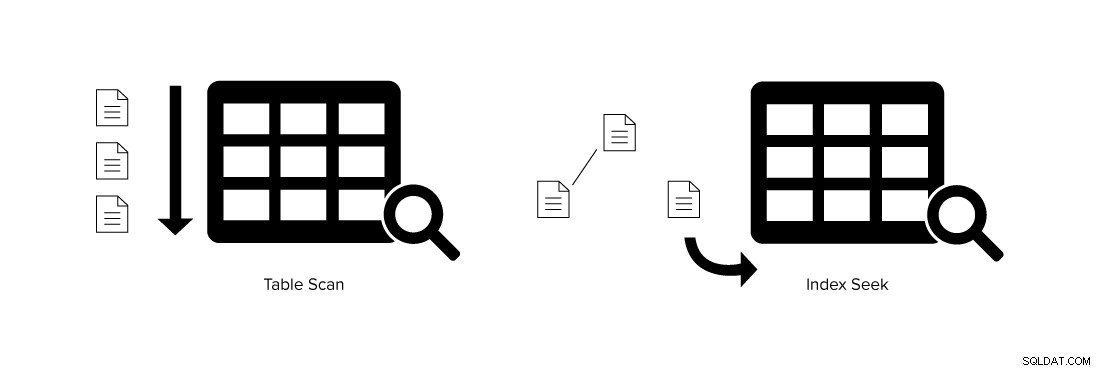
Indici buoni (utili) e indici non validi in SQL Server
Come suggerisce il nome, un buon indice migliora le prestazioni delle query e riduce al minimo l'utilizzo delle risorse. Un indice può ridurre le prestazioni delle query in SQL Server? A volte creiamo l'indice su una colonna specifica, ma non viene mai utilizzato. Supponiamo di avere un indice su una colonna e di eseguire molti inserimenti e aggiornamenti per quella colonna. Per ogni aggiornamento è richiesto anche il corrispondente aggiornamento dell'indice. Se il tuo carico di lavoro ha più attività di scrittura e hai molti indici su una colonna, rallenterebbe le prestazioni complessive delle tue query. Un indice inutilizzato potrebbe anche causare un rallentamento delle prestazioni per le istruzioni selezionate. Query Optimizer utilizza le statistiche per creare un piano di esecuzione. Legge tutti gli indici e il relativo campionamento dei dati e, in base a ciò, crea un piano di esecuzione delle query ottimizzato. Puoi monitorare l'utilizzo dell'indice utilizzando la visualizzazione a gestione dinamica sys.dm_db_index_usage_stats e monitorare le risorse, come la scansione degli utenti, le ricerche degli utenti e le ricerche degli utenti.
Tipi di indici di SQL Server e considerazioni
SQL Server dispone di due indici principali:indici cluster e non cluster. Un indice cluster archivia i dati effettivi nel nodo foglia dell'indice. Ordina fisicamente i dati all'interno delle pagine di dati in base alla chiave dell'indice cluster. SQL Server consente un indice cluster per tabella. Puoi unire più colonne per creare una chiave di indice cluster. Un indice non cluster è un indice logico e ha la colonna della chiave dell'indice che punta alla chiave dell'indice cluster.
Possiamo avere anche altri indici in SQL Server come indice XML, indice archivio colonne, indice spaziale, indice full-text, indice hash, ecc.
È necessario considerare i seguenti punti prima di creare un indice in SQL Server:
- Carico di lavoro
- La colonna su cui è richiesto l'indice
- Misura del tavolo
- Ordine crescente o decrescente dei dati delle colonne
- Ordine colonna
- Tipo di indice
- Fattore di riempimento, indice pad e ordinamento TempDB
Vantaggi, implicazioni e consigli dell'indice di SQL Server
Gli indici in un database possono essere un'arma a doppio taglio. Un utile indice di SQL Server migliora la query e le prestazioni del sistema senza influire sulle altre query. D'altra parte, se crei un indice senza alcuna preparazione o considerazione, potrebbe causare un degrado delle prestazioni, un lento recupero dei dati e potrebbe consumare risorse più critiche come CPU, IO e memoria. Gli indici aumentano anche le attività di manutenzione del database. Tenendo presenti questi fattori, è sempre meglio testare un indice appropriato in un ambiente di pre-produzione con il carico di lavoro equivalente alla produzione, quindi analizzare le prestazioni e decidere se è meglio implementarlo in un database di produzione. Ci sono molti altri consigli da tenere in considerazione, controlla le mie migliori 11 migliori pratiche dell'indice per ulteriori approfondimenti.