Quando si lavora a un progetto costituito da molti microservizi, è probabile che includa anche più database.
Ad esempio, potresti avere un database MySQL e un database PostgreSQL, entrambi in esecuzione su server separati.
Di solito, per unire i dati dei due database, dovresti introdurre un nuovo microservizio che unisca i dati insieme. Ma questo aumenterebbe la complessità del sistema.
In questo tutorial, utilizzeremo Materialise per unire MySQL e Postgres in una vista materializzata dal vivo. Saremo quindi in grado di interrogarlo direttamente e ottenere risultati da entrambi i database in tempo reale utilizzando SQL standard.
Materialise è un database di streaming disponibile all'origine scritto in Rust che mantiene i risultati di una query SQL (una vista materializzata) in memoria quando i dati cambiano.
Il tutorial include un progetto demo che puoi iniziare a utilizzare docker-compose .
Il progetto demo che utilizzeremo monitorerà gli ordini sul nostro sito Web fittizio. Genererà eventi che potrebbero, in seguito, essere utilizzati per inviare notifiche quando un carrello è stato abbandonato per molto tempo.
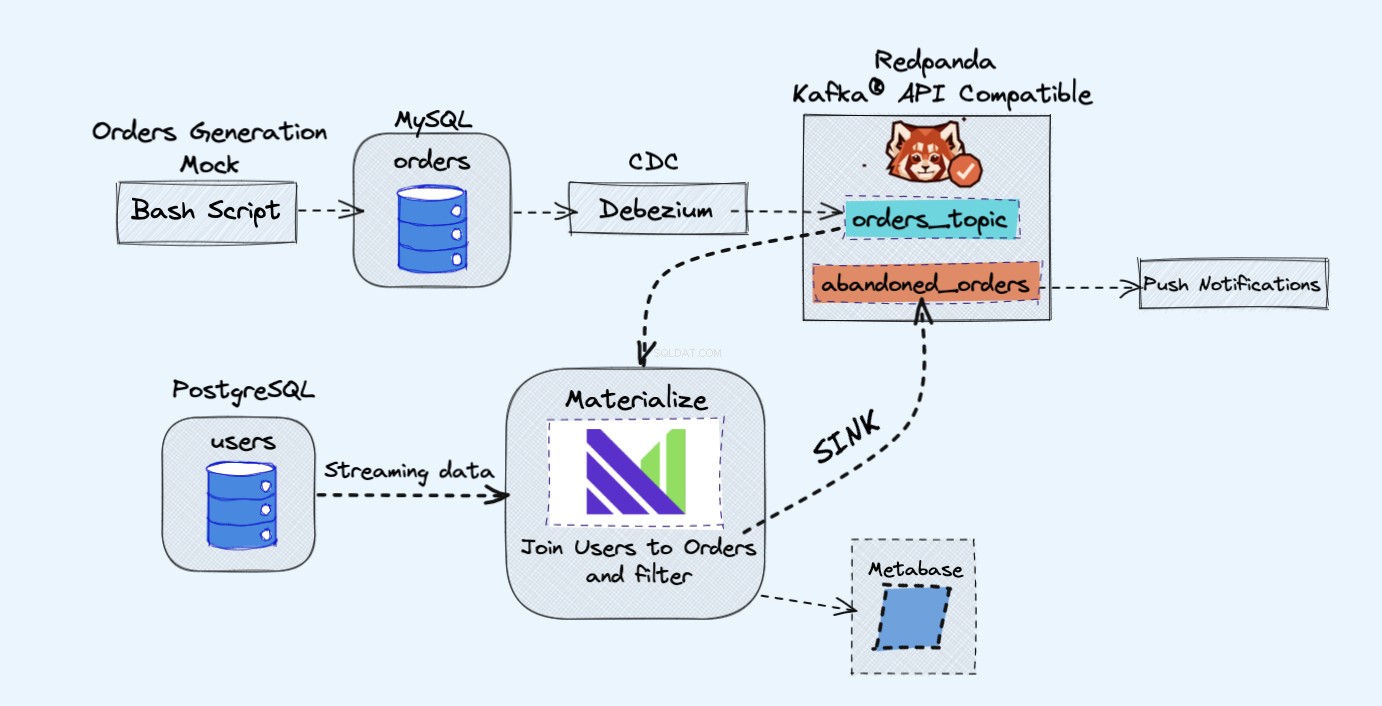
L'architettura del progetto demo è la seguente:
Prerequisiti
Tutti i servizi che utilizzeremo nella demo verranno eseguiti all'interno dei contenitori Docker, in questo modo non dovrai installare alcun servizio aggiuntivo sul tuo laptop o server anziché Docker e Docker Compose.
Nel caso in cui Docker e Docker Compose non siano già installati, puoi seguire le istruzioni ufficiali su come farlo qui:
- Installa Docker
- Installa Docker Compose
Panoramica
Come mostrato nel diagramma sopra, avremo i seguenti componenti:
- Un servizio fittizio per generare continuamente ordini.
- Gli ordini verranno archiviati in un database MySQL .
- Quando si verificano le scritture del database, Debezium trasmette le modifiche da MySQL a un Redpanda argomento.
- Avremo anche un Postgres database dove possiamo ottenere i nostri utenti.
- Quindi inseriremo questo argomento di Redpanda in Materiale direttamente insieme agli utenti dal database di Postgres.
- In Materialise uniremo i nostri ordini e gli utenti, faremo dei filtri e creeremo una vista materializzata che mostra le informazioni sul carrello abbandonato.
- Creeremo quindi un sink per inviare i dati del carrello abbandonato a un nuovo argomento Redpanda.
- Alla fine utilizzeremo Metabase per visualizzare i dati.
- Potresti, in seguito, utilizzare le informazioni di quel nuovo argomento per inviare notifiche ai tuoi utenti e ricordare loro che hanno un carrello abbandonato.
Come nota a margine qui, staresti perfettamente bene usando Kafka invece di Redpanda. Mi piace solo la semplicità che Redpanda porta in tavola, dato che puoi eseguire una singola istanza di Redpanda invece di tutti i componenti Kafka.
Come eseguire la demo
Innanzitutto, inizia clonando il repository:
git clone https://github.com/bobbyiliev/materialize-tutorials.git
Dopodiché puoi accedere alla directory:
cd materialize-tutorials/mz-join-mysql-and-postgresql
Iniziamo eseguendo prima il contenitore Redpanda:
docker-compose up -d redpanda
Costruisci le immagini:
docker-compose build
Infine, avvia tutti i servizi:
docker-compose up -d
Per avviare Materialise CLI, puoi eseguire il seguente comando:
docker-compose run mzcli
Questa è solo una scorciatoia per un container Docker con postgres-client pre installato. Se hai già psql potresti eseguire psql -U materialize -h localhost -p 6875 materialize invece.
Come creare una fonte di Materialise Kafka
Ora che sei nella CLI di Materialise, definiamo gli orders tabelle nel mysql.shop database come fonti Redpanda:
CREATE SOURCE orders
FROM KAFKA BROKER 'redpanda:9092' TOPIC 'mysql.shop.orders'
FORMAT AVRO USING CONFLUENT SCHEMA REGISTRY 'https://redpanda:8081'
ENVELOPE DEBEZIUM;
Se dovessi controllare le colonne disponibili da orders sorgente eseguendo la seguente istruzione:
SHOW COLUMNS FROM orders;
Potresti vedere che, poiché Materialise sta estraendo i dati dello schema del messaggio dal registro di Redpanda, conosce i tipi di colonna da utilizzare per ogni attributo:
name | nullable | type
--------------+----------+-----------
id | f | bigint
user_id | t | bigint
order_status | t | integer
price | t | numeric
created_at | f | text
updated_at | t | timestamp
Come creare viste materializzate
Successivamente, creeremo la nostra prima vista materializzata, per ottenere tutti i dati dagli orders Fonte Redpanda:
CREATE MATERIALIZED VIEW orders_view AS
SELECT * FROM orders;
CREATE MATERIALIZED VIEW abandoned_orders AS
SELECT
user_id,
order_status,
SUM(price) as revenue,
COUNT(id) AS total
FROM orders_view
WHERE order_status=0
GROUP BY 1,2;
Ora puoi utilizzare SELECT * FROM abandoned_orders; per vedere i risultati:
SELECT * FROM abandoned_orders;
Per ulteriori informazioni sulla creazione di viste materializzate, consulta la sezione Viste materializzate della documentazione Materialise.
Come creare una sorgente Postgres
Esistono due modi per creare una fonte Postgres in Materialise:
- Utilizzare Debezium proprio come abbiamo fatto con il sorgente MySQL.
- Utilizzo di Postgres Materialise Source, che ti consente di connettere Materialise direttamente a Postgres in modo da non dover utilizzare Debezium.
Per questa demo, useremo Postgres Materialise Source solo come dimostrazione su come usarlo, ma sentiti libero di usare invece Debezium.
Per creare un Postgres Materialise Source esegui la seguente istruzione:
CREATE MATERIALIZED SOURCE "mz_source" FROM POSTGRES
CONNECTION 'user=postgres port=5432 host=postgres dbname=postgres password=postgres'
PUBLICATION 'mz_source';
Un rapido riassunto della dichiarazione di cui sopra:
MATERIALIZED:Materializza i dati dell'origine PostgreSQL. Tutti i dati sono conservati in memoria e rendono direttamente selezionabili le sorgenti.mz_source:Il nome del sorgente PostgreSQL.CONNECTION:I parametri di connessione di PostgreSQL.PUBLICATION:la pubblicazione PostgreSQL, contenente le tabelle da trasmettere in streaming a Materialise.
Una volta creato il sorgente PostgreSQL, per poter interrogare le tabelle PostgreSQL, dovremmo creare viste che rappresentino le tabelle originali della pubblicazione a monte.
Nel nostro caso, abbiamo solo una tabella chiamata users quindi l'istruzione che dovremmo eseguire è:
CREATE VIEWS FROM SOURCE mz_source (users);
Per vedere le viste disponibili eseguire la seguente istruzione:
SHOW FULL VIEWS;
Una volta fatto, puoi interrogare direttamente le nuove viste:
SELECT * FROM users;
Quindi, andiamo avanti e creiamo altre visualizzazioni.
Come creare un lavabo Kafka
I sink ti consentono di inviare dati da Materialise a una fonte esterna.
Per questa demo utilizzeremo Redpanda.
Redpanda è compatibile con l'API Kafka e Materialise può elaborare i dati da esso proprio come elaborerebbe i dati da una fonte Kafka.
Creiamo una vista materializzata, che conterrà tutti gli ordini non pagati ad alto volume:
CREATE MATERIALIZED VIEW high_value_orders AS
SELECT
users.id,
users.email,
abandoned_orders.revenue,
abandoned_orders.total
FROM users
JOIN abandoned_orders ON abandoned_orders.user_id = users.id
GROUP BY 1,2,3,4
HAVING revenue > 2000;
Come puoi vedere, qui ci stiamo effettivamente unendo agli users view che sta importando i dati direttamente dalla nostra fonte Postgres e il abandond_orders vista che sta importando i dati dall'argomento Redpanda, insieme.
Creiamo un Sink dove invieremo i dati della vista sopra materializzata:
CREATE SINK high_value_orders_sink
FROM high_value_orders
INTO KAFKA BROKER 'redpanda:9092' TOPIC 'high-value-orders-sink'
FORMAT AVRO USING
CONFLUENT SCHEMA REGISTRY 'https://redpanda:8081';
Ora se dovessi connetterti al contenitore Redpanda e utilizzare il rpk topic consume comando, sarai in grado di leggere i record dall'argomento.
Tuttavia, al momento, non saremo in grado di visualizzare in anteprima i risultati con rpk perché è formattato in AVRO. Molto probabilmente Redpanda lo implementerà in futuro, ma per il momento possiamo effettivamente trasmettere l'argomento in Materialise per confermare il formato.
Innanzitutto, ottieni il nome dell'argomento che è stato generato automaticamente:
SELECT topic FROM mz_kafka_sinks;
Uscita:
topic
-----------------------------------------------------------------
high-volume-orders-sink-u12-1637586945-13670686352905873426
Per ulteriori informazioni su come vengono generati i nomi degli argomenti, consulta la documentazione qui.
Quindi crea una nuova fonte materializzata da questo argomento Redpanda:
CREATE MATERIALIZED SOURCE high_volume_orders_test
FROM KAFKA BROKER 'redpanda:9092' TOPIC ' high-volume-orders-sink-u12-1637586945-13670686352905873426'
FORMAT AVRO USING CONFLUENT SCHEMA REGISTRY 'https://redpanda:8081';
Assicurati di cambiare il nome dell'argomento di conseguenza!
Infine, interroga questa nuova vista materializzata:
SELECT * FROM high_volume_orders_test LIMIT 2;
Ora che hai i dati nell'argomento, puoi fare in modo che altri servizi si colleghino ad esso e li consumino e quindi attivino e-mail o avvisi, ad esempio.
Come collegare la metabase
Per accedere all'istanza della metabase, visita https://localhost:3030 se stai eseguendo la demo in locale o https://your_server_ip:3030 se stai eseguendo la demo su un server. Quindi segui i passaggi per completare la configurazione della metabase.
Assicurati di selezionare Materializza come origine dei dati.
Una volta pronto sarai in grado di visualizzare i tuoi dati proprio come faresti con un database PostgreSQL standard.
Come interrompere la demo
Per interrompere tutti i servizi, esegui il seguente comando:
docker-compose down
Conclusione
Come puoi vedere, questo è un esempio molto semplice di come utilizzare Materialise. Puoi utilizzare Materialise per importare dati da una varietà di origini e quindi trasmetterli in streaming a una varietà di destinazioni.
Risorse utili:
CREATE SOURCE: PostgreSQLCREATE SOURCECREATE VIEWSSELECT