Come abbiamo visto in precedenza, potrebbe essere difficile per le aziende spostare i propri dati da RDS per MySQL. Nella prima parte di questo blog, ti abbiamo mostrato come configurare il tuo ambiente di destinazione su EC2 e inserire un livello proxy (ProxySQL) tra le tue applicazioni e RDS. In questa seconda parte, ti mostreremo come eseguire l'effettiva migrazione dei dati sul tuo server e quindi reindirizzare le tue applicazioni alla nuova istanza del database senza tempi di inattività.
Copiare dati da RDS
Una volta che il traffico del nostro database è in esecuzione tramite ProxySQL, possiamo iniziare i preparativi per copiare i nostri dati da RDS. Dobbiamo farlo per impostare la replica tra RDS e la nostra istanza MySQL in esecuzione su EC2. Fatto ciò, configureremo ProxySQL per reindirizzare il traffico da RDS al nostro MySQL/EC2.
Come abbiamo discusso nel primo post del blog di questa serie, l'unico modo per ottenere i dati dall'RDS è tramite il dump logico. Senza l'accesso all'istanza, non possiamo utilizzare alcuno strumento di backup fisico attivo come xtrabackup. Non possiamo nemmeno utilizzare gli snapshot poiché non c'è modo di creare nient'altro che una nuova istanza RDS dallo snapshot.
Siamo limitati agli strumenti di dump logici, quindi l'opzione logica sarebbe quella di utilizzare mydumper/myloader per elaborare i dati. Fortunatamente, mydumper può creare backup coerenti in modo che possiamo fare affidamento su di esso per fornire le coordinate binlog a cui il nostro nuovo slave può connettersi. Il problema principale durante la creazione di repliche RDS è la politica di rotazione del binlog:il caricamento e il dump logico possono richiedere anche giorni su set di dati più grandi (centinaia di gigabyte) e devi mantenere i binlog sull'istanza RDS per la durata dell'intero processo. Certo, puoi aumentare la conservazione della rotazione dei binlog su RDS (chiama mysql.rds_set_configuration('binlog retention hours', 24); - puoi mantenerli fino a 7 giorni) ma è molto più sicuro farlo in modo diverso.
Prima di procedere con un dump, aggiungeremo una replica alla nostra istanza RDS.
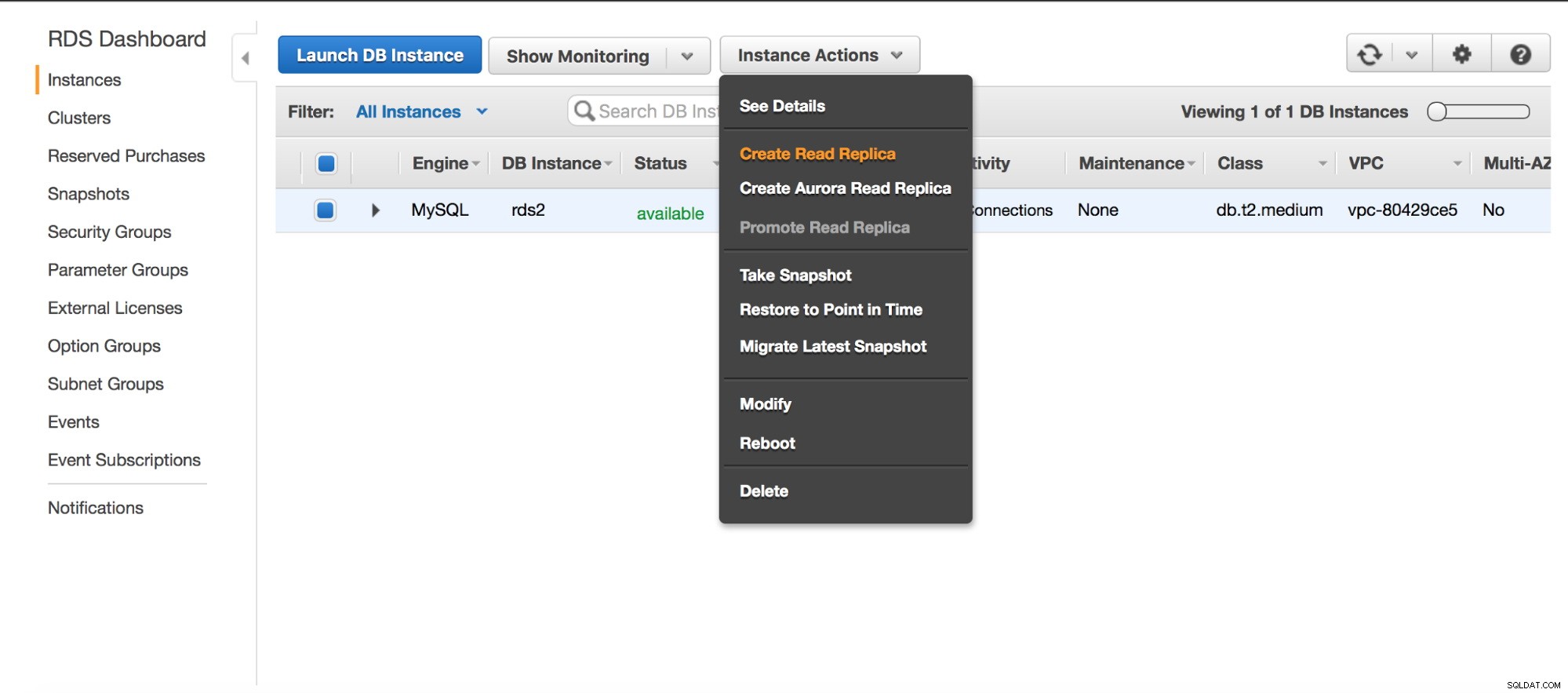 Dashboard Amazon RDS
Dashboard Amazon RDS 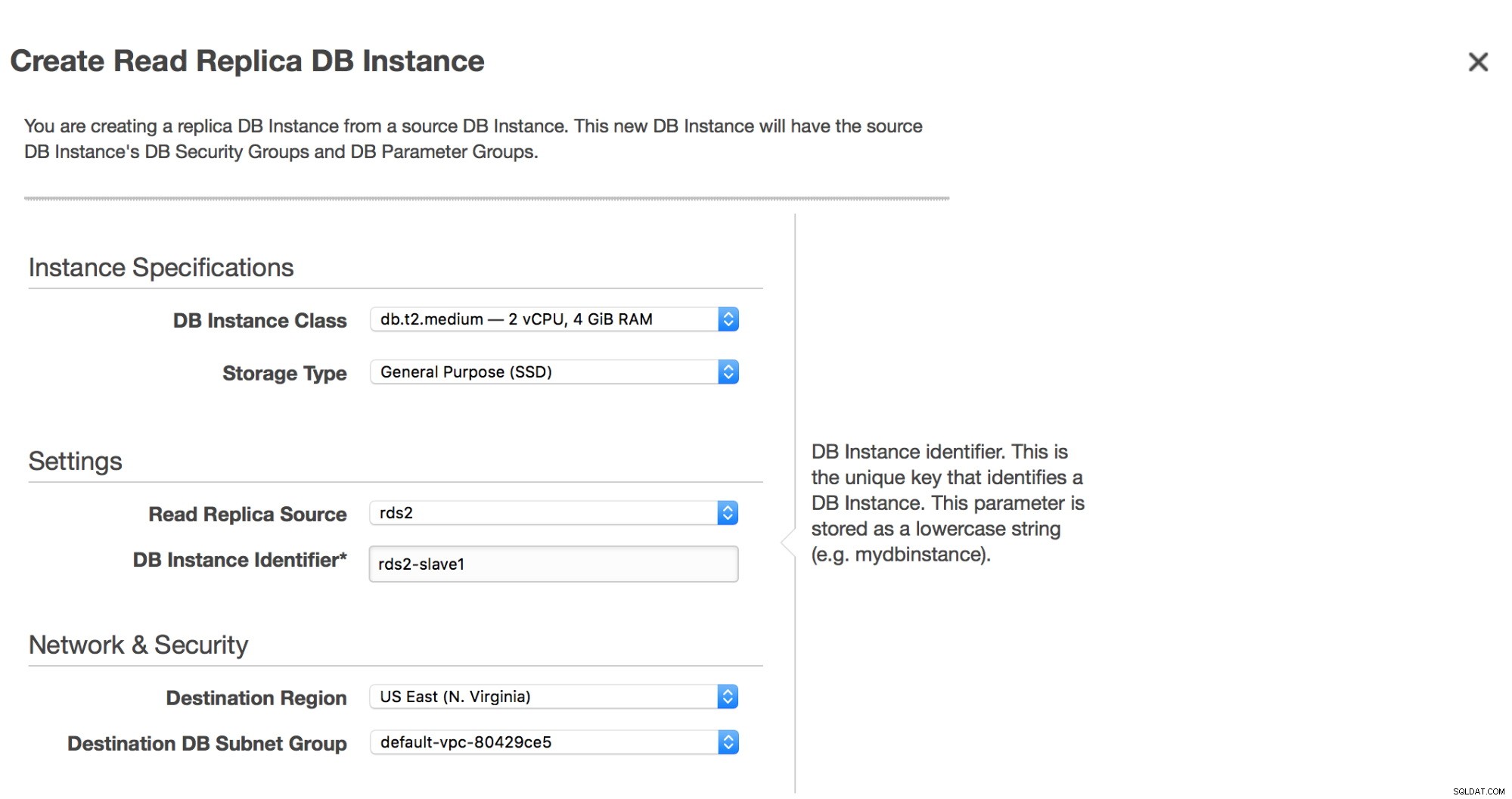 Crea DB di replica in RDS
Crea DB di replica in RDS 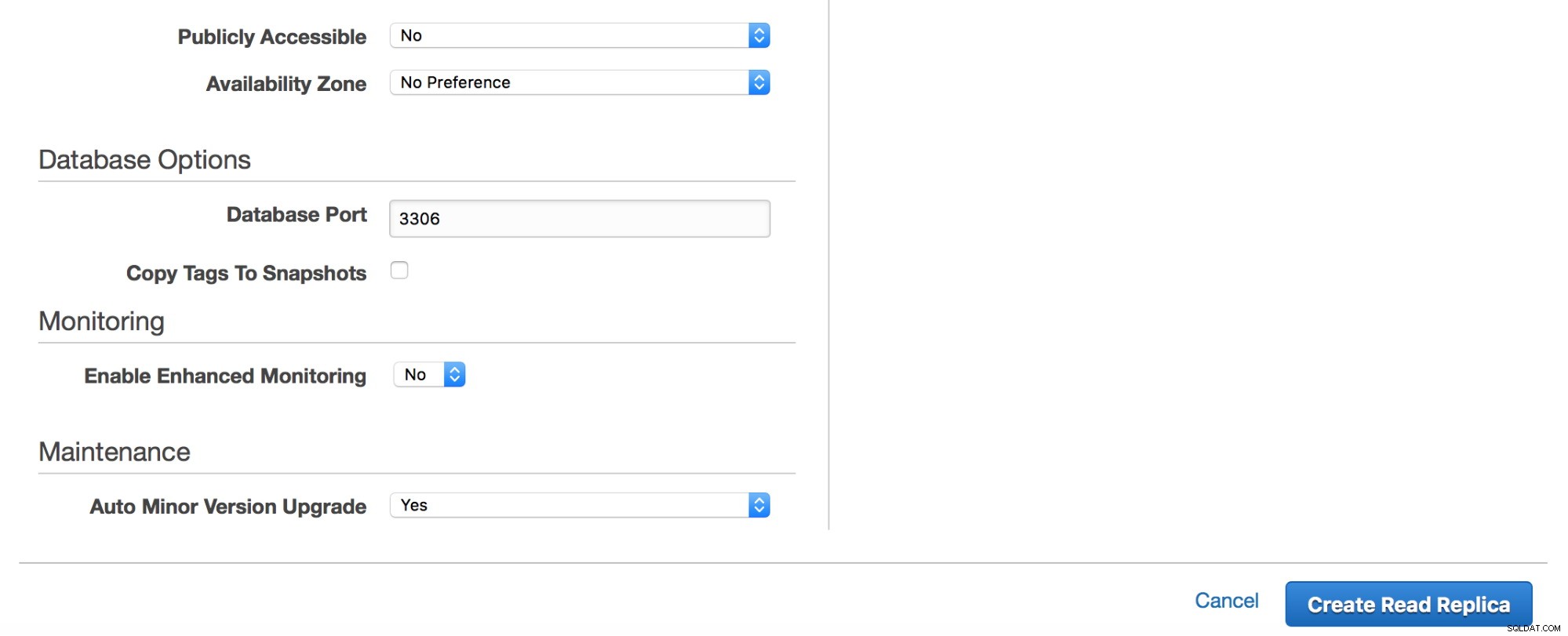
Dopo aver fatto clic sul pulsante "Crea replica di lettura", verrà avviata un'istantanea sulla replica RDS "master". Verrà utilizzato per il provisioning del nuovo slave. Il processo può richiedere ore, tutto dipende dalle dimensioni del volume, quando è stata eseguita l'ultima istantanea e dalle prestazioni del volume (io1/gp2? Magnetico? Quanti pIOPS ha un volume?).
 Replica RDS master
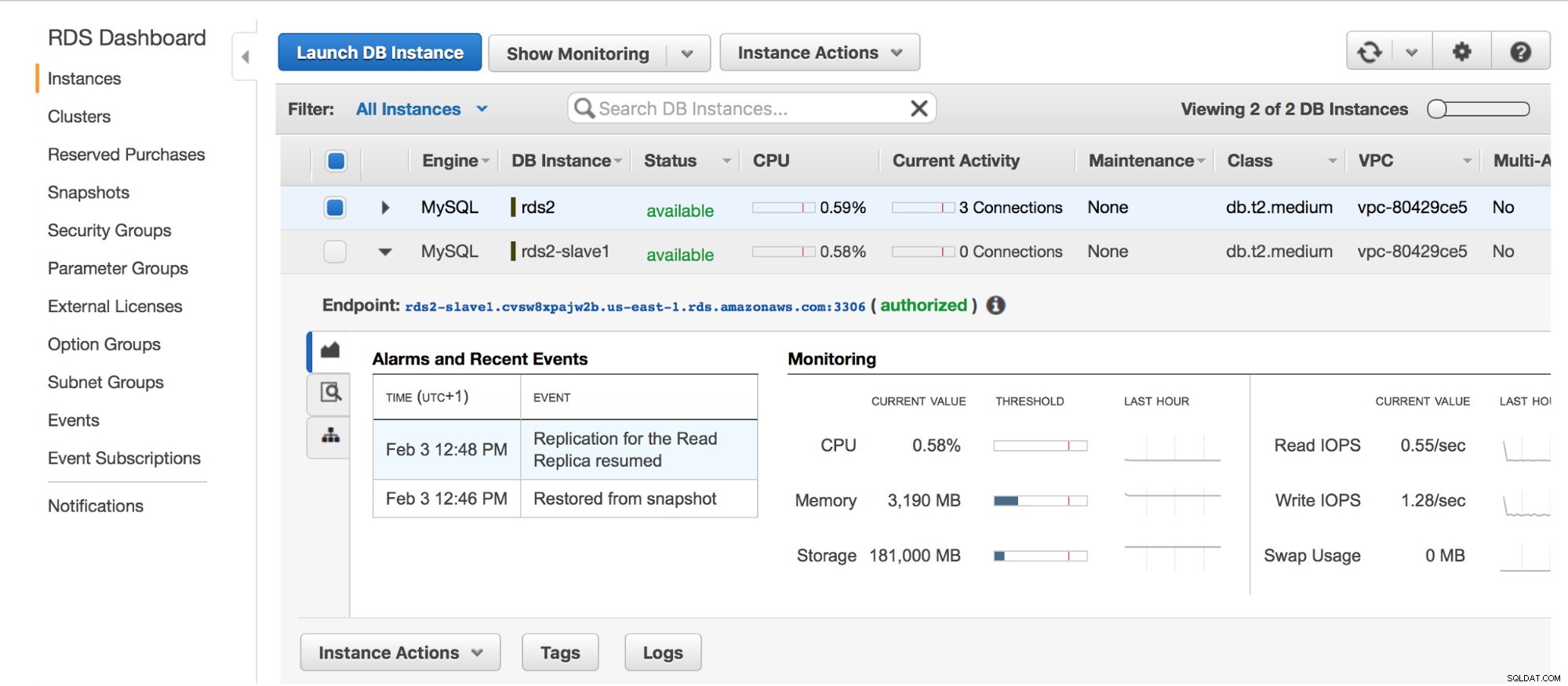
Replica RDS master Quando lo slave è pronto (il suo stato è cambiato in "disponibile"), possiamo accedervi utilizzando il suo endpoint RDS.
 Slave RDS
Slave RDS Una volta effettuato l'accesso, interromperemo la replica sul nostro slave:questo assicurerà che il master RDS non elimini i log binari e che saranno ancora disponibili per il nostro slave EC2 una volta completato il processo di dump/ricarica.
mysql> CALL mysql.rds_stop_replication;
+---------------------------+
| Message |
+---------------------------+
| Slave is down or disabled |
+---------------------------+
1 row in set (1.02 sec)
Query OK, 0 rows affected (1.02 sec)Ora è finalmente il momento di copiare i dati su EC2. Per prima cosa, dobbiamo installare mydumper. Puoi ottenerlo da github:https://github.com/maxbube/mydumper. Il processo di installazione è abbastanza semplice e ben descritto nel file readme, quindi non lo tratteremo qui. Molto probabilmente dovrai installare un paio di pacchetti (elencati nel readme) e la parte più difficile è identificare quale pacchetto contiene mysql_config:dipende dal tipo di MySQL (e talvolta anche dalla versione di MySQL).
Una volta che mydumper è compilato e pronto per l'uso, puoi eseguirlo:
example@sqldat.com:~/mydumper# mkdir /tmp/rdsdump
example@sqldat.com:~/mydumper# ./mydumper -h rds2.cvsw8xpajw2b.us-east-1.rds.amazonaws.com -p tpccpass -u tpcc -o /tmp/rdsdump --lock-all-tables --chunk-filesize 100 --events --routines --triggers
. Si prega di notare --lock-all-tables che assicura che l'istantanea dei dati sia coerente e sarà possibile utilizzarla per creare uno slave. Ora dobbiamo aspettare che mydumper completi il suo compito.
È necessario un altro passaggio:non vogliamo ripristinare lo schema mysql ma dobbiamo copiare gli utenti e le loro sovvenzioni. Possiamo usare pt-show-grants per questo:
example@sqldat.com:~# wget https://percona.com/get/pt-show-grants
example@sqldat.com:~# chmod u+x ./pt-show-grants
example@sqldat.com:~# ./pt-show-grants -h rds2.cvsw8xpajw2b.us-east-1.rds.amazonaws.com -u tpcc -p tpccpass > grants.sqlUn esempio di pt-show-grants potrebbe assomigliare a questo:
-- Grants for 'sbtest'@'%'
CREATE USER IF NOT EXISTS 'sbtest'@'%';
ALTER USER 'sbtest'@'%' IDENTIFIED WITH 'mysql_native_password' AS '*2AFD99E79E4AA23DE141540F4179F64FFB3AC521' REQUIRE NONE PASSWORD EXPIRE DEFAULT ACCOUNT UNLOCK;
GRANT ALTER, ALTER ROUTINE, CREATE, CREATE ROUTINE, CREATE TEMPORARY TABLES, CREATE USER, CREATE VIEW, DELETE, DROP, EVENT, EXECUTE, INDEX, INSERT, LOCK TABLES, PROCESS, REFERENCES, RELOAD, REPLICATION CLIENT, REPLICATION SLAVE, SELECT, SHOW DATABASES, SHOW VIEW, TRIGGER, UPDATE ON *.* TO 'sbtest'@'%';Sta a te scegliere quali utenti devono essere copiati sulla tua istanza MySQL/EC2. Non ha senso farlo per tutti loro. Ad esempio, gli utenti root non hanno il privilegio "SUPER" su RDS, quindi è meglio ricrearli da zero. Quello che devi copiare sono le sovvenzioni per l'utente dell'applicazione. Abbiamo anche bisogno di copiare gli utenti utilizzati da ProxySQL (proxysql-monitor nel nostro caso).
Inserimento di dati nella tua istanza MySQL/EC2
Come indicato sopra, non vogliamo ripristinare gli schemi di sistema. Quindi sposteremo i file relativi a quegli schemi fuori dalla nostra directory mydumper:
example@sqldat.com:~# mkdir /tmp/rdsdump_sys/
example@sqldat.com:~# mv /tmp/rdsdump/mysql* /tmp/rdsdump_sys/
example@sqldat.com:~# mv /tmp/rdsdump/sys* /tmp/rdsdump_sys/Quando abbiamo finito, è il momento di iniziare a caricare i dati nell'istanza MySQL/EC2:
example@sqldat.com:~/mydumper# ./myloader -d /tmp/rdsdump/ -u tpcc -p tpccpass -t 4 --overwrite-tables -h 172.30.4.238Tieni presente che abbiamo utilizzato quattro thread (-t 4):assicurati di impostarlo su qualsiasi cosa abbia senso nel tuo ambiente. Si tratta di saturare l'istanza MySQL di destinazione:CPU o I/O, a seconda del collo di bottiglia. Vogliamo spremere il più possibile per assicurarci di aver utilizzato tutte le risorse disponibili per caricare i dati.
Dopo che i dati principali sono stati caricati, ci sono altri due passaggi da eseguire, entrambi sono correlati agli interni di RDS ed entrambi potrebbero interrompere la nostra replica. Innanzitutto, RDS contiene un paio di tabelle rds_* nello schema mysql. Vogliamo caricarli nel caso in cui alcuni di essi vengano utilizzati da RDS:la replica si interromperà se il nostro slave non li avrà. Possiamo farlo nel modo seguente:
example@sqldat.com:~/mydumper# for i in $(ls -alh /tmp/rdsdump_sys/ | grep rds | awk '{print $9}') ; do echo $i ; mysql -ppass -uroot mysql < /tmp/rdsdump_sys/$i ; done
mysql.rds_configuration-schema.sql
mysql.rds_configuration.sql
mysql.rds_global_status_history_old-schema.sql
mysql.rds_global_status_history-schema.sql
mysql.rds_heartbeat2-schema.sql
mysql.rds_heartbeat2.sql
mysql.rds_history-schema.sql
mysql.rds_history.sql
mysql.rds_replication_status-schema.sql
mysql.rds_replication_status.sql
mysql.rds_sysinfo-schema.sqlUn problema simile è con le tabelle dei fusi orari, dobbiamo caricarle utilizzando i dati dell'istanza RDS:
example@sqldat.com:~/mydumper# for i in $(ls -alh /tmp/rdsdump_sys/ | grep time_zone | grep -v schema | awk '{print $9}') ; do echo $i ; mysql -ppass -uroot mysql < /tmp/rdsdump_sys/$i ; done
mysql.time_zone_name.sql
mysql.time_zone.sql
mysql.time_zone_transition.sql
mysql.time_zone_transition_type.sqlQuando tutto questo è pronto, possiamo configurare la replica tra RDS (master) e la nostra istanza MySQL/EC2 (slave).
Configurazione della replica
Mydumper, quando esegue un dump coerente, annota una posizione di registro binario. Possiamo trovare questi dati in un file chiamato metadata nella directory dump. Diamo un'occhiata, useremo quindi la posizione per impostare la replica.
example@sqldat.com:~/mydumper# cat /tmp/rdsdump/metadata
Started dump at: 2017-02-03 16:17:29
SHOW SLAVE STATUS:
Host: 10.1.4.180
Log: mysql-bin-changelog.007079
Pos: 10537102
GTID:
Finished dump at: 2017-02-03 16:44:46Un'ultima cosa che ci manca è un utente che potremmo usare per configurare il nostro slave. Creiamone uno sull'istanza RDS:
example@sqldat.com:~# mysql -ppassword -h rds2.cvsw8xpajw2b.us-east-1.rds.amazonaws.commysql> CREATE USER IF NOT EXISTS 'rds_rpl'@'%' IDENTIFIED BY 'rds_rpl_pass';
Query OK, 0 rows affected (0.04 sec)mysql> GRANT REPLICATION SLAVE ON *.* TO 'rds_rpl'@'%';
Query OK, 0 rows affected (0.01 sec)Ora è il momento di asservire il nostro server MySQL/EC2 dall'istanza RDS:
mysql> CHANGE MASTER TO MASTER_HOST='rds2.cvsw8xpajw2b.us-east-1.rds.amazonaws.com', MASTER_USER='rds_rpl', MASTER_PASSWORD='rds_rpl_pass', MASTER_LOG_FILE='mysql-bin-changelog.007079', MASTER_LOG_POS=10537102;
Query OK, 0 rows affected, 2 warnings (0.03 sec)mysql> START SLAVE;
Query OK, 0 rows affected (0.02 sec)mysql> SHOW SLAVE STATUS\G
*************************** 1. row ***************************
Slave_IO_State: Queueing master event to the relay log
Master_Host: rds2.cvsw8xpajw2b.us-east-1.rds.amazonaws.com
Master_User: rds_rpl
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin-changelog.007080
Read_Master_Log_Pos: 13842678
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 20448
Relay_Master_Log_File: mysql-bin-changelog.007079
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 10557220
Relay_Log_Space: 29071382
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 258726
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1237547456
Master_UUID: b5337d20-d815-11e6-abf1-120217bb3ac2
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: System lock
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set:
Auto_Position: 0
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
1 row in set (0.01 sec)L'ultimo passaggio sarà trasferire il nostro traffico dall'istanza RDS a MySQL/EC2, ma prima dobbiamo lasciarlo recuperare.
Quando lo schiavo ha raggiunto, dobbiamo eseguire un cutover. Per automatizzarlo, abbiamo deciso di preparare un breve script bash che si collegherà a ProxySQL e farà ciò che deve essere fatto.
# At first, we define old and new masters
OldMaster=rds2.cvsw8xpajw2b.us-east-1.rds.amazonaws.com
NewMaster=172.30.4.238
(
# We remove entries from mysql_replication_hostgroup so ProxySQL logic won’t interfere
# with our script
echo "DELETE FROM mysql_replication_hostgroups;"
# Then we set current master to OFFLINE_SOFT - this will allow current transactions to
# complete while not accepting any more transactions - they will wait (by default for
# 10 seconds) for a master to become available again.
echo "UPDATE mysql_servers SET STATUS='OFFLINE_SOFT' WHERE hostname=\"$OldMaster\";"
echo "LOAD MYSQL SERVERS TO RUNTIME;"
) | mysql -u admin -padmin -h 127.0.0.1 -P6032
# Here we are going to check for connections in the pool which are still used by
# transactions which haven’t closed so far. If we see that neither hostgroup 10 nor
# hostgroup 20 has open transactions, we can perform a switchover.
CONNUSED=`mysql -h 127.0.0.1 -P6032 -uadmin -padmin -e 'SELECT IFNULL(SUM(ConnUsed),0) FROM stats_mysql_connection_pool WHERE status="OFFLINE_SOFT" AND (hostgroup=10 OR hostgroup=20)' -B -N 2> /dev/null`
TRIES=0
while [ $CONNUSED -ne 0 -a $TRIES -ne 20 ]
do
CONNUSED=`mysql -h 127.0.0.1 -P6032 -uadmin -padmin -e 'SELECT IFNULL(SUM(ConnUsed),0) FROM stats_mysql_connection_pool WHERE status="OFFLINE_SOFT" AND (hostgroup=10 OR hostgroup=20)' -B -N 2> /dev/null`
TRIES=$(($TRIES+1))
if [ $CONNUSED -ne "0" ]; then
sleep 0.05
fi
done
# Here is our switchover logic - we basically exchange hostgroups for RDS and EC2
# instance. We also configure back mysql_replication_hostgroups table.
(
echo "UPDATE mysql_servers SET STATUS='ONLINE', hostgroup_id=110 WHERE hostname=\"$OldMaster\" AND hostgroup_id=10;"
echo "UPDATE mysql_servers SET STATUS='ONLINE', hostgroup_id=120 WHERE hostname=\"$OldMaster\" AND hostgroup_id=20;"
echo "UPDATE mysql_servers SET hostgroup_id=10 WHERE hostname=\"$NewMaster\" AND hostgroup_id=110;"
echo "UPDATE mysql_servers SET hostgroup_id=20 WHERE hostname=\"$NewMaster\" AND hostgroup_id=120;"
echo "INSERT INTO mysql_replication_hostgroups VALUES (10, 20, 'hostgroups');"
echo "LOAD MYSQL SERVERS TO RUNTIME;"
) | mysql -u admin -padmin -h 127.0.0.1 -P6032Al termine, dovresti vedere i seguenti contenuti nella tabella mysql_servers:
mysql> select * from mysql_servers;
+--------------+-----------------------------------------------+------+--------+--------+-------------+-----------------+---------------------+---------+----------------+-------------+
| hostgroup_id | hostname | port | status | weight | compression | max_connections | max_replication_lag | use_ssl | max_latency_ms | comment |
+--------------+-----------------------------------------------+------+--------+--------+-------------+-----------------+---------------------+---------+----------------+-------------+
| 20 | 172.30.4.238 | 3306 | ONLINE | 1 | 0 | 100 | 10 | 0 | 0 | read server |
| 10 | 172.30.4.238 | 3306 | ONLINE | 1 | 0 | 100 | 10 | 0 | 0 | read server |
| 120 | rds2.cvsw8xpajw2b.us-east-1.rds.amazonaws.com | 3306 | ONLINE | 1 | 0 | 100 | 10 | 0 | 0 | |
| 110 | rds2.cvsw8xpajw2b.us-east-1.rds.amazonaws.com | 3306 | ONLINE | 1 | 0 | 100 | 10 | 0 | 0 | |
+--------------+-----------------------------------------------+------+--------+--------+-------------+-----------------+---------------------+---------+----------------+-------------+Sul lato dell'applicazione, non dovresti vedere un grande impatto, grazie alla capacità di ProxySQL di mettere in coda le query per un po' di tempo.
Con questo abbiamo completato il processo di spostamento del database da RDS a EC2. L'ultimo passaggio da fare è rimuovere il nostro slave RDS:ha fatto il suo lavoro e può essere eliminato.
Nel nostro prossimo post sul blog, ci svilupperemo su questo. Esamineremo uno scenario in cui sposteremo il nostro database da AWS/EC2 a un provider di hosting separato.