Per utilizzare qualsiasi database in modo efficiente, è necessario disporre di informazioni dettagliate sulle prestazioni del database. Questo potrebbe non essere ovvio quando tutto sta andando bene, ma non appena qualcosa va storto, l'accesso alle informazioni può essere determinante per una diagnosi rapida e corretta del problema.
Tutti i database mettono a disposizione degli utenti alcuni dei loro dati di stato interni. In MySQL, puoi ottenere questi dati principalmente eseguendo 'SHOW STATUS' e 'SHOW GLOBAL STATUS', eseguendo 'SHOW ENGINE INNODB STATUS', controllando le tabelle information_schema e, nelle versioni più recenti, interrogando le tabelle performance_schema.

Questi metodi sono tutt'altro che convenienti nelle operazioni quotidiane, da qui la popolarità di diverse soluzioni di monitoraggio e trend. Strumenti come Nagios/Icinga sono progettati per monitorare host/servizi e avvisare quando un servizio non rientra in un intervallo accettabile. Altri strumenti come Cacti e Munin forniscono uno sguardo grafico alle informazioni sull'host/servizio e forniscono un contesto storico alle prestazioni e all'utilizzo. ClusterControl combina questi due tipi di monitoraggio, quindi esamineremo le informazioni che presenta e come dovremmo interpretarle.
Se stai utilizzando Galera Cluster (MySQL Galera Cluster by Codership o MariaDB Cluster o Percona XtraDB Cluster), potresti aver notato la seguente sezione nella scheda "Panoramica" di ClusterControl:
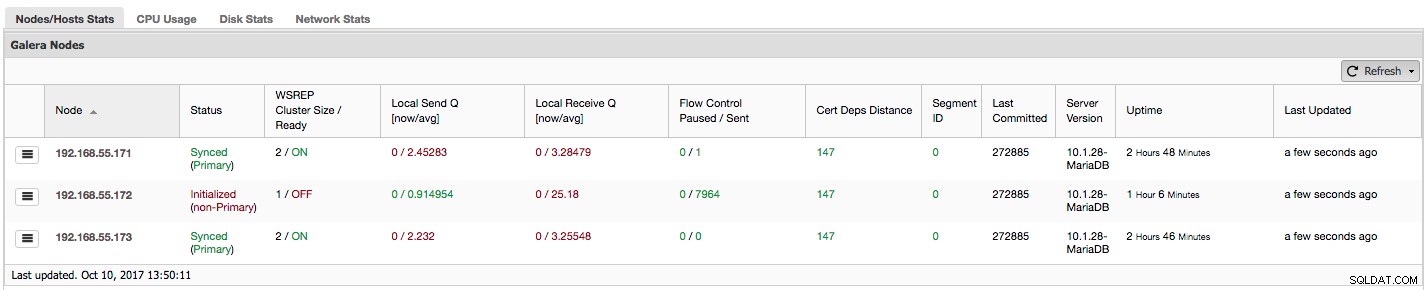
Vediamo, passo dopo passo, che tipo di dati abbiamo qui.
La prima colonna contiene l'elenco dei nodi con i loro indirizzi IP:non c'è molto altro da dire al riguardo.
La seconda colonna è più interessante:descrive lo stato del nodo (wsrep_local_state_comment stato). Un nodo può trovarsi in diversi stati:
- Inizializzato:il nodo è attivo e funzionante, ma non fa parte di un cluster. Può essere causato, ad esempio, da problemi di rete;
- Partecipazione:il nodo sta per unirsi al cluster e sta ricevendo o richiedendo un trasferimento di stato da uno degli altri nodi;
- Donatore/non sincronizzato - Il nodo funge da donatore per un altro nodo che si sta unendo al cluster;
- Unito:il nodo è unito al cluster ma è impegnato a recuperare il ritardo sui set di scrittura impegnati;
- Sincronizzato - Il nodo funziona normalmente.
Nella stessa colonna all'interno della parentesi è lo stato del cluster (wsrep_cluster_status stato). Può avere tre stati distinti:
- Principale - La comunicazione tra i nodi funziona ed è presente il quorum (la maggior parte dei nodi è disponibile)
- Non primario:il nodo faceva parte del cluster ma, per qualche motivo, ha perso il contatto con il resto del cluster. Di conseguenza, questo nodo è considerato inattivo e non accetterà query
- Disconnesso - Il nodo non ha potuto stabilire la comunicazione di gruppo.
"WSREP Cluster Size / Ready" ci informa sulle dimensioni del cluster viste dal nodo e se il nodo è pronto per accettare query. I componenti non primari creano un cluster con dimensione 1 e la disponibilità per wsrep è disattivata.
Diamo un'occhiata allo screenshot qui sopra e vediamo cosa ci dice su Galera. Possiamo vedere tre nodi. Due di loro (192.168.55.171 e 192.168.55.173) sono perfettamente a posto, sono entrambi "sincronizzati" e il cluster è nello stato "primario". Il cluster è attualmente composto da due nodi. Il nodo 192.168.55.172 è "inizializzato" e forma un componente "non primario". Significa che questo nodo ha perso la connessione con il cluster, molto probabilmente una sorta di problema di rete (in effetti, abbiamo usato iptables per bloccare un traffico verso questo nodo sia da 192.168.55.171 che da 192.168.55.173).
In questo momento dobbiamo fermarci un po' e descrivere come funziona internamente Galera Cluster. Non entreremo nei dettagli in quanto non rientra nell'ambito di questo post del blog, ma è necessaria una certa conoscenza per comprendere l'importanza dei dati presentati nelle prossime colonne.
Galera è un cluster multimaster "virtualmente" sincrono. Significa che dovresti aspettarti che i dati vengano trasferiti tra i nodi "virtualmente" allo stesso tempo (niente più fastidiosi problemi con gli slave in ritardo) e che puoi scrivere su qualsiasi nodo in un cluster (niente più fastidiosi problemi con la promozione di uno slave a master ). A tal fine, Galera utilizza i set di scrittura, un insieme atomico di modifiche replicate nel cluster. Un writeset può contenere diverse modifiche alla riga e informazioni aggiuntive necessarie come i dati relativi al blocco.
Una volta che un client emette COMMIT, ma prima che MySQL effettui effettivamente il commit, viene creato un writeset e inviato a tutti i nodi del cluster per la certificazione. Tutti i nodi controllano se è possibile eseguire o meno il commit delle modifiche (poiché le modifiche potrebbero interferire con altre scritture eseguite, nel frattempo, direttamente su un altro nodo). Se sì, i dati vengono effettivamente salvati da MySQL, in caso contrario viene eseguito il rollback.
Ciò che è importante ricordare è il fatto che i nodi, simili agli slave nella normale replica, possono funzionare in modo diverso:alcuni potrebbero avere un hardware migliore di altri, alcuni potrebbero essere più caricati di altri. Eppure Galera richiede loro di elaborare i set di scrittura in modo breve e veloce, al fine di mantenere la sincronizzazione "virtuale". Deve esistere un meccanismo in grado di limitare la replica e consentire ai nodi più lenti di stare al passo con il resto del cluster.
Diamo un'occhiata alle colonne "Invia Q locale [ora/media]" e "Ricezione locale Q [ora/media]". Ogni nodo dispone di una coda locale per l'invio e la ricezione di writeset. Consente di parallelizzare alcune delle scritture e dei dati di coda che non potrebbero essere elaborati contemporaneamente se il nodo non riesce a tenere il passo con il traffico. In SHOW GLOBAL STATUS possiamo trovare otto contatori che descrivono entrambe le code, quattro contatori per coda:
- wsrep_local_send_queue - stato attuale della coda di invio
- wsrep_local_send_queue_min - minimo da FLUSH STATUS
- wsrep_local_send_queue_max - massimo da FLUSH STATUS
- wsrep_local_send_queue_avg - media da FLUSH STATUS
- wsrep_local_recv_queue - stato attuale della coda di ricezione
- wsrep_local_recv_queue_min - minimo da FLUSH STATUS
- wsrep_local_recv_queue_max - massimo da FLUSH STATUS
- wsrep_local_recv_queue_avg - media da FLUSH STATUS
Le metriche di cui sopra sono unificate tra i nodi in ClusterControl -> Prestazioni -> Stato database:
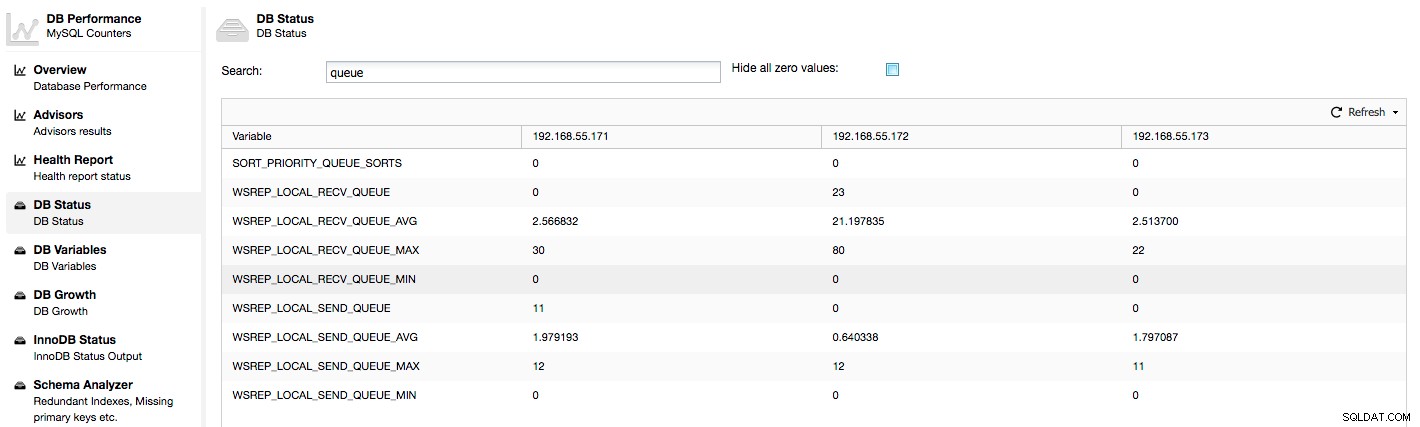
ClusterControl visualizza i contatori "adesso" e "medio", in quanto sono i più significativi come un unico numero (è anche possibile creare grafici personalizzati basati su variabili che descrivono lo stato corrente delle code). Quando vediamo che una delle code è in aumento, significa che il nodo non può tenere il passo con la replica e gli altri nodi dovranno rallentare per consentirgli di recuperare il ritardo. Ti consigliamo di esaminare un carico di lavoro di quel dato nodo:controlla l'elenco dei processi per alcune query a esecuzione prolungata, controlla le statistiche del sistema operativo come l'utilizzo della CPU e il carico di lavoro di I/O. Forse è anche possibile ridistribuire parte del traffico da quel nodo al resto del cluster.
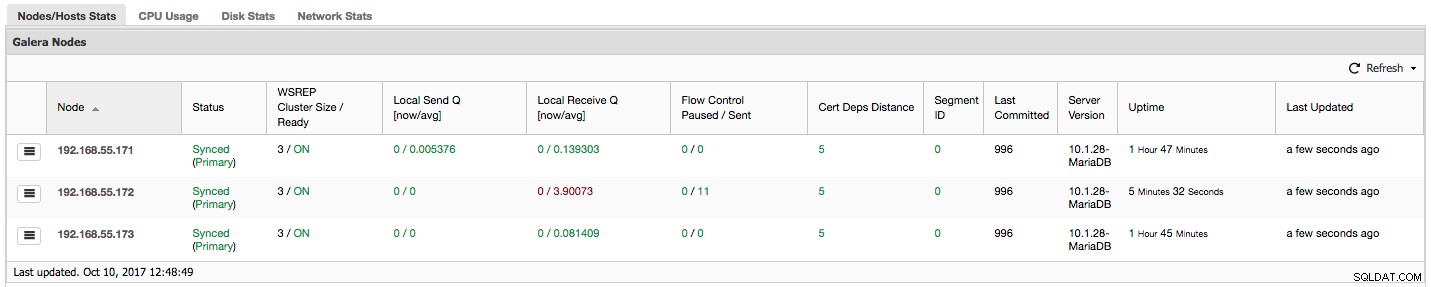
"Controllo flusso in pausa" mostra informazioni sulla percentuale di tempo in cui un determinato nodo ha dovuto sospendere la replica a causa di un carico troppo elevato. Quando un nodo non riesce a tenere il passo con il carico di lavoro, invia pacchetti di controllo del flusso ad altri nodi, informandoli che dovrebbero rallentare l'invio di set di scritture. Nel nostro screenshot, abbiamo il valore di '0.30' per il nodo 192.168.55.172. Ciò significa che quasi il 30% delle volte questo nodo ha dovuto sospendere la replica perché non è stato in grado di tenere il passo con il tasso di certificazione del set di scrittura richiesto da altri nodi (o più semplicemente, troppe scritture lo hanno colpito!). Come possiamo vedere, "Local Receive Q [avg]" ci indica anche questo fatto.
La colonna successiva, "Controllo flusso inviato", fornisce informazioni su quanti pacchetti di controllo flusso un determinato nodo ha inviato al cluster. Ancora una volta, vediamo che è il nodo 192.168.55.172 che sta rallentando il cluster.
Cosa possiamo fare con queste informazioni? Per lo più, dovremmo indagare su cosa sta succedendo nel nodo lento. Controlla l'utilizzo della CPU, controlla le prestazioni di I/O e le statistiche di rete. Questo primo passaggio aiuta a valutare che tipo di problema stiamo affrontando.
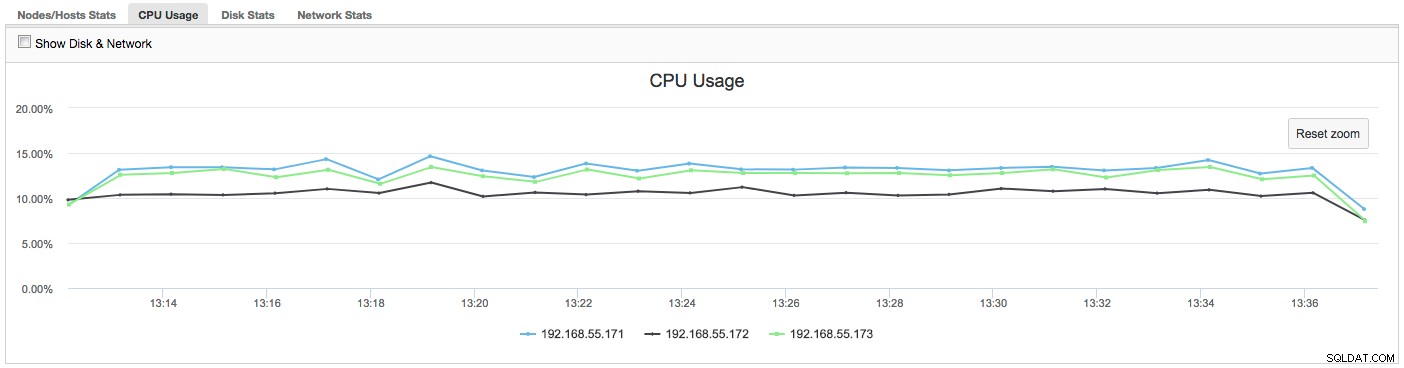
In questo caso, una volta che si passa alla scheda Utilizzo CPU, diventa chiaro che l'ampio utilizzo della CPU sta causando i nostri problemi. Il passo successivo sarebbe identificare il colpevole esaminando PROCESSLIST (Query Monitor -> Esecuzione di query -> filtro per 192.168.55.172) per verificare la presenza di query offensive:
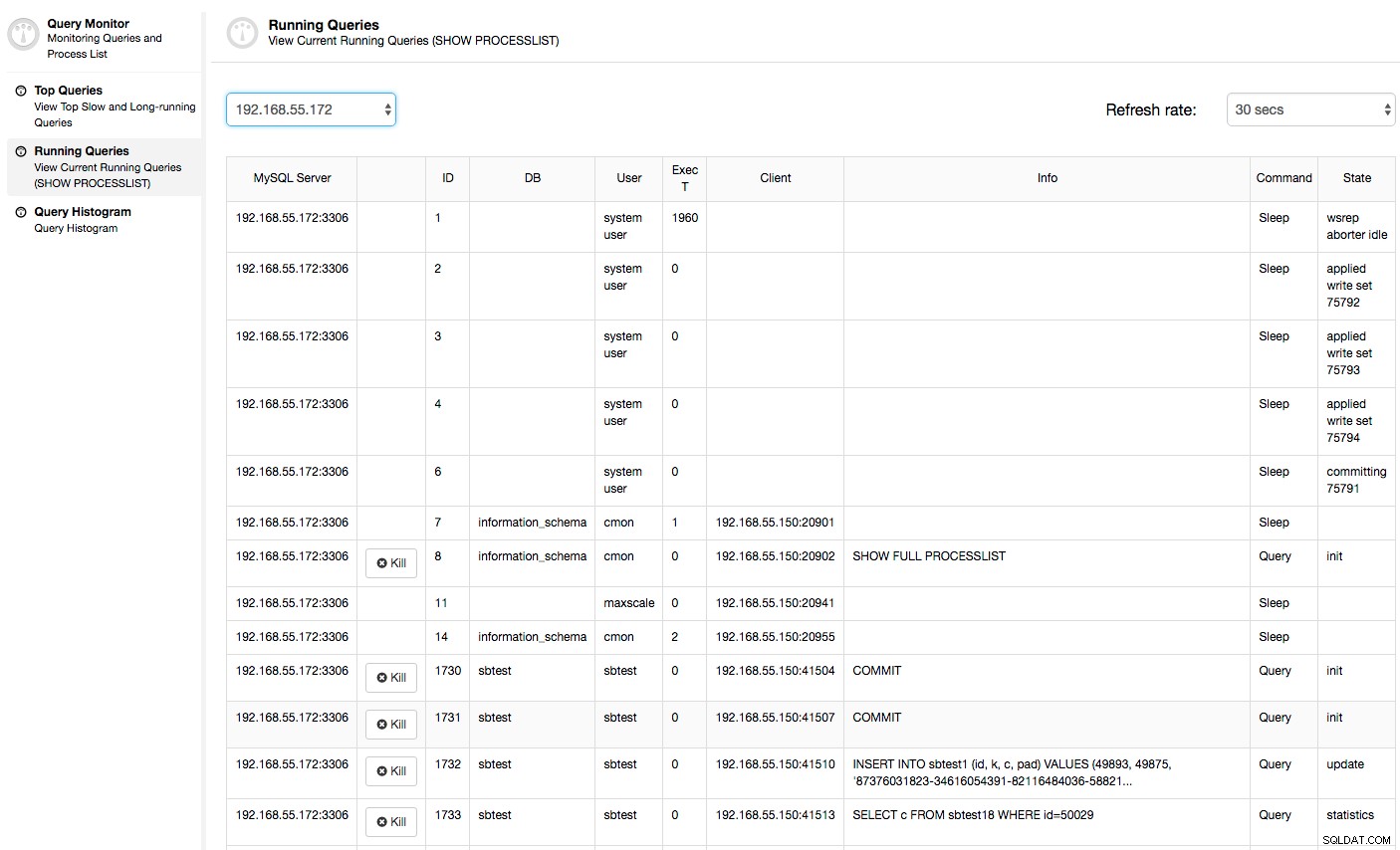
Oppure, controlla i processi sul nodo dal lato del sistema operativo (Nodi -> 192.168.55.172 -> In alto) per vedere se il carico non è causato da qualcosa al di fuori di Galera/MySQL.
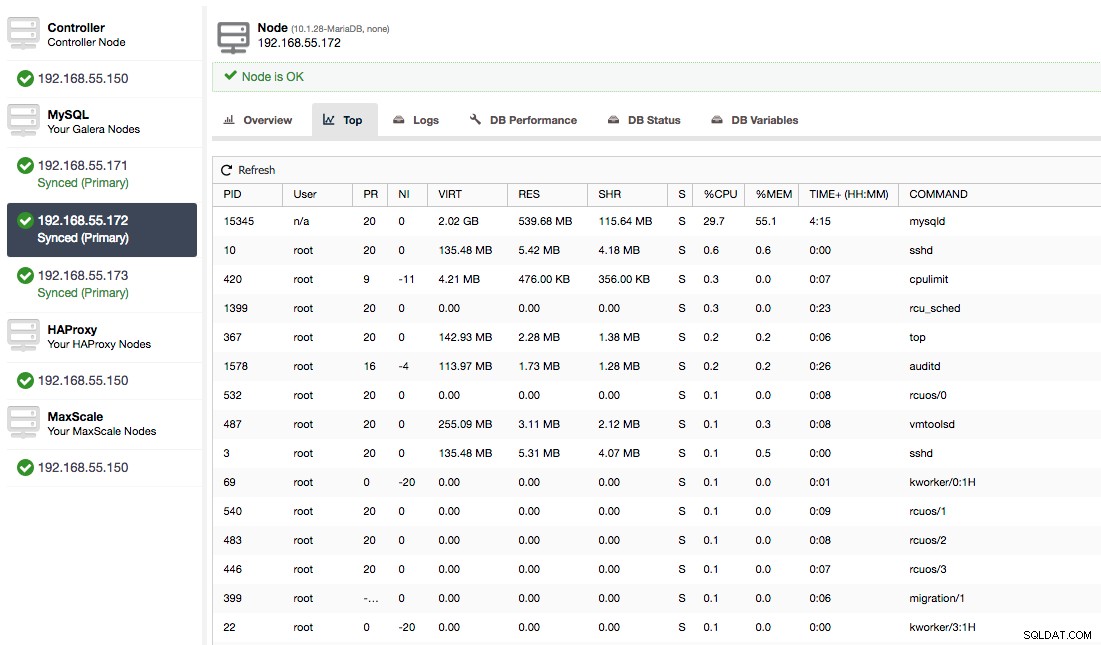
In questo caso, abbiamo eseguito il comando mysqld tramite cpulimit, per simulare un utilizzo lento della CPU specifico per il processo mysqld limitandolo al 30% del 400% della CPU disponibile (il server ha 4 core).
La colonna "Cert Deps Distance" fornisce informazioni su quanti writeset, in media, possono essere applicati in parallelo. I set di scrittura possono, a volte, essere eseguiti contemporaneamente - Galera ne trae vantaggio utilizzando più wsrep_slave_threads per applicare i set di scrittura. Questa colonna ti dà un'idea di quanti thread slave potresti usare sul tuo carico di lavoro. Vale la pena notare che non ha senso impostare wsrep_slave_threads variabile a valori superiori a quelli visualizzati in questa colonna o in wsrep_cert_deps_distance variabile di stato, su cui si basa la colonna "Cert Deps Distance". Un'altra nota importante:non ha senso nemmeno impostare wsrep_slave_threads variabile a più del numero di core della tua CPU.
"ID segmento":questa colonna richiederà ulteriori spiegazioni. I segmenti sono una nuova funzionalità aggiunta in Galera 3.0. Prima di questa versione, i set di scrittura venivano scambiati tra tutti i nodi. Supponiamo di avere due datacenter:
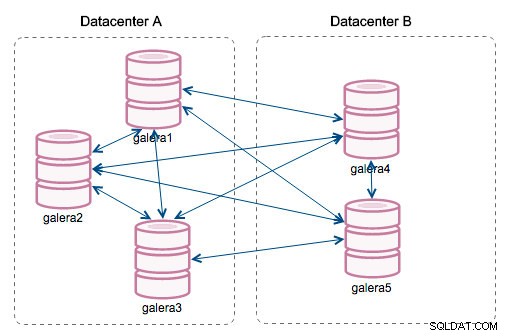
Questo tipo di chat funziona bene sulle reti locali, ma la WAN è un'altra storia:la certificazione rallenta a causa della maggiore latenza, vengono generati costi aggiuntivi a causa della larghezza di banda di rete utilizzata per trasferire i set di scrittura tra ogni membro del cluster.
Con l'introduzione dei "Segmenti", le cose sono cambiate. Puoi assegnare un nodo a un segmento modificando wsrep_provider_options variabile e aggiungendo "gmcast.segment=x" (0, 1, 2). I nodi con lo stesso numero di segmento vengono trattati come se fossero nello stesso datacenter, connesso dalla rete locale. Il nostro grafico diventa quindi diverso:
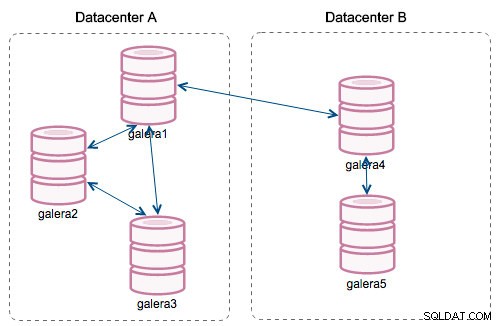
La differenza principale è che non è più la comunicazione da tutti a tutti. All'interno di ogni segmento, sì, è sempre lo stesso meccanismo ma entrambi i segmenti comunicano solo attraverso un'unica connessione tra due nodi scelti. In caso di inattività, questa connessione eseguirà automaticamente il failover. Di conseguenza, otteniamo meno chiacchiere sulla rete e un minore utilizzo della larghezza di banda tra i data center remoti. Quindi, in pratica, la colonna "Segment ID" ci dice a quale segmento è assegnato un nodo.
La colonna "Last Committed" fornisce informazioni sul numero di sequenza del writeset eseguito l'ultima volta su un determinato nodo. Può essere utile per determinare quale nodo è il più aggiornato se è necessario eseguire il bootstrap del cluster.
Il resto delle colonne è autoesplicativo:versione del server, tempo di attività di un nodo e quando lo stato è stato aggiornato.
Come puoi vedere, la sezione "Nodi Galera" delle "Statistiche nodi/host" nella scheda "Panoramica" ti offre una buona comprensione dello stato di salute del cluster:se forma un componente "Primario", quanti nodi sono integri , ci sono problemi di prestazioni con alcuni nodi e, in caso affermativo, quale nodo sta rallentando il cluster.
Questo set di dati è molto utile quando utilizzi il tuo cluster Galera, quindi si spera che non voli più alla cieca :-)