
I professionisti del database devono confrontarsi di routine con problemi di prestazioni del database come indicizzazione impropria e codice scritto male nelle istanze SQL di produzione. Si supponga di aver aggiornato una transazione e SQL Server ha segnalato il seguente messaggio di deadlock. Per i DBA appena agli inizi, questo potrebbe essere uno shock.

In questo articolo esploreremo i deadlock di SQL Server e i modi migliori per evitarli.
Che cos'è un deadlock di SQL Server?
SQL Server è un database altamente transazionale. Si supponga, ad esempio, di supportare il database di un portale di acquisti online in cui si ricevono nuovi ordini dai clienti 24 ore su 24. È probabile che più utenti stiano svolgendo la stessa attività contemporaneamente. In questo caso, il tuo database dovrebbe seguire le proprietà di Atomicità, Consistenza, Isolamento, Durabilità (ACID) per essere coerente, affidabile e proteggere l'integrità dei dati.
L'immagine seguente descrive le proprietà ACID in un database relazionale.
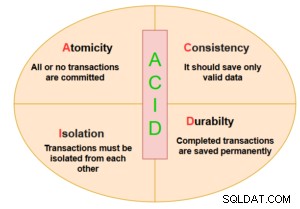
Per seguire le proprietà ACID, SQL Server utilizza meccanismi di blocco, vincoli e registrazione write-ahead. Vari tipi di blocco includono:blocco esclusivo(X), blocco condiviso(S), blocco aggiornamento (U), blocco intento (I), blocco schema (SCH) e blocco aggiornamento in blocco (BU). Questi blocchi possono essere acquisiti a livello di chiave, tabella, riga, pagina e database.
Supponiamo di avere due utenti, John e Peter, collegati al database dei clienti.
- John vuole aggiornare i record per il cliente che ha [customerid] 1.
- Allo stesso tempo, Peter vuole recuperare il valore per il cliente che ha [customerid] 1.
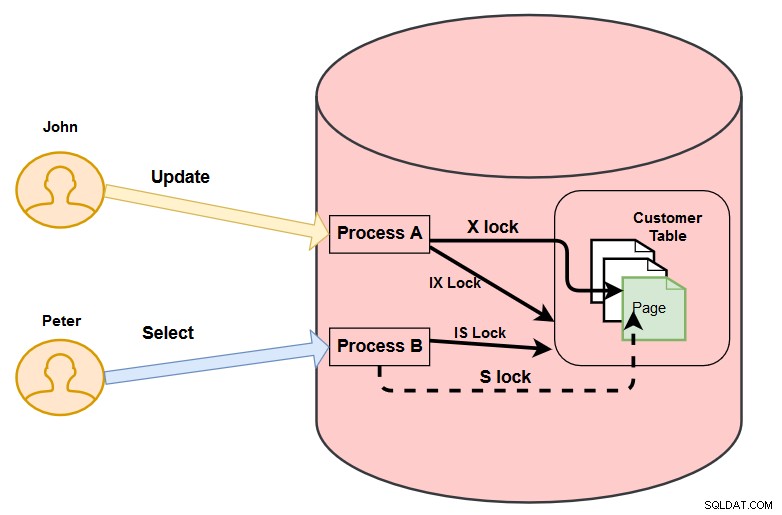
In questo caso, SQL Server utilizza i seguenti blocchi sia per John che per Peter.
Serrature per Giovanni
- Richiede un blocco intento esclusivo (IX) sulla tabella del cliente e sulla pagina che contiene il record.
- Ci vuole inoltre un blocco (X) esclusivo sulla riga che John vuole aggiornare. Impedisce a qualsiasi altro utente di modificare i dati della riga fino a quando il processo A non rilascia il blocco.
Serrature per Peter
- Acquisisce un blocco di intent shared (IS) sulla tabella del cliente e sulla pagina che contiene il record come da clausola where.
- Cerca di prendere un blocco condiviso per leggere la riga. Questa riga ha già un blocco esclusivo per John.
In questo caso, Peter deve aspettare che John finisca il suo lavoro e rilasci il blocco esclusivo. Questa situazione è nota come blocco.
Supponiamo ora che in un altro scenario, John e Peter abbiano i seguenti blocchi.
- John ha un blocco esclusivo sulla tabella cliente per l'ID cliente 1.
- Peter ha un blocco esclusivo sulla tabella degli ordini per l'ID cliente 1.
- John richiede un blocco esclusivo sulla tabella degli ordini per completare la sua transazione. Peter ha già un blocco esclusivo sulla tabella degli ordini.
- Peter richiede un blocco esclusivo sul tavolo del cliente per completare la sua transazione. John ha già un blocco esclusivo sulla tabella dei clienti.
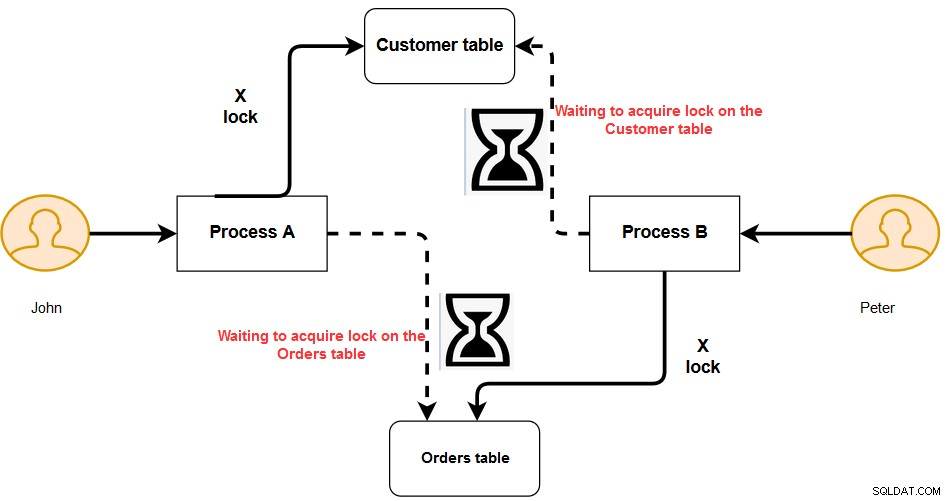
In questo caso, nessuna delle transazioni può procedere perché ogni transazione richiede una risorsa detenuta dall'altra transazione. Questa situazione è nota come deadlock di SQL Server.
Meccanismi di monitoraggio del deadlock di SQL Server
SQL Server esegue il monitoraggio periodico delle situazioni di deadlock utilizzando il thread di monitoraggio del deadlock. Questo controlla i processi coinvolti in un deadlock e identifica se una sessione è diventata una vittima di deadlock. Utilizza un meccanismo interno per identificare il processo vittima di deadlock. Per impostazione predefinita, la transazione con la minor quantità di risorse necessarie per il rollback è considerata una vittima.
SQL Server interrompe la sessione della vittima in modo che un'altra sessione possa acquisire il blocco richiesto per completare la transazione. Per impostazione predefinita, SQL Server verifica la situazione di deadlock ogni 5 secondi utilizzando il monitoraggio di deadlock. Se rileva un deadlock, potrebbe ridurre la frequenza da 5 secondi a 100 millisecondi a seconda dell'occorrenza del deadlock. Reimposta nuovamente il thread di monitoraggio a 5 secondi se non si verificano frequenti deadlock.
Una volta che SQL Server termina un processo come vittima di deadlock, verrà visualizzato il messaggio seguente. In questa sessione, l'ID processo 69 è stato vittima di un deadlock.

L'impatto dell'utilizzo delle istruzioni di priorità deadlock di SQL Server
Per impostazione predefinita, SQL Server contrassegna la transazione con il rollback meno costoso come vittima di un deadlock. Gli utenti possono impostare la priorità del deadlock in una transazione utilizzando l'istruzione DEADLOCK_PRIORITY.
SET DEADLOCK_PRIORITYUtilizza i seguenti argomenti:
- Basso:equivale a priorità deadlock -5
- Normale:è la priorità di deadlock predefinita 0
- Alto:è la priorità di deadlock più alta 5.
Possiamo anche impostare valori numerici per la priorità deadlock da -10 a 10 (21 valori totali).
Diamo un'occhiata ad alcuni esempi di istruzioni di priorità deadlock.
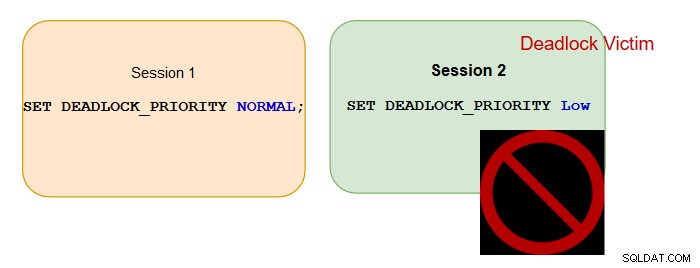
Esempio 1:
Sessione 1 con priorità deadlock:Normale (0)> Sessione 2 con priorità deadlock:Bassa (-5)
Vittima di stallo: Sessione 2
Esempio 2:
Sessione 1 con priorità deadlock:Normale (0)
Vittima di stallo: Sessione 1
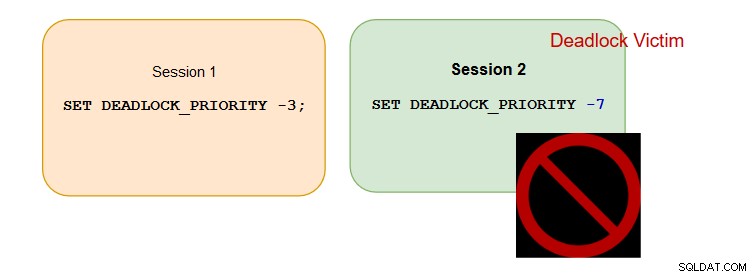
Esempio 3
Sessione 1 con priorità deadlock:-3> Sessione 2 con priorità deadlock:-7
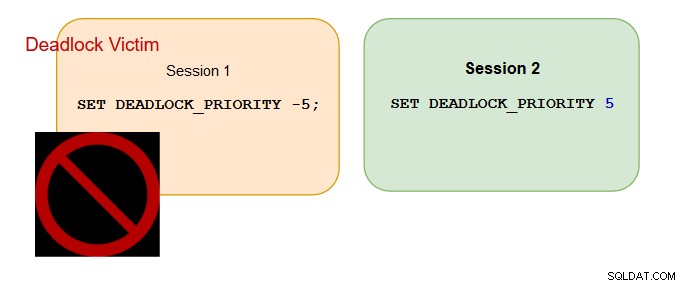
Esempio 4:
Sessione 1 con priorità deadlock:-5
Vittima di stallo: Sessione 1
Un grafico deadlock è una rappresentazione visiva dei processi di deadlock, dei relativi blocchi e della vittima del deadlock. Possiamo abilitare i flag di traccia 1204 e 1222 per acquisire informazioni dettagliate sui deadlock in un formato grafico e XML. Possiamo utilizzare l'evento esteso system_health predefinito per ottenere i dettagli del deadlock. Un modo semplice e veloce per interpretare il deadlock è attraverso un grafico di deadlock. Simuliamo una condizione di deadlock e visualizziamo il relativo grafico di deadlock.
Per questa dimostrazione, abbiamo creato la tabella Clienti e Ordini e inserito alcuni record di esempio.
Quindi, abbiamo aperto una nuova finestra di query e abilitato il flag di traccia a livello globale.
Traceon DBCC(1222,-1)
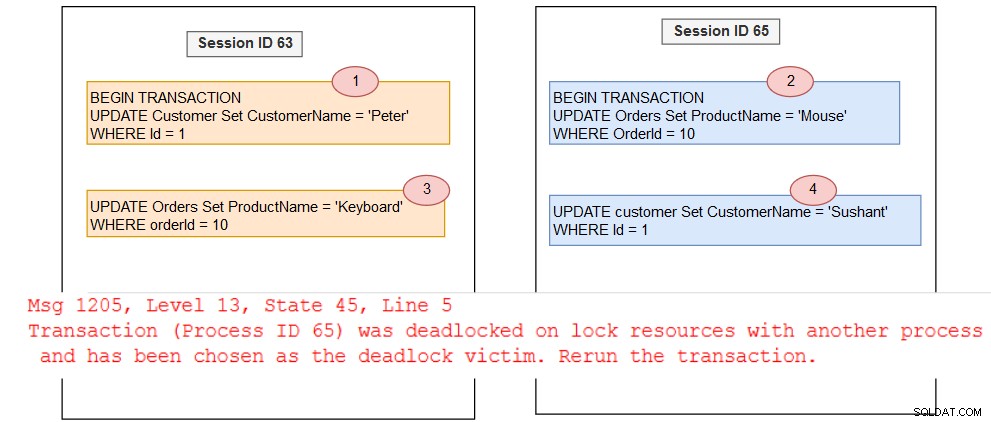
Dopo aver abilitato il flag di traccia deadlock, abbiamo avviato due sessioni ed eseguito la query nell'ordine seguente:
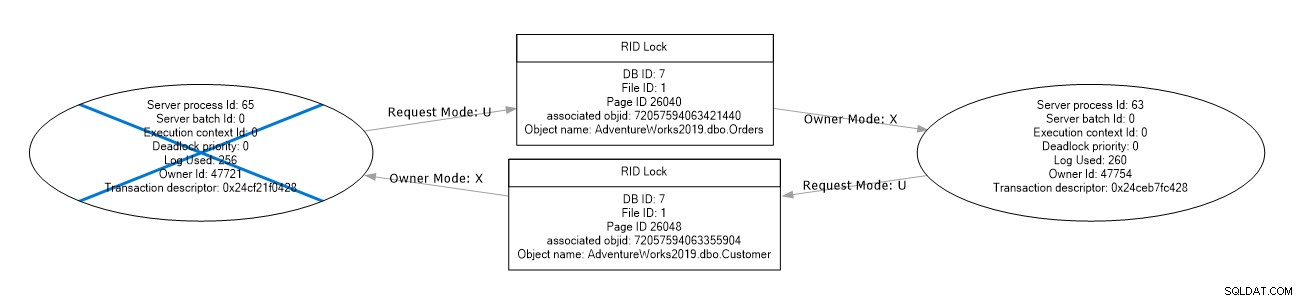
In questo esempio, SQL Server sceglie una vittima di deadlock (ID sessione 65) e termina la transazione. Recuperiamo il grafico del deadlock dalla sessione dell'evento esteso system_health.
Questa query fornisce un XML deadlock che richiede un DBA esperto per interpretare le informazioni.
Salviamo questo XML deadlock utilizzando l'estensione .XDL e quando apriamo il file XDL in SSMS, otteniamo il grafico deadlock mostrato di seguito.
Questo grafico deadlock fornisce le seguenti informazioni:
Rappresenta una vittima di deadlock cancellando l'ovale nel grafico di deadlock.
È possibile acquisire le informazioni sul deadlock di SQL Server nei seguenti modi:
1) Deadlock per la ricerca dei preferiti
La ricerca nei segnalibri è un deadlock che si trova comunemente in SQL Server. Si verifica a causa di un conflitto tra l'istruzione select e le istruzioni DML (insert, update and delete). In genere, SQL Server sceglie l'istruzione select come vittima di deadlock perché non causa modifiche ai dati e il rollback è rapido. Per evitare la ricerca del segnalibro, puoi utilizzare un indice di copertura. Puoi anche utilizzare un suggerimento per la query NOLOCK nelle istruzioni select, ma legge i dati non vincolati.
2) Deadlock della scansione dell'intervallo
A volte, utilizziamo un livello di isolamento SERIALIZABLE a livello di server o di sessione. È un livello di isolamento restrittivo per il controllo della concorrenza e può creare blocchi di scansione dell'intervallo anziché blocchi a livello di pagina o riga. Nel livello di isolamento SERIALIZABLE, gli utenti non possono leggere i dati se sono modificati ma in attesa di essere confermati in una transazione. Allo stesso modo, se una transazione legge i dati, un'altra transazione non può modificarli. Fornisce la concorrenza più bassa, quindi dovremmo utilizzare questo livello di isolamento nei requisiti dell'applicazione specifici.
3) Deadlock del vincolo a cascata
SQL Server utilizza la relazione padre-figlio tra le tabelle utilizzando i vincoli di chiave esterna. In questo scenario, se aggiorniamo o eliminiamo un record dalla tabella padre, sono necessari i blocchi della tabella figlio per evitare record orfani. Per eliminare questi deadlock, dovresti sempre modificare prima i dati in una tabella figlio seguito dai dati padre. Puoi anche lavorare direttamente con la tabella padre usando le opzioni DELETE CASCADE o UPDATE CASCADE. Dovresti anche creare indici appropriati nelle colonne della chiave esterna.
4) Deadlock del parallelismo tra le query
Dopo che un utente ha inviato una query al motore di query SQL, Query Optimizer crea un piano di esecuzione ottimizzato. Può eseguire la query in un ordine seriale o parallelo a seconda del costo della query, del grado massimo di parallelismo (MAXDOP) e della soglia di costo per il parallelismo.
In una modalità di parallelismo, SQL Server assegna più thread. A volte per una query di grandi dimensioni in modalità parallelismo, questi thread iniziano a bloccarsi a vicenda. Alla fine, si converte in deadlock. In questo caso, è necessario rivedere il piano di esecuzione, il MAXDOP e la soglia di costo per le configurazioni di parallelismo. Puoi anche specificare il MAXDOP a livello di sessione per risolvere lo scenario di deadlock.
5) Invertire il deadlock dell'ordine degli oggetti
In questo tipo di deadlock, più transazioni accedono agli oggetti in un ordine diverso nel T-SQL. Ciò provoca il blocco tra le risorse per ogni sessione e lo converte in un deadlock. Vuoi sempre accedere agli oggetti in un ordine logico in modo che non porti a una situazione di stallo.
I deadlock sono un meccanismo naturale in SQL Server per evitare che la sessione tenga i blocchi e attenda altre risorse. È necessario acquisire le query deadlock e ottimizzarle in modo che non siano in conflitto tra loro. È importante acquisire il blocco per un breve periodo e rilasciarlo, in modo che altre query possano utilizzarlo efficacemente.
I deadlock di SQL Server si verificano e, sebbene SQL Server gestisca internamente le situazioni di deadlock, dovresti provare a ridurle a icona quando possibile. Alcuni dei modi migliori per eliminare i deadlock sono creare un indice, applicare le modifiche al codice dell'applicazione o ispezionare attentamente le risorse in un grafico di deadlock. Per ulteriori suggerimenti su come evitare i deadlock SQL, consulta il nostro post: Evitare i deadlock SQL con l'ottimizzazione delle query.
Deadlock di SQL Server che utilizzano grafici di deadlock
CREATE TABLE Customer (ID INT IDENTITY(1,1), CustomerName VARCHAR(20)) GO CREATE TABLE Orders (OrderID INT IDENTITY(1,1), ProductName VARCHAR(50)) GO INSERT INTO Customer(CustomerName) VALUES ('Rajendra') Go 100 S INSERT INTO Orders(ProductName) VALUES ('Laptop') Go 100
SELECT XEvent.query('(event/data/value/deadlock)[1]') AS DeadlockGraph FROM ( SELECT XEvent.query('.') AS XEvent FROM ( SELECT CAST(target_data AS XML) AS TargetData FROM sys.dm_xe_session_targets st INNER JOIN sys.dm_xe_sessions s ON s.address = st.event_session_address WHERE s.NAME = ‘system_health’ AND st.target_name = ‘ring_buffer’ ) AS Data CROSS APPLY TargetData.nodes('RingBufferTarget/event[@name="xml_deadlock_report"] ') AS XEventData(XEvent) ) AS source;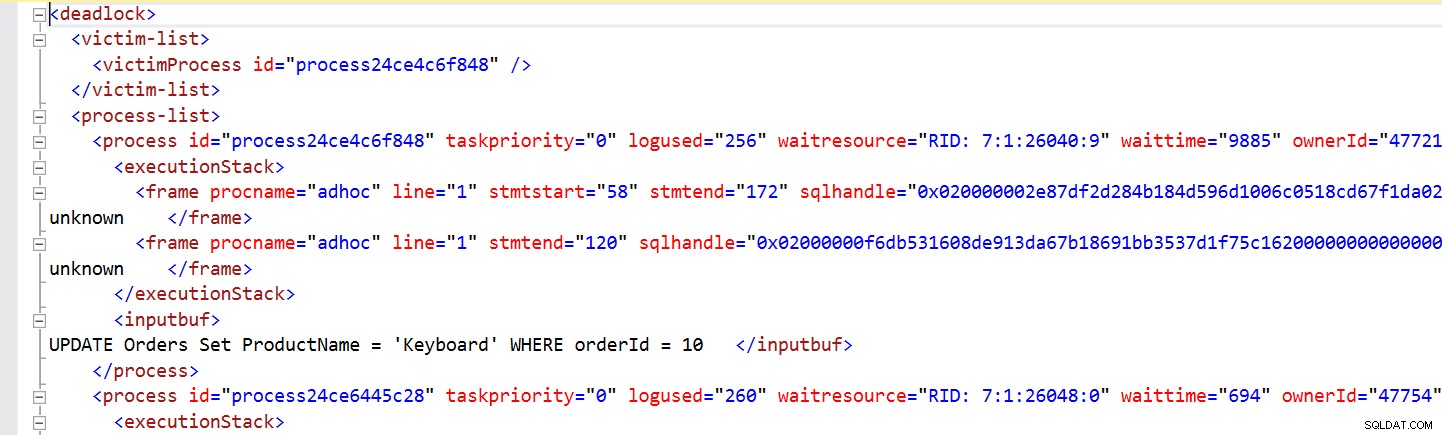
5 tipi di deadlock in SQL Server
Modi utili per evitare e ridurre al minimo i deadlock di SQL Server
Considerazioni sul deadlock di SQL Server



