I database devono funzionare in modo ottimale, ma non è un compito così facile. Il database INFORMATION SCHEMA può essere la tua arma segreta nella guerra dell'ottimizzazione del database.
Siamo abituati a creare database utilizzando un'interfaccia grafica o una serie di comandi SQL. Va benissimo, ma è anche bene capire un po' cosa sta succedendo in background. Questo è importante per la creazione, la manutenzione e l'ottimizzazione di un database, ed è anche un buon modo per tenere traccia delle modifiche che si verificano "dietro le quinte".
In questo articolo, esamineremo una manciata di query SQL che possono aiutarti a esaminare il funzionamento di un database MySQL.
Il database INFORMATION_SCHEMA
Abbiamo già discusso di INFORMATION_SCHEMA database in questo articolo. Se non l'hai già letto, ti consiglio vivamente di farlo prima di continuare.
Se hai bisogno di un aggiornamento su INFORMATION_SCHEMA database – o se decidi di non leggere il primo articolo – ecco alcuni fatti di base che devi sapere:
- Il
INFORMATION_SCHEMAdatabase fa parte dello standard ANSI. Lavoreremo con MySQL, ma altri RDBMS hanno le loro varianti. Puoi trovare versioni per H2 Database, HSQLDB, MariaDB, Microsoft SQL Server e PostgreSQL. - Questo è il database che tiene traccia di tutti gli altri database sul server; qui troveremo le descrizioni di tutti gli oggetti.
- Come qualsiasi altro database, il
INFORMATION_SCHEMAil database contiene una serie di tabelle correlate e informazioni su oggetti diversi. - Puoi interrogare questo database usando SQL e usare i risultati per:
- Monitoraggio dello stato e delle prestazioni del database e
- Genera automaticamente codice in base ai risultati della query.
Passiamo ora all'interrogazione del database INFORMATION_SCHEMA. Inizieremo osservando il modello di dati che utilizzeremo.
Il modello dei dati
Il modello che utilizzeremo in questo articolo è mostrato di seguito.
Questo è un modello semplificato che ci consente di memorizzare informazioni su classi, insegnanti, studenti e altri dettagli correlati. Esaminiamo brevemente le tabelle.
Conserveremo l'elenco degli insegnanti nel lecturer tavolo. Per ogni docente registreremo un first_name e un last_name .
La class la tabella elenca tutte le classi che abbiamo nella nostra scuola. Per ogni record in questa tabella, memorizzeremo il class_name , l'ID del docente, una start_date pianificata e end_date e qualsiasi ulteriore class_details . Per semplicità, suppongo che abbiamo un solo docente per classe.
Le lezioni sono generalmente organizzate come una serie di lezioni. In genere richiedono uno o più esami. Conserveremo elenchi di lezioni ed esami correlati nella lecture e exam tavoli. Entrambi avranno l'ID della classe correlata e il start_time previsto e end_time .
Ora abbiamo bisogno di studenti per le nostre classi. Un elenco di tutti gli studenti è memorizzato in student tavolo. Ancora una volta, memorizzeremo solo il first_name e il last_name di ogni studente.
L'ultima cosa che dobbiamo fare è tenere traccia delle attività degli studenti. Conserveremo un elenco di ogni classe a cui uno studente si è iscritto, il record di frequenza dello studente e i risultati degli esami. Ognuna delle restanti tre tabelle – on_class , on_lecture e on_exam – avrà un riferimento allo studente e un riferimento all'apposita tabella. Solo il on_exam la tabella avrà un valore aggiuntivo:voto.
Sì, questo modello è molto semplice. Potremmo aggiungere molti altri dettagli su studenti, docenti e classi. Potremmo memorizzare valori storici quando i record vengono aggiornati o eliminati. Tuttavia, questo modello sarà sufficiente per gli scopi di questo articolo.
Creazione di un database
Siamo pronti per creare un database sul nostro server locale ed esaminare cosa sta succedendo al suo interno. Esporteremo il modello (in Vertabelo) utilizzando "Generate SQL script pulsante ".
Quindi creeremo un database sull'istanza di MySQL Server. Ho chiamato il mio database “classes_and_students ”.
La prossima cosa che dobbiamo fare è eseguire uno script SQL precedentemente generato.
Ora abbiamo il database con tutti i suoi oggetti (tabelle, chiavi primarie ed esterne, chiavi alternative).
Dimensioni database
Dopo l'esecuzione dello script, i dati su "classes and students ” è memorizzato nel INFORMATION_SCHEMA Banca dati. Questi dati sono in molte tabelle diverse. Non li elencherò di nuovo tutti qui; l'abbiamo fatto nell'articolo precedente.
Vediamo come possiamo utilizzare SQL standard su questo database. Inizierò con una domanda molto importante:
SET @table_schema = "classes_and_students";
SELECT
ROUND(SUM( INFORMATION_SCHEMA.TABLES.DATA_LENGTH + INFORMATION_SCHEMA.TABLES.INDEX_LENGTH ) / 1024 / 1024, 2) AS "DB Size (in MB)",
ROUND(SUM( INFORMATION_SCHEMA.TABLES.DATA_FREE )/ 1024 / 1024, 2) AS "Free Space (in MB)"
FROM INFORMATION_SCHEMA.TABLES
WHERE INFORMATION_SCHEMA.TABLES.TABLE_SCHEMA = @table_schema;
Stiamo solo interrogando il INFORMATION_SCHEMA.TABLES tabella qui. Questa tabella dovrebbe darci dettagli più che sufficienti su tutte le tabelle sul server. Tieni presente che ho filtrato solo le tabelle da "classes_and_students " database utilizzando il SET variabile nella prima riga e successivamente utilizzando questo valore nella query. La maggior parte delle tabelle contiene le colonne TABLE_NAME e TABLE_SCHEMA , che indica la tabella e lo schema/database a cui appartengono questi dati.
Questa query restituirà la dimensione attuale del nostro database e lo spazio libero riservato al nostro database. Ecco il risultato effettivo:

Come previsto, la dimensione del nostro database vuoto è inferiore a 1 MB e lo spazio libero riservato è molto maggiore.
Dimensioni e proprietà della tabella
La prossima cosa interessante da fare sarebbe guardare le dimensioni delle tabelle nel nostro database. Per farlo, utilizzeremo la seguente query:
SET @table_schema = "classes_and_students";
SELECT
INFORMATION_SCHEMA.TABLES.TABLE_NAME,
ROUND(SUM( INFORMATION_SCHEMA.TABLES.DATA_LENGTH + INFORMATION_SCHEMA.TABLES.INDEX_LENGTH ) / 1024 / 1024, 2) "Table Size (in MB)",
ROUND(SUM( INFORMATION_SCHEMA.TABLES.DATA_FREE )/ 1024 / 1024, 2) AS "Free Space (in MB)",
MAX( INFORMATION_SCHEMA.TABLES.TABLE_ROWS) AS table_rows_number,
MAX( INFORMATION_SCHEMA.TABLES.AUTO_INCREMENT) AS auto_increment_value
FROM INFORMATION_SCHEMA.TABLES
WHERE INFORMATION_SCHEMA.TABLES.TABLE_SCHEMA = @table_schema
GROUP BY INFORMATION_SCHEMA.TABLES.TABLE_NAME
ORDER BY 2 DESC;
La query è quasi identica alla precedente, con un'eccezione:il risultato è raggruppato a livello di tabella.
Ecco un'immagine del risultato restituito da questa query:
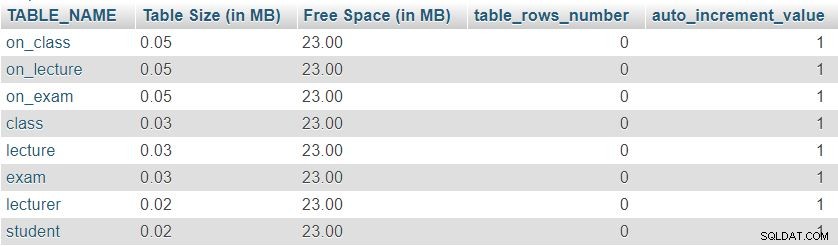
Innanzitutto, possiamo notare che tutte e otto le tabelle hanno una "Dimensione tabella" minima riservato per la definizione della tabella, che include le colonne, la chiave primaria e l'indice. Lo "Spazio libero" è equamente distribuito tra tutte le tabelle.
Possiamo anche vedere il numero di righe attualmente in ogni tabella e il valore corrente di auto_increment proprietà per ogni tabella. Poiché tutte le tabelle sono completamente vuote, non abbiamo dati e auto_increment è impostato su 1 (un valore che verrà assegnato alla riga successiva inserita).
Chiavi primarie
Ogni tabella dovrebbe avere un valore di chiave primaria definito, quindi è consigliabile verificare se questo è vero per il nostro database. Un modo per farlo è unire un elenco di tutte le tabelle con un elenco di vincoli. Questo dovrebbe darci le informazioni di cui abbiamo bisogno.
SET @table_schema = "classes_and_students";
SELECT
tab.TABLE_NAME,
COUNT(*) AS PRI_number
FROM INFORMATION_SCHEMA.TABLES tab
LEFT JOIN (
SELECT
INFORMATION_SCHEMA.COLUMNS.TABLE_SCHEMA,
INFORMATION_SCHEMA.COLUMNS.TABLE_NAME
FROM INFORMATION_SCHEMA.COLUMNS
WHERE INFORMATION_SCHEMA.COLUMNS.TABLE_SCHEMA = @table_schema
AND INFORMATION_SCHEMA.COLUMNS.COLUMN_KEY = 'PRI'
) col
ON tab.TABLE_SCHEMA = col.TABLE_SCHEMA
AND tab.TABLE_NAME = col.TABLE_NAME
WHERE tab.TABLE_SCHEMA = @table_schema
GROUP BY
tab.TABLE_NAME;
Abbiamo anche utilizzato INFORMATION_SCHEMA.COLUMNS tabella in questa query. Mentre la prima parte della query restituirà semplicemente tutte le tabelle nel database, la seconda parte (dopo LEFT JOIN ) conteggerà il numero di PRI in queste tabelle. Abbiamo usato LEFT JOIN perché vogliamo vedere se una tabella ha 0 PRI nelle COLUMNS tabella.
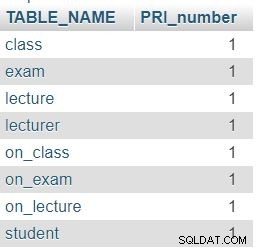
Come previsto, ogni tabella nel nostro database contiene esattamente una colonna di chiave primaria (PRI).
"Isole"?
Le “Isole” sono tabelle completamente separate dal resto del modello. Si verificano quando una tabella non contiene chiavi esterne e non è referenziata in nessun'altra tabella. Questo in realtà non dovrebbe verificarsi a meno che non ci sia una buona ragione, ad es. quando le tabelle contengono parametri o memorizzano risultati o report all'interno del modello.
SET @table_schema = "classes_and_students";
SELECT
tab.TABLE_NAME,
(CASE WHEN f1.number_referenced IS NULL THEN 0 ELSE f1.number_referenced END) AS number_referenced,
(CASE WHEN f2.number_referencing IS NULL THEN 0 ELSE f2.number_referencing END) AS number_referencing
FROM INFORMATION_SCHEMA.TABLES tab
LEFT JOIN
-- # table was used as a reference
(
SELECT
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_SCHEMA,
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_NAME,
COUNT(*) AS number_referenced
FROM INFORMATION_SCHEMA.KEY_COLUMN_USAGE
WHERE INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_SCHEMA = @table_schema
GROUP BY
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_SCHEMA,
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_NAME
) f1
ON tab.TABLE_SCHEMA = f1.REFERENCED_TABLE_SCHEMA
AND tab.TABLE_NAME = f1.REFERENCED_TABLE_NAME
LEFT JOIN
-- # of references in the table
(
SELECT
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.TABLE_SCHEMA,
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.TABLE_NAME,
COUNT(*) AS number_referencing
FROM INFORMATION_SCHEMA.KEY_COLUMN_USAGE
WHERE INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_SCHEMA = @table_schema
AND INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_NAME IS NOT NULL
GROUP BY
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.TABLE_SCHEMA,
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.TABLE_NAME
) f2
ON tab.TABLE_SCHEMA = f2.TABLE_SCHEMA
AND tab.TABLE_NAME = f2.TABLE_NAME
WHERE tab.TABLE_SCHEMA = @table_schema;
Qual è l'idea alla base di questa query? Bene, stiamo usando il INFORMATION_SCHEMA.KEY_COLUMN_USAGE tabella per verificare se una colonna nella tabella è un riferimento a un'altra tabella o se una colonna viene utilizzata come riferimento in qualsiasi altra tabella. La prima parte della query seleziona tutte le tabelle. Dopo il primo LEFT JOIN, contiamo il numero di volte in cui una colonna di questa tabella è stata utilizzata come riferimento. Dopo il secondo LEFT JOIN, contiamo il numero di volte in cui una colonna di questa tabella ha fatto riferimento a qualsiasi altra tabella.
Il risultato restituito è:
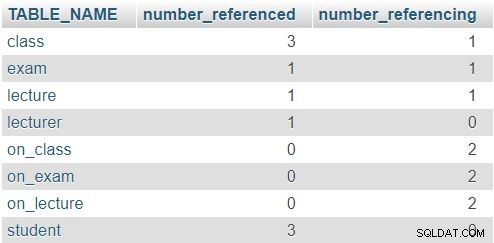
Nella riga per la class tabella, i numeri 3 e 1 indicano che questa tabella è stata referenziata tre volte (nella lecture , exam e on_class tabelle) e che contiene un attributo che fa riferimento a un'altra tabella (lecturer_id ). Le altre tabelle seguono uno schema simile, anche se i numeri effettivi saranno ovviamente diversi. La regola qui è che nessuna riga deve avere uno 0 in entrambe le colonne.
Aggiunta di righe
Finora, tutto è andato come previsto. Abbiamo importato con successo il nostro modello di dati da Vertabelo al server MySQL locale. Tutte le tabelle contengono chiavi, proprio come le desideriamo, e tutte le tabelle sono correlate tra loro:non ci sono "isole" nel nostro modello.
Ora inseriremo alcune righe nelle nostre tabelle e utilizzeremo le query precedentemente dimostrate per tenere traccia delle modifiche nel nostro database.
Dopo aver aggiunto 1.000 righe nella tabella del docente, eseguiremo nuovamente la query da "Table Sizes and Properties " sezione. Restituirà il seguente risultato:
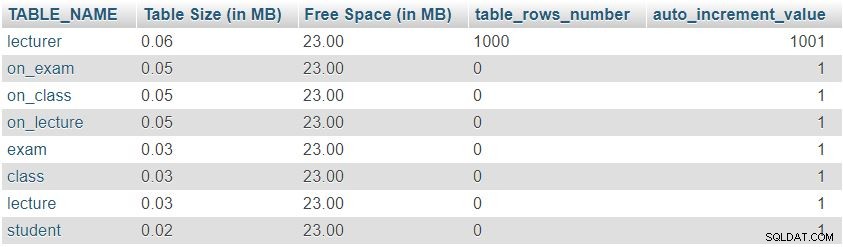
Possiamo facilmente notare che il numero di righe e i valori di auto_increment sono cambiati come previsto, ma non ci sono stati cambiamenti significativi nelle dimensioni della tabella.
Questo era solo un esempio di prova; in situazioni di vita reale, noteremo cambiamenti significativi. Il numero di righe cambierà drasticamente nelle tabelle popolate da utenti o processi automatizzati (cioè tabelle che non sono dizionari). Controllare la dimensione e i valori in tali tabelle è un ottimo modo per trovare e correggere rapidamente comportamenti indesiderati.
Vuoi condividere?
Lavorare con i database è una ricerca costante per prestazioni ottimali. Per avere più successo in quella ricerca, dovresti usare qualsiasi strumento disponibile. Oggi abbiamo visto alcune domande utili nella nostra lotta per prestazioni migliori. Hai trovato qualcos'altro di utile? Hai giocato con INFORMATION_SCHEMA database prima? Condividi la tua esperienza nei commenti qui sotto.