Gli indici hash sono parte integrante dei database. Se hai mai utilizzato un database, è probabile che tu lo abbia visto in azione senza nemmeno accorgertene.
Gli indici hash differiscono nel lavoro da altri tipi di indici perché memorizzano valori anziché puntatori a record che si trovano su un disco. Ciò garantisce una ricerca e un inserimento più rapidi nell'indice. Ecco perché gli indici hash sono spesso usati come chiavi primarie o identificatori univoci.
Capire gli indici hash
Un indice hash è un tipo di indice più comunemente utilizzato nella gestione dei dati. In genere viene creato su una colonna che contiene valori univoci, come una chiave primaria o un indirizzo e-mail. Il principale vantaggio dell'utilizzo degli indici hash è la loro performance veloce.
Il concetto alla base di questi indici può essere sofisticato da comprendere per qualcuno che non ne ha mai sentito parlare prima. Tuttavia, la comprensione degli indici hash è importante se è necessario comprendere come funzionano i database. È necessario per risolvere problemi comuni relativi ai database e alla loro velocità.
La buona notizia è che con un po' di pazienza e un telefono cellulare spento, puoi sicuramente padroneggiare gli indici hash! Quindi, diamo un'occhiata meglio.
Veloce e facile
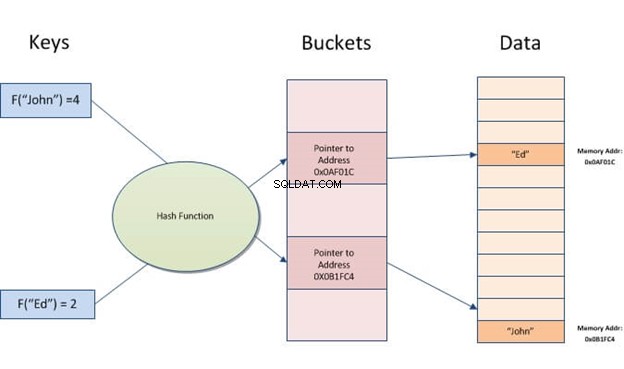
Un indice hash è una struttura di dati che può essere utilizzata per accelerare le query del database. Funziona convertendo i record di input in una matrice di bucket. Ogni bucket ha lo stesso numero di record di tutti gli altri bucket nella tabella. Pertanto, indipendentemente dal numero di valori diversi che hai per una determinata colonna, ogni riga verrà sempre mappata su un bucket.
Gli indici hash consentono ricerche rapide sui dati archiviati nelle tabelle. Funzionano creando una chiave di indice dal valore e quindi localizzandola in base all'hash risultante. È utile quando sono presenti molti input con valori simili o duplicati, poiché è sufficiente confrontare le chiavi invece di esaminare tutti i record.
Non è stato né facile né veloce? Per capire come funzionano gli indici hash e perché sono così potenti, devi capire cosa si intende per hashing.
Hashing sta prendendo un'informazione (una stringa) e trasformandola in un indirizzo o in un puntatore per un rapido accesso in seguito.
L'idea con l'hashing è che ai dati viene assegnato un numero piccolo. Quando cerchi i dati, non devi effettivamente setacciare le masse. Invece, cerca solo quel numero. L'esempio più semplice è Ctrl+F-ing la parola che stai cercando in un testo invece di leggere dozzine di pagine da solo.
A cosa servono gli indici hash?
Un indice hash è un modo per accelerare il processo di ricerca. Con gli indici tradizionali, devi scansionare ogni riga per assicurarti che la tua query abbia esito positivo. Ma con gli indici hash non è così!
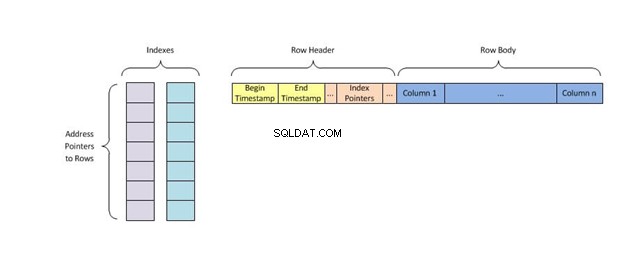
Ciascuna chiave dell'indice contiene solo una riga dei dati della tabella e utilizza l'algoritmo di indicizzazione chiamato hashing che assegna loro una posizione univoca in memoria, eliminando tutte le altre chiavi con valori duplicati prima di trovare ciò che sta cercando.
Gli indici hash sono uno dei tanti modi per organizzare i dati in un database. Funzionano prendendo input e usandolo come chiave per l'archiviazione su un disco. Queste chiavi o valori hash , può essere qualsiasi cosa, dalle lunghezze delle stringhe ai caratteri nell'input.
Gli indici hash sono più comunemente usati quando si eseguono query su input specifici con attributi specifici. Ad esempio, potrebbe trovare tutte le lettere A più alte di 10 cm. Puoi farlo rapidamente creando una funzione di indice hash.
Gli indici hash fanno parte del sistema di database PostgreSQL. Questo sistema è stato sviluppato per aumentare velocità e prestazioni. Gli indici hash possono essere utilizzati insieme ad altri tipi di indici, come B-tree o GiST.
Un indice hash memorizza le chiavi dividendole in blocchi più piccoli chiamati bucket, in cui a ciascun bucket viene assegnato un numero ID intero per recuperarlo rapidamente durante la ricerca della posizione di una chiave nella tabella hash. I bucket vengono archiviati in sequenza su un disco in modo da poter accedere rapidamente ai dati in essi contenuti.
Ulteriori spiegazioni tecniche sono disponibili in questa pagina (fai clic con il pulsante destro del mouse e scegli "Traduci in inglese").
Vantaggi
Il vantaggio principale dell'utilizzo degli indici hash è che consentono un accesso rapido durante il recupero del record in base al valore della chiave. È spesso utile per le query con una condizione di uguaglianza. Inoltre, l'utilizzo di benchmark hash non richiede molto spazio di archiviazione. Si tratta quindi di uno strumento efficace, ma non privo di inconvenienti.
Svantaggi
Gli indici hash sono una struttura di indicizzazione relativamente nuova con il potenziale di fornire significativi vantaggi in termini di prestazioni. Puoi pensarli come un'estensione degli alberi di ricerca binari (BST).
Gli indici hash funzionano archiviando i dati in bucket in base ai loro valori hash, il che consente un recupero rapido ed efficiente dei dati. Sono garantiti per essere in ordine.
Tuttavia, è impossibile archiviare chiavi duplicate all'interno di un bucket. Quindi, ci sarà sempre un po' di sovraccarico. Ma finora, i vantaggi dell'utilizzo degli indici hash superano i contro.
Come funziona tutto un po' più in profondità?
Facciamo una demo aviasales database per ottenere una comprensione più approfondita del funzionamento degli indici hash.
demo=# create index on flights using hash(flight_no);
WARNING: hash indexes are not WAL-logged and their use is discouraged
CREATE INDEX
demo=# explain (costs off) select * from flights where flight_no = 'PG0001';
QUERY PLAN
----------------------------------------------------
Bitmap Heap Scan on flights
Recheck Cond: (flight_no = 'PG0001'::bpchar)
-> Bitmap Index Scan on flights_flight_no_idx
Index Cond: (flight_no = 'PG0001'::bpchar)
(4 rows)
Qui puoi vedere come stiamo implementando gli indici hash compilando i dati in set.
Questo è un semplice esempio, ma tieni presente che le limitazioni vengono fornite con una minore infrastruttura di codice. Potrebbe esserci una mancanza di accesso al registro WAL o l'impossibilità di recuperare gli indici (indici?) dopo un arresto anomalo. Inoltre, gli indici potrebbero non partecipare alla replica, perché PostgreSQL è obsoleto. Tuttavia, proprio come con Python, ricevi avvisi che spesso ti consentono di prevenire errori.
Puoi dare un'occhiata più a fondo all'interno di questi indici se sei sufficientemente incuriosito. Per questo, stiamo creando una ispeziona pagina istanza di estensione.
demo=# create extension pageinspect;
CREATE EXTENSION
demo=# select hash_page_type(get_raw_page('flights_flight_no_idx',0));
hash_page_type
----------------
metapage
(1 row)
demo=# select ntuples, maxbucket from hash_metapage_info(get_raw_page('flights_flight_no_idx',0));
ntuples | maxbucket
---------+-----------
33121 | 127
(1 row)
demo=# select hash_page_type(get_raw_page('flights_flight_no_idx',1));
hash_page_type
----------------
bucket
(1 row)
demo=# select live_items, dead_items from hash_page_stats(get_raw_page('flights_flight_no_idx',1));
live_items | dead_items
------------+------------
407 | 0
(1 row)
Se vuoi ispezionare completamente il codice, inizia con README.
Riepilogo
Gli indici hash sono una struttura di dati che accelera il processo di ricerca di informazioni in database di grandi dimensioni. Funzionano suddividendo i dati in blocchi più piccoli e quindi ordinandoli. Pertanto, quando cerchi qualcosa, puoi trovarlo molto più velocemente.
Se vuoi cercare più cose, ci sono risorse per DYOR. Inoltre, tieni d'occhio i nostri nuovi articoli, che stanno uscendo più velocemente di quanto tu possa Ctrl+F la parola "hash" in questa pagina. Spero che questo aiuti!