I problemi di ritardo della replica in PostgreSQL non sono un problema diffuso per la maggior parte delle configurazioni. Tuttavia, può verificarsi e quando lo fa può influire sulle impostazioni di produzione. PostgreSQL è progettato per gestire più thread, come il parallelismo delle query o la distribuzione di thread di lavoro per gestire attività specifiche in base ai valori assegnati nella configurazione. PostgreSQL è progettato per gestire carichi pesanti e stressanti, ma a volte (a causa di una configurazione errata) il tuo server potrebbe andare ancora male.
Identificare il ritardo di replica in PostgreSQL non è un compito complicato da fare, ma ci sono alcuni approcci diversi per esaminare il problema. In questo blog, daremo un'occhiata a cosa guardare quando la tua replica PostgreSQL è in ritardo.
Tipi di replica in PostgreSQL
Prima di approfondire l'argomento, vediamo innanzitutto come si evolve la replica in PostgreSQL poiché esistono diversi set di approcci e soluzioni quando si ha a che fare con la replica.
Warm standby per PostgreSQL è stato implementato nella versione 8.2 (nel 2006) ed era basato sul metodo di log shipping. Ciò significa che i record WAL vengono spostati direttamente da un server di database a un altro per essere applicati, o semplicemente un approccio analogo a PITR, o molto simile a quello che stai facendo con rsync.
Questo approccio, anche vecchio, è ancora utilizzato oggi e alcune istituzioni in realtà preferiscono questo approccio più vecchio. Questo approccio implementa un log shipping basato su file trasferendo i record WAL un file (segmento WAL) alla volta. Anche se ha un aspetto negativo; Un grave errore sui server primari, le transazioni non ancora spedite andranno perse. C'è una finestra per la perdita di dati (puoi regolarla usando il parametro archive_timeout, che può essere impostato su un minimo di pochi secondi, ma un'impostazione così bassa aumenterà sostanzialmente la larghezza di banda richiesta per la spedizione dei file).
In PostgreSQL versione 9.0 è stata introdotta la replica in streaming. Questa funzione ci ha permesso di rimanere più aggiornati rispetto alla spedizione dei log basata su file. Il suo approccio consiste nel trasferire i record WAL (un file WAL è composto da record WAL) al volo (semplicemente un log shipping basato su record), tra un server master e uno o più server in standby. Questo protocollo non deve attendere il riempimento del file WAL, a differenza del log shipping basato su file. In pratica, un processo chiamato ricevitore WAL, in esecuzione sul server di standby, si connetterà al server primario utilizzando una connessione TCP/IP. Nel server primario esiste un altro processo denominato mittente WAL. Il suo ruolo è responsabile dell'invio dei registri WAL ai server di standby nel momento in cui si verificano.
Le configurazioni della replica asincrona nella replica in streaming possono incorrere in problemi come la perdita di dati o lo slave lag, quindi la versione 9.1 introduce la replica sincrona. Nella replica sincrona, ogni commit di una transazione di scrittura attende fino alla ricezione della conferma che il commit è stato scritto nel disco di registrazione write-ahead sia del server primario che di quello di standby. Questo metodo riduce al minimo la possibilità di perdita di dati, poiché affinché ciò accada avremo bisogno che entrambi, il master e lo standby si interrompano contemporaneamente.
L'ovvio svantaggio di questa configurazione è che il tempo di risposta per ogni transazione di scrittura aumenta, poiché dobbiamo aspettare che tutte le parti abbiano risposto. A differenza di MySQL, non c'è supporto come in un ambiente semi-sincrono di MySQL, se si verifica un timeout, verrà eseguito il failback in asincrono. Quindi, in Con PostgreSQL, il tempo per un commit è (almeno) il viaggio di andata e ritorno tra il primario e lo standby. Le transazioni di sola lettura non saranno interessate da ciò.
Man mano che si evolve, PostgreSQL migliora continuamente e tuttavia la sua replica è diversa. Ad esempio, è possibile utilizzare la replica asincrona del flusso fisico o utilizzare la replica del flusso logico. Entrambi sono monitorati in modo diverso sebbene utilizzino lo stesso approccio durante l'invio di dati tramite replica, che è ancora una replica in streaming. Per maggiori dettagli, controlla nel manuale i diversi tipi di soluzioni in PostgreSQL quando hai a che fare con la replica.
Cause del ritardo di replica di PostgreSQL
Come definito nel nostro blog precedente, un ritardo di replica è il costo del ritardo per le transazioni o operazioni calcolato dalla differenza di tempo di esecuzione tra il primario/master e lo standby/slave nodo.
Poiché PostgreSQL utilizza la replica in streaming, è progettato per essere veloce poiché le modifiche vengono registrate come un insieme di sequenze di record di registro (byte per byte) intercettati dal ricevitore WAL, quindi scrive questi record di registro al file WAL. Quindi il processo di avvio di PostgreSQL riproduce i dati da quel segmento WAL e inizia la replica in streaming. In PostgreSQL, un ritardo di replica può verificarsi a causa di questi fattori:
- Problemi di rete
- Impossibile trovare il segmento WAL dal primario. Di solito, ciò è dovuto al comportamento di checkpoint in cui i segmenti WAL vengono ruotati o riciclati
- Nodi occupati (primari e standby/i). Può essere causato da processi esterni o da alcune query errate causate da un uso intensivo di risorse
- Problemi hardware o hardware difettosi che causano un certo ritardo
- Configurazione scadente in PostgreSQL, ad esempio un piccolo numero di max_wal_senders impostato durante l'elaborazione di tonnellate di richieste di transazione (o un grande volume di modifiche).
Cosa cercare con il ritardo di replica di PostgreSQL
La replica PostgreSQL è ancora diversa, ma il monitoraggio dello stato della replica è sottile ma non complicato. In questo approccio mostreremo che si basano su una configurazione di standby primario con replica di streaming asincrona. La replica logica non può avvantaggiare la maggior parte dei casi che stiamo discutendo qui, ma la vista pg_stat_subscription può aiutarti a raccogliere informazioni. Tuttavia, non ci concentreremo su questo in questo blog.
Utilizzo della vista pg_stat_replication
L'approccio più comune consiste nell'eseguire una query che fa riferimento a questa vista nel nodo primario. Ricorda, puoi raccogliere informazioni solo dal nodo primario utilizzando questa vista. Questa vista contiene la seguente definizione di tabella basata su PostgreSQL 11 come mostrato di seguito:
postgres=# \d pg_stat_replication
View "pg_catalog.pg_stat_replication"
Column | Type | Collation | Nullable | Default
------------------+--------------------------+-----------+----------+---------
pid | integer | | |
usesysid | oid | | |
usename | name | | |
application_name | text | | |
client_addr | inet | | |
client_hostname | text | | |
client_port | integer | | |
backend_start | timestamp with time zone | | |
backend_xmin | xid | | |
state | text | | |
sent_lsn | pg_lsn | | |
write_lsn | pg_lsn | | |
flush_lsn | pg_lsn | | |
replay_lsn | pg_lsn | | |
write_lag | interval | | |
flush_lag | interval | | |
replay_lag | interval | | |
sync_priority | integer | | |
sync_state | text | | | Dove i campi sono definiti come (include PG <10 versione),
- pid :ID processo del processo walsender
- idsysid :OID dell'utente utilizzato per la replica in streaming.
- nome utente :Nome dell'utente utilizzato per la replica in streaming
- nome_applicazione :nome dell'applicazione collegata al master
- indirizzo_client :Indirizzo della replica in standby/streaming
- nome host_client :Nome host di standby.
- porta_client :numero di porta TCP su cui è in standby la comunicazione con il mittente WAL
- backend_start :Ora di inizio quando SR si è connesso al Master.
- backend_xmin :orizzonte xmin di standby riportato da hot_standby_feedback.
- stato :stato del mittente WAL corrente, ovvero streaming
- sent_lsn /posto_inviato :ultima posizione della transazione inviata in standby.
- write_lsn /scrivi_posizione :ultima transazione scritta su disco in standby
- flush_lsn /posizione_di_lavaggio :ultima transazione scaricata su disco in standby.
- replay_lsn /posizione_riproduzione :ultima transazione scaricata su disco in standby.
- write_lag :tempo trascorso durante il commit WAL dal primario allo standby (ma non ancora eseguito il commit in standby)
- flush_lag :tempo trascorso durante i WAL impegnati dal primario allo standby (i WAL sono già stati scaricati ma non ancora applicati)
- replay_lag :tempo trascorso durante il commit WAL dal primario allo standby (committo completamente nel nodo standby)
- priorità_sincronizzazione :Priorità del server di standby scelto come standby sincrono
- stato_sincronizzazione :Sync Stato di standby (è asincrono o sincrono).
Una query di esempio avrebbe il seguente aspetto in PostgreSQL 9.6,
paultest=# select * from pg_stat_replication;
-[ RECORD 1 ]----+------------------------------
pid | 7174
usesysid | 16385
usename | cmon_replication
application_name | pgsql_1_node_1
client_addr | 192.168.30.30
client_hostname |
client_port | 10580
backend_start | 2020-02-20 18:45:52.892062+00
backend_xmin |
state | streaming
sent_location | 1/9FD5D78
write_location | 1/9FD5D78
flush_location | 1/9FD5D78
replay_location | 1/9FD5D78
sync_priority | 0
sync_state | async
-[ RECORD 2 ]----+------------------------------
pid | 7175
usesysid | 16385
usename | cmon_replication
application_name | pgsql_80_node_2
client_addr | 192.168.30.20
client_hostname |
client_port | 60686
backend_start | 2020-02-20 18:45:52.899446+00
backend_xmin |
state | streaming
sent_location | 1/9FD5D78
write_location | 1/9FD5D78
flush_location | 1/9FD5D78
replay_location | 1/9FD5D78
sync_priority | 0
sync_state | asyncQuesto fondamentalmente ti dice quali blocchi di posizione nei segmenti WAL sono stati scritti, cancellati o applicati. Fornisce una panoramica dettagliata dello stato della replica.
Query da utilizzare nel nodo standby
Nel nodo standby, ci sono funzioni supportate per le quali puoi mitigarle in una query e fornire una panoramica dello stato della tua replica standby. Per fare ciò, puoi eseguire la seguente query di seguito (la query è basata sulla versione PG> 10),
postgres=# select pg_is_in_recovery(),pg_is_wal_replay_paused(), pg_last_wal_receive_lsn(), pg_last_wal_replay_lsn(), pg_last_xact_replay_timestamp();
-[ RECORD 1 ]-----------------+------------------------------
pg_is_in_recovery | t
pg_is_wal_replay_paused | f
pg_last_wal_receive_lsn | 0/2705BDA0
pg_last_wal_replay_lsn | 0/2705BDA0
pg_last_xact_replay_timestamp | 2020-02-21 02:18:54.603677+00Nelle versioni precedenti, puoi utilizzare la seguente query:
postgres=# select pg_is_in_recovery(),pg_last_xlog_receive_location(), pg_last_xlog_replay_location(), pg_last_xact_replay_timestamp();
-[ RECORD 1 ]-----------------+------------------------------
pg_is_in_recovery | t
pg_last_xlog_receive_location | 1/9FD6490
pg_last_xlog_replay_location | 1/9FD6490
pg_last_xact_replay_timestamp | 2020-02-21 08:32:40.485958-06Cosa dice la query? Le funzioni sono definite di conseguenza qui,
- pg_is_in_recovery ():(booleano) Vero se il ripristino è ancora in corso.
- pg_last_wal_receive_lsn ()/pg_last_xlog_receive_location(): (pg_lsn) Il percorso del registro write-ahead ricevuto e sincronizzato su disco tramite la replica in streaming.
- pg_last_wal_replay_lsn ()/pg_last_xlog_replay_location(): (pg_lsn) L'ultima posizione del registro write-ahead riprodotta durante il ripristino. Se il recupero è ancora in corso, aumenterà in modo monotono.
- pg_last_xact_replay_timestamp (): (timestamp con fuso orario) Ottieni il timestamp dell'ultima transazione riprodotta durante il ripristino.
Utilizzando un po' di matematica di base, puoi combinare queste funzioni. Le funzioni più comuni utilizzate dai DBA sono,
SELECT CASE WHEN pg_last_wal_receive_lsn() = pg_last_wal_replay_lsn()
THEN 0
ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
END AS log_delay;
o nelle versioni PG <10,
SELECT CASE WHEN pg_last_xlog_receive_location() = pg_last_xlog_replay_location()
THEN 0
ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
END AS log_delay;Sebbene questa query sia stata praticata e sia utilizzata dai DBA. Tuttavia, non fornisce una visione accurata del ritardo. Come mai? Ne parliamo nella prossima sezione.
Identificazione del ritardo causato dall'assenza del segmento WAL
I nodi di standby PostgreSQL, che sono in modalità di ripristino, non ti segnalano lo stato esatto di ciò che sta accadendo alla tua replica. A meno che non visualizzi il registro PG, puoi raccogliere informazioni su ciò che sta accadendo. Non ci sono query che puoi eseguire per determinarlo. Nella maggior parte dei casi, le organizzazioni e anche le piccole istituzioni escogitano software di terze parti per consentire loro di essere avvisati quando viene lanciato un allarme.
Uno di questi è ClusterControl, che ti offre osservabilità, invia avvisi quando vengono generati allarmi o ripristina il tuo nodo in caso di disastro o catastrofe. Prendiamo questo scenario, il mio cluster di replica di streaming asincrono di standby primario non è riuscito. Come faresti a sapere se qualcosa non va? Uniamo quanto segue:
Passaggio 1:determina se c'è un ritardo
postgres=# SELECT CASE WHEN pg_last_wal_receive_lsn() = pg_last_wal_replay_lsn()
postgres-# THEN 0
postgres-# ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
postgres-# END AS log_delay;
-[ RECORD 1 ]
log_delay | 0Fase 2:determina i segmenti WAL ricevuti dal nodo principale e confrontali con il nodo standby
## Get the master's current LSN. Run the query below in the master
postgres=# SELECT pg_current_wal_lsn();
-[ RECORD 1 ]------+-----------
pg_current_wal_lsn | 0/925D7E70Per le versioni precedenti di PG <10, usa pg_current_xlog_location.
## Get the current WAL segments received (flushed or applied/replayed)
postgres=# select pg_is_in_recovery(),pg_is_wal_replay_paused(), pg_last_wal_receive_lsn(), pg_last_wal_replay_lsn(), pg_last_xact_replay_timestamp();
-[ RECORD 1 ]-----------------+------------------------------
pg_is_in_recovery | t
pg_is_wal_replay_paused | f
pg_last_wal_receive_lsn | 0/2705BDA0
pg_last_wal_replay_lsn | 0/2705BDA0
pg_last_xact_replay_timestamp | 2020-02-21 02:18:54.603677+00Sembra che non vada bene.
Fase 3:determina quanto potrebbe essere grave
Ora, mescoliamo la formula dal punto 1 al punto 2 e otteniamo la differenza. Come fare questo, PostgreSQL ha una funzione chiamata pg_wal_lsn_diff che è definita come,
pg_wal_lsn_diff(lsn pg_lsn, lsn pg_lsn) / pg_xlog_location_diff (posizione pg_lsn, posizione pg_lsn): (numerico) Calcola la differenza tra due posizioni del registro write-ahead
Ora usiamolo per determinare il ritardo. Puoi eseguirlo in qualsiasi nodo PG, poiché forniremo solo i valori statici:
postgres=# select pg_wal_lsn_diff('0/925D7E70','0/2705BDA0'); -[ RECORD 1 ]---+-----------
pg_wal_lsn_diff | 1800913104Stimiamo quanto è 1800913104, che sembra essere circa 1,6 GiB potrebbe essere stato assente nel nodo standby,
postgres=# select round(1800913104/pow(1024,3.0),2) missing_lsn_GiB;
-[ RECORD 1 ]---+-----
missing_lsn_gib | 1.68Infine, puoi procedere o anche prima della query guardare i log come usare tail -5f per seguire e controllare cosa sta succedendo. Eseguire questa operazione per entrambi i nodi primari/di standby. In questo esempio, vedremo che ha un problema,
## Primary
example@sqldat.com:/var/lib/postgresql/11/main# tail -5f log/postgresql-2020-02-21_033512.log
2020-02-21 16:44:33.574 UTC [25023] ERROR: requested WAL segment 000000030000000000000027 has already been removed
...
## Standby
example@sqldat.com:/var/lib/postgresql/11/main# tail -5f log/postgresql-2020-02-21_014137.log
2020-02-21 16:45:23.599 UTC [26976] LOG: started streaming WAL from primary at 0/27000000 on timeline 3
2020-02-21 16:45:23.599 UTC [26976] FATAL: could not receive data from WAL stream: ERROR: requested WAL segment 000000030000000000000027 has already been removed
...Quando si verifica questo problema, è meglio ricostruire i nodi di standby. In ClusterControl è facile come un clic. Vai alla sezione Nodi/Topologia e ricostruisci il nodo proprio come di seguito:
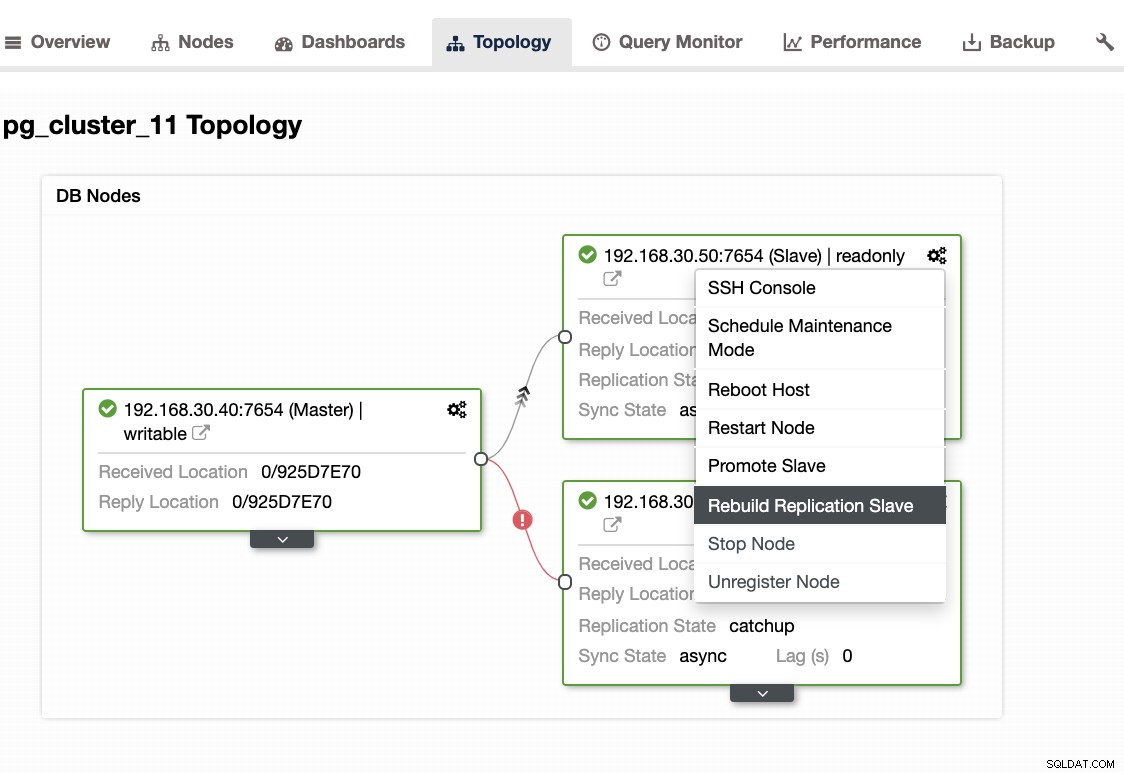
Altre cose da controllare
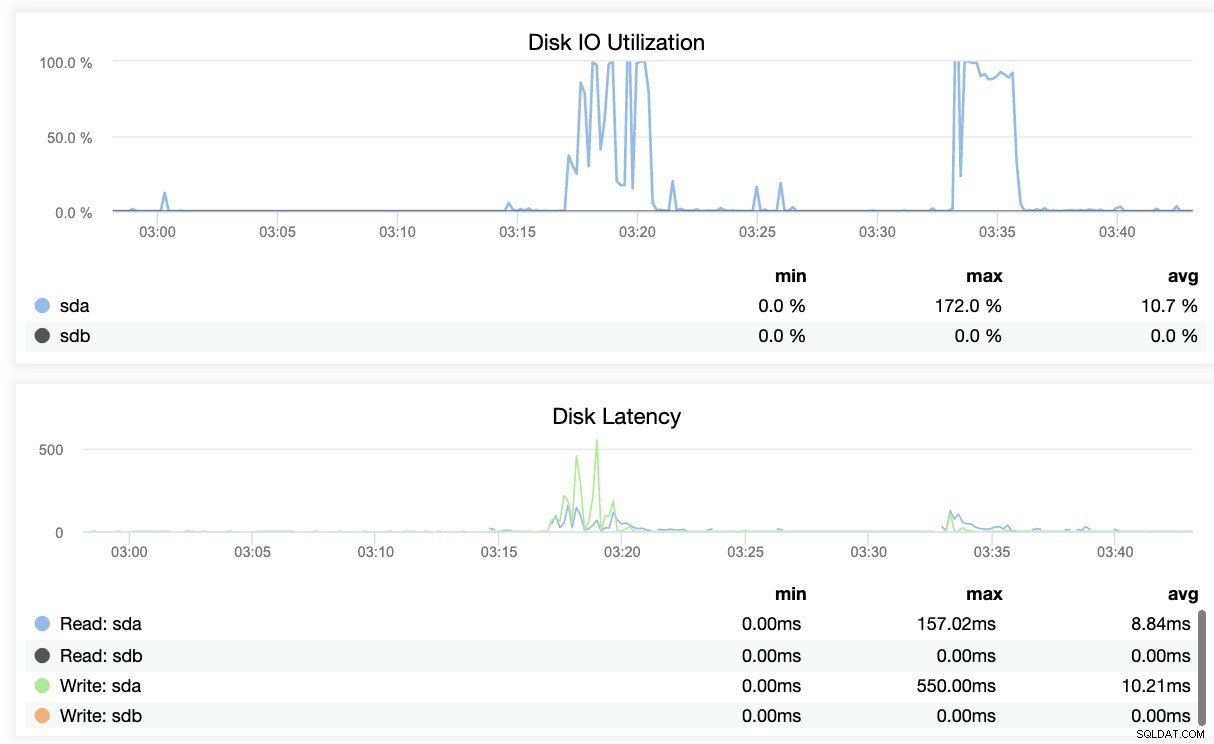
Puoi usare lo stesso approccio nel nostro blog precedente (in MySQL), usando strumenti di sistema come ps, top, iostat, netstat combination. Ad esempio, puoi anche ottenere il segmento WAL recuperato corrente dal nodo di standby,
example@sqldat.com:/var/lib/postgresql/11/main# ps axufwww|egrep "postgre[s].*startup"
postgres 8065 0.0 8.3 715820 170872 ? Ss 01:41 0:03 \_ postgres: 11/main: startup recovering 000000030000000000000027Come può essere d'aiuto ClusterControl?
ClusterControl offre un modo efficiente per monitorare i nodi del database dai nodi primari a quelli slave. Quando vai alla scheda Panoramica, hai già la visualizzazione dello stato della tua replica:
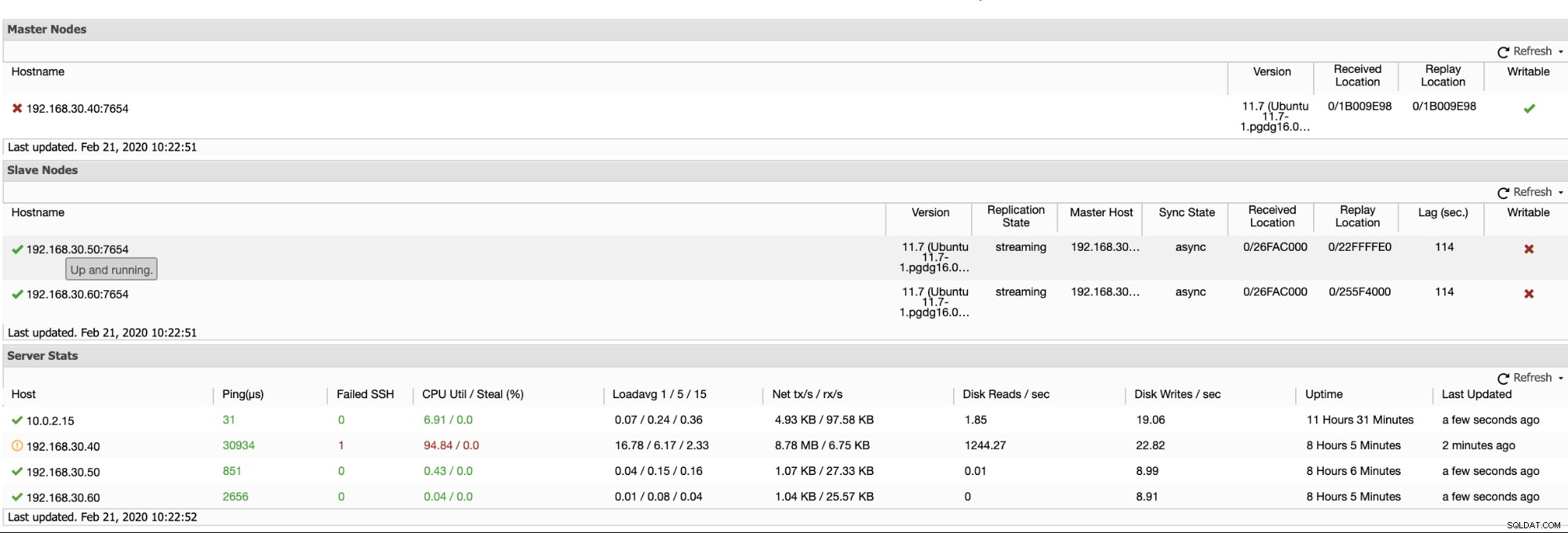
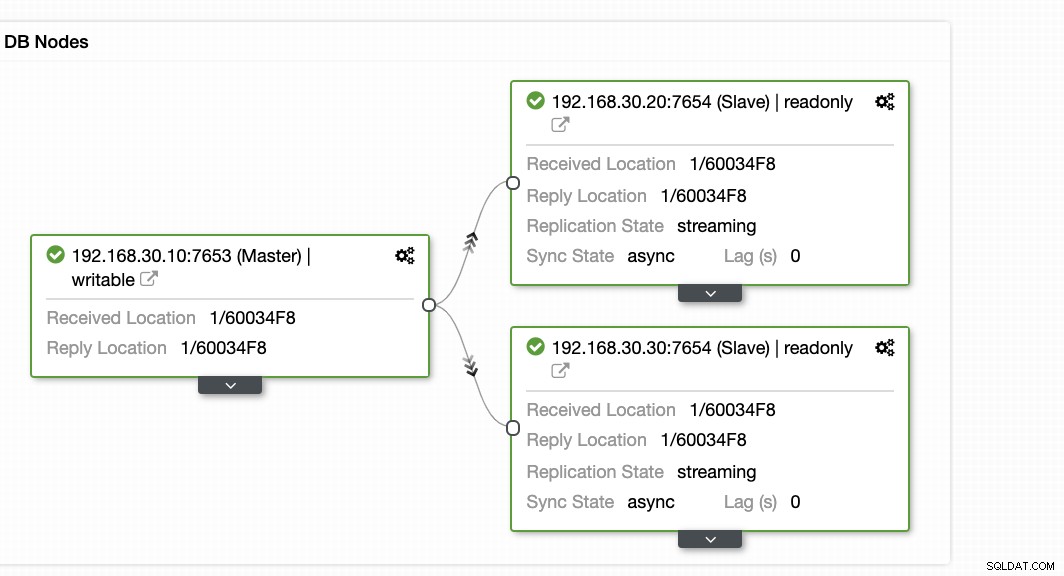
Fondamentalmente, i due screenshot qui sopra mostrano come è lo stato della replica e qual è l'attuale segmenti WAL. Non è affatto. ClusterControl mostra anche l'attività corrente di ciò che sta accadendo con il tuo Cluster.
Conclusione
Il monitoraggio dell'integrità della replica in PostgreSQL può finire con un approccio diverso purché tu sia in grado di soddisfare le tue esigenze. L'utilizzo di strumenti di terze parti con osservabilità in grado di avvisarti in caso di catastrofe è la tua strada perfetta, sia open source che aziendale. La cosa più importante è che tu abbia pianificato il tuo piano di ripristino di emergenza e la continuità aziendale prima di tali problemi.