Introduzione
Raggiungere una registrazione minima con INSERT...SELECT può essere un affare complicato. Le considerazioni elencate nella Guida alle prestazioni del caricamento dei dati sono ancora piuttosto complete, anche se è necessario leggere anche SQL Server 2016, Registrazione minima e Impatto della dimensione batch nelle operazioni di caricamento in blocco di Parikshit Savjani del Team Tiger di SQL Server per ottenere l'immagine aggiornata per SQL Server 2016 e versioni successive, durante il caricamento in blocco in tabelle rowstore in cluster. Detto questo, questo articolo si occupa esclusivamente di fornire nuovi dettagli su registrazione minima durante il caricamento in blocco di tabelle heap tradizionali (non "ottimizzate per la memoria") utilizzando INSERT...SELECT . Le tabelle con un indice cluster b-tree sono trattate separatamente nella seconda parte di questa serie.
Tabelle heap
Quando si inseriscono righe utilizzando INSERT...SELECT in un mucchio senza indici non cluster, la documentazione afferma universalmente che tali inserti verranno registrati minimamente purché un TABLOCK suggerimento è presente. Ciò si riflette nelle tabelle di riepilogo incluse nella Guida alle prestazioni del caricamento dei dati e il posto del Tiger Team. Le righe di riepilogo per le tabelle heap senza indici sono le stesse in entrambi i documenti (nessuna modifica per SQL Server 2016):

Un esplicito TABLOCK hint non è l'unico modo per soddisfare il requisito del blocco a livello di tabella . Possiamo anche impostare il "blocco della tabella sul carico di massa" opzione per la tabella di destinazione utilizzando sp_tableoption o abilitando il flag di traccia documentato 715. (Nota:queste opzioni non sono sufficienti per abilitare la registrazione minima quando si utilizza INSERT...SELECT perché INSERT...SELECT non supporta i blocchi degli aggiornamenti in blocco).
Il "concorrente possibile" la colonna nel riepilogo si applica solo ai metodi di caricamento in blocco diversi da INSERT...SELECT . Il caricamento simultaneo di una tabella heap non è possibile con INSERT...SELECT . Come indicato nella Guida alle prestazioni del caricamento dei dati , caricamento in blocco con INSERT...SELECT prende un esclusiva X lock on the table, non l'aggiornamento collettivo BU blocco richiesto per carichi di massa simultanei.
Tutto ciò a parte — e supponendo che non ci siano altri motivi per non aspettarsi una registrazione minima durante il caricamento in blocco di un heap non indicizzato con TABLOCK (o equivalente) — l'inserto ancora potrebbe non essere registrato minimamente...
Un'eccezione alla regola
Il seguente script demo deve essere eseguito su un'istanza di sviluppo in un nuovo database di test impostare per utilizzare il SIMPLE modello di recupero. Carica un numero di righe in una tabella heap usando INSERT...SELECT con TABLOCK e rapporti sui record del registro delle transazioni generati:
CREATE TABLE dbo.TestHeap
(
id integer NOT NULL IDENTITY,
c1 integer NOT NULL,
padding char(45) NOT NULL
DEFAULT ''
);
GO
-- Clear the log
CHECKPOINT;
GO
-- Insert rows
INSERT dbo.TestHeap WITH (TABLOCK)
(c1)
SELECT TOP (897)
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV;
GO
-- Show log entries
SELECT
FD.Operation,
FD.Context,
FD.[Log Record Length],
FD.[Log Reserve],
FD.AllocUnitName,
FD.[Transaction Name],
FD.[Lock Information],
FD.[Description]
FROM sys.fn_dblog(NULL, NULL) AS FD;
GO
-- Count the number of fully-logged rows
SELECT
[Fully Logged Rows] = COUNT_BIG(*)
FROM sys.fn_dblog(NULL, NULL) AS FD
WHERE
FD.Operation = N'LOP_INSERT_ROWS'
AND FD.Context = N'LCX_HEAP'
AND FD.AllocUnitName = N'dbo.TestHeap'; L'output mostra che tutte le 897 righe sono state registrate completamente nonostante apparentemente soddisfino tutte le condizioni per la registrazione minima (solo un campione di record di registro viene mostrato per motivi di spazio):
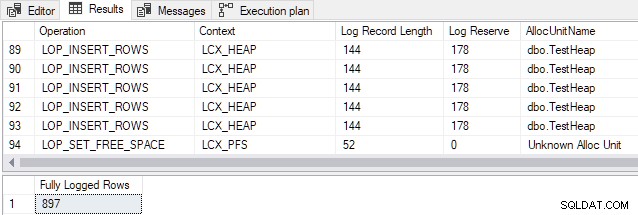
Lo stesso risultato si vede se l'inserimento viene ripetuto (cioè non importa se la tabella heap è vuota o meno). Questo risultato contraddice la documentazione.
La soglia minima di registrazione per gli heap
Il numero di righe da aggiungere in un singolo INSERT...SELECT dichiarazione per ottenere una registrazione minima in un heap non indicizzato con blocco tabella abilitato dipende da un calcolo eseguito da SQL Server durante la stima della dimensione totale dei dati da inserire. Gli input per questo calcolo sono:
- La versione di SQL Server.
- Il numero stimato di righe che portano all'Inserisci operatore.
- Misura della riga della tabella di destinazione.
Per SQL Server 2012 e versioni precedenti , il punto di transizione per questa tabella particolare è 898 righe . Modifica del numero nello script demo TOP la clausola da 897 a 898 produce il seguente output:
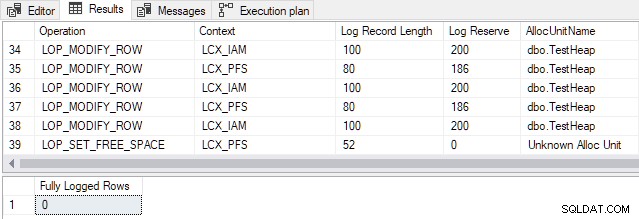
Le voci del registro delle transazioni generate riguardano l'allocazione delle pagine e il mantenimento della Mappa di allocazione dell'indice (IAM) e Spazio libero nella pagina (PFS) strutture. Ricorda che registrazione minima significa che SQL Server non registra ogni inserimento di riga singolarmente. Vengono invece registrate solo le modifiche ai metadati e alle strutture di allocazione. Il passaggio da 897 a 898 righe consente una registrazione minima per questa tabella specifica.
Per SQL Server 2014 e versioni successive , il punto di transizione è 950 righe per questa tavola Esecuzione di INSERT...SELECT con TOP (949) utilizzerà la registrazione completa – passando a TOP (950) produrrà registrazione minima .
Le soglie non dipendente dalla Stima della cardinalità modello in uso o il livello di compatibilità del database.
Il calcolo della dimensione dei dati
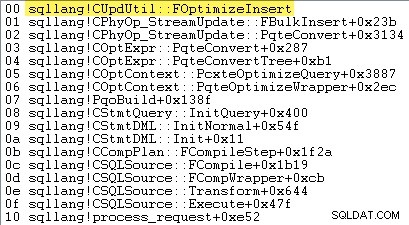
Se SQL Server decide di utilizzare il caricamento in blocco del set di righe — e quindi se registrazione minima è disponibile o meno — dipende dal risultato di una serie di calcoli eseguiti con un metodo chiamato sqllang!CUpdUtil::FOptimizeInsert , che restituisce true per la registrazione minima o falso per la registrazione completa. Di seguito è mostrato un esempio di stack di chiamate:
L'essenza del test è:
- L'inserto deve contenere più di 250 righe .
- La dimensione totale dei dati di inserimento deve essere calcolata come almeno 8 pagine .
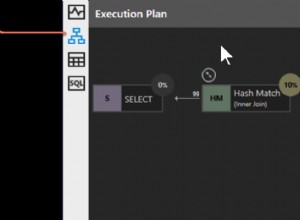
Il controllo per più di 250 righe dipende esclusivamente dal numero stimato di righe che arrivano al Inserimento tabella operatore. Questo viene mostrato nel piano di esecuzione come "Numero di righe stimato" . Stai attento con questo. È facile produrre un piano con un numero di righe stimato basso, ad esempio utilizzando una variabile nel TOP clausola senza OPTION (RECOMPILE) . In tal caso, l'ottimizzatore ipotizza 100 righe, che non raggiungeranno la soglia, impedendo così il caricamento di massa e la registrazione minima.
Il calcolo della dimensione totale dei dati è più complesso e non corrisponde la "Dimensione stimata della riga" che scorre nell'Inserimento tabella operatore. Il modo in cui viene eseguito il calcolo è leggermente diverso in SQL Server 2012 e versioni precedenti rispetto a SQL Server 2014 e versioni successive. Tuttavia, entrambi producono un risultato di dimensioni di riga diverso da quello visualizzato nel piano di esecuzione.
Il calcolo della dimensione della riga
La dimensione totale dei dati di inserimento viene calcolata moltiplicando il numero stimato di righe dalla dimensione massima prevista per la riga . Il calcolo della dimensione della riga è il punto che differisce tra le versioni di SQL Server.
In SQL Server 2012 e versioni precedenti, il calcolo viene eseguito da sqllang!OptimizerUtil::ComputeRowLength . Per la tabella heap di test (progettata deliberatamente con semplici colonne non null a lunghezza fissa utilizzando l'originale FixedVar formato di archiviazione riga) uno schema del calcolo è:
- Inizializza una FixedVar generatore di metadati.
- Ottieni informazioni sul tipo e sugli attributi per ciascuna colonna nell'Inserimento tabella flusso di input.
- Aggiungi colonne e attributi digitati ai metadati.
- Finalizza il generatore e chiedigli la dimensione massima della riga.
- Aggiungi un sovraccarico per la bitmap nulla e numero di colonne.
- Aggiungi quattro byte per la riga bit di stato e l'offset della riga al numero di colonne di dati.
Dimensione fisica della riga
È possibile che il risultato di questo calcolo corrisponda alla dimensione fisica della riga, ma non è così. Ad esempio, con il controllo delle versioni delle righe disattivato per il database:
SELECT
DDIPS.index_type_desc,
DDIPS.alloc_unit_type_desc,
DDIPS.page_count,
DDIPS.record_count,
DDIPS.min_record_size_in_bytes,
DDIPS.max_record_size_in_bytes,
DDIPS.avg_record_size_in_bytes
FROM sys.dm_db_index_physical_stats
(
DB_ID(),
OBJECT_ID(N'dbo.TestHeap', N'U'),
0, -- heap
NULL, -- all partitions
'DETAILED'
) AS DDIPS; …fornisce una dimensione record di 60 byte in ogni riga della tabella di test:

Questo è come descritto in Stimare la dimensione di un heap:
- Dimensione totale in byte di tutti i a lunghezza fissa colonne =53 byte:
id integer NOT NULL=4 bytec1 integer NOT NULL=4 bytepadding char(45) NOT NULL=45 byte.
- Bitmap nulla =3 byte :
- =2 + int((Num_Cols + 7) / 8)
- =2 + int((3 + 7) / 8)
- =3 byte.
- Intestazione riga =4 byte .
- Totale 53 + 3 + 4 =60 byte .
Corrisponde anche alla dimensione stimata della riga mostrata nel piano di esecuzione:

Dettagli di calcolo interno
Il calcolo interno utilizzato per determinare se viene utilizzato il carico di massa fornisce un risultato diverso, basato sul seguente flusso di inserimento informazioni sulla colonna ottenute utilizzando un debugger. I numeri di tipo utilizzati corrispondono a sys.types :
- Totale a lunghezza fissa dimensione della colonna =66 byte :
- Digita ID 173
binary(8)=8 byte (interni). - Digita ID 56
integer=4 byte (interni). - Digita ID 104
bit=1 byte (interno). - Digita ID 56
integer=4 byte (idcolonna). - Digita ID 56
integer=4 byte (c1colonna). - Digita ID 175
char(45)=45 byte (paddingcolonna).
- Digita ID 173
- Bitmap nulla =3 byte (come prima).
- Intestazione riga sovraccarico =4 byte (come prima).
- Dimensione riga calcolata =66 + 3 + 4 =73 byte .
La differenza è che il flusso di input alimenta l'Inserimento tabella contiene tre colonne interne extra . Questi vengono eliminati quando viene generato showplan. Le colonne extra costituiscono il localizzatore di inserimento tabella , che include il segnalibro (RID o ricerca riga) come primo componente. Sono metadati per l'inserto e non finisce per essere aggiunto alla tabella.
Le colonne extra spiegano la discrepanza tra il calcolo eseguito da OptimizerUtil::ComputeRowLength e la dimensione fisica delle righe. Questo potrebbe essere visto come un bug :SQL Server non deve contare le colonne di metadati nel flusso di inserimento verso la dimensione fisica finale della riga. D'altra parte, il calcolo può essere semplicemente una stima del massimo sforzo utilizzando il generico aggiornamento operatore.
Il calcolo non tiene inoltre conto di altri fattori come l'overhead di 14 byte del controllo delle versioni delle righe. Questo può essere verificato rieseguendo lo script demo con uno degli isolamento snapshot o leggere l'isolamento dello snapshot commit opzioni del database abilitate. La dimensione fisica della riga aumenterà di 14 byte (da 60 byte a 74), ma la soglia per registrazione minima rimane invariato a 898 righe.
Calcolo della soglia
Ora abbiamo tutti i dettagli di cui abbiamo bisogno per vedere perché la soglia è 898 righe per questa tabella su SQL Server 2012 e versioni precedenti:
- 898 righe soddisfano il primo requisito per più di 250 righe .
- Dimensione riga calcolata =73 byte.
- Numero stimato di righe =897.
- Dimensione totale dei dati =73 byte * 897 righe =65481 byte.
- Pagine totali =65481 / 8192 =7.9932861328125.
- Questo è appena al di sotto del secondo requisito per>=8 pagine.
- Per 898 righe, il numero di pagine è 8,002197265625.
- Sono >=8 pagine quindi registrazione minima è attivato.
In SQL Server 2014 e versioni successive , le modifiche sono:
- La dimensione della riga viene calcolata dal generatore di metadati.
- La colonna intera interna nel localizzatore tabella non è più presente nel flusso di inserimento. Questo rappresenta l'unificatore , che si applica solo agli indici. Sembra probabile che sia stato rimosso come correzione di un bug.
- La dimensione della riga prevista cambia da 73 a 69 byte a causa della colonna intera omessa (4 byte).
- La dimensione fisica è ancora di 60 byte. La differenza rimanente di 9 byte è spiegata dal RID aggiuntivo da 8 byte e dalle colonne interne di bit da 1 byte nel flusso di inserimento.
Per raggiungere la soglia di 8 pagine con 69 byte per riga:
- 8 pagine * 8192 byte per pagina =65536 byte.
- 65535 byte / 69 byte per riga =949,7971014492754 righe.
- Ci aspettiamo quindi un minimo di 950 righe per abilitare il caricamento in blocco del set di righe per questa tabella su SQL Server 2014 in poi.
Riepilogo e pensieri finali
In contrasto con i metodi di caricamento in blocco che supportano dimensione batch , come spiegato nel post di Parikshit Savjani, INSERT...SELECT in un heap non indicizzato (vuoto o meno) non sempre comporta una registrazione minima quando viene specificato il blocco della tabella.
Per abilitare la registrazione minima con INSERT...SELECT , SQL Server deve prevedere più di 250 righe con una dimensione totale di almeno un'estensione (8 pagine).
Quando si calcola la dimensione totale di inserimento stimata (da confrontare con la soglia di 8 pagine), SQL Server moltiplica il numero stimato di righe per la dimensione massima calcolata della riga. SQL Server conta le colonne interne presente nel flusso di inserimento quando si calcola la dimensione della riga. Per SQL Server 2012 e versioni precedenti, vengono aggiunti 13 byte per riga. Per SQL Server 2014 e versioni successive, aggiunge 9 byte per riga. Ciò influisce solo sul calcolo; non influisce sulla dimensione fisica finale delle righe.
Quando è attivo il caricamento in blocco dell'heap con registrazione minima, SQL Server non inserire le righe una alla volta. Le estensioni vengono allocate in anticipo e le righe da inserire vengono raccolte in pagine completamente nuove da sqlmin!RowsetBulk prima di essere aggiunto alla struttura esistente. Di seguito è mostrato un esempio di stack di chiamate:
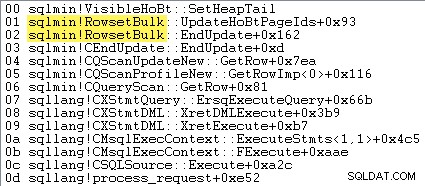
Le letture logiche non vengono riportate per la tabella di destinazione quando viene utilizzato il caricamento bulk dell'heap con registrazione minima:l'Inserimento tabella l'operatore non ha bisogno di leggere una pagina esistente per individuare il punto di inserimento per ogni nuova riga.
I piani di esecuzione attualmente non vengono visualizzati quante righe o pagine sono state inserite utilizzando il caricamento collettivo del set di righe e registrazione minima . Forse queste informazioni utili verranno aggiunte al prodotto in una versione futura.