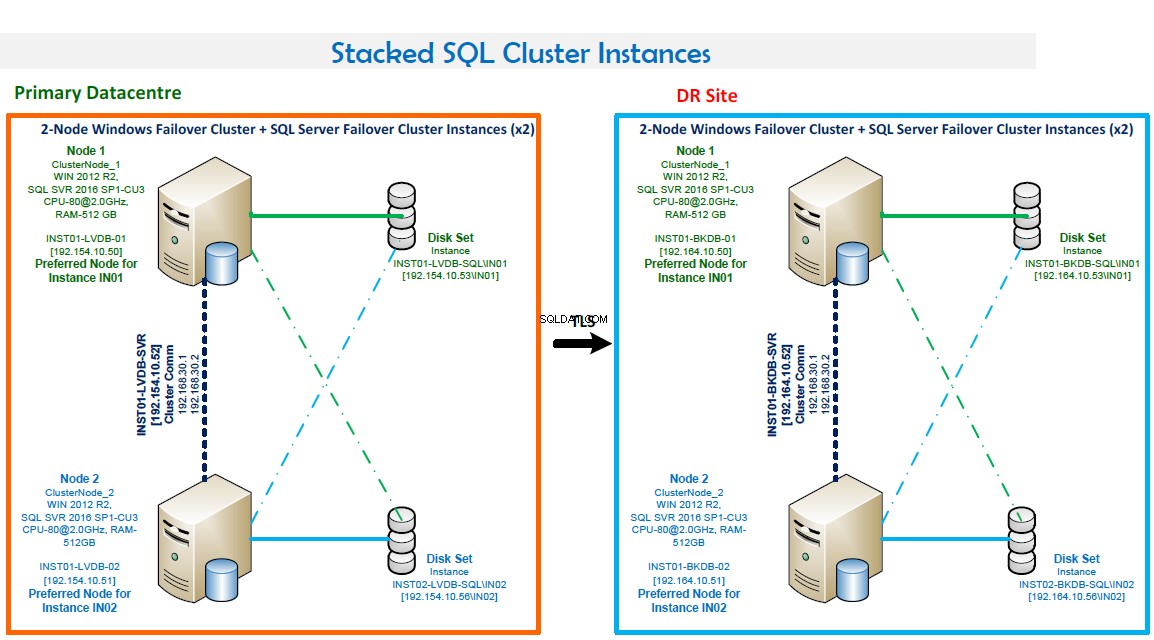
NOTE:
- Gruppo di failover di Windows composto da due nodi.
- Due istanze del cluster di failover di SQL Server. Questa configurazione ottimizza l'hardware. IN01 è preferito sul Nodo1 e IN02 è preferito sul Nodo2.
- Numeri di porta:IN01 è in ascolto sulla porta 1435 e IN02 è in ascolto sulla porta 1436.
- Alta disponibilità. Entrambi i nodi si supportano a vicenda. Il failover è automatico in caso di errore.
- La modalità Quorum è la maggioranza dei nodi e dei dischi.
- Backup LAN in atto e backup di routine configurato utilizzando Veritas
Introduzione
Non è raro che sviluppatori e project manager richiedano una nuova istanza di SQL Server per ogni nuova applicazione o servizio. Mentre tecnologie come la virtualizzazione e il cloud hanno reso la creazione di nuove istanze un gioco da ragazzi, alcune vecchie tecniche integrate in SQL Server consentono di ottenere tempi di risposta ridotti quando è necessario fornire un nuovo database per un nuovo servizio o applicazione. Questo stato di cose può essere creato da un DBA che può progettare e distribuire un cluster di SQL Server di grandi dimensioni in grado di supportare la maggior parte dei database di SQL Server richiesti dall'organizzazione. Ci sono ulteriori vantaggi in questo tipo di consolidamento, come minori costi di licenza, migliore governance e facilità di amministrazione. Nell'articolo evidenzieremo alcune considerazioni che abbiamo avuto l'opportunità di sperimentare utilizzando il clustering e lo stacking come mezzo per consolidare i database di SQL Server.
Raggruppamento
Il clustering di failover di Windows Server è una soluzione ad alta disponibilità molto nota che è sopravvissuta a molte versioni di Windows Server e in cui Microsoft intende continuare a investire e migliorare. Le istanze del cluster di failover di SQL Server si basano su WSFC. Sia l'edizione Standard che quella Enterprise di SQL Server supportano le istanze del cluster di failover di SQL Server, ma l'edizione Standard è limitata a due soli nodi. Il consolidamento dei database su una singola FCI di SQL Server offre vantaggi quali:
- HA per impostazione predefinita — Tutti i database distribuiti su un'istanza di SQL Server in cluster sono a disponibilità elevata per impostazione predefinita! Una volta creata un'istanza in cluster, le nuove distribuzioni vengono gestite in anticipo in termini di HA.
- Facilità di amministrazione – Un minor numero di DBA può dedicare tempo alla configurazione, al monitoraggio e, se necessario, alla risoluzione dei problemi di UN'UNICA istanza in cluster che supporta molte applicazioni. In modo corretto, anche la documentazione dell'istanza è molto più semplice quando si ha a che fare con un ambiente di grandi dimensioni. La configurazione di una soluzione di backup aziendale per gestire tutti i database nel tuo ambiente è facilitata dal fatto che devi eseguire questa configurazione solo una quando utilizzi istanze consolidate.
- Conformità – Requisiti chiave come l'applicazione di patch e persino il rafforzamento possono essere eseguiti una sola volta con tempi di inattività minimi su un gran numero di database in un unico sforzo amministrativo. Nel nostro negozio, abbiamo utilizzato Transaction Log Shipping tra istanze in cluster in due data center per garantire che i database siano protetti dal rischio di disastri.
- Standardizzazione – L'applicazione di standard quali le convenzioni di denominazione, la gestione degli accessi, l'autenticazione di Windows, il controllo e la gestione basata su criteri è molto più semplice quando si ha a che fare con uno o due ambienti a seconda delle dimensioni del negozio
Listato 1: Estrai informazioni sulla tua istanza
-- Extract Instance Details
-- Includes a Column to Check Whether Instance is Clustered
SELECT SERVERPROPERTY('MachineName') AS [MachineName]
, SERVERPROPERTY('ServerName') AS [ServerName]
, SERVERPROPERTY('InstanceName') AS [Instance]
, SERVERPROPERTY('IsClustered') AS [IsClustered]
, SERVERPROPERTY('ComputerNamePhysicalNetBIOS') AS [ComputerNamePhysicalNetBIOS]
, SERVERPROPERTY('Edition') AS [Edition]
, SERVERPROPERTY('ProductLevel') AS [ProductLevel]
, SERVERPROPERTY('ProductVersion') AS [ProductVersion]
, SERVERPROPERTY('ProcessID') AS [ProcessID]
, SERVERPROPERTY('Collation') AS [Collation]
, SERVERPROPERTY('IsFullTextInstalled') AS [IsFullTextInstalled]
, SERVERPROPERTY('IsIntegratedSecurityOnly') AS [IsIntegratedSecurityOnly]
, SERVERPROPERTY('IsHadrEnabled') AS [IsHadrEnabled]
, SERVERPROPERTY('HadrManagerStatus') AS [HadrManagerStatus]
, SERVERPROPERTY('IsXTPSupported') AS [IsXTPSupported];
Accatastamento
SQL Server supporta fino a cinquanta singole istanze su un server e fino a 25 istanze del cluster di failover su un cluster di failover di Windows Server. Diverse versioni di SQL Server possono essere impilate nello stesso ambiente per fornire un ambiente robusto che supporterà applicazioni diverse. In una tale configurazione, l'aggiornamento dei database può assumere la forma della semplice promozione da un'istanza di SQL Server alla versione successiva nello stesso cluster fino all'invecchiamento dell'hardware. Una considerazione fondamentale da tenere a mente durante lo stacking di SQL Server è che è necessario allocare memoria a ciascuna istanza in modo tale che la quantità totale di memoria allocata non superi la memoria disponibile nel sistema operativo. L'altro punto in questa direzione consiste nel garantire che l'account del servizio SQL Server per ogni istanza disponga delle pagine di blocco nei privilegi di memoria. L'assegnazione di pagine di blocco in memoria garantisce che quando SQL Server acquisisce memoria, il sistema operativo non tenti di ripristinare tale memoria quando altri processi sul server necessitano di memoria. La configurazione di un account del servizio SQL Server definito, la configurazione di MAX_SERVER_MEMORY e il privilegio di blocco delle pagine in memoria sono un trio essenziale quando si impilano le istanze di SQL Server.
Microsoft addebita alcune migliaia di dollari per coppia di core della CPU. Lo stacking delle istanze di SQL Server consente di sfruttare questo modello di licenza facendo in modo che le istanze condividano lo stesso set di CPU (sudando la risorsa). Abbiamo già accennato al fatto che è possibile impilare diverse versioni di SQL Server, ad esempio, occupandoti delle applicazioni legacy che eseguono versioni precedenti a SQL Server 2016. Quando si utilizzano edizioni diverse di SQL Server, è possibile prendere in considerazione l'utilizzo dell'affinità del processore come descritto da Glen Berry in questo articolo. L'affinità del processore può anche essere utilizzata per controllare il modo in cui le risorse della CPU vengono condivise tra le istanze, proprio come controlli la memoria. Lo stacking risolve anche i problemi di sicurezza per le applicazioni che devono utilizzare l'account SA, ad esempio, oi problemi di configurazione per le applicazioni che richiedono un'istanza dedicata, o tali opzioni sono un confronto specifico. La preoccupazione per le prestazioni del TempDB condiviso è un altro motivo per cui potresti voler impilare anziché raggruppare tutti i database su un'istanza cluster.
Vale la pena notare che il valore del clustering, come evidenziato in precedenza, si estende ulteriormente con lo stacking. Ad esempio, quando si applica la patch a un'istanza di SQL Server con più FCI, è possibile applicare la patch a tutte le FCI in una volta sola.
Indicazioni da notare
Quando si utilizza il clustering, alcune convenzioni renderanno un po' più semplice l'amministrazione e la gestione dell'ambiente e miglioreranno le risorse. Ne toccheremo brevemente alcuni:
- Strumenti client attuali:potresti riscontrare errori insoliti quando tenti di gestire un'istanza di SQL Server 2016 utilizzando SQL Server Management Studio 2012. Gli errori non indicano specificamente che il problema è la versione dello strumento client. In genere abbiamo un'istanza di SQL Server Management Studio 17.3 sul client che desideriamo utilizzare per connetterci alle nostre istanze.
- Convenzioni di denominazione:una convenzione di denominazione ti consente di essere sicuro dell'istanza su cui stai lavorando in qualsiasi momento. Utilizzando gli alias, puoi ridurre ulteriormente l'onere di ricordare il nome lungo dell'istanza per gli utenti finali che hanno bisogno di accedere al database.
- Nodo preferito:l'impostazione di un nodo preferito per ogni ruolo di SQL Server in Gestione cluster di failover è una buona idea, un buon modo per assicurarsi che la potenza di elaborazione di tutti i nodi del cluster venga utilizzata. Nel nostro negozio, dopo aver impostato i nodi preferiti, abbiamo configurato il ruolo per il failback tra 0500 HRS e 0600 HRS in caso di failover involontario.
- Transaction Log Shipping – Quando si configura il Disaster Recovery per FCI, ha senso identificare tutti i percorsi UNC utilizzando nomi virtuali, non i nomi o l'indirizzo IP dei nodi del cluster. Ciò garantisce che le cose continuino a funzionare correttamente se si verifica un failover. È inoltre molto importante garantire che gli account di SQL Server Agent in entrambi i siti abbiano il controllo completo su questi percorsi.
Listato 2: Configura il monitoraggio per la spedizione del registro delle transazioni tramite e-mail
-- Create Table to Store Log Shipping Data
create table msdb dbo log_shipping_report
(status bit,
is_primary bit,
server sysname,
database_name sysname,
time_since_last_backup int,
last_backup_file nvarchar (500),
backup_threshold int,
is_backup_alert_enabled bit,
time_since_last_copy int,
last_copied_file nvarchar 500),
time_since_last_restore int,
last_restored_file nvarchar(500),
last_restored_latency int,
restore_threshold int,
is_restore_alert_enabled bit);
go
-- Create an SQL Agent Job with the Following Script
-- This will send an Email at Intervals determined by the job Schedule
-- The Job Should be Created on the Log Shipping Secondary Clustered Instance
-- This Job Requires that Database Mail is Enabled
truncate table msdb dbo log_shipping_report
go
insert into msdb dbo log_shipping_report
EXEC sp_help_log_shipping_monitor;
go
/*
select [server]
, database_name [database]
, time_since_last_copy [Last Copy Time]
, last_copied_file [Last Copied File]
, time_since_last_restore [Last Restore Time]
, last_restored_file [Last Restored File]
, restore_threshold [Restore Threshold]
, restore_threshold - time_since_last_restore [Restore Latency]
from msdb.dbo.log_shipping_report;
go
*/
DECLARE @tableHTML NVARCHAR(MAX) ;
DECLARE @SecServer SYSNAME ;
SET @SecServer = @@SERVERNAME
SET @tableHTML =
N'<H1><font face="Verdana" size="4">Transaction Logshipping Status from Secondary
Server ' + @SecServer + N'</H1>' +
N'<p style="margin-top: 0; margin-bottom: 0"><font face="Verdana" size="2">Please
find below status of Secondary databases: </font></p> ' +
N'<table border="1" style="BORDER-COLLAPSE: collapse" borderColor="#111111"
cellPadding="0" width="2000" bgColor="#ffffff" borderColorLight="#000000"
border="1"><font face="Verdana" size="2">' +
N'<tr><th><font face="Verdana" size="2">Secondary Server</th>
<th><font face="Verdana" size="2">Secondary Database</th>
<th><font face="Verdana" size="2">Last Copy Time</th>' +
N'<th><font face="Verdana" size="2">Last Copied File</th><th>
<font face="Verdana" size="2">Last Restore Time</th>' +
N'<th><font face="Verdana" size="2">Last Restored File</th><th>
<font face="Verdana" size="2">Restore Threshold</th>
<th><font face="Verdana" size="2">Restore Latency</th>' +
CAST ( ( SELECT td = lsr.server, '',
td = lsr [database_name], td = lsr time_since_last_copy '',
td = lsr last_copied_file td = lsr time_since_last_restore '',
td = lsr last_restored_file, '',
td = lsr restore_threshold '',
td =
case
when lsr restore_threshold
lsr time_since_last_restore < 0 then + '<td bgcolor="#FFCC99"><b><font face="Verdana"
size="1">' + 'CRITICAL' + '</font></b></td>'
when lsr restore_threshold
lsr time_since_last_restore < 20 and lsr restore_threshold
lsr time_since_last_restore > 0 then + '<td bgcolor="#FFBB33"><b><font face="Verdana
size="1">' + 'WARNING' + '</font></b></td>'
when lsr restore_threshold
lsr time_since_last_restore > 20 then + '<td bgcolor="#21B63F"><b><font face="Verdana
size="1">' + 'OK' + '</font></b></td>'
end , ''
FROM msdb dbo log_shipping_report as lsr
ORDER BY lsr.[database_name]
FOR XML PATH('tr'), TYPE ) AS NVARCHAR(MAX) ) +
N'</table>' + ' ';
EXEC msdb dbo.sp_send_dbmail
@recipients='example@sqldat.com',
@copy_recipients='example@sqldat.com',
@subject = 'Transaction Log Shipping Report',
@body = @tableHTML,
@body_format = 'HTML' ;
Unità disco
Un effetto collaterale dell'impilamento dell'istanza di SQL Server e del provisioning per diversi database è la tendenza a esaurire le lettere di unità. Abbiamo aggirato questo problema configurando i punti di montaggio del volume. Ciascun disco assegnato a un ruolo del cluster è configurato come punto di montaggio con una lettera di unità necessaria solo per una o due unità per istanza. Un punto importante da notare quando si utilizzano punti di montaggio del volume su un cluster è che in futuro, quando sarà necessario aggiungere più punti di montaggio per eseguire attività di manutenzione simili, sarà necessario inserire ENTRAMBE l'unità primaria che possiede la lettera di unità e il montaggio punto in modalità manutenzione sul cluster.
Nel nostro caso, abbiamo trovato il nome di ciascun punto di montaggio del volume in base al ruolo del cluster a cui era stato assegnato. Con così tante unità da gestire, dovresti sicuramente trovare un modo per te e l'amministratore di archiviazione di identificare un disco univoco in modo che mantenere i dischi a livello di archiviazione, ad esempio, non sia una seccatura.
Listato 3: Monitoraggio dell'utilizzo dello spazio su disco quando si utilizzano i punti di montaggio del volume
-- The Following Script Will Show Disk Space Usage from Within SQL Server -- It is Especially Helpful When Using Volume Mount Points -- Volume Mount Point Space Usage Can Also Be Monitored from Computer Management (OS Level) SELECT DISTINCT vs volume_mount_point , vs file_system_type , vs logical_volume_name , CONVERT(DECIMAL!18 2 vs total_bytes 1073741824.0) AS [Total Size (GB)] , CONVERT(DECIMAL(18 2 vs available_bytes 1073741824.0' AS [Available Size (GB)] , CAST(CAST(vs available_bytes AS FLOAT)/ CAST(vs total_bytes AS FLOAT) AS DECIMAL (18,2)) * 100 AS [Space Free %] FROM sys.master_files AS f WITH (NOLOCK) CROSS APPLY sys.dm_os_volume_stats f database_id, f [file_id]i AS vs OPTION (RECOMPILE);
Distribuzione database
Nel nostro caso, la nostra strategia era garantire che i nuovi database seguissero il nostro standard. I database più vecchi sono stati gestiti con un po' più di attenzione poiché stavamo consolidando e aggiornando allo stesso tempo. Database Migration Assistant ci ha aiutato a dirci quali database non sarebbero sicuramente compatibili con la nostra consacrata istanza di SQL Server 2016 e li abbiamo lasciati in pace (alcuni con livelli di compatibilità sono a partire da 100). Ciascun database distribuito dovrebbe avere i propri volumi per i dati e i file di registro a seconda delle dimensioni. L'utilizzo di volumi separati per ciascun database è un altro passo verso la creazione di un ambiente molto ben organizzato, aspetto importante considerando la potenziale complessità di questo ambiente consolidato. L'ultima affermazione implica anche che quando si consente a un'applicazione di creare i propri database, come DBA è necessario riposizionare i file di dati al termine della distribuzione poiché l'applicazione utilizzerà le stesse posizioni dei file utilizzate dal database modello.
Listato 4: Riposizionamento dei database degli utenti
-- 1. Set the database offline -- Be sure to replace DB_NAME with the actual database name ALTER DATABASE DB_NAME SET OFFLINE -- 2. Move the file or files to the new location. -- This means actually copying the datafiles at OS level -- You may also need grant the SQL Server Service account full permissions on the data file -- 3. For each file moved, run the following statement. ALTER DATABASE DB_NAME MODIFY FILE ( NAME = logical_name FILENAME = 'new_path\os_file_name') -- 4. Bring the database back online ALTER DATABASE database name SET ONLINE -- 5. Verify the file change: SELECT name, physical_name AS CurrentLocation, state_desc FROM sys.master_files WHERE database_id = DB_ID(N'DB_NAME');
Gestione degli accessi
Sarai d'accordo sul fatto che nel nostro ambiente consolidato potremmo finire per avere un elenco molto lungo di oggetti a livello di server come gli accessi. L'uso dei gruppi di Windows consentirà di abbreviare questo elenco e semplificare la gestione degli accessi in ogni istanza del cluster. In genere, avrai bisogno di gruppi creati su Active Directory per gli amministratori dell'applicazione che necessitano di accesso, gli account del servizio dell'applicazione, gli utenti aziendali che devono eseguire il pull dei report e, naturalmente, gli amministratori del database. Uno dei principali vantaggi dell'utilizzo di Gruppi di Windows è che l'accesso può essere concesso o revocato semplicemente gestendo l'appartenenza a questi gruppi direttamente in Active Directory.
Probabilmente ormai è ovvio che questo vantaggio nell'area della gestione degli accessi è possibile solo con l'autenticazione di Windows. Gli accessi a SQL Server non possono essere gestiti in gruppi.
Listato 5: Accessi alle istanze, utenti del database e relativi ruoli
create table #userlist (
[Server Name] varchar(20)
,[Database Name] varchar(50)
,[Database User] varchar(50)
, [Database Role] varchar(50)
, [Instance Login] varchar(50)
, [Status] varchar(15)
)
go
insert into #userlist
exec sp_MSforeachdb @command1 ='
USE [?]
IF ''?'' NOT IN ("tempdb","model"J"msdb"J"master")
BEGIN
select @@servername as instance_name , ''?'' as database_name , rp.name as database_user , mp.name as database_role , sp.name as instance_login , case
when sp.is_disabled = 1 then ''Disabled'' when sp.is_disabled = 0 then ''Enabled'' end
[login_status]
from sys.database_principals rp
left outer join sys.database_role_members drm on (drm.member_principal_id = rp.principal_id)
left outer join sys.database_principals mp on (drm.role_principal_id = mp.principal_id)
left outer join sys.server_principals sp on (rp.sid=sp.sid)
where rp.type_desc in (''WINDOWS_GROUP'',''WINDOWS_USER'',''SQL_USER'')
END' go
select * from #userlist go
drop table #userlist
Conclusione
Abbiamo esaminato a un livello molto elevato i vantaggi che si possono ottenere raggruppando e impilando le istanze di SQL Server come mezzo per ottenere il consolidamento, l'ottimizzazione dei costi e la facilità di gestione. Se ti trovi in grado di acquistare hardware di grandi dimensioni, puoi esplorare questa opzione e sfruttare i vantaggi che abbiamo descritto sopra.