Nei database relazionali creiamo tabelle per archiviare dati in vari formati. SQL ServerSQL Server archivia i dati in un formato di riga e colonna che contiene un valore associato a ciascun tipo di dati. Quando progettiamo tabelle SQL, definiamo tipi di dati come intero, float, decimale, varchar e bit. Ad esempio, una tabella che memorizza i dati dei clienti potrebbe avere campi come nome del cliente, e-mail, indirizzo, stato, paese e così via. Vari comandi SQL vengono eseguiti su una tabella SQL e possono essere suddivisi nelle seguenti categorie:
- Data Definition Language (DDL): Questi comandi vengono utilizzati per creare e modificare gli oggetti del database in un database.
- Crea: Crea oggetti
- Modifica: Modifica gli oggetti
- Rilascio: Elimina gli oggetti
- Tronca: Elimina tutti i dati da una tabella
- Lingua di manipolazione dei dati (DML): Questi comandi inseriscono, recuperano, modificano, eliminano e aggiornano i dati nel database.
- Seleziona: Recupera i dati da una o più tabelle
- Inserisci: Aggiunge nuovi dati in una tabella
- Aggiornamento: Modifica i dati esistenti
- Elimina: Elimina i record esistenti in una tabella
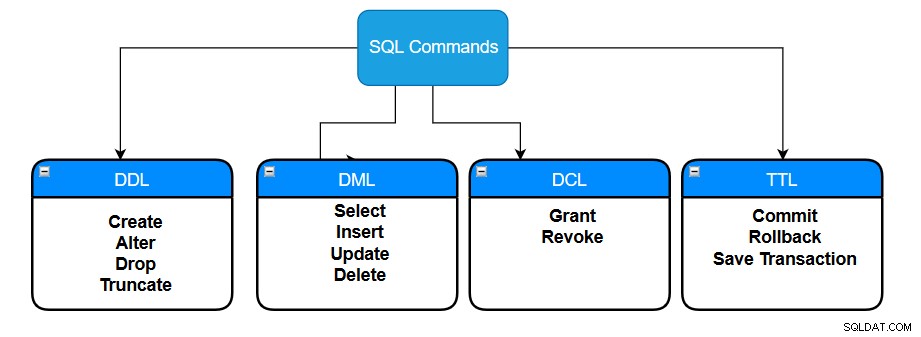
- Lingua di controllo dei dati (DCL): Questi comandi sono associati a diritti o controlli di autorizzazione in un database.
- Concessione: Assegna le autorizzazioni a un utente
- Revocare: Revoca le autorizzazioni a un utente
- Linguaggio di controllo delle transazioni (TCL): Questi comandi controllano le transazioni in un database.
- Impegnati: Salva le modifiche apportate dalla query
- Ripristino: Riporta una transazione esplicita o implicita all'inizio della transazione o a un punto di salvataggio all'interno della transazione
- Salva le transazioni: Imposta un punto di salvataggio o un marker all'interno di una transazione
Si supponga di avere i dati degli ordini dei clienti archiviati in una tabella SQL. Se continuassi a inserire dati in questa tabella continuamente, la tabella potrebbe contenere milioni di record, il che causerebbe problemi di prestazioni all'interno delle tue applicazioni. Anche la manutenzione dell'indice potrebbe richiedere molto tempo. Spesso non è necessario conservare gli ordini più vecchi di tre anni. In questi casi, puoi eliminare quei record dalla tabella. Ciò farebbe risparmiare spazio di archiviazione e ridurrebbe gli sforzi di manutenzione.
Puoi rimuovere i dati da una tabella SQL in due modi:
- Utilizzo di un'istruzione di eliminazione SQL
- Utilizzo di un troncamento
Vedremo la differenza tra questi comandi SQL in seguito. Esploriamo prima l'istruzione SQL delete.
Un'istruzione di eliminazione SQL senza alcuna condizione
Nelle istruzioni del linguaggio di manipolazione dei dati (DML), un'istruzione di eliminazione SQL rimuove le righe da una tabella. È possibile eliminare una riga specifica o tutte le righe. Un'istruzione di eliminazione di base non richiede alcun argomento.
Creiamo una tabella SQL degli ordini utilizzando lo script seguente. Questa tabella ha tre colonne [OrderID], [ProductName] e [ProductQuantity].
Create Table Orders( OrderID int,ProductName varchar(50),ProductQuantity int)
Inserisci alcuni record in questa tabella.
Insert into Orders values (1,'ABC books',10),(2,'XYZ',100),(3,'SQL book',50)
Supponiamo ora di voler eliminare i dati della tabella. È possibile specificare il nome della tabella per rimuovere i dati utilizzando l'istruzione delete. Entrambe le istruzioni SQL sono le stesse. Possiamo specificare il nome della tabella dalla parola chiave (opzionale) o specificare il nome della tabella subito dopo l'eliminazione.
Delete OrdersGoDelete from OrdersGO
Un'istruzione di eliminazione SQL con dati filtrati
Queste istruzioni di eliminazione SQL eliminano tutti i dati della tabella. Di solito, non rimuoviamo tutte le righe da una tabella SQL. Per rimuovere una riga specifica, possiamo aggiungere una clausola where con l'istruzione delete. La clausola where contiene i criteri di filtro e alla fine determina quali righe rimuovere.
Ad esempio, supponiamo di voler rimuovere l'id ordine 1. Dopo aver aggiunto una clausola where, SQL Server verifica prima le righe corrispondenti e rimuove quelle righe specifiche.Delete Orders where orderid=1
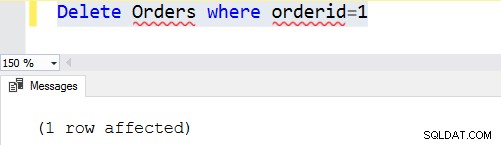
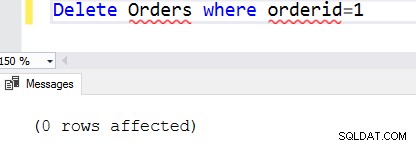
Se la condizione della clausola where è falsa, non rimuove alcuna riga. Ad esempio, abbiamo rimosso l'ordinato 1 dalla tabella degli ordini. Se eseguiamo di nuovo l'istruzione, non trova alcuna riga che soddisfi la condizione della clausola where. In questo caso, restituisce 0 righe interessate.
Istruzione di eliminazione SQL e clausola TOP
È possibile utilizzare anche l'istruzione TOP per eliminare le righe. Ad esempio, la query seguente elimina le prime 100 righe dalla tabella Ordini.
Delete top (100) [OrderID]from Orders
Poiché non abbiamo specificato alcun "ORDINA PER", seleziona le righe casuali e le elimina. Possiamo utilizzare la clausola Order by per ordinare i dati ed eliminare le prime righe. Nella query seguente, ordina [OrderID] in ordine decrescente, quindi lo elimina dalla tabella [Ordini].
Delete from Orders where [OrderID] In(Select top 100 [OrderID] FROM Ordersorder by [OrderID] Desc)
Eliminazione di righe in base a un'altra tabella
A volte è necessario eliminare le righe in base a un'altra tabella. Questa tabella potrebbe esistere o meno nello stesso database.
- Ricerca tabella
Possiamo usare il metodo di ricerca della tabella o il join SQL per eliminare queste righe. Ad esempio, vogliamo eliminare le righe dalla tabella [Ordini] che soddisfano la seguente condizione:
Dovrebbe avere le righe corrispondenti nella tabella [dbo].[Customer].
Guarda la query seguente, qui abbiamo un'istruzione select nella clausola where dell'istruzione delete. SQL Server ottiene prima le righe che soddisfano l'istruzione select, quindi rimuove tali righe dalla tabella [Ordini] utilizzando l'istruzione SQL delete.
Delete Orders where orderid in(Select orderidfrom Customer)
- Unisciti a SQL
In alternativa, possiamo utilizzare i join SQL tra queste tabelle e rimuovere le righe. Nella query seguente, uniamo le tabelle [Ordini]] con la tabella [Cliente]. Un join SQL funziona sempre su una colonna comune tra le tabelle. Abbiamo una colonna [OrderID] che unisce entrambe le tabelle.
DELETE OrdersFROM Orders oINNER JOIN Customer c ON o.orderid=c.orderid
Per comprendere l'istruzione di eliminazione di cui sopra, esaminiamo il piano di esecuzione effettivo.
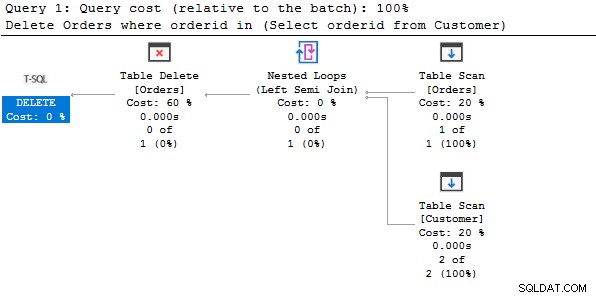
Secondo il piano di esecuzione, esegue una scansione della tabella su entrambe le tabelle, ottiene i dati corrispondenti e li elimina dalla tabella Ordini.
- Espressione di tabella comune (CTE)
Possiamo anche usare un'espressione di tabella comune (CTE) per eliminare le righe da una tabella SQL. Innanzitutto, definiamo un CTE per trovare la riga che vogliamo rimuovere.
Quindi, uniamo il CTE con la tabella SQL Orders ed eliminiamo le righe.
WITH cteOrders AS(SELECT OrderIDFROM CustomerWHERE CustomerID = 1 )DELETE OrdersFROM cteOrders spINNER JOIN dbo.Orders o ON o.orderid = sp.orderid;
Impatti sulla gamma di identità
Le colonne Identity in SQL Server generano valori sequenziali univoci per la colonna. Vengono utilizzati principalmente per identificare in modo univoco una riga nella tabella SQL. Una colonna di chiave primaria è anche una buona scelta per un indice cluster in SQL Server.
Nello script seguente, abbiamo una tabella [Impiegato]. Questa tabella ha un ID colonna Identity.
Create Table Employee(id int identity(1,1),[Name] varchar(50))
Abbiamo inserito 50 record in questa tabella che hanno generato i valori di identità per la colonna id.
Declare @id int=1While(@id<=50)BEGINInsert into Employee([Name]) values('Test'+CONVERT(VARCHAR,@ID))Set @id=@id+1END
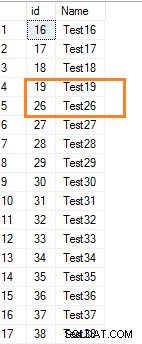
Se eliminiamo alcune righe dalla tabella SQL, non reimposta i valori di identità per i valori successivi. Ad esempio, eliminiamo alcune righe con valori di identità compresi tra 20 e 25.
Delete from employeewhere id between 20 and 25
Ora, visualizza i record della tabella.
Select * from employee where id>15Mostra il divario nell'intervallo di valori di identità.
Istruzione di eliminazione SQL e registro delle transazioni
L'eliminazione SQL registra l'eliminazione di ogni riga nel registro delle transazioni. Supponi di dover eliminare milioni di record da una tabella SQL. Non si desidera eliminare un numero elevato di record in una singola transazione perché potrebbe causare una crescita esponenziale del file di registro e anche il database potrebbe non essere disponibile. Se annulli una transazione nel mezzo, potrebbero essere necessarie ore per eseguire il rollback di un'istruzione di eliminazione.
In questo caso, dovresti sempre eliminare le righe in piccoli blocchi e impegnarli regolarmente. Ad esempio, puoi eliminare un batch di 10.000 righe alla volta, eseguirne il commit e passare al batch successivo. Quando SQL Server esegue il commit del blocco, è possibile controllare la crescita del registro delle transazioni.
Best practice
- Dovresti sempre eseguire un backup prima di eliminare i dati.
- Per impostazione predefinita, SQL Server utilizza le transazioni implicite ed esegue il commit dei record senza chiedere all'utente. Come best practice, dovresti avviare una transazione esplicita utilizzando Begin Transaction. Ti dà il controllo per eseguire il commit o il rollback della transazione. Dovresti anche eseguire backup frequenti del registro delle transazioni se il tuo database è in modalità di ripristino completo.
- Vuoi eliminare i dati in piccoli blocchi per evitare un utilizzo eccessivo del registro delle transazioni. Evita anche i blocchi per altre transazioni SQL.
- Dovresti limitare le autorizzazioni in modo che gli utenti non possano eliminare i dati. Solo gli utenti autorizzati dovrebbero avere accesso per rimuovere i dati da una tabella SQL.
- Vuoi eseguire l'istruzione delete con una clausola where. Rimuove i dati filtrati da una tabella SQL. Se l'applicazione richiede l'eliminazione frequente dei dati, è una buona idea reimpostare periodicamente i valori di identità. In caso contrario, potresti dover affrontare problemi di esaurimento del valore dell'identità.
- Nel caso si desideri svuotare la tabella, è consigliabile utilizzare l'istruzione truncate. L'istruzione truncate rimuove tutti i dati da una tabella, utilizza la registrazione minima delle transazioni, reimposta l'intervallo di valori di identità ed è più veloce dell'istruzione SQL delete perché dealloca immediatamente tutte le pagine della tabella.
- Nel caso in cui utilizzi vincoli di chiave esterna (relazione genitore-figlio) per le tue tabelle, dovresti eliminare la riga da una riga figlia e quindi dalla tabella padre. Se elimini la riga dalla riga padre, puoi anche utilizzare l'opzione di eliminazione a cascata per eliminare automaticamente la riga da una tabella figlio. Puoi fare riferimento all'articolo: Elimina in sequenza e aggiorna in sequenza nella chiave esterna di SQL Server per ulteriori approfondimenti.
- Se si utilizza l'istruzione top per eliminare le righe, SQL Server elimina le righe in modo casuale. Dovresti sempre utilizzare la clausola superiore con la clausola Order by e Group by corrispondente.
- Un'istruzione delete acquisisce un blocco di intenti esclusivo sulla tabella di riferimento; pertanto, durante tale periodo, nessun'altra transazione può modificare i dati. Puoi usare il suggerimento NOLOCK per leggere i dati.
- Dovresti evitare di usare l'hint della tabella per sovrascrivere il comportamento di blocco predefinito dell'istruzione SQL delete; dovrebbe essere utilizzato solo da DBA e sviluppatori esperti.
Considerazioni importanti
Ci sono molti vantaggi nell'usare le istruzioni di eliminazione SQL per rimuovere i dati da una tabella SQL, ma come puoi vedere, richiede un approccio metodico. È importante eliminare sempre i dati in piccoli lotti e procedere con cautela durante l'eliminazione dei dati da un'istanza di produzione. Avere una strategia di backup per recuperare i dati nel minor tempo possibile è fondamentale per evitare tempi di inattività o impatti futuri sulle prestazioni.