Nella prima parte di questa serie, ho introdotto la terminologia di base sulla registrazione, quindi ti consiglio di leggerla prima di continuare con questo post. Tutto il resto che tratterò nella serie richiede la conoscenza di parte dell'architettura del registro delle transazioni, quindi è ciò di cui parlerò questa volta. Anche se non seguirai la serie, vale la pena conoscere alcuni dei concetti che spiegherò di seguito per le attività quotidiane che i DBA gestiscono in produzione.
Gerarchia strutturale
Il registro delle transazioni è organizzato internamente utilizzando una gerarchia a tre livelli, come mostrato nella figura 1 di seguito.
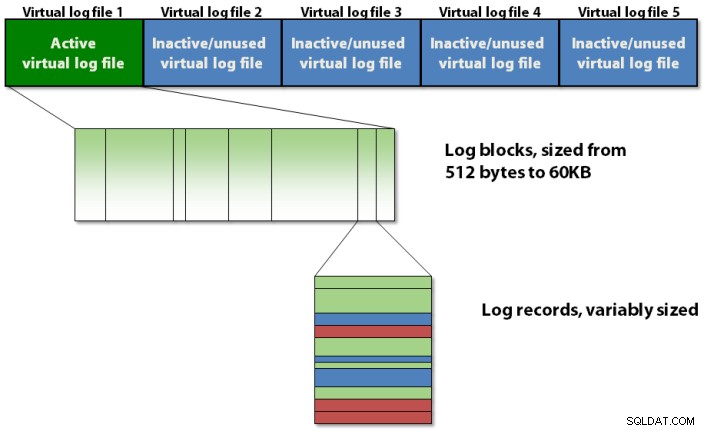 Figura 1:La gerarchia strutturale a tre livelli del log delle transazioni
Figura 1:La gerarchia strutturale a tre livelli del log delle transazioni
Il registro delle transazioni contiene file di registro virtuali, che contengono blocchi di registro, che memorizzano i record di registro effettivi.
File di registro virtuali
Il registro delle transazioni è suddiviso in sezioni denominate file di registro virtuali , comunemente chiamati semplicemente VLF . Questo viene fatto per semplificare la gestione delle operazioni nel registro delle transazioni per il gestore dei registri in SQL ServerSQL Server. Non puoi specificare quanti VLF vengono creati da SQL Server quando il database viene creato per la prima volta o il file di registro cresce automaticamente, ma puoi influenzarlo. L'algoritmo per il numero di VLF creati è il seguente:
- Le dimensioni del file di registro sono inferiori a 64 MB:crea 4 VLF, ciascuno con una dimensione di circa 16 MB
- Dimensione del file di registro da 64 MB a 1 GB:crea 8 VLF, ciascuno circa 1/8 della dimensione totale
- Dimensione del file di registro maggiore di 1 GB:crea 16 VLF, ciascuno circa 1/16 della dimensione totale
Prima di SQL Server 2014, quando il file di registro aumenta automaticamente, il numero di nuovi VLF aggiunti alla fine del file di registro è determinato dall'algoritmo sopra, in base alla dimensione di aumento automatico. Tuttavia, utilizzando questo algoritmo, se la dimensione della crescita automatica è piccola e il file di registro subisce molte espansioni automatiche, può portare a un numero molto elevato di piccoli VLF (chiamati frammentazione VLF ) che può essere un grosso problema di prestazioni per alcune operazioni (vedi qui).
A causa di questo problema, in SQL Server 2014 l'algoritmo è stato modificato per la crescita automatica del file di registro. Se la dimensione dell'aumento automatico è inferiore a 1/8 della dimensione totale del file di registro, viene creato solo un nuovo VLF, altrimenti viene utilizzato il vecchio algoritmo. Ciò riduce drasticamente il numero di VLF per un file di registro che ha subito una grande quantità di crescita automatica. Ho spiegato un esempio della differenza in questo post del blog.
Ogni VLF ha un numero di sequenza che lo identifica in modo univoco e viene utilizzato in una varietà di luoghi, che spiegherò di seguito e nei post futuri. Penseresti che i numeri di sequenza inizino da 1 per un database nuovo di zecca, ma non è così.
In un'istanza di SQL Server 2019, ho creato un nuovo database, senza specificare le dimensioni dei file, quindi ho verificato i VLF utilizzando il codice seguente:
CREATE DATABASE NewDB;
GO
SELECT
[file_id],
[vlf_begin_offset],
[vlf_size_mb],
[vlf_sequence_number]
FROM
sys.dm_db_log_info (DB_ID (N'NewDB'));
Nota il sys.dm_db_log_info DMV è stato aggiunto in SQL Server 2016 SP2. Prima di allora (e oggi, perché esiste ancora) puoi usare il DBCC LOGINFO non documentato comando, ma non puoi dargli un elenco di selezione:esegui semplicemente DBCC LOGINFO(N'NewDB'); e i numeri di sequenza VLF sono nel FSeqNo colonna del set di risultati.
Ad ogni modo, i risultati della query su sys.dm_db_log_info erano:
file_id vlf_begin_offset vlf_size_mb vlf_sequence_number ------- ---------------- ----------- ------------------- 2 8192 1.93 37 2 2039808 1.93 0 2 4071424 1.93 0 2 6103040 2.17 0
Si noti che il primo VLF inizia con un offset di 8.192 byte nel file di registro. Questo perché tutti i file di database, incluso il registro delle transazioni, hanno una pagina di intestazione del file che occupa i primi 8 KB e memorizza vari metadati sul file.
Allora perché SQL Server sceglie 37 e non 1 per il primo numero di sequenza VLF? Trova il numero di sequenza VLF più alto nel model database e quindi, per qualsiasi nuovo database, il primo VLF del log delle transazioni utilizza quel numero più 1 come numero di sequenza. Non so perché questo algoritmo sia stato scelto nella notte dei tempi, ma è così da almeno SQL Server 7.0.
Per dimostrarlo, ho eseguito questo codice:
SELECT
MAX ([vlf_sequence_number]) AS [Max_VLF_SeqNo]
FROM
sys.dm_db_log_info (DB_ID (N'model')); E i risultati sono stati:
Max_VLF_SeqNo -------------------- 36
Quindi il gioco è fatto.
C'è altro da discutere sui VLF e su come vengono utilizzati, ma per ora è sufficiente sapere che ogni VLF ha un numero di sequenza, che aumenta di uno per ogni VLF.
Blocchi registro
Ogni VLF contiene una piccola intestazione di metadati e il resto dello spazio è riempito con blocchi di registro. Ogni blocco di registro inizia a 512 byte e crescerà con incrementi di 512 byte fino a una dimensione massima di 60 KB, a quel punto deve essere scritto su disco. Un blocco di log potrebbe essere scritto su disco prima che raggiunga la sua dimensione massima se si verifica una delle seguenti condizioni:
- Una transazione viene eseguita e la durabilità ritardata non viene utilizzata per questa transazione, quindi il blocco di registro deve essere scritto su disco per rendere la transazione durevole
- La durabilità ritardata è in uso e l'attività timer di 1 ms "svuota il blocco di registro corrente su disco" in background viene attivata
- Una pagina di un file di dati viene scritta su disco da un checkpoint o dal lazy writer e sono presenti uno o più record di registro nel blocco di registro corrente che influiscono sulla pagina che sta per essere scritta (ricorda che la registrazione write-ahead deve essere garantito)
Puoi considerare un blocco di registro come qualcosa come una pagina di dimensioni variabili che memorizza i record di registro nell'ordine in cui sono stati creati dalle transazioni che modificano il database. Non esiste un blocco di registro per ogni transazione; i record di registro per più transazioni simultanee possono essere mescolati in un blocco di registro. Potresti pensare che ciò comporti difficoltà per le operazioni che devono trovare tutti i record di registro per una singola transazione, ma non è così, come spiegherò quando parlerò di come funzionano i rollback delle transazioni in un post successivo.
Inoltre, quando un blocco di registro viene scritto su disco, è del tutto possibile che contenga record di registro di transazioni non vincolate. Anche questo non è un problema a causa del modo in cui funziona il ripristino in caso di arresto anomalo, che è un buon paio di post nel futuro della serie.
Numeri di sequenza del registro
I blocchi di log hanno un ID all'interno di un VLF, che inizia da 1 e aumenta di 1 per ogni nuovo blocco di log nel VLF. I record di registro hanno anche un ID all'interno di un blocco di registro, che inizia da 1 e aumenta di 1 per ogni nuovo record di registro nel blocco di registro. Quindi, tutti e tre gli elementi nella gerarchia strutturale del log delle transazioni hanno un ID e sono riuniti in un identificatore tripartito chiamato numero di sequenza del log , più comunemente indicato semplicemente come LSN .
Un LSN è definito come <VLF sequence number>:<log block ID>:<log record ID> (4 byte:4 byte:2 byte) e identifica univocamente un singolo record di registro. È un identificatore in continua crescita, perché i numeri di sequenza VLF aumentano per sempre.
Lavoro a terra fatto!
Sebbene i VLF siano importanti da conoscere, a mio avviso l'LSN è il concetto più importante da comprendere sull'implementazione della registrazione in SQL Server poiché gli LSN sono la pietra angolare su cui sono costruiti il rollback delle transazioni e il ripristino da crash e gli LSN riappariranno ancora e ancora quando Avanzo attraverso la serie. Nel prossimo post tratterò il troncamento del registro e la natura circolare del registro delle transazioni, che ha tutto a che fare con i VLF e come vengono riutilizzati.