Ansible è semplicemente fantastico e PostgreSQL è sicuramente fantastico, vediamo come funzionano straordinariamente insieme!

======================Annuncio in prima serata! =====================
PGConf Europe 2015 si terrà dal 27 al 30 ottobre a Vienna quest'anno.
Suppongo che tu possa essere interessato alla gestione della configurazione, all'orchestrazione del server, all'implementazione automatizzata (ecco perché stai leggendo questo post del blog, giusto?) e ti piace lavorare con PostgreSQL (di sicuro) su AWS (opzionale), quindi potresti voler unirti al mio discorso "Managing PostgreSQL with Ansible" il 28 ottobre, 15-15:50.
Controlla il fantastico programma e non perdere l'occasione di partecipare al più grande evento PostgreSQL d'Europa!
Spero di vederti lì, sì mi piace bere il caffè dopo i colloqui 🙂
=====================Annuncio in prima serata! =====================
Cos'è Ansible e come funziona?
Il motto di Ansible è "sautomazione IT open source semplice, senza agenti e potente ” citando i documenti di Ansible.
Come si può vedere dalla figura seguente, la homepage di Ansible indica le principali aree di utilizzo di Ansible come:provisioning, gestione della configurazione, distribuzione delle app, distribuzione continua, sicurezza e conformità, orchestrazione. Il menu di panoramica mostra anche su quali piattaforme possiamo integrare Ansible, ovvero AWS, Docker, OpenStack, Red Hat, Windows.
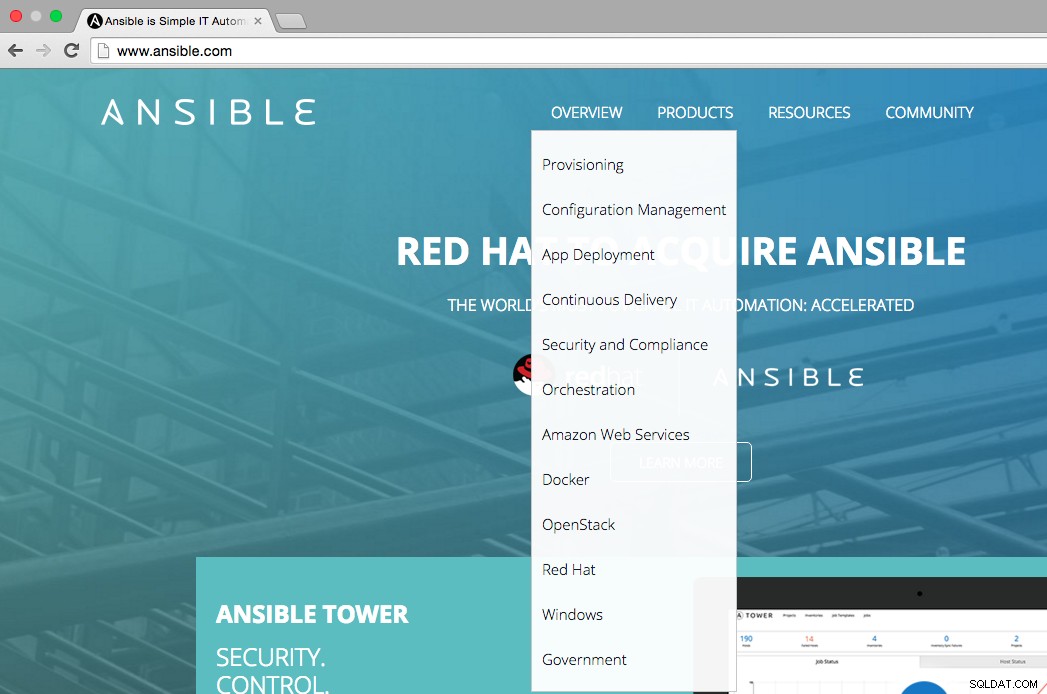
Esaminiamo i principali casi d'uso di Ansible per capire come funziona e quanto sia utile per gli ambienti IT.
Approvvigionamento
Ansible è il tuo fedele amico quando vuoi automatizzare tutto nel tuo sistema. È senza agenti e puoi semplicemente gestire le tue cose (ad esempio server, bilanciatori di carico, switch, firewall) tramite SSH. Indipendentemente dal fatto che i tuoi sistemi vengano eseguiti su server bare-metal o cloud, Ansible sarà presente e ti aiuterà a eseguire il provisioning delle tue istanze. Le sue caratteristiche idempotenti assicurano che sarai sempre nello stato che desideravi (e ti aspettavi) di essere.
Gestione della configurazione
Una delle cose più difficili è non ripetersi in compiti operativi ripetitivi e qui Ansible torna in mente di nuovo come un salvatore. Ai bei vecchi tempi, quando i tempi erano brutti, gli amministratori di sistema scrivevano molti molti script e si connettevano a molti server per applicarli e ovviamente non era la cosa migliore della loro vita. Come tutti sappiamo, le attività manuali sono soggette a errori e portano a un ambiente eterogeneo invece a uno omogeneo e più gestibile, rendendo decisamente la nostra vita più stressante.
Con Ansible puoi scrivere semplici playbook (con l'aiuto di una documentazione molto informativa e il supporto della sua vasta comunità) e una volta scritti i tuoi compiti puoi chiamare un'ampia gamma di moduli (ad esempio AWS, Nagios, PostgreSQL, SSH, APT, File moduli). Di conseguenza, puoi concentrarti su attività più creative rispetto alla gestione manuale delle configurazioni.
Distribuzione dell'app
Avendo gli artefatti pronti, è semplicissimo distribuirli su un numero di server. Poiché Ansible comunica tramite SSH, non è necessario eseguire il pull da un repository su ciascun server o problemi con metodi antichi come la copia di file su FTP. Ansible può sincronizzare gli artefatti e garantire che vengano trasferiti solo i file nuovi o aggiornati e che i file obsoleti vengano rimossi. Ciò velocizza anche i trasferimenti di file e consente di risparmiare molta larghezza di banda.
Oltre a trasferire file, Ansible aiuta anche a rendere i server pronti per l'uso in produzione. Prima del trasferimento, può sospendere il monitoraggio, rimuovere i server dai servizi di bilanciamento del carico e interrompere i servizi. Dopo la distribuzione, può avviare servizi, aggiungere server ai sistemi di bilanciamento del carico e riprendere il monitoraggio.
Tutto questo non deve accadere in una volta per tutti i server. Ansible può lavorare su un sottoinsieme di server alla volta per fornire implementazioni senza tempi di inattività. Ad esempio, in una sola volta può distribuire 5 server contemporaneamente, quindi può essere distribuito ai successivi 5 server al termine.
Dopo aver implementato questo scenario, può essere eseguito ovunque. Gli sviluppatori o i membri del team QA possono effettuare distribuzioni sui propri computer a scopo di test. Inoltre, per eseguire il rollback di una distribuzione per qualsiasi motivo, tutto ciò di cui Ansible ha bisogno è la posizione degli ultimi artefatti di lavoro noti. Può quindi ridistribuirli facilmente sui server di produzione per riportare il sistema in uno stato stabile.
Consegna continua
La consegna continua significa adottare un approccio rapido e semplice per i rilasci. Per raggiungere tale obiettivo, è fondamentale utilizzare i migliori strumenti che consentano rilasci frequenti senza tempi di fermo e richiedano il minor intervento umano possibile. Dato che abbiamo appreso le capacità di distribuzione delle applicazioni di Ansible sopra, è abbastanza facile eseguire distribuzioni senza tempi di inattività. L'altro requisito per la consegna continua è meno processi manuali e questo significa automazione. Ansible può automatizzare qualsiasi attività, dal provisioning dei server alla configurazione dei servizi, per renderla pronta per la produzione. Dopo aver creato e testato gli scenari in Ansible, diventa banale metterli di fronte a un sistema di integrazione continua e lasciare che Ansible faccia il suo lavoro.
Sicurezza e conformità
La sicurezza è sempre considerata la cosa più importante, ma mantenere i sistemi sicuri è una delle cose più difficili da raggiungere. Devi essere sicuro della sicurezza dei tuoi dati e della sicurezza dei dati dei tuoi clienti. Per essere sicuro della sicurezza dei tuoi sistemi, definire la sicurezza non è sufficiente, devi essere in grado di applicare tale sicurezza e monitorare costantemente i tuoi sistemi per assicurarti che rimangano conformi a tale sicurezza.
Ansible è facile da usare sia che si tratti di impostare regole del firewall, bloccare utenti e gruppi o applicare criteri di sicurezza personalizzati. È sicuro per sua natura poiché puoi applicare ripetutamente la stessa configurazione e apporterà solo le modifiche necessarie per riportare il sistema in conformità.
Orchestratura
Ansible garantisce che tutti i compiti assegnati siano nell'ordine corretto e stabilisce un'armonia tra tutte le risorse che gestisce. L'orchestrazione di complesse distribuzioni multilivello è più semplice grazie alle funzionalità di gestione e distribuzione della configurazione di Ansible. Ad esempio, considerando la distribuzione di uno stack software, preoccupazioni come assicurarsi che tutti i server di database siano pronti prima di attivare i server delle applicazioni o che la rete sia configurata prima di aggiungere server al sistema di bilanciamento del carico non sono più problemi complicati.
Ansible aiuta anche l'orchestrazione di altri strumenti di orchestrazione come CloudFormation di Amazon, Heat di OpenStack, Docker's Swarm, ecc. In questo modo, invece di apprendere piattaforme, lingue e regole diverse; gli utenti possono concentrarsi solo sulla sintassi YAML e sui potenti moduli di Ansible.
Cos'è un modulo Ansible?
I moduli o le librerie di moduli forniscono mezzi Ansible per controllare o gestire le risorse su server locali o remoti. Svolgono una varietà di funzioni. Ad esempio, un modulo può essere responsabile del riavvio di una macchina o può semplicemente visualizzare un messaggio sullo schermo.
Ansible consente agli utenti di scrivere i propri moduli e fornisce anche moduli di base o extra pronti all'uso.
E i playbook Ansible?
Ansible ci permette di organizzare il nostro lavoro in vari modi. Nella sua forma più diretta, possiamo lavorare con i moduli Ansible utilizzando "ansible ” strumento da riga di comando e il file di inventario.
Inventario
Uno dei concetti più importanti è l'inventario . Abbiamo bisogno di un file di inventario per consentire ad Ansible di sapere quali server ha bisogno di connettersi tramite SSH, quali informazioni di connessione richiede e, facoltativamente, quali variabili sono associate a quei server.
Il file di inventario è in un formato simile a INI. Nel file di inventario, possiamo specificare più di un host e raggrupparli in più di un gruppo di host.
Il nostro esempio di file di inventario hosts.ini è simile al seguente:
[dbservers]
db.example.com
Qui abbiamo un singolo host chiamato "db.example.com" in un gruppo host chiamato "dbservers". Nel file di inventario, potremmo anche includere porte SSH personalizzate, nomi utente SSH, chiavi SSH, informazioni proxy, variabili, ecc.
Dal momento che abbiamo un file di inventario pronto, per vedere i tempi di attività dei nostri server di database, possiamo invocare il "comando di Ansible ” ed eseguire il “tempo di attività comando ” su quei server:
ansible dbservers -i hosts.ini -m command -a "uptime"
Qui abbiamo indicato ad Ansible di leggere gli host dal file hosts.ini, collegarli tramite SSH, eseguire il "uptime ” su ciascuno di essi, quindi stampa il loro output sullo schermo. Questo tipo di esecuzione del modulo è chiamato comando ad hoc .
L'output del comando sarà come:
example@sqldat.com ~/blog/ansible-loves-postgresql # ansible dbservers -i hosts.ini -m command -a "uptime"
db.example.com | success | rc=0 >>
21:16:24 up 93 days, 9:17, 4 users, load average: 0.08, 0.03, 0.05
Tuttavia, se la nostra soluzione contiene più di un singolo passaggio, diventa difficile gestirli solo utilizzando comandi ad hoc.
Arrivano i playbook Ansible. Ci consente di organizzare la nostra soluzione in un file di playbook integrando tutti i passaggi tramite attività, variabili, ruoli, modelli, gestori e un inventario.
Diamo una breve occhiata ad alcuni di questi termini per capire come possono aiutarci.
Compiti
Un altro concetto importante sono i compiti. Ogni attività Ansible contiene un nome, un modulo da chiamare, parametri del modulo e, facoltativamente, pre/post-condizioni. Ci consentono di chiamare moduli Ansible e passare informazioni ad attività consecutive.
Variabili
Ci sono anche variabili. Sono molto utili per riutilizzare le informazioni che abbiamo fornito o raccolto. Possiamo definirli nell'inventario, in file YAML esterni o nei playbook.
Playbook
I playbook Ansible sono scritti utilizzando la sintassi YAML. Può contenere più di una riproduzione. Ogni riproduzione contiene il nome dei gruppi host a cui connettersi e le attività che deve eseguire. Può contenere anche variabili/ruoli/gestori, se definiti.
Ora possiamo guardare un playbook molto semplice per vedere come può essere strutturato:
---
- hosts: dbservers
gather_facts: no
vars:
who: World
tasks:
- name: say hello
debug: msg="Hello {{ who }}"
- name: retrieve the uptime
command: uptimeIn questo semplicissimo playbook, abbiamo detto ad Ansible che dovrebbe funzionare su server definiti nel gruppo host "dbservers". Abbiamo creato una variabile chiamata “chi” e poi abbiamo definito i nostri compiti. Si noti che nella prima attività in cui stampiamo un messaggio di debug, abbiamo utilizzato la variabile "chi" e fatto in modo che Ansible stampasse "Hello World" sullo schermo. Nella seconda attività, abbiamo detto ad Ansible di connettersi a ciascun host e quindi di eseguire lì il comando "uptime".
Moduli Ansible PostgreSQL
Ansible fornisce una serie di moduli per PostgreSQL. Alcuni di essi si trovano sotto i moduli principali, mentre altri si trovano sotto i moduli extra.
Tutti i moduli PostgreSQL richiedono che il pacchetto Python psycopg2 sia installato sulla stessa macchina con il server PostgreSQL. Psycopg2 è un adattatore per database PostgreSQL nel linguaggio di programmazione Python.
Sui sistemi Debian/Ubuntu, il pacchetto psycopg2 può essere installato utilizzando il seguente comando:
apt-get install python-psycopg2
Ora esamineremo questi moduli in dettaglio. Ad esempio, lavoreremo su un server PostgreSQL presso l'host db.example.com sulla porta 5432 con postgres utente e una password vuota.
postgresql_db
Questo modulo principale crea o rimuove un determinato database PostgreSQL. Nella terminologia di Ansible, garantisce che un determinato database PostgreSQL sia presente o assente.
L'opzione più importante è il parametro obbligatorio “nome ”. Rappresenta il nome del database in un server PostgreSQL. Un altro parametro significativo è “stato ”. Richiede uno dei due valori:presente o assente . Questo ci permette di creare o rimuovere un database identificato dal valore dato nel nome parametro.
Alcuni flussi di lavoro possono anche richiedere la specifica di parametri di connessione come login_host , porta , utente_accesso e password_accesso .
Creiamo un database chiamato “module_test ” sul nostro server PostgreSQL aggiungendo le righe sottostanti al nostro file di playbook:
- postgresql_db: name=module_test
state=present
login_host=db.example.com
port=5432
login_user=postgres
Qui, ci siamo collegati al nostro server di database di prova su db.example.com con l'utente; postgres . Tuttavia, non deve essere per forza il postgres utente poiché il nome utente può essere qualsiasi cosa.
Rimuovere il database è facile come crearlo:
- postgresql_db: name=module_test
state=absent
login_host=db.example.com
port=5432
login_user=postgres
Notare il valore "assente" nel parametro "stato".
postgresql_ext
PostgreSQL è noto per avere estensioni molto utili e potenti. Ad esempio, un'estensione recente è tsm_system_rows che aiuta a recuperare il numero esatto di righe in tableampling. (Per ulteriori informazioni puoi controllare il mio precedente post sui metodi di campionamento delle tabelle.)
Questo modulo extra aggiunge o rimuove le estensioni PostgreSQL da un database. Richiede due parametri obbligatori:db e nome . Il db parametro fa riferimento al nome del database e al nome parametro fa riferimento al nome dell'estensione. Abbiamo anche lo stato parametro che deve essere presente o assente valori e gli stessi parametri di connessione del modulo postgresql_db.
Iniziamo creando l'estensione di cui abbiamo parlato:
- postgresql_ext: db=module_test
name=tsm_system_rows
state=present
login_host=db.example.com
port=5432
login_user=postgres
utente_postgresql
Questo modulo principale consente di aggiungere o rimuovere utenti e ruoli da un database PostgreSQL.
È un modulo molto potente perché, oltre a garantire la presenza di un utente nel database, consente anche la modifica di privilegi o ruoli allo stesso tempo.
Iniziamo osservando i parametri. L'unico parametro obbligatorio qui è "nome ”, che fa riferimento a un utente o a un nome di ruolo. Inoltre, come nella maggior parte dei moduli Ansible, lo “stato ” parametro è importante. Può avere uno dei presenti o assente valori e il suo valore predefinito è presente .
Oltre ai parametri di connessione come nei moduli precedenti, alcuni altri importanti parametri opzionali sono:
- db :Nome del database a cui verranno concesse le autorizzazioni
- password :Password dell'utente
- privato :Privilegi in "priv1/priv2" o privilegi di tabella in formato "table:priv1,priv2,..."
- role_attr_flags :Attributi del ruolo. I valori possibili sono:
- [NO]SUPERUSER
- [NO]CREATEROLO
- [NO]CREATEUSER
- [NO]CREATOB
- [NO]EREDITE
- [NO]ACCEDI
- [NESSUNA]REPLICAZIONE
Per creare un nuovo utente chiamato ada con password lovelace e un privilegio di connessione al database module_test , potremmo aggiungere quanto segue al nostro playbook:
- postgresql_user: db=module_test
name=ada
password=lovelace
state=present
priv=CONNECT
login_host=db.example.com
port=5432
login_user=postgres
Ora che abbiamo l'utente pronto, possiamo assegnarle alcuni ruoli. Per consentire ad "ada" di accedere e creare database:
- postgresql_user: name=ada
role_attr_flags=LOGIN,CREATEDB
login_host=db.example.com
port=5432
login_user=postgres
Possiamo anche concedere privilegi globali o basati su tabelle come "INSERT ”, “AGGIORNAMENTO ”, “SELEZIONA ”, e “ELIMINA ” utilizzando il priv parametro. Un punto importante da considerare è che un utente non può essere rimosso finché tutti i privilegi concessi non sono stati revocati prima.
postgresql_privs
Questo modulo principale concede o revoca i privilegi sugli oggetti del database PostgreSQL. Gli oggetti supportati sono:tabella , sequenza , funzione , database , schema , lingua , spazio tabella e gruppo .
I parametri obbligatori sono "database"; nome del database su cui concedere/revocare i privilegi e “ruoli”; un elenco di nomi di ruoli separati da virgole.
I parametri opzionali più importanti sono:
- digitare :Tipo di oggetto su cui impostare i privilegi. Può essere uno di:tabella, sequenza, funzione, database, schema, lingua, tablespace, gruppo . Il valore predefinito è tabella .
- oggetti :Oggetti database su cui impostare i privilegi. Può avere più valori. In tal caso, gli oggetti vengono separati utilizzando una virgola.
- privati :Elenco separato da virgole di privilegi da concedere o revocare. I valori possibili includono:TUTTI , SELEZIONA , AGGIORNAMENTO , INSERIRE .
Vediamo come funziona concedendo tutti i privilegi sul "pubblico ” schema a “ada ”:
- postgresql_privs: db=module_test
privs=ALL
type=schema
objs=public
role=ada
login_host=db.example.com
port=5432
login_user=postgres
postgresql_lang
Una delle caratteristiche molto potenti di PostgreSQL è il suo supporto per praticamente qualsiasi linguaggio da utilizzare come linguaggio procedurale. Questo modulo extra aggiunge, rimuove o cambia linguaggi procedurali con un database PostgreSQL.
L'unico parametro obbligatorio è “lang ”; nome della lingua procedurale da aggiungere o rimuovere. Altre opzioni importanti sono "db ”; nome del database in cui viene aggiunta o rimossa la lingua e “trust ”; opzione per rendere la lingua attendibile o non attendibile per il database selezionato.
Abilitiamo il linguaggio PL/Python per il nostro database:
- postgresql_lang: db=module_test
lang=plpython2u
state=present
login_host=db.example.com
port=5432
login_user=postgres
Mettere tutto insieme
Ora che sappiamo come è strutturato un playbook Ansible e quali moduli PostgreSQL sono disponibili per l'uso, ora possiamo unire le nostre conoscenze in un playbook Ansible.
La forma finale del nostro playbook main.yml è simile alla seguente:
---
- hosts: dbservers
sudo: yes
sudo_user: postgres
gather_facts: yes
vars:
dbname: module_test
dbuser: postgres
tasks:
- name: ensure the database is present
postgresql_db: >
state=present
db={{ dbname }}
login_user={{ dbuser }}
- name: ensure the tsm_system_rows extension is present
postgresql_ext: >
name=tsm_system_rows
state=present
db={{ dbname }}
login_user={{ dbuser }}
- name: ensure the user has access to database
postgresql_user: >
name=ada
password=lovelace
state=present
priv=CONNECT
db={{ dbname }}
login_user={{ dbuser }}
- name: ensure the user has necessary privileges
postgresql_user: >
name=ada
role_attr_flags=LOGIN,CREATEDB
login_user={{ dbuser }}
- name: ensure the user has schema privileges
postgresql_privs: >
privs=ALL
type=schema
objs=public
role=ada
db={{ dbname }}
login_user={{ dbuser }}
- name: ensure the postgresql-plpython-9.4 package is installed
apt: name=postgresql-plpython-9.4 state=latest
sudo_user: root
- name: ensure the PL/Python language is available
postgresql_lang: >
lang=plpython2u
state=present
db={{ dbname }}
login_user={{ dbuser }}
Ora possiamo eseguire il nostro playbook usando il comando "ansible-playbook":
example@sqldat.com ~/blog/ansible-loves-postgresql # ansible-playbook -i hosts.ini main.yml
PLAY [dbservers] **************************************************************
GATHERING FACTS ***************************************************************
ok: [db.example.com]
TASK: [ensure the database is present] ****************************************
changed: [db.example.com]
TASK: [ensure the tsm_system_rows extension is present] ***********************
changed: [db.example.com]
TASK: [ensure the user has access to database] ********************************
changed: [db.example.com]
TASK: [ensure the user has necessary privileges] ******************************
changed: [db.example.com]
TASK: [ensure the user has schema privileges] *********************************
changed: [db.example.com]
TASK: [ensure the postgresql-plpython-9.4 package is installed] ***************
changed: [db.example.com]
TASK: [ensure the PL/Python language is available] ****************************
changed: [db.example.com]
PLAY RECAP ********************************************************************
db.example.com : ok=8 changed=7 unreachable=0 failed=0
Puoi trovare l'inventario e il file del playbook nel mio repository GitHub creato per questo post del blog. C'è anche un altro playbook chiamato "remove.yml" che annulla tutto ciò che abbiamo fatto nel playbook principale.
Per ulteriori informazioni su Ansible:
- Consulta i loro documenti ben scritti.
- Guarda il video di avvio rapido di Ansible che è un esercitazione davvero utile.
- Segui il loro programma di webinar, ci sono alcuni fantastici webinar in arrivo nell'elenco.