L'implementazione di una ricerca intuitiva può essere complicata, ma può anche essere eseguita in modo molto efficiente. Come faccio a saperlo? Non molto tempo fa, avevo bisogno di implementare un motore di ricerca su un'app mobile. L'app è stata costruita sul framework Ionic e si sarebbe collegata a un backend CakePHP 2. L'idea era di visualizzare i risultati mentre l'utente stava digitando. C'erano diverse opzioni per questo, ma non tutte soddisfacevano i requisiti del mio progetto.
Per illustrare cosa comporta questo tipo di attività, immaginiamo di cercare le canzoni e le loro possibili relazioni (come artisti, album, ecc.).
I record dovrebbero essere ordinati per pertinenza, che dipenderebbe dal fatto che la parola di ricerca corrispondesse ai campi del record stesso o di altre colonne nelle tabelle correlate. Inoltre, la ricerca dovrebbe implementare almeno alcune derivazioni di parole di base. (Stemming è usato per ottenere la forma radice di una parola. "Gambi", "stemmer", "stemming" e "stemmed" hanno tutti la stessa radice:"stem".)
L'approccio qui presentato è stato testato con diverse centinaia di migliaia di record ed è stato in grado di recuperare risultati utili durante la digitazione dell'utente.
Prodotti di ricerca full-text da considerare
Ci sono diversi modi in cui potremmo implementare questo tipo di ricerca. Il nostro progetto aveva alcuni vincoli in relazione al tempo e alle risorse del server, quindi dovevamo mantenere la soluzione il più semplice possibile. Alla fine sono emersi un paio di contendenti:
Ricerca elastica
Elasticsearch fornisce ricerche full-text in un servizio orientato ai documenti. È progettato per gestire enormi quantità di carico in modo distribuito:può classificare i risultati in base alla pertinenza, eseguire aggregazioni e lavorare con la derivazione delle parole e sinonimi. Questo strumento è pensato per ricerche in tempo reale. Dal loro sito web:
Elasticsearch costruisce capacità distribuite su Apache Lucene per fornire le più potenti capacità di ricerca full-text disponibili. L'API di query potente e intuitiva per gli sviluppatori supporta la ricerca multilingue, la geolocalizzazione, i suggerimenti contestuali, il completamento automatico e gli snippet dei risultati.
Elasticsearch può funzionare come servizio REST, rispondendo alle richieste http e può essere configurato molto rapidamente. Tuttavia, per avviare il motore come servizio è necessario disporre di alcuni privilegi di accesso al server. E se il tuo provider di hosting non supporta Elasticsearch immediatamente, dovrai installare alcuni pacchetti.
La linea di fondo è che questo prodotto è un'ottima opzione se si desidera una soluzione di ricerca solida. (Nota:potresti aver bisogno di un VPS o di un server dedicato poiché i requisiti hardware sono piuttosto esigenti.)
Sfinge
Come Elasticsearch, anche Sphinx fornisce un prodotto di ricerca full-text molto solido:Craigslist serve più di 300.000.000 di query al giorno con esso. Sphinx non fornisce un'interfaccia RESTful nativa. È implementato in C, con un footprint hardware inferiore rispetto a Elasticsearch (che è implementato in Java e può essere eseguito su qualsiasi sistema operativo con jvm). Avrai anche bisogno dell'accesso come root al server con un po' di RAM/CPU dedicata per eseguire Sphinx correttamente.
Ricerca full-text in MySQL
Storicamente, le ricerche full-text erano supportate nei motori MyISAM. Dopo la versione 5.6, MySQL supportava anche le ricerche full-text nei motori di archiviazione InnoDB. Questa è stata un'ottima notizia, poiché consente agli sviluppatori di beneficiare dell'integrità referenziale, della capacità di eseguire transazioni e dei blocchi a livello di riga di InnoDB.
Esistono fondamentalmente due approcci alle ricerche full-text in MySQL:linguaggio naturale e modalità booleana. (Una terza opzione aumenta la ricerca in linguaggio naturale con una seconda query di espansione.)
La principale differenza tra la modalità naturale e quella booleana è che la modalità booleana consente determinati operatori come parte della ricerca. Ad esempio, gli operatori booleani possono essere utilizzati se una parola ha maggiore rilevanza di altre nella query o se una parola specifica dovrebbe essere presente nei risultati, ecc. Vale la pena notare che in entrambi i casi, i risultati possono essere ordinati in base alla rilevanza calcolata da MySQL durante la ricerca.
Prendere le decisioni
La soluzione migliore per il nostro problema era utilizzare le ricerche full-text di InnoDb in modalità booleana. Come mai?
- Abbiamo avuto poco tempo per implementare la funzione di ricerca.
- A questo punto, non avevamo big data da sgranocchiare né un carico enorme per richiedere qualcosa come Elasticsearch o Sphinx.
- Abbiamo utilizzato un hosting condiviso che non supporta Elasticsearch o Sphinx e l'hardware era piuttosto limitato in questa fase.
- Anche se volevamo la derivazione delle parole nella nostra funzione di ricerca, non è stato un problema:potevamo implementarla (entro i limiti) tramite una semplice codifica PHP e denormalizzazione dei dati
- Le ricerche full-text in modalità booleana possono cercare parole con caratteri jolly (per la derivazione delle parole) e ordinare i risultati in base alla pertinenza.
Ricerche full-text in modalità booleana
Come accennato in precedenza, la ricerca in linguaggio naturale è l'approccio più semplice:basta cercare una frase o una parola nelle colonne in cui hai impostato un indice full-text e otterrai risultati ordinati per rilevanza.
Nel modello Vertabelo normalizzato
Vediamo come funzionerebbe una semplice ricerca. Creeremo prima una tabella di esempio:
-- Created by Vertabelo (https://vertabelo.com) -- Last modification date: 2016-04-25 15:01:22.153 -- tables -- Table: artists CREATE TABLE artists ( id int(11) NOT NULL AUTO_INCREMENT, name varchar(255) NOT NULL, bio text NOT NULL, CONSTRAINT artists_pk PRIMARY KEY (id) ) ENGINE InnoDB; CREATE FULLTEXT INDEX artists_idx_1 ON artists (name); -- End of file.
In modalità linguaggio naturale
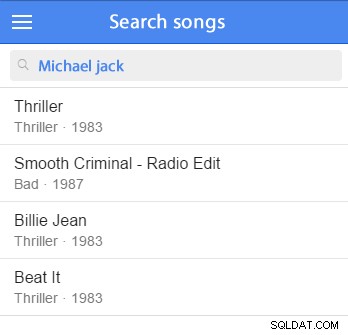
È possibile inserire alcuni dati di esempio e avviare il test. (Sarebbe utile aggiungerlo al tuo set di dati di esempio.) Ad esempio, proveremo a cercare Michael Jackson:
SELECT
*
FROM
artists
WHERE
MATCH (artists.name) AGAINST ('Michael Jackson' IN NATURAL LANGUAGE MODE)
Questa query troverà i record che corrispondono ai termini di ricerca e li ordinerà per rilevanza; migliore è la corrispondenza, più rilevante è e più alto sarà il risultato nell'elenco.
In modalità booleana
Possiamo eseguire la stessa ricerca in modalità booleana. Se non applichiamo alcun operatore alla nostra query, l'unica differenza sarà che i risultati non lo sono ordinati per rilevanza:
SELECT
*
FROM
artists
WHERE
MATCH (artists.name) AGAINST ('Michael Jackson' IN BOOLEAN MODE)
L'operatore jolly in modalità booleana
Poiché vogliamo cercare parole derivate e parziali, avremo bisogno dell'operatore jolly (*). Questo operatore può essere utilizzato nelle ricerche in modalità booleana, motivo per cui abbiamo scelto quella modalità.
Quindi, liberiamo il potere della ricerca booleana e proviamo a cercare parte del nome dell'artista. Utilizzeremo l'operatore jolly per abbinare qualsiasi artista il cui nome inizia con "Mich":
SELECT
*
FROM
artists
WHERE
MATCH (name) AGAINST ('Mich*' IN BOOLEAN MODE)
Ordinamento per rilevanza in modalità booleana
Ora vediamo la pertinenza calcolata per la ricerca. Questo ci aiuterà a capire lo smistamento che faremo in seguito con Cake:
SELECT
*, MATCH (name) AGAINST ('mich*' IN BOOLEAN MODE) AS rank
FROM
artists
WHERE
MATCH (name) AGAINST ('mich*' IN BOOLEAN MODE)
ORDER BY rank DESC
Questa query recupera le corrispondenze di ricerca e il valore di pertinenza che MySQL calcola per ogni record. L'ottimizzatore del motore rileverà che stiamo selezionando la pertinenza, quindi non si preoccuperà di ricalcolare il grado.
Word Stemming nella ricerca full-text
Quando incorporiamo la derivazione di parole in una ricerca, la ricerca diventa più intuitiva. Anche se il risultato non è una parola in sé, gli algoritmi cercano di generare la stessa radice per le parole derivate. Ad esempio, la radice "argu" non è una parola inglese, ma può essere usata come radice per "argue", "argued", "argues", "arguing","Argus" e altre parole.
Stemming migliora i risultati, poiché l'utente può inserire una parola che non ha una corrispondenza esatta ma la sua "radice" sì. Sebbene PHP stemmer o Snowball's Python stemmer possano essere un'opzione (se hai accesso SSH root al tuo server), utilizzeremo la classe PorterStemmer.php.
Questa classe implementa l'algoritmo proposto da Martin Porter per arginare le parole in inglese. Come affermato dall'autore nel suo sito Web, è gratuito per qualsiasi scopo. Trascina semplicemente il file all'interno della tua directory Vendors all'interno di CakePHP, includi la libreria nel tuo modello e chiama il metodo static per derivare una parola:
//include the library (should be called PorterStemmer.php) within CakePHP’s Vendors folder
App::import('Vendor', 'PorterStemmer');
//stem a word (words must be stemmed one by one)
echo PorterStemmer::Stem(‘stemming’);
//output will be ‘stem’
Il nostro obiettivo è rendere la ricerca rapida ed efficiente e poter ordinare i risultati in base alla pertinenza del testo completo. Per fare ciò, dovremo utilizzare la radice delle parole in due modi:
- Le parole inserite dall'utente
- Dati relativi al brano (che memorizzeremo in colonne e ordineremo i risultati in base alla pertinenza)
Il primo tipo di derivazione delle parole può essere realizzato in questo modo:
App::import('Vendor', 'PorterStemmer');
$search = trim(preg_replace('/[^A-Za-z0-9_\s]/', '', $search));//remove undesired characters
$words = explode(" ", trim($search));
$stemmedSearch = "";
$unstemmedSearch = "";
foreach ($words as $word) {
$stemmedSearch .= PorterStemmer::Stem($word) . "* ";//we add the wildcard after each word
$unstemmedSearch = $word . "* " ;//to search the artist column which is not stemmed
}
$stemmedSearch = trim($stemmedSearch);
$unstemmedSearch = trim($unstemmedSearch);
if ($stemmedSearch == "*" || $unstemmedSearch=="*") {
//otherwise mySql will complain, as you cannot use the wildcard alone
$stemmedSearch = "";
$unstemmedSearch = "";
}
Abbiamo creato due stringhe:una per cercare il nome dell'artista (senza stemming) e una per cercare nelle altre colonne stem. Questo ci aiuterà in seguito a costruire il nostro 'contro' parte della query full-text. Ora vediamo come possiamo derivare e ordinare i dati della canzone.
Denormalizzazione dei dati dei brani
I nostri criteri di ordinamento si baseranno prima sulla corrispondenza dell'artista della canzone (senza stemming). Successivamente verranno il nome della canzone, l'album e le categorie correlate. Lo stemma verrà utilizzato su tutti i criteri di ricerca secondari.
Per illustrare questo, supponiamo che io cerchi "nirvana" e ci sia una canzone chiamata "Nirvana Games" di "XYZ" e un'altra canzone chiamata "Polly" dell'artista "Nirvana". I risultati dovrebbero elencare prima "Polly", poiché la corrispondenza con il nome dell'artista è più importante di una corrispondenza con il nome del brano (in base ai miei criteri).
Per fare ciò, ho aggiunto 4 campi nei songs tabella, una per ciascuno dei criteri di ricerca/ordinamento desiderati:
ALTER TABLE `songs` ADD `denorm_artist` VARCHAR(255) NOT NULL AFTER`trackname`, ADD `denorm_trackname` VARCHAR(500) NOT NULL AFTER`denorm_artist`, ADD `denorm_album` VARCHAR(255) NOT NULL AFTER`denorm_trackname`, ADD `denorm_categories` VARCHAR(500) NOT NULL AFTER`denorm_album`, ADD FULLTEXT (`denorm_artist`), ADD FULLTEXT(`denorm_trackname`), ADD FULLTEXT (`denorm_album`), ADD FULLTEXT(`denorm_categories`);
Il nostro modello di database completo sarebbe simile a questo:
Ogni volta che salvi un brano utilizzando aggiungi/modifica in CakePHP, devi solo memorizzare il nome dell'artista nella colonna denorm_artist senza arginare. Quindi, aggiungi il nome della traccia derivata nel denorm_trackname campo (simile a quello che abbiamo fatto nel testo cercato) e salvare il nome dell'album derivato nel denorm_album colonna. Infine, memorizza la categoria derivata impostata per il brano in denorm_categories campo, concatenando le parole e aggiungendo uno spazio tra ogni nome di categoria derivata.
Ricerca full-text e ordinamento per rilevanza in CakePHP
Continuando con l'esempio della ricerca di "Nirvana", vediamo cosa può ottenere una query simile a questa:
SELECT
trackname,
MATCH(denorm_artist) AGAINST ('Nirvana*' IN BOOLEAN MODE) as rank1,
MATCH(denorm_trackname) AGAINST ('Nirvana*' IN BOOLEAN MODE) as rank2,
MATCH(denorm_album) AGAINST ('Nirvana*' IN BOOLEAN MODE) as rank3,
MATCH(denorm_categories) AGAINST ('Nirvana*' IN BOOLEAN MODE) as rank4
FROM songs
WHERE
MATCH(denorm_artist) AGAINST ('Nirvana*' IN BOOLEAN MODE) OR
MATCH(denorm_trackname) AGAINST ('Nirvana*' IN BOOLEAN MODE) OR
MATCH(denorm_album) AGAINST ('Nirvana*' IN BOOLEAN MODE) OR
MATCH(denorm_categories) AGAINST ('Nirvana*' IN BOOLEAN MODE)
ORDER BY rank1 DESC, rank2 DESC, rank3 DESC, rank4 DESC
Otterremmo il seguente output:
| nome traccia | grado1 | grado2 | grado3 | grado4 |
| Polli | 0,0906190574169159 | 0 | 0 | 0 |
| giochi nirvana | 0 | 0,0906190574169159 | 0 | 0 |
Per farlo in CakePHP, il trova deve essere chiamato utilizzando una combinazione di parametri "campi", "condizioni" e "ordine". Continuando con il precedente codice di esempio PHP:
//within Song.php model file
$fields = array(
"Song.trackname",
"MATCH(Song.denorm_artist) AGAINST ({$unstemmedSearch} IN BOOLEAN MODE) as `rank1`",
"MATCH(Song.denorm_trackname) AGAINST ({$stemmedSearch} IN BOOLEAN MODE) as `rank2`",
"MATCH(Song.denorm_album) AGAINST ({$stemmedSearch} IN BOOLEAN MODE) as `rank3`",
"MATCH(Song.denorm_categories) AGAINST ({$stemmedSearch} IN BOOLEAN MODE) as `rank4`"
);
$order = "`rank1` DESC,`rank2` DESC,`rank3` DESC,`rank4` DESC,Song.trackname ASC";
$conditions = array(
"OR" => array(
"MATCH(Song.denorm_artist) AGAINST ({$unstemmedSearch} IN BOOLEAN MODE)",
"MATCH(Song.denorm_trackname) AGAINST ({$stemmedSearch} IN BOOLEAN MODE)",
"MATCH(Song.denorm_album) AGAINST ({$stemmedSearch} IN BOOLEAN MODE)",
"MATCH(Song.denorm_categories) AGAINST ({$stemmedSearch} IN BOOLEAN MODE)"
)
);
$results = $this->find(‘all’,array(‘conditions’=>$conditions,’fields’=>$fields,’order’=>$order);
$risultati sarà l'array di brani ordinati con i criteri che abbiamo definito in precedenza.
Questa soluzione può essere utilizzata per generare ricerche significative per l'utente, senza richiedere troppo tempo agli sviluppatori o aggiungere complessità al codice.
Migliorare ulteriormente le ricerche su CakePHP
Vale la pena ricordare che "ravvivare" le colonne denormalizzate con più dati può portare a risultati migliori.
Per "spicing" intendo che potresti includere, nelle colonne denormalizzate, più dati da colonne aggiuntive che ritieni utili con l'obiettivo di rendere i risultati più pertinenti, ad esempio se sapessi che il paese di un artista potrebbe figurare nei termini di ricerca, potrebbe aggiungere il paese insieme al nome dell'artista nel denorm_artist colonna. Ciò migliorerebbe la qualità dei risultati della ricerca.
Dalla mia esperienza (a seconda dei dati effettivi che usi e delle colonne che denormalizzi) i risultati più alti tendono ad essere davvero accurati. Questo è ottimo per le app mobili, poiché scorrere un lungo elenco può essere frustrante per l'utente.
Infine, se hai bisogno di ottenere più dati dalle tabelle a cui si riferisce il brano, puoi sempre creare un join e ottenere l'artista, le categorie, gli album, i commenti del brano, ecc. Se stai utilizzando il filtro di comportamento contenibile di CakePHP, lo farei suggerisci di aggiungere il plug-in EagerLoader per eseguire i join in modo efficiente.
Se hai il tuo approccio per implementare la ricerca full-text, condividilo nei commenti qui sotto. Tutti possiamo imparare dall'esperienza dell'altro.