Come amministratori di sistema e sviluppatori, trascorriamo molto tempo in un terminale. Quindi abbiamo portato ClusterControl sul terminale con il nostro strumento di interfaccia a riga di comando chiamato s9s. s9s fornisce un'interfaccia semplice per l'API ClusterControl RPC v2. Lo troverai molto utile quando lavori con implementazioni su larga scala, poiché la CLI consente di progettare funzionalità e flussi di lavoro più complessi.
Questo post sul blog mostra come utilizzare s9s per automatizzare la gestione di Galera Cluster per MySQL o MariaDB, oltre a una semplice configurazione di replica master-slave.
Configurazione
Puoi trovare le istruzioni di installazione per il tuo particolare sistema operativo nella documentazione. Ciò che è importante notare è che se ti capita di utilizzare gli ultimi s9s-tools, da GitHub, c'è un leggero cambiamento nel modo in cui crei un utente. Il seguente comando funzionerà correttamente:
s9s user --create --generate-key --controller="https://localhost:9501" dbaIn generale, sono necessari due passaggi se si desidera configurare la CLI in locale sull'host ClusterControl. Innanzitutto, devi creare un utente e quindi apportare alcune modifiche al file di configurazione:tutti i passaggi sono inclusi nella documentazione.
Distribuzione
Una volta che la CLI è stata configurata correttamente e ha accesso SSH agli host del database di destinazione, è possibile avviare il processo di distribuzione. Al momento della scrittura, puoi utilizzare la CLI per distribuire cluster MySQL, MariaDB e PostgreSQL. Iniziamo con un esempio di come distribuire Percona XtraDB Cluster 5.7. Per farlo è necessario un solo comando.
s9s cluster --create --cluster-type=galera --nodes="10.0.0.226;10.0.0.227;10.0.0.228" --vendor=percona --provider-version=5.7 --db-admin-passwd="pass" --os-user=root --cluster-name="PXC_Cluster_57" --waitL'ultima opzione "--wait" significa che il comando attenderà il completamento del lavoro, mostrando il suo avanzamento. Puoi saltarlo se lo desideri:in tal caso, il comando s9s tornerà immediatamente alla shell dopo aver registrato un nuovo lavoro in cmon. Questo va benissimo in quanto cmon è il processo che gestisce il lavoro stesso. Puoi sempre controllare lo stato di avanzamento di un lavoro separatamente, utilizzando:
example@sqldat.com:~# s9s job --list -l
--------------------------------------------------------------------------------------
Create Galera Cluster
Installing MySQL on 10.0.0.226 [██▊ ]
26.09%
Created : 2017-10-05 11:23:00 ID : 1 Status : RUNNING
Started : 2017-10-05 11:23:02 User : dba Host :
Ended : Group: users
--------------------------------------------------------------------------------------
Total: 1Diamo un'occhiata a un altro esempio. Questa volta creeremo un nuovo cluster, la replica MySQL:semplice coppia master - slave. Anche in questo caso basta un solo comando:
example@sqldat.com:~# s9s cluster --create --nodes="10.0.0.229?master;10.0.0.230?slave" --vendor=percona --cluster-type=mysqlreplication --provider-version=5.7 --os-user=root --wait
Create MySQL Replication Cluster
/ Job 6 FINISHED [██████████] 100% Cluster createdOra possiamo verificare che entrambi i cluster siano attivi e in esecuzione:
example@sqldat.com:~# s9s cluster --list --long
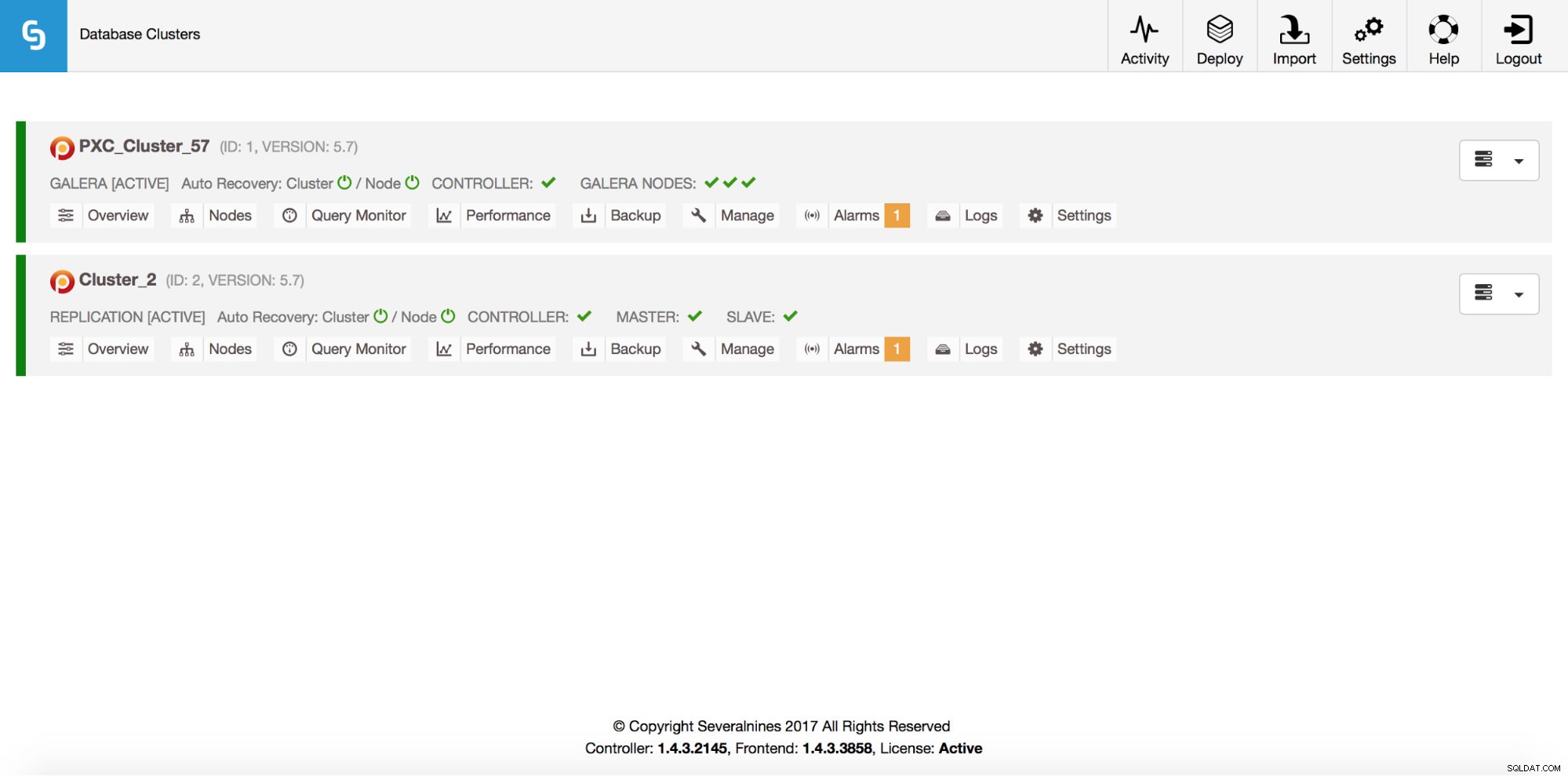
ID STATE TYPE OWNER GROUP NAME COMMENT
1 STARTED galera dba users PXC_Cluster_57 All nodes are operational.
2 STARTED replication dba users cluster_2 All nodes are operational.
Total: 2Naturalmente, tutto questo è visibile anche tramite la GUI:
Ora aggiungiamo un loadbalancer ProxySQL:
example@sqldat.com:~# s9s cluster --add-node --nodes="proxysql://10.0.0.226" --cluster-id=1
WARNING: admin/admin
WARNING: proxy-monitor/proxy-monitor
Job with ID 7 registered.Questa volta non abbiamo usato l'opzione "--wait", quindi, se vogliamo controllare i progressi, dobbiamo farlo da soli. Tieni presente che stiamo utilizzando un ID lavoro che è stato restituito dal comando precedente, quindi otterremo informazioni solo su questo particolare lavoro:
example@sqldat.com:~# s9s job --list --long --job-id=7
--------------------------------------------------------------------------------------
Add ProxySQL to Cluster
Waiting for ProxySQL [██████▋ ]
65.00%
Created : 2017-10-06 14:09:11 ID : 7 Status : RUNNING
Started : 2017-10-06 14:09:12 User : dba Host :
Ended : Group: users
--------------------------------------------------------------------------------------
Total: 7Ridimensionamento
I nodi possono essere aggiunti al nostro cluster Galera tramite un unico comando:
s9s cluster --add-node --nodes 10.0.0.229 --cluster-id 1
Job with ID 8 registered.
example@sqldat.com:~# s9s job --list --job-id=8
ID CID STATE OWNER GROUP CREATED RDY TITLE
8 1 FAILED dba users 14:15:52 0% Add Node to Cluster
Total: 8Qualcosa è andato storto. Possiamo verificare cosa è successo esattamente:
example@sqldat.com:~# s9s job --log --job-id=8
addNode: Verifying job parameters.
10.0.0.229:3306: Adding host to cluster.
10.0.0.229:3306: Testing SSH to host.
10.0.0.229:3306: Installing node.
10.0.0.229:3306: Setup new node (installSoftware = true).
10.0.0.229:3306: Detected a running mysqld server. It must be uninstalled first, or you can also add it to ClusterControl.Esatto, quell'IP è già utilizzato per il nostro server di replica. Avremmo dovuto usare un altro IP gratuito. Proviamo così:
example@sqldat.com:~# s9s cluster --add-node --nodes 10.0.0.231 --cluster-id 1
Job with ID 9 registered.
example@sqldat.com:~# s9s job --list --job-id=9
ID CID STATE OWNER GROUP CREATED RDY TITLE
9 1 FINISHED dba users 14:20:08 100% Add Node to Cluster
Total: 9Gestione
Supponiamo di voler eseguire un backup del nostro master di replica. Possiamo farlo dalla GUI, ma a volte potrebbe essere necessario integrarlo con script esterni. ClusterControl CLI sarebbe perfetto per questo caso. Controlliamo quali cluster abbiamo:
example@sqldat.com:~# s9s cluster --list --long
ID STATE TYPE OWNER GROUP NAME COMMENT
1 STARTED galera dba users PXC_Cluster_57 All nodes are operational.
2 STARTED replication dba users cluster_2 All nodes are operational.
Total: 2Quindi, controlliamo gli host nel nostro cluster di replica, con ID cluster 2:
example@sqldat.com:~# s9s nodes --list --long --cluster-id=2
STAT VERSION CID CLUSTER HOST PORT COMMENT
soM- 5.7.19-17-log 2 cluster_2 10.0.0.229 3306 Up and running
soS- 5.7.19-17-log 2 cluster_2 10.0.0.230 3306 Up and running
coC- 1.4.3.2145 2 cluster_2 10.0.2.15 9500 Up and runningCome possiamo vedere, esistono tre host di cui ClusterControl è a conoscenza:due sono host MySQL (10.0.0.229 e 10.0.0.230), il terzo è l'istanza ClusterControl stessa. Stampiamo solo gli host MySQL rilevanti:
example@sqldat.com:~# s9s nodes --list --long --cluster-id=2 10.0.0.2*
STAT VERSION CID CLUSTER HOST PORT COMMENT
soM- 5.7.19-17-log 2 cluster_2 10.0.0.229 3306 Up and running
soS- 5.7.19-17-log 2 cluster_2 10.0.0.230 3306 Up and running
Total: 3Nella colonna "STAT" puoi vedere alcuni caratteri lì. Per ulteriori informazioni, suggeriamo di consultare la pagina di manuale per s9s-nodes (man s9s-nodes). Qui ci limiteremo a riassumere i bit più importanti. Il primo carattere ci dice il tipo di nodo:"s" significa che è un normale nodo MySQL, "c" - controller ClusterControl. Il secondo carattere descrive lo stato del nodo:"o" ci dice che è online. Terzo personaggio:ruolo del nodo. Qui "M" descrive un master e "S" - uno slave mentre "C" sta per controller. Il quarto carattere finale ci dice se il nodo è in modalità di manutenzione. "-" significa che non c'è manutenzione programmata. Altrimenti vedremmo "M" qui. Quindi, da questi dati possiamo vedere che il nostro master è un host con IP:10.0.0.229. Facciamone un backup e memorizziamolo sul controller.
example@sqldat.com:~# s9s backup --create --nodes=10.0.0.229 --cluster-id=2 --backup-method=xtrabackupfull --wait
Create Backup
| Job 12 FINISHED [██████████] 100% Command okPossiamo quindi verificare se è stato effettivamente completato correttamente. Si prega di notare l'opzione "--backup-format" che consente di definire quali informazioni devono essere stampate:
example@sqldat.com:~# s9s backup --list --full --backup-format="Started: %B Completed: %E Method: %M Stored on: %S Size: %s %F\n" --cluster-id=2
Started: 15:29:11 Completed: 15:29:19 Method: xtrabackupfull Stored on: 10.0.0.229 Size: 543382 backup-full-2017-10-06_152911.xbstream.gz
Total 1Monitoraggio
Tutti i database devono essere monitorati. ClusterControl utilizza gli advisor per controllare alcune delle metriche sia su MySQL che sul sistema operativo. Quando una condizione è soddisfatta, viene inviata una notifica. ClusterControl fornisce anche un'ampia serie di grafici, sia in tempo reale che storici per la pianificazione post mortem o della capacità. A volte sarebbe bello avere accesso ad alcune di queste metriche senza dover passare attraverso la GUI. ClusterControl CLI lo rende possibile tramite il comando s9s-node. Le informazioni su come farlo possono essere trovate nella pagina di manuale di s9s-node. Mostreremo alcuni esempi di cosa puoi fare con la CLI.
Prima di tutto, diamo un'occhiata all'opzione "--node-format" per il comando "s9s node". Come puoi vedere, ci sono molte opzioni per stampare contenuti interessanti.
example@sqldat.com:~# s9s node --list --node-format "%N %T %R %c cores %u%% CPU utilization %fmG of free memory, %tMB/s of net TX+RX, %M\n" "10.0.0.2*"
10.0.0.226 galera none 1 cores 13.823200% CPU utilization 0.503227G of free memory, 0.061036MB/s of net TX+RX, Up and running
10.0.0.227 galera none 1 cores 13.033900% CPU utilization 0.543209G of free memory, 0.053596MB/s of net TX+RX, Up and running
10.0.0.228 galera none 1 cores 12.929100% CPU utilization 0.541988G of free memory, 0.052066MB/s of net TX+RX, Up and running
10.0.0.226 proxysql 1 cores 13.823200% CPU utilization 0.503227G of free memory, 0.061036MB/s of net TX+RX, Process 'proxysql' is running.
10.0.0.231 galera none 1 cores 13.104700% CPU utilization 0.544048G of free memory, 0.045713MB/s of net TX+RX, Up and running
10.0.0.229 mysql master 1 cores 11.107300% CPU utilization 0.575871G of free memory, 0.035830MB/s of net TX+RX, Up and running
10.0.0.230 mysql slave 1 cores 9.861590% CPU utilization 0.580315G of free memory, 0.035451MB/s of net TX+RX, Up and runningCon quanto mostrato qui, probabilmente puoi immaginare alcuni casi di automazione. Ad esempio, puoi guardare l'utilizzo della CPU dei nodi e se raggiunge una certa soglia, puoi eseguire un altro lavoro s9s per avviare un nuovo nodo nel cluster Galera. Puoi anche, ad esempio, monitorare l'utilizzo della memoria e inviare avvisi se supera una certa soglia.
La CLI può fare di più. Innanzitutto è possibile controllare i grafici dalla riga di comando. Ovviamente, quelli non sono così ricchi di funzionalità come i grafici nella GUI, ma a volte è sufficiente vedere un grafico per trovare uno schema inaspettato e decidere se vale la pena indagare ulteriormente.
example@sqldat.com:~# s9s node --stat --cluster-id=1 --begin="00:00" --end="14:00" --graph=load 10.0.0.231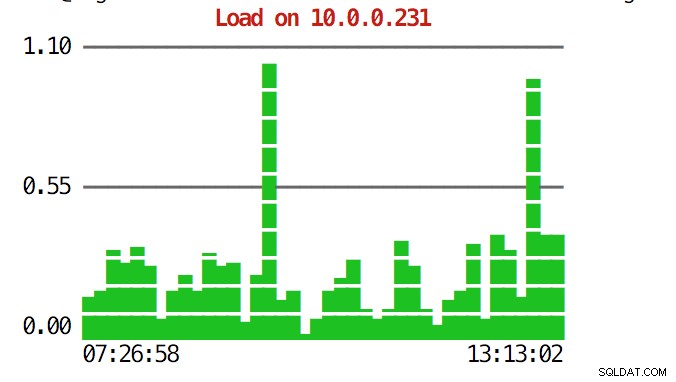
example@sqldat.com:~# s9s node --stat --cluster-id=1 --begin="00:00" --end="14:00" --graph=sqlqueries 10.0.0.231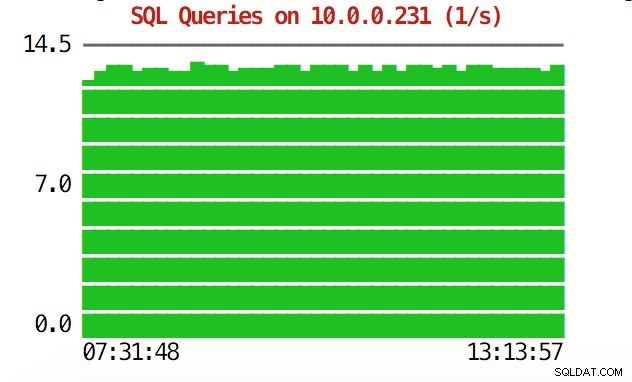
Durante le situazioni di emergenza, potresti voler controllare l'utilizzo delle risorse nel cluster. Puoi creare un output simile a un top che combina i dati di tutti i nodi del cluster:
example@sqldat.com:~# s9s process --top --cluster-id=1
PXC_Cluster_57 - 14:38:01 All nodes are operational.
4 hosts, 7 cores, 2.2 us, 3.1 sy, 94.7 id, 0.0 wa, 0.0 st,
GiB Mem : 2.9 total, 0.2 free, 0.9 used, 0.2 buffers, 1.6 cached
GiB Swap: 3 total, 0 used, 3 free,
PID USER HOST PR VIRT RES S %CPU %MEM COMMAND
8331 root 10.0.2.15 20 743748 40948 S 10.28 5.40 cmon
26479 root 10.0.0.226 20 278532 6448 S 2.49 0.85 accounts-daemon
5466 root 10.0.0.226 20 95372 7132 R 1.72 0.94 sshd
651 root 10.0.0.227 20 278416 6184 S 1.37 0.82 accounts-daemon
716 root 10.0.0.228 20 278304 6052 S 1.35 0.80 accounts-daemon
22447 n/a 10.0.0.226 20 2744444 148820 S 1.20 19.63 mysqld
975 mysql 10.0.0.228 20 2733624 115212 S 1.18 15.20 mysqld
13691 n/a 10.0.0.227 20 2734104 130568 S 1.11 17.22 mysqld
22994 root 10.0.2.15 20 30400 9312 S 0.93 1.23 s9s
9115 root 10.0.0.227 20 95368 7192 S 0.68 0.95 sshd
23768 root 10.0.0.228 20 95372 7160 S 0.67 0.94 sshd
15690 mysql 10.0.2.15 20 1102012 209056 S 0.67 27.58 mysqld
11471 root 10.0.0.226 20 95372 7392 S 0.17 0.98 sshd
22086 vagrant 10.0.2.15 20 95372 4960 S 0.17 0.65 sshd
7282 root 10.0.0.226 20 0 0 S 0.09 0.00 kworker/u4:2
9003 root 10.0.0.226 20 0 0 S 0.09 0.00 kworker/u4:1
1195 root 10.0.0.227 20 0 0 S 0.09 0.00 kworker/u4:0
27240 root 10.0.0.227 20 0 0 S 0.09 0.00 kworker/1:1
9933 root 10.0.0.227 20 0 0 S 0.09 0.00 kworker/u4:2
16181 root 10.0.0.228 20 0 0 S 0.08 0.00 kworker/u4:1
1744 root 10.0.0.228 20 0 0 S 0.08 0.00 kworker/1:1
28506 root 10.0.0.228 20 95372 7348 S 0.08 0.97 sshd
691 messagebus 10.0.0.228 20 42896 3872 S 0.08 0.51 dbus-daemon
11892 root 10.0.2.15 20 0 0 S 0.08 0.00 kworker/0:2
15609 root 10.0.2.15 20 403548 12908 S 0.08 1.70 apache2
256 root 10.0.2.15 20 0 0 S 0.08 0.00 jbd2/dm-0-8
840 root 10.0.2.15 20 316200 1308 S 0.08 0.17 VBoxService
14694 root 10.0.0.227 20 95368 7200 S 0.00 0.95 sshd
12724 n/a 10.0.0.227 20 4508 1780 S 0.00 0.23 mysqld_safe
10974 root 10.0.0.227 20 95368 7400 S 0.00 0.98 sshd
14712 root 10.0.0.227 20 95368 7384 S 0.00 0.97 sshd
16952 root 10.0.0.227 20 95368 7344 S 0.00 0.97 sshd
17025 root 10.0.0.227 20 95368 7100 S 0.00 0.94 sshd
27075 root 10.0.0.227 20 0 0 S 0.00 0.00 kworker/u4:1
27169 root 10.0.0.227 20 0 0 S 0.00 0.00 kworker/0:0
881 root 10.0.0.227 20 37976 760 S 0.00 0.10 rpc.mountd
100 root 10.0.0.227 0 0 0 S 0.00 0.00 deferwq
102 root 10.0.0.227 0 0 0 S 0.00 0.00 bioset
11876 root 10.0.0.227 20 9588 2572 S 0.00 0.34 bash
11852 root 10.0.0.227 20 95368 7352 S 0.00 0.97 sshd
104 root 10.0.0.227 0 0 0 S 0.00 0.00 kworker/1:1HQuando dai un'occhiata in alto, vedrai le statistiche di CPU e memoria aggregate nell'intero cluster.
example@sqldat.com:~# s9s process --top --cluster-id=1
PXC_Cluster_57 - 14:38:01 All nodes are operational.
4 hosts, 7 cores, 2.2 us, 3.1 sy, 94.7 id, 0.0 wa, 0.0 st,
GiB Mem : 2.9 total, 0.2 free, 0.9 used, 0.2 buffers, 1.6 cached
GiB Swap: 3 total, 0 used, 3 free,Di seguito puoi trovare l'elenco dei processi di tutti i nodi del cluster.
PID USER HOST PR VIRT RES S %CPU %MEM COMMAND
8331 root 10.0.2.15 20 743748 40948 S 10.28 5.40 cmon
26479 root 10.0.0.226 20 278532 6448 S 2.49 0.85 accounts-daemon
5466 root 10.0.0.226 20 95372 7132 R 1.72 0.94 sshd
651 root 10.0.0.227 20 278416 6184 S 1.37 0.82 accounts-daemon
716 root 10.0.0.228 20 278304 6052 S 1.35 0.80 accounts-daemon
22447 n/a 10.0.0.226 20 2744444 148820 S 1.20 19.63 mysqld
975 mysql 10.0.0.228 20 2733624 115212 S 1.18 15.20 mysqld
13691 n/a 10.0.0.227 20 2734104 130568 S 1.11 17.22 mysqldQuesto può essere estremamente utile se devi capire cosa sta causando il carico e quale nodo è quello più colpito.
Si spera che lo strumento CLI semplifichi l'integrazione di ClusterControl con script esterni e strumenti di orchestrazione dell'infrastruttura. Ci auguriamo che ti divertirai a utilizzare questo strumento e se hai commenti su come migliorarlo, non esitare a farcelo sapere.