Python è molto popolare in questi giorni. Poiché Python è un linguaggio di programmazione generico, può essere utilizzato anche per eseguire il processo Extract, Transform, Load (ETL). Sono disponibili diversi moduli ETL, ma oggi continueremo con la combinazione di Python e MySQL. Useremo Python per invocare stored procedure e preparare ed eseguire istruzioni SQL.
Useremo due approcci simili ma diversi. In primo luogo, invocheremo le procedure memorizzate che faranno l'intero lavoro, quindi analizzeremo come potremmo eseguire lo stesso processo senza procedure memorizzate utilizzando il codice MySQL in Python.
Pronto? Prima di approfondire, diamo un'occhiata al modello di dati, o modelli di dati, poiché in questo articolo ce ne sono due.
I modelli di dati
Avremo bisogno di due modelli di dati, uno per archiviare i nostri dati operativi e l'altro per archiviare i nostri dati di reporting.
Il primo modello è mostrato nella foto sopra. Questo modello viene utilizzato per archiviare i dati operativi (in tempo reale) per un'azienda basata su abbonamento. Per ulteriori informazioni su questo modello, dai un'occhiata al nostro articolo precedente, Creazione di un DWH, parte prima:un modello di dati aziendali in abbonamento.
Separare i dati operativi e di reporting è generalmente una decisione molto saggia. Per ottenere tale separazione, dovremo creare un data warehouse (DWH). L'abbiamo già fatto; puoi vedere il modello nella foto sopra. Questo modello è anche descritto in dettaglio nel post Creazione di un DWH, parte seconda:un modello di dati aziendali in abbonamento.
Infine, dobbiamo estrarre i dati dal database live, trasformarli e caricarli nel nostro DWH. Lo abbiamo già fatto utilizzando le stored procedure SQL. Puoi trovare una descrizione di ciò che vogliamo ottenere insieme ad alcuni esempi di codice in Creazione di un data warehouse, parte 3:un modello di dati aziendali in abbonamento.
Se hai bisogno di ulteriori informazioni sui DWH, ti consigliamo di leggere questi articoli:
- Lo schema a stella
- Lo schema del fiocco di neve
- Schema a stella vs. Schema a fiocco di neve.
Il nostro compito oggi è sostituire le stored procedure SQL con codice Python. Siamo pronti per creare un po' di magia Python. Iniziamo con l'utilizzo solo delle stored procedure in Python.
Metodo 1:ETL utilizzando le stored procedure
Prima di iniziare a descrivere il processo, è importante ricordare che abbiamo due database sul nostro server.
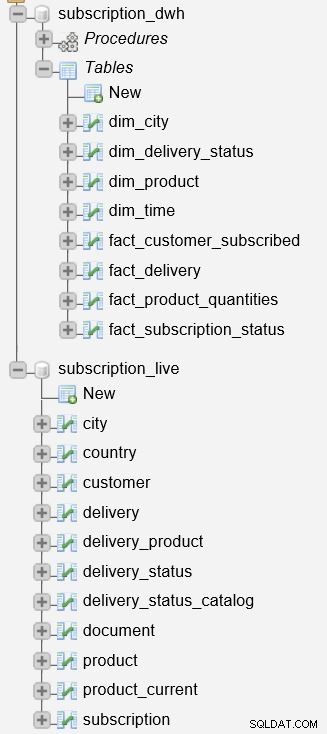
Il subscription_live il database viene utilizzato per memorizzare dati transazionali/in tempo reale, mentre il subscription_dwh è il nostro database di reporting (DWH).
Abbiamo già descritto le procedure memorizzate utilizzate per aggiornare le tabelle delle dimensioni e dei fatti. Leggeranno i dati da subscription_live database, combinalo con i dati nel subscription_dwh database e inserire nuovi dati nel subscription_dwh Banca dati. Queste due procedure sono:
p_update_dimensions– Aggiorna le tabelle delle dimensionidim_timeedim_city.p_update_facts– Aggiorna due tabelle dei fatti,fact_customer_subscribedefact_subscription_status.
Se vuoi vedere il codice completo per queste procedure, leggi Creazione di un Data Warehouse, Parte 3:Un modello di dati aziendali in abbonamento.
Ora siamo pronti per scrivere un semplice script Python che si collegherà al server ed eseguirà il processo ETL. Diamo prima un'occhiata all'intero script (etl_procedures.py ). Quindi spiegheremo le parti più importanti.
# import MySQL connector import mysql.connector # connect to server connection = mysql.connector.connect(user='', password=' ', host='127.0.0.1') print('Connected to database.') cursor = connection.cursor() # I update dimensions cursor.callproc('subscription_dwh.p_update_dimensions') print('Dimension tables updated.') # II update facts cursor.callproc('subscription_dwh.p_update_facts') print('Fact tables updated.') # commit & close connection cursor.close() connection.commit() connection.close() print('Disconnected from database.')
etl_procedures.py
Importazione di moduli e connessione al database
Python utilizza i moduli per memorizzare definizioni e istruzioni. Potresti usare un modulo esistente o scriverne uno tuo. L'uso dei moduli esistenti ti semplificherà la vita perché stai utilizzando codice pre-scritto, ma anche scrivere il tuo modulo è molto utile. Quando esci dall'interprete Python e lo esegui di nuovo, perderai le funzioni e le variabili che hai precedentemente definito. Ovviamente, non vuoi digitare lo stesso codice più e più volte. Per evitarlo, puoi memorizzare le tue definizioni in un modulo e importarlo in Python.
Torna a etl_procedures.py . Nel nostro programma, iniziamo con l'importazione di MySQL Connector:
# import MySQL connector import mysql.connector
MySQL Connector per Python viene utilizzato come driver standard che si connette a un server/database MySQL. Dovrai scaricarlo e installarlo se non l'hai fatto in precedenza. Oltre a connettersi al database, offre una serie di metodi e proprietà per lavorare con un database. Ne useremo alcuni, ma puoi controllare la documentazione completa qui.
Successivamente, dovremo connetterci al nostro database:
# connect to server connection = mysql.connector.connect(user='', password=' ', host='127.0.0.1') print('Connected to database.') cursor = connection.cursor()
La prima riga si collegherà a un server (in questo caso mi sto connettendo al mio computer locale) utilizzando le tue credenziali (sostituisci
connection = mysql.connector.connect(user='', password=' ', host='127.0.0.1', database=' ')
Mi sono connesso intenzionalmente solo a un server e non a un database specifico perché utilizzerò due database situati sullo stesso server.
Il comando successivo:print – è qui solo una notifica che ci siamo collegati con successo. Sebbene non abbia alcun significato di programmazione, potrebbe essere utilizzato per eseguire il debug del codice se qualcosa è andato storto nello script.
L'ultima riga in questa parte è:
cursor =connection.cursor()
Cursors are the handler structure used to work with the data. We’ll use them for retrieving data from the database (SELECT), but also to modify the data (INSERT, UPDATE, DELETE). Before using a cursor, we need to create it. And that is what this line does.
Procedure di chiamata
La parte precedente era generale e poteva essere utilizzata per altre attività relative al database. La parte seguente del codice è specifica per ETL:chiamare le nostre stored procedure con il cursor.callproc comando. Si presenta così:
# 1. update dimensions
cursor.callproc('subscription_dwh.p_update_dimensions')
print('Dimension tables updated.')
# 2. update facts
cursor.callproc('subscription_dwh.p_update_facts')
print('Fact tables updated.')
Le procedure di chiamata sono praticamente autoesplicative. Dopo ogni chiamata è stato aggiunto un comando di stampa. Ancora una volta, questo ci dà solo una notifica che tutto è andato bene.
Impegna e chiudi
La parte finale dello script conferma le modifiche al database e chiude tutti gli oggetti utilizzati:
# commit & close connection
cursor.close()
connection.commit()
connection.close()
print('Disconnected from database.')
Le procedure di chiamata sono praticamente autoesplicative. Dopo ogni chiamata è stato aggiunto un comando di stampa. Ancora una volta, questo ci dà solo una notifica che tutto è andato bene.
Impegnarsi è essenziale qui; senza di esso, non ci saranno modifiche al database, anche se hai chiamato una procedura o eseguito un'istruzione SQL.
Esecuzione dello script
L'ultima cosa che dobbiamo fare è eseguire il nostro script. Utilizzeremo i seguenti comandi nella shell Python per raggiungere questo obiettivo:
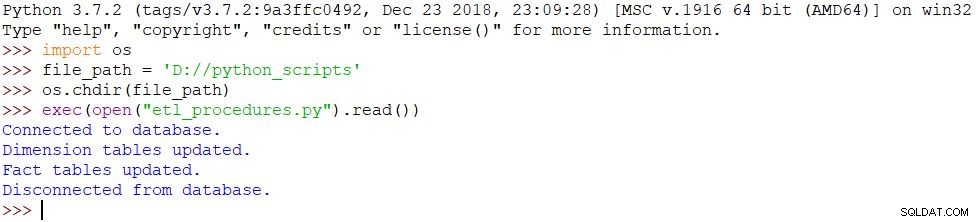
import osfile_path ='D://python_scripts'os.chdir(file_path)exec(open("etl_procedures.py").read())Lo script viene eseguito e tutte le modifiche vengono apportate nel database di conseguenza. Il risultato può essere visto nell'immagine qui sotto.
Metodo 2:ETL utilizzando Python e MySQL
L'approccio presentato sopra non differisce molto dall'approccio di chiamare le stored procedure direttamente in MySQL. L'unica differenza è che ora abbiamo uno script che farà l'intero lavoro per noi.
Potremmo usare un altro approccio:mettere tutto all'interno dello script Python. Includeremo le istruzioni Python, ma prepareremo anche le query SQL e le eseguiremo sul database. Il database di origine (live) e il database di destinazione (DWH) sono gli stessi dell'esempio con le stored procedure.
Prima di approfondire, diamo un'occhiata allo script completo (etl_queries.py ):
from datetime import date # import MySQL connector import mysql.connector # connect to server connection = mysql.connector.connect(user='', password=' ', host='127.0.0.1') print('Connected to database.') # 1. update dimensions # 1.1 update dim_time # date - yesterday yesterday = date.fromordinal(date.today().toordinal()-1) yesterday_str = '"' + str(yesterday) + '"' # test if date is already in the table cursor = connection.cursor() query = ( "SELECT COUNT(*) " "FROM subscription_dwh.dim_time " "WHERE time_date = " + yesterday_str) cursor.execute(query) result = cursor.fetchall() yesterday_subscription_count = int(result[0][0]) if yesterday_subscription_count == 0: yesterday_year = 'YEAR("' + str(yesterday) + '")' yesterday_month = 'MONTH("' + str(yesterday) + '")' yesterday_week = 'WEEK("' + str(yesterday) + '")' yesterday_weekday = 'WEEKDAY("' + str(yesterday) + '")' query = ( "INSERT INTO subscription_dwh.`dim_time`(`time_date`, `time_year`, `time_month`, `time_week`, `time_weekday`, `ts`) " " VALUES (" + yesterday_str + ", " + yesterday_year + ", " + yesterday_month + ", " + yesterday_week + ", " + yesterday_weekday + ", Now())") cursor.execute(query) # 1.2 update dim_city query = ( "INSERT INTO subscription_dwh.`dim_city`(`city_name`, `postal_code`, `country_name`, `ts`) " "SELECT city_live.city_name, city_live.postal_code, country_live.country_name, Now() " "FROM subscription_live.city city_live " "INNER JOIN subscription_live.country country_live ON city_live.country_id = country_live.id " "LEFT JOIN subscription_dwh.dim_city city_dwh ON city_live.city_name = city_dwh.city_name AND city_live.postal_code = city_dwh.postal_code AND country_live.country_name = city_dwh.country_name " "WHERE city_dwh.id IS NULL") cursor.execute(query) print('Dimension tables updated.') # 2. update facts # 2.1 update customers subscribed # delete old data for the same date query = ( "DELETE subscription_dwh.`fact_customer_subscribed`.* " "FROM subscription_dwh.`fact_customer_subscribed` " "INNER JOIN subscription_dwh.`dim_time` ON subscription_dwh.`fact_customer_subscribed`.`dim_time_id` = subscription_dwh.`dim_time`.`id` " "WHERE subscription_dwh.`dim_time`.`time_date` = " + yesterday_str) cursor.execute(query) # insert new data query = ( "INSERT INTO subscription_dwh.`fact_customer_subscribed`(`dim_city_id`, `dim_time_id`, `total_active`, `total_inactive`, `daily_new`, `daily_canceled`, `ts`) " " SELECT city_dwh.id AS dim_ctiy_id, time_dwh.id AS dim_time_id, SUM(CASE WHEN customer_live.active = 1 THEN 1 ELSE 0 END) AS total_active, SUM(CASE WHEN customer_live.active = 0 THEN 1 ELSE 0 END) AS total_inactive, SUM(CASE WHEN customer_live.active = 1 AND DATE(customer_live.time_updated) = @time_date THEN 1 ELSE 0 END) AS daily_new, SUM(CASE WHEN customer_live.active = 0 AND DATE(customer_live.time_updated) = @time_date THEN 1 ELSE 0 END) AS daily_canceled, MIN(NOW()) AS ts " "FROM subscription_live.`customer` customer_live " "INNER JOIN subscription_live.`city` city_live ON customer_live.city_id = city_live.id " "INNER JOIN subscription_live.`country` country_live ON city_live.country_id = country_live.id " "INNER JOIN subscription_dwh.dim_city city_dwh ON city_live.city_name = city_dwh.city_name AND city_live.postal_code = city_dwh.postal_code AND country_live.country_name = city_dwh.country_name " "INNER JOIN subscription_dwh.dim_time time_dwh ON time_dwh.time_date = " + yesterday_str + " " "GROUP BY city_dwh.id, time_dwh.id") cursor.execute(query) # 2.2 update subscription statuses # delete old data for the same date query = ( "DELETE subscription_dwh.`fact_subscription_status`.* " "FROM subscription_dwh.`fact_subscription_status` " "INNER JOIN subscription_dwh.`dim_time` ON subscription_dwh.`fact_subscription_status`.`dim_time_id` = subscription_dwh.`dim_time`.`id` " "WHERE subscription_dwh.`dim_time`.`time_date` = " + yesterday_str) cursor.execute(query) # insert new data query = ( "INSERT INTO subscription_dwh.`fact_subscription_status`(`dim_city_id`, `dim_time_id`, `total_active`, `total_inactive`, `daily_new`, `daily_canceled`, `ts`) " "SELECT city_dwh.id AS dim_ctiy_id, time_dwh.id AS dim_time_id, SUM(CASE WHEN subscription_live.active = 1 THEN 1 ELSE 0 END) AS total_active, SUM(CASE WHEN subscription_live.active = 0 THEN 1 ELSE 0 END) AS total_inactive, SUM(CASE WHEN subscription_live.active = 1 AND DATE(subscription_live.time_updated) = @time_date THEN 1 ELSE 0 END) AS daily_new, SUM(CASE WHEN subscription_live.active = 0 AND DATE(subscription_live.time_updated) = @time_date THEN 1 ELSE 0 END) AS daily_canceled, MIN(NOW()) AS ts " "FROM subscription_live.`customer` customer_live " "INNER JOIN subscription_live.`subscription` subscription_live ON subscription_live.customer_id = customer_live.id " "INNER JOIN subscription_live.`city` city_live ON customer_live.city_id = city_live.id " "INNER JOIN subscription_live.`country` country_live ON city_live.country_id = country_live.id " "INNER JOIN subscription_dwh.dim_city city_dwh ON city_live.city_name = city_dwh.city_name AND city_live.postal_code = city_dwh.postal_code AND country_live.country_name = city_dwh.country_name " "INNER JOIN subscription_dwh.dim_time time_dwh ON time_dwh.time_date = " + yesterday_str + " " "GROUP BY city_dwh.id, time_dwh.id") cursor.execute(query) print('Fact tables updated.') # commit & close connection cursor.close() connection.commit() connection.close() print('Disconnected from database.')
etl_queries.py
Importazione di moduli e connessione al database
Ancora una volta, dovremo importare MySQL utilizzando il seguente codice:
import mysql.connector
Importeremo anche il modulo datetime, come mostrato di seguito. Ne abbiamo bisogno per le operazioni relative alla data in Python:
from datetime import date
Il processo di connessione al database è lo stesso dell'esempio precedente.
Aggiornamento della dimensione dim_time
Per aggiornare il dim_time tabella, dovremo controllare se il valore (di ieri) è già nella tabella. Dovremo usare le funzioni di data di Python (invece di SQL) per farlo:
# date - yesterday yesterday = date.fromordinal(date.today().toordinal()-1) yesterday_str = '"' + str(yesterday) + '"'
La prima riga di codice restituirà la data di ieri nella variabile date, mentre la seconda riga memorizzerà questo valore come stringa. Avremo bisogno di questa come stringa perché la concateneremo con un'altra stringa quando creeremo la query SQL.
Successivamente, dovremo verificare se questa data è già nel dim_time tavolo. Dopo aver dichiarato un cursore, prepareremo la query SQL. Per eseguire la query, utilizzeremo cursor.execute comando:
# test if date is already in the table cursor = connection.cursor() query = ( "SELECT COUNT(*) " "FROM subscription_dwh.dim_time " "WHERE time_date = " + yesterday_str) cursor.execute(query) '"'
Memorizzeremo il risultato della query nel risultato variabile. Il risultato avrà 0 o 1 righe, quindi possiamo testare la prima colonna della prima riga. Conterrà uno 0 o un 1. (Ricorda, possiamo avere la stessa data solo una volta in una tabella dimensionale.)
Se la data non è già nella tabella, prepareremo le stringhe che faranno parte della query SQL:
result = cursor.fetchall()
yesterday_subscription_count = int(result[0][0])
if yesterday_subscription_count == 0:
yesterday_year = 'YEAR("' + str(yesterday) + '")'
yesterday_month = 'MONTH("' + str(yesterday) + '")'
yesterday_week = 'WEEK("' + str(yesterday) + '")'
yesterday_weekday = 'WEEKDAY("' + str(yesterday) + '")'
Infine, creeremo una query e la eseguiremo. Questo aggiornerà il dim_time tabella dopo il commit. Tieni presente che ho utilizzato il percorso completo della tabella, incluso il nome del database (subscription_dwh ).
query = (
"INSERT INTO subscription_dwh.`dim_time`(`time_date`, `time_year`, `time_month`, `time_week`, `time_weekday`, `ts`) "
" VALUES (" + yesterday_str + ", " + yesterday_year + ", " + yesterday_month + ", " + yesterday_week + ", " + yesterday_weekday + ", Now())")
cursor.execute(query)
Aggiorna la dimensione dim_city
Aggiornamento di dim_city table è ancora più semplice perché non abbiamo bisogno di testare nulla prima dell'inserimento. Includeremo effettivamente quel test nella query SQL.
# 1.2 update dim_city query = ( "INSERT INTO subscription_dwh.`dim_city`(`city_name`, `postal_code`, `country_name`, `ts`) " "SELECT city_live.city_name, city_live.postal_code, country_live.country_name, Now() " "FROM subscription_live.city city_live " "INNER JOIN subscription_live.country country_live ON city_live.country_id = country_live.id " "LEFT JOIN subscription_dwh.dim_city city_dwh ON city_live.city_name = city_dwh.city_name AND city_live.postal_code = city_dwh.postal_code AND country_live.country_name = city_dwh.country_name " "WHERE city_dwh.id IS NULL") cursor.execute(query)
Qui prepariamo un'esecuzione della query SQL. Si noti che ho nuovamente utilizzato i percorsi completi delle tabelle, inclusi i nomi di entrambi i database (subscription_live e subscription_dwh ).
Aggiornamento delle tabelle dei fatti
L'ultima cosa che dobbiamo fare è aggiornare le nostre tabelle dei fatti. Il processo è quasi lo stesso dell'aggiornamento delle tabelle dimensionali:prepariamo le query e le eseguiamo. Queste query sono molto più complesse, ma sono le stesse utilizzate nelle stored procedure.
Abbiamo aggiunto un miglioramento rispetto alle stored procedure:eliminare i dati esistenti per la stessa data nella tabella dei fatti. Questo ci consentirà di eseguire uno script più volte per la stessa data. Alla fine, dovremo eseguire il commit della transazione e chiudere tutti gli oggetti e la connessione.
Esecuzione dello script
Abbiamo una piccola modifica in questa parte, che chiama uno script diverso:
- import os
- file_path = 'D://python_scripts'
- os.chdir(file_path)
- exec(open("etl_queries.py").read())
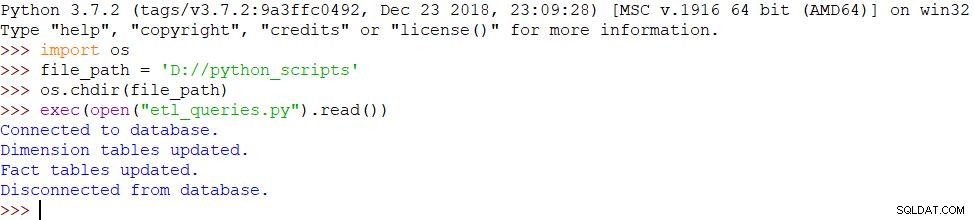
Poiché abbiamo utilizzato gli stessi messaggi e lo script è stato completato correttamente, il risultato è lo stesso:
Come useresti Python in ETL?
Oggi abbiamo visto un esempio di esecuzione del processo ETL con uno script Python. Ci sono altri modi per farlo, ad es. una serie di soluzioni open source che utilizzano le librerie Python per lavorare con i database ed eseguire il processo ETL. Nel prossimo articolo giocheremo con uno di loro. Nel frattempo, sentiti libero di condividere la tua esperienza con Python ed ETL.