SQLAlchemy ti aiuta a lavorare con i database in Python. In questo post, ti diciamo tutto ciò che devi sapere per iniziare con questo modulo.
Nell'articolo precedente abbiamo parlato di come utilizzare Python nel processo ETL. Ci siamo concentrati sul portare a termine il lavoro eseguendo stored procedure e query SQL. In questo articolo e nel prossimo utilizzeremo un approccio diverso. Invece di scrivere codice SQL, useremo il toolkit SQLAlchemy. Puoi anche utilizzare questo articolo separatamente, come una rapida introduzione all'installazione e all'utilizzo di SQLAlchemy.
Pronto? Cominciamo.
Cos'è SQLAlchemy?
Python è ben noto per il suo numero e varietà di moduli. Questi moduli riducono significativamente il nostro tempo di codifica perché implementano le routine necessarie per svolgere un'attività specifica. Sono disponibili numerosi moduli che funzionano con i dati, incluso SQLAlchemy.
Per descrivere SQLAlchemy, userò una citazione da SQLAlchemy.org:
SQLAlchemy è il toolkit Python SQL e Object Relational Mapper che offre agli sviluppatori di applicazioni tutta la potenza e la flessibilità di SQL.
Fornisce una suite completa di ben nota persistenza a livello aziendale modelli, progettati per un accesso al database efficiente e ad alte prestazioni, adattati in un linguaggio di dominio semplice e Pythonic.
La parte più importante qui riguarda l'ORM (object-relational mapper), che ci aiuta a trattare gli oggetti del database come oggetti Python piuttosto che come elenchi.
Prima di andare oltre con SQLAlchemy, fermiamoci e parliamo di ORM.
Pro e contro dell'utilizzo degli ORM
Rispetto all'SQL grezzo, gli ORM hanno i loro pro e contro e la maggior parte di questi si applica anche a SQLAlchemy.
La roba buona:
- Portabilità del codice. L'ORM si occupa delle differenze sintattiche tra i database.
- Una sola lingua è necessario per gestire il database. Anche se, ad essere onesti, questa non dovrebbe essere la motivazione principale per utilizzare un ORM.
- Gli ORM semplificano il tuo codice , per esempio. si prendono cura delle relazioni e le trattano come oggetti, il che è fantastico se sei abituato a OOP.
- Puoi manipolare i tuoi dati all'interno del programma .
Sfortunatamente, tutto ha un prezzo. Le cose non così buone sugli ORM:
- In alcuni casi, un ORM potrebbe essere lento .
- Scrittura di query complesse potrebbe diventare ancora più complicato o potrebbe comportare query lente. Ma questo non è il caso quando si utilizza SQLAlchemy.
- Se conosci bene il tuo DBMS, è una perdita di tempo imparare a scrivere le stesse cose in un ORM.
Ora che abbiamo affrontato l'argomento, torniamo a SQLAlchemy.
Prima di iniziare...
…ricordiamoci l'obiettivo di questo articolo. Se sei solo interessato all'installazione di SQLAlchemy e hai bisogno di un breve tutorial su come eseguire semplici comandi, questo articolo lo farà. Tuttavia, i comandi presentati in questo articolo verranno utilizzati nel prossimo articolo per eseguire il processo ETL e sostituire il codice SQL (stored procedure) e Python che abbiamo presentato negli articoli precedenti.
Bene, ora iniziamo proprio dall'inizio:con l'installazione di SQLAlchemy.
Installazione di SQLAlchemy
1. Verifica se il modulo è già installato
Per utilizzare un modulo Python, devi installarlo (cioè se non è stato precedentemente installato). Un modo per verificare quali moduli sono stati installati è usare questo comando in Python Shell:
help('modules')
Per verificare se un modulo specifico è installato, prova semplicemente a importarlo. Usa questi comandi:
import sqlalchemy sqlalchemy.__version__
Se SQLAlchemy è già installato, la prima riga verrà eseguita correttamente. import è un comando Python standard utilizzato per importare i moduli. Se il modulo non è installato, Python genererà un errore – in realtà un elenco di errori, in testo rosso – che non puoi perdere :)
Il secondo comando restituisce la versione corrente di SQLAlchemy. Il risultato restituito è illustrato di seguito:

Avremo bisogno anche di un altro modulo, e questo è PyMySQL . Questa è una libreria client MySQL leggera in puro Python. Questo modulo supporta tutto ciò di cui abbiamo bisogno per lavorare con un database MySQL, dall'esecuzione di semplici query ad azioni di database più complesse. Possiamo verificare se esiste usando help('modules') , come descritto in precedenza, o utilizzando le due istruzioni seguenti:
import pymysql pymysql.__version__
Ovviamente, questi sono gli stessi comandi che abbiamo usato per verificare se SQLAlchemy è stato installato.
Cosa succede se SQLAlchemy o PyMySQL non sono già installati?
L'importazione di moduli installati in precedenza non è difficile. Ma cosa succede se i moduli che ti servono non sono già installati?
Alcuni moduli hanno un pacchetto di installazione, ma per lo più utilizzerai il comando pip per installarli. PIP è uno strumento Python utilizzato per installare e disinstallare moduli. Il modo più semplice per installare un modulo (in Windows OS) è:
- Usa Prompt dei comandi -> Esegui -> cmd .
- Posizione nella directory Python cd C:\...\Python\Python37\Scripts .
- Esegui il comando pip
install(nel nostro caso, eseguiremopip install pyMySQLepip install sqlAlchemy.
PIP può essere utilizzato anche per disinstallare il modulo esistente. Per farlo, dovresti usare pip uninstall .
2. Connessione al database
Sebbene l'installazione di tutto il necessario per utilizzare SQLAlchemy sia essenziale, non è molto interessante. Né fa davvero parte di ciò che ci interessa. Non ci siamo nemmeno collegati ai database che vogliamo utilizzare. Lo risolveremo ora:
import sqlalchemy
from sqlalchemy.engine import create_engine
engine_live = sqlalchemy.create_engine('mysql+pymysql://:@localhost:3306/subscription_live')
connection_live = engine_live.connect()
print(engine_live.table_names())
Utilizzando lo script sopra, stabiliremo una connessione al database che si trova sul nostro server locale, il subscription_live Banca dati.
(Nota: Sostituisci
Esaminiamo lo script, comando per comando.
import sqlalchemy from sqlalchemy.engine import create_engine
Queste due righe importano il nostro modulo e il create_engine funzione.
Successivamente, stabiliremo una connessione al database che si trova sul nostro server.
engine_live = sqlalchemy.create_engine('mysql+pymysql:// :@localhost:3306/subscription_live')
connection_live = engine_live.connect()
La funzione create_engine crea il motore e utilizza .connect() , si collega al database. Il create_engine la funzione utilizza questi parametri:
dialect+driver://username:password@host:port/database
Nel nostro caso, il dialetto è mysql , il driver è pymysql (installato in precedenza) e le restanti variabili sono specifiche per il server e i database a cui vogliamo connetterci.
(Nota: Se ti connetti in locale, usa localhost invece del tuo indirizzo IP "locale", 127.0.0.1 e la porta appropriata :3306 .)

Il risultato del comando print(engine_live.table_names()) è mostrato nell'immagine sopra. Come previsto, abbiamo ottenuto l'elenco di tutte le tabelle dal nostro database operativo/attivo.
3. Esecuzione di comandi SQL utilizzando SQLAlchemy
In questa sezione analizzeremo i comandi SQL più importanti, esamineremo la struttura della tabella ed eseguiremo tutti e quattro i comandi DML:SELECT, INSERT, UPDATE e DELETE.
Discuteremo separatamente le affermazioni utilizzate in questo script. Tieni presente che abbiamo già esaminato la parte relativa alla connessione di questo script e abbiamo già elencato i nomi delle tabelle. Ci sono modifiche minori in questa riga:
from sqlalchemy import create_engine, select, MetaData, Table, asc
Abbiamo appena importato tutto ciò che utilizzeremo da SQLAlchemy.
Tabelle e struttura
Eseguiremo lo script digitando il seguente comando nella shell Python:
import os
file_path = 'D://python_scripts'
os.chdir(file_path)
exec(open("queries.py").read())
Il risultato è lo script eseguito. Ora analizziamo il resto dello script.
SQLAlchemy importa le informazioni relative a tabelle, struttura e relazioni. Per lavorare con queste informazioni, potrebbe essere utile controllare l'elenco delle tabelle (e le relative colonne) nel database:
#print connected tables
print("\n -- Tables from _live database -- ")
print (engine_live.table_names())

Questo restituisce semplicemente un elenco di tutte le tabelle dal database connesso.
Nota: Il table_names() il metodo restituisce un elenco di nomi di tabelle per il motore specificato. Puoi stampare l'intero elenco o scorrere di esso utilizzando un ciclo (come potresti fare con qualsiasi altro elenco).
Successivamente, restituiremo un elenco di tutti gli attributi dalla tabella selezionata. La parte rilevante dello script e il risultato sono mostrati di seguito:
#SELECT
metadata = MetaData(bind=None)
table_city = Table('city', metadata, autoload = True, autoload_with = engine_live)
# print table columns
print("\n -- Tables columns for table 'city' --")
for column in table_city.c:
print(column.name)
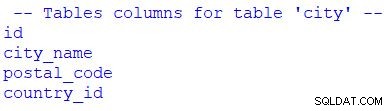
Puoi vedere che ho usato for per scorrere il set di risultati. Potremmo sostituire table_city.c con table_city.columns .
Nota: Il processo di caricamento della descrizione del database e di creazione dei metadati in SQLAlchemy è chiamato riflessione.
Nota: MetaData è l'oggetto che conserva le informazioni sugli oggetti nel database, quindi anche le tabelle nel database sono collegate a questo oggetto. In generale, questo oggetto memorizza informazioni sull'aspetto dello schema del database. Lo utilizzerai come unico punto di contatto quando desideri apportare modifiche o ottenere informazioni sullo schema del database.
Nota: Gli attributi autoload = True e autoload_with = engine_live dovrebbe essere utilizzato per garantire che gli attributi della tabella vengano caricati (se non lo sono già stati).
SELEZIONA
Non credo di dover spiegare quanto sia importante l'istruzione SELECT :) Quindi, diciamo solo che puoi usare SQLAlchemy per scrivere istruzioni SELECT. Se sei abituato alla sintassi MySQL, ci vorrà del tempo per adattarti; comunque, tutto è abbastanza logico. Per dirla nel modo più semplice possibile, direi che l'istruzione SELECT è suddivisa e alcune parti vengono omesse, ma tutto è ancora nello stesso ordine.
Proviamo ora alcune istruzioni SELECT.
# simple select
print("\n -- SIMPLE SELECT -- ")
stmt = select([table_city])
print(stmt)
print(connection_live.execute(stmt).fetchall())
# loop through results
results = connection_live.execute(stmt).fetchall()
for result in results:
print(result)
La prima è una semplice istruzione SELECT restituendo tutti i valori dalla tabella data. La sintassi di questa affermazione è molto semplice:ho inserito il nome della tabella in select() . Si prega di notare che ho:
- Preparato l'istruzione -
stmt = select([table_city]. - Stampa la dichiarazione usando
print(stmt), che ci dà una buona idea dell'istruzione appena eseguita. Questo potrebbe essere utilizzato anche per il debug. - Stampato il risultato con
print(connection_live.execute(stmt).fetchall()). - Ho passato in rassegna il risultato e stampato ogni singolo record.
Nota: Poiché abbiamo anche caricato i vincoli di chiave primaria ed esterna in SQLAlchemy, l'istruzione SELECT accetta un elenco di oggetti tabella come argomenti e stabilisce automaticamente le relazioni dove necessario.
Il risultato è mostrato nell'immagine qui sotto:

Python recupererà tutti gli attributi dalla tabella e li memorizzerà nell'oggetto. Come mostrato, possiamo usare questo oggetto per eseguire operazioni aggiuntive. Il risultato finale della nostra dichiarazione è un elenco di tutte le città della city tabella.
Ora siamo pronti per una query più complessa. Ho appena aggiunto una clausola ORDER BY .
# simple select
# simple select, using order by
print("\n -- SIMPLE SELECT, USING ORDER BY")
stmt = select([table_city]).order_by(asc(table_city.columns.id))
print(stmt)
print(connection_live.execute(stmt).fetchall())

Nota: Il asc() Il metodo esegue l'ordinamento crescente rispetto all'oggetto padre, utilizzando colonne definite come parametri.
L'elenco restituito è lo stesso, ma ora è ordinato in base al valore id, in ordine crescente. È importante notare che abbiamo semplicemente aggiunto .order_by( alla precedente query SELECT. Il .order_by(...) Il metodo ci consente di modificare l'ordine del set di risultati restituito, nello stesso modo in cui utilizzeremmo in una query SQL. Pertanto, i parametri devono seguire la logica SQL, utilizzando i nomi delle colonne o l'ordine delle colonne e ASC o DESC.
Successivamente, aggiungeremo DOVE alla nostra dichiarazione SELECT.
# select with WHERE
print("\n -- SELECT WITH WHERE --")
stmt = select([table_city]).where(table_city.columns.city_name == 'London')
print(stmt)
print(connection_live.execute(stmt).fetchall())

Nota: Il .where() viene utilizzato per testare una condizione che abbiamo usato come argomento. Potremmo anche usare .filter() metodo, che è migliore nel filtrare condizioni più complesse.
Ancora una volta, il .where parte è semplicemente concatenata alla nostra istruzione SELECT. Si noti che abbiamo messo la condizione tra parentesi. Qualunque condizione sia tra parentesi viene verificata nello stesso modo in cui verrebbe verificata nella parte WHERE di un'istruzione SELECT. La condizione di uguaglianza viene verificata utilizzando ==invece di =.
L'ultima cosa che proveremo con SELECT è unire due tabelle. Diamo prima un'occhiata al codice e al suo risultato.
# select with JOIN
print("\n -- SELECT WITH JOIN --")
table_country = Table('country', metadata, autoload = True, autoload_with = engine_live)
stmt = select([table_city.columns.city_name, table_country.columns.country_name]).select_from(table_city.join(table_country))
print(stmt)
print(connection_live.execute(stmt).fetchall())

Ci sono due parti importanti nella dichiarazione di cui sopra:
select([table_city.columns.city_name, table_country.columns.country_name])definisce quali colonne verranno restituite nel nostro risultato..select_from(table_city.join(table_country))definisce la condizione/tabella di unione. Si noti che non è stato necessario annotare la condizione di unione completa, comprese le chiavi. Questo perché SQLAlchemy "sa" come queste due tabelle vengono unite, poiché le chiavi primarie e le regole delle chiavi esterne vengono importate in background.
INSERIRE / AGGIORNA / ELIMINA
Questi sono i tre comandi DML rimanenti che tratteremo in questo articolo. Sebbene la loro struttura possa diventare molto complessa, questi comandi sono generalmente molto più semplici. Il codice utilizzato è presentato di seguito.
# INSERT
print("\n -- INSERT --")
stmt = table_country.insert().values(country_name='USA')
print(stmt)
connection_live.execute(stmt)
# check & print changes
stmt = select([table_country]).order_by(asc(table_country.columns.id))
print(connection_live.execute(stmt).fetchall())
# UPDATE
print("\n -- UPDATE --")
stmt = table_country.update().where(table_country.columns.country_name == 'USA').values(country_name = 'United States of America')
print(stmt)
connection_live.execute(stmt)
# check & print changes
stmt = select([table_country]).order_by(asc(table_country.columns.id))
print(connection_live.execute(stmt).fetchall())
# DELETE
print("\n -- DELETE --")
stmt = table_country.delete().where(table_country.columns.country_name == 'United States of America')
print(stmt)
connection_live.execute(stmt)
# check & print changes
stmt = select([table_country]).order_by(asc(table_country.columns.id))
print(connection_live.execute(stmt).fetchall())
Lo stesso schema viene utilizzato per tutte e tre le istruzioni:preparare l'istruzione, stamparla ed eseguirla e stampare il risultato dopo ogni istruzione in modo da poter vedere cosa è realmente accaduto nel database. Si noti ancora una volta che parti dell'istruzione sono state trattate come oggetti (.values(), .where()).

Utilizzeremo questa conoscenza nel prossimo articolo per creare un intero script ETL utilizzando SQLAlchemy.
Prossimo:SQLAlchemy nel processo ETL
Oggi abbiamo analizzato come impostare SQLAlchemy e come eseguire semplici comandi DML. Nel prossimo articolo, utilizzeremo questa conoscenza per scrivere il processo ETL completo utilizzando SQLAlchemy.
Puoi scaricare lo script completo, utilizzato in questo articolo qui.