In un articolo precedente, abbiamo esaminato i requisiti dell'indice di SQL Server e le considerazioni sulle prestazioni. Quando si tratta di prestazioni del database, l'ottimizzazione delle prestazioni è senza dubbio una delle funzioni più importanti e complesse. È costituito da molte aree diverse come l'ottimizzazione delle query SQL, l'ottimizzazione dell'indice e l'ottimizzazione delle risorse di sistema, che devono essere tutte eseguite correttamente per recuperare rapidamente i dati con successo.
Esistono diverse aree importanti da considerare quando si tratta di indici di SQL Server, poiché possono avere un impatto significativo sia sugli sforzi di ottimizzazione delle prestazioni che sulle prestazioni complessive del database. Di seguito sono riportati alcuni dettagli su ciascuno e sui ruoli critici che svolgono.
Best practice per gli indici di SQL Server
1. Scopri in che modo la progettazione del database influisce sugli indici di SQL Server
I requisiti di indicizzazione variano tra i database di elaborazione delle transazioni online (OLTP) e di elaborazione analitica online (OLAP).
In un database OLTP, gli utenti eseguono frequenti operazioni di lettura-scrittura, inserendo nuovi dati e modificando quelli esistenti. Usano le query del linguaggio di manipolazione dei dati (Inserisci, Aggiorna, Elimina) insieme alle istruzioni Select per il recupero e le modifiche dei dati. Per i database OLTP, è meglio creare indici nella colonna Selected di una tabella. Più indici potrebbero avere un impatto negativo sulle prestazioni e stressare le risorse di sistema. Si consiglia invece di creare il numero minimo di indici in grado di soddisfare i requisiti di indicizzazione. Nei database OLAP, invece, si utilizzano principalmente le istruzioni Select per recuperare i dati per ulteriori scopi analitici. In questo caso, puoi aggiungere più indici con più colonne chiave per indice. Puoi anche sfruttare gli indici columnstore per un recupero più rapido dei dati nelle query di data warehouse
2. Crea indici per i requisiti del tuo carico di lavoro
Quando crei una nuova tabella nel tuo database, non limitarti ad aggiungere gli indici alla cieca. A volte, gli sviluppatori inseriscono un indice in cluster e alcuni indici non in cluster senza cercare le query che utilizzano tali indici. Potrebbe essere presente un indice che non soddisfa i requisiti di Query Optimizer; pertanto, è necessario analizzare correttamente il carico di lavoro e le query SQL (procedure archiviate, funzioni, viste e query ad hoc). Puoi acquisire il carico di lavoro utilizzando SQL Profiler, eventi estesi e viste a gestione dinamica, quindi creare indici per ottimizzare le query a uso intensivo di risorse.
3. Crea indici per le query più pesanti e utilizzate di frequente
È importante raggruppare i carichi di lavoro per le query più utilizzate nel sistema. Creando i migliori indici per queste query, sottoporrà il tuo sistema al minimo sforzo.
4. Applicare le best practice per la colonna della chiave dell'indice di SQL Server
Poiché puoi avere più colonne in una tabella, ecco alcune considerazioni per le colonne della chiave di indice.
- Le colonne con text, image, ntext, varchar(max), nvarchar(max) e varbinary(max) non possono essere utilizzate nelle colonne della chiave dell'indice.
- Si consiglia di utilizzare un tipo di dati intero nella colonna della chiave dell'indice. Ha un ingombro ridotto e funziona in modo efficiente. Per questo motivo, ti consigliamo di creare la colonna della chiave primaria, di solito su un tipo di dati intero.
- Puoi utilizzare solo il tipo di dati XML in un indice XML.
- Dovresti considerare di creare una chiave primaria per la colonna con valori univoci. Se una tabella non ha colonne di valori univoci, puoi definire una colonna di identità per un tipo di dati intero. Una chiave primaria crea anche un indice cluster per la distribuzione delle righe.
- Puoi considerare una colonna con i valori Unique e Not NULL come un utile candidato per la chiave di indice.
- Dovresti creare un indice basato sui predicati nella clausola Where. Ad esempio, puoi considerare le colonne utilizzate nella clausola Where, i join SQL, come order by, group by predicati e così via.
- Dovresti unire le tabelle in modo da ridurre il numero di righe per il resto della query. Ciò aiuterà Query Optimizer a preparare il piano di esecuzione con risorse di sistema minime.
- Se utilizzi più colonne per una chiave di indice, è anche essenziale considerare la loro posizione nella chiave di indice.
- Dovresti anche considerare l'utilizzo di colonne incluse nei tuoi indici.
5. Analizza la distribuzione dei dati delle colonne dell'indice di SQL Server
È necessario esaminare la distribuzione dei dati nelle colonne della chiave dell'indice di SQL Server. Una colonna con valori non univoci potrebbe causare un ritardo nel recupero dei dati e causare una transazione di lunga durata. Puoi analizzare la distribuzione dei dati utilizzando l'istogramma nelle statistiche.
6. Usa l'ordinamento dei dati
Dovresti anche considerare i requisiti di ordinamento dei dati nelle tue query e negli indici. Per impostazione predefinita, SQL Server ordina i dati in ordine crescente in un indice. Si supponga di creare un indice in ordine crescente, ma le query utilizzano la clausola Order By per ordinare i dati in ordine decrescente.
Ad esempio, guarda il piano di esecuzione effettivo della query seguente.
SELECT [SalesOrderID],
[UnitPrice]
FROM [AdventureWorks].[Sales].[SalesOrderDetail]
ORDER BY UnitPrice DESC,
SalesOrderID ASC;
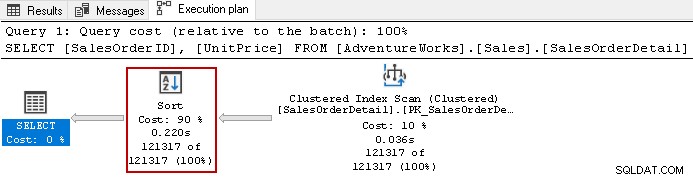
Utilizza l'operatore di ordinamento costoso con un costo complessivo del 90% in questa query. Abbiamo deciso di creare un indice non cluster su [UnitPrice] e [SalesOrderID]. Utilizza un ordinamento predefinito per entrambe le colonne nell'indice.
CREATE NONCLUSTERED INDEX IX_SalesOrderDetail_Unitprice
ON [AdventureWorks].[Sales].[SalesOrderDetail]
(UnitPrice ASC, SalesOrderID ASC);
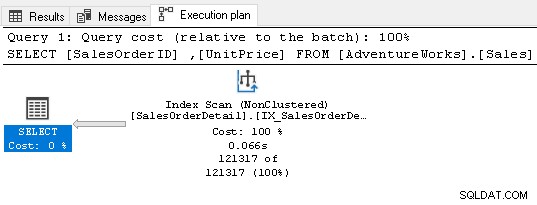
Abbiamo eseguito nuovamente l'istruzione Select e Query Optimizer utilizza ancora l'operatore di ordinamento. Può utilizzare l'indice non cluster ma ordina i dati per preparare il risultato.
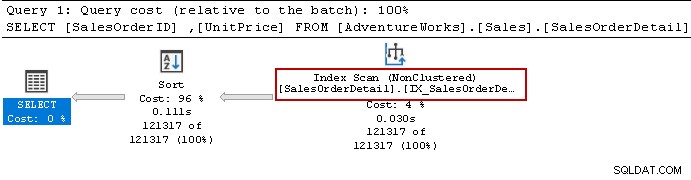
Ricreiamo l'indice utilizzando la query seguente. Questa volta ordina i dati in ordine decrescente per [Unitprice] nella definizione dell'indice.
DROP INDEX IX_SalesOrderDetail_Unitprice ON [AdventureWorks].[Sales].[SalesOrderDetail];
Go CREATE NONCLUSTERED INDEX IX_SalesOrderDetail_Unitprice ON [AdventureWorks].[Sales].[SalesOrderDetail](UnitPrice DESC, SalesOrderID ASC);
Go
Non richiede alcun operatore di ordinamento ora perché l'indice soddisfa i requisiti della query.
7. Usa chiavi esterne per il tuo indice SQL Server
Dovresti creare un indice sulle colonne delle chiavi esterne. È consigliabile creare un indice cluster sulla chiave esterna per migliorare le prestazioni della query.
8. Prestare attenzione alle considerazioni sull'archiviazione degli indici di SQL Server
Anche la memorizzazione degli indici è un aspetto utile da considerare. SQL Server crea tutti gli indici nello stesso filegroup della tabella. Puoi considerare un filegroup separato per gli indici e separare il file fisico su un disco separato. Ciò aumenterà le prestazioni IO e il throughput.
Allo stesso modo, puoi utilizzare il partizionamento delle tabelle per separare i dati su più dischi e filegroup. Puoi progettare indici partizionati per queste partizioni di tabelle per migliorare l'accesso simultaneo ai dati.
Un'altra opzione consiste nel definire FILLFACTOR durante la creazione o la ricostruzione di un indice. Un FILLFACTOR definisce lo spazio libero nelle pagine di dati del nodo foglia. È utile per ulteriori inserimenti di dati. Se i tuoi dati sono statici e non cambiano frequentemente, puoi considerare un valore elevato di FILLFACTOR. D'altra parte, per i dati che cambiano frequentemente, puoi lasciare spazio sufficiente per nuovi inserimenti di dati.
9. Trova gli indici mancanti
A volte, si ottengono informazioni su un indice di SQL Server mancante nel piano di esecuzione della query. Puoi anche eseguire le viste a gestione dinamica per trovare questi indici mancanti. Non dovresti creare alla cieca questi indici. Si tratta semplicemente di un suggerimento di Query Optimizer, ma non tiene conto dell'indice esistente o dei requisiti del carico di lavoro. Potrebbe anche includere più colonne nella definizione dell'indice, quindi esamina questi suggerimenti prima di implementarlo.
10. Crea sempre un indice cluster prima di un indice non cluster
Come linea guida generale, dovresti creare un indice cluster prima di creare indici non cluster. Se una tabella non ha un indice, un indice non cluster è costituito da identificatori di riga. Dopo aver creato un indice cluster, SQL Server deve ricostruire questi indici non cluster in modo che possano puntare alla chiave dell'indice cluster anziché agli identificatori di riga.
11. Monitora la manutenzione dell'indice e aggiorna le statistiche
Di seguito sono elencate diverse aree di manutenzione da monitorare quando si tratta di indici di SQL Server.
- Rimuovi la frammentazione dell'indice :dovresti rivedere regolarmente le frammentazioni interne ed esterne, in particolare per le tabelle di transazioni elevate. Le tue query potrebbero rispondere lentamente anche se disponi di indici appropriati per i tuoi carichi di lavoro. Un indice fortemente frammentato potrebbe ridurre le prestazioni perché richiede IO aggiuntivo. È possibile eseguire una riorganizzazione o ricostruire un indice in base ai suoi valori di frammentazione. Di solito, dovresti ricostruire l'indice se ha una frammentazione maggiore del 30% e riorganizzarlo se ha una frammentazione inferiore al 30%.
- Rimuovi gli indici inutilizzati: Dovresti sempre rivedere gli indici inutilizzati (inattivi) nel tuo database perché Query Optimizer deve prenderli in considerazione per ogni query. Un indice inutilizzato consuma anche spazio di archiviazione e aumenta i costi di manutenzione.
- Aggiorna le statistiche: È necessario aggiornare periodicamente le statistiche anche se sono state impostate le statistiche di aggiornamento automatico all'interno della configurazione del database. Query Optimizer potrebbe preparare un piano di esecuzione errato se le statistiche dell'indice non vengono aggiornate. È possibile pianificare un processo agente per aggiornare le statistiche di SQL Server con un'analisi completa dopo l'orario di lavoro.
Puoi fare riferimento a Manutenzione dell'indice SQL per ulteriori approfondimenti su questo argomento.
Applicazione delle best practice per gli indici di SQL Server
Sebbene non ci sia sempre un modo semplice per progettare un indice SQL Server ottimale, l'applicazione dei consigli specificati in questo post ti aiuterà a navigare tra i vari requisiti di indicizzazione che incontrerai con ogni tipo di database e i relativi carichi di lavoro. Queste best practice ti aiuteranno a ottimizzare i tuoi indici per migliorare le prestazioni del database e garantire un processo di ottimizzazione delle prestazioni più fluido lungo il percorso.