[ Parte 1 | Parte 2 | Parte 3]
Nella parte 1, ho mostrato come sia la compressione della pagina che quella del columnstore possono ridurre le dimensioni di una tabella da 1 TB dell'80% o più. Sebbene fossi impressionato di poter ridurre una tabella da 1 TB a 50 GB, non ero molto soddisfatto del tempo impiegato (da 2 a 14 ore). Con alcuni suggerimenti gentilmente presi in prestito da persone come Joe Obbish, Lonny Niederstadt, Niko Neugebauer e altri, in questo post cercherò di apportare alcune modifiche al mio tentativo originale di ottenere prestazioni di carico migliori. Poiché il normale indice columnstore non è stato compresso meglio della compressione della pagina su questo set di dati e ci sono volute 13 ore in più per arrivarci, mi concentrerò esclusivamente sulla soluzione più avanzata utilizzando COLUMNSTORE_ARCHIVE compressione.
Alcuni dei problemi che penso abbiano influito sulle prestazioni includono quanto segue:
- Scelte di layout file errate – Ho inserito 8 file in un filegroup, con parallelismo ma senza partizionamento (o non ottimale), spruzzando I/O su più file con abbandono sconsiderato. Per risolvere questo problema, farò:
- partizionare la tabella in 8 partizioni (una per core)
- metti il file di dati di ciascuna partizione nel proprio filegroup
- utilizza 8 processi separati per l'affinità a ciascuna partizione
- usa la compressione dell'archivio su tutte le partizioni tranne quella "attiva"
- troppi batch piccoli e popolazione di rowgroup non ottimale – elaborando 10 milioni di righe alla volta, stavo popolando nove gruppi di righe con ben 1.048.576 righe, quindi le restanti 562.816 righe sarebbero finite in un altro gruppo di righe più piccolo. E qualsiasi distribuzione irregolare che lasciasse un resto <102.400 righe introdurrebbe gli inserti nella struttura del negozio delta meno efficiente. Per distribuire le righe in modo più uniforme ed evitare il delta store, farò:
- elabora quanti più dati possibile in multipli esatti di 1.048.576 righe
- distribuiscili su 8 partizioni nel modo più uniforme possibile
- utilizza una dimensione batch più vicina a 10x -> 100 milioni di righe
- impilamento del programmatore – anche se non l'ho verificato, è possibile che parte del rallentamento sia stato causato da uno scheduler che ha assunto troppo lavoro e un altro scheduler non abbastanza, a causa del round-robining dello scheduler. Ora che caricherò intenzionalmente i dati con 8 processi maxdop 1 invece di un processo maxdop 8, per mantenere tutti gli scheduler ugualmente occupati, farò:
- utilizzare una procedura memorizzata che tenti di bilanciare in modo uniforme tra gli scheduler (vedere le pagine 189-191 nella Guida di SQLCAT a:motore relazionale per l'ispirazione dietro questa idea)
- abilita il flag di traccia globale 2467 e 2469, come messo in guardia nella documentazione
- attività di compressione columnstore in background – è stato uno spreco permettere che questo funzionasse durante la popolazione, dal momento che avevo comunque pianificato di ricostruire alla fine. Questa volta farò:
- disabilita questa attività utilizzando il flag di traccia globale 634
Ho scartato la funzione e lo schema di partizione iniziali e ne ho creato uno nuovo basato su una distribuzione più uniforme dei dati. Voglio che 8 partizioni corrispondano al numero di core e al numero di file di dati, per massimizzare il "poveri parallelismi" che intendo utilizzare.
Per prima cosa, dobbiamo creare un nuovo set di filegroup, ognuno con il proprio file:
ALTER DATABASE OCopy ADD FILEGROUP FG_CCI_Part1; ALTER DATABASE OCopy ADD FILE (name = N'CCI_Part_1', size = 250000, filename = 'K:\Data\o_cci_p_1.mdf') TO FILEGROUP FG_CCI_Part1; -- ... 6 more ... ALTER DATABASE OCopy ADD FILEGROUP FG_CCI_Part8; ALTER DATABASE OCopy ADD FILE (name = N'CCI_Part_8', size = 250000, filename = 'K:\Data\o_cci_p_8.mdf') TO FILEGROUP FG_CCI_Part8;
Successivamente, ho esaminato il numero di righe nella tabella:3.754.965.954. Per distribuirli esattamente uniformemente su 8 partizioni, sarebbero 469.370.744,25 righe per partizione. Per farlo funzionare correttamente, facciamo in modo che i limiti della partizione si adattino al successivo multiplo di 1.048.576 righe. Questo è 1,048,576 x 448 = 469,762,048 – quale sarebbe il numero di righe per le quali spariamo nelle prime 7 partizioni, lasciando 466.631.618 righe nell'ultima partizione. Per vedere l'effettivo OID valori che servirebbero da limiti per contenere il numero ottimale di righe in ciascuna partizione, ho eseguito questa query sulla tabella originale (poiché ci sono voluti 25 minuti per l'esecuzione, ho imparato rapidamente a scaricare questi risultati in una tabella separata):
;WITH x AS
(
SELECT OID, rn = ROW_NUMBER() OVER (ORDER BY OID)
FROM dbo.tblOriginal WITH (NOLOCK)
)
SELECT OID, PartitionID = 1+(rn/((1048576*448)+1))
INTO dbo.stage
FROM x
WHERE rn % (1048576*112) = 0;
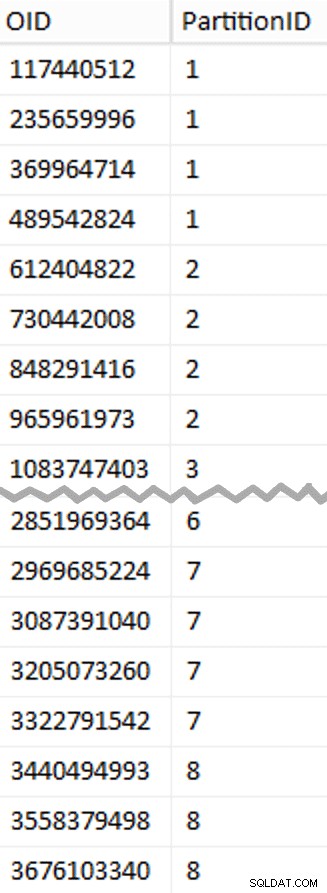 Più da decomprimere qui di quanto potresti aspettarti. Il CTE fa tutto il lavoro pesante, dal momento che deve scansionare l'intera tabella da 1,14 TB e assegnare un numero di riga a ogni riga . Voglio restituire solo ogni
Più da decomprimere qui di quanto potresti aspettarti. Il CTE fa tutto il lavoro pesante, dal momento che deve scansionare l'intera tabella da 1,14 TB e assegnare un numero di riga a ogni riga . Voglio restituire solo ogni (1048576*112)th riga, tuttavia, poiché queste sono le mie righe limite del batch, quindi questo è ciò che il WHERE clausola lo fa. Ricorda che voglio dividere il lavoro in batch più vicini a 100 milioni di righe alla volta, ma non voglio nemmeno elaborare 469 milioni di righe in un colpo solo. Quindi, oltre a dividere i dati in 8 partizioni, voglio dividere ciascuna di queste partizioni in quattro batch di 117.440.512 (1,048,576*112) righe. Ogni insieme adiacente di quattro batch appartiene a una partizione, quindi PartitionID I derivare aggiunge solo uno al risultato del numero di riga corrente intero diviso per (1,048,576*448) , che assicura che il confine sia sempre nell'insieme "sinistra". Quindi ne aggiungiamo uno al risultato perché altrimenti ci riferiremmo a una raccolta di partizioni basata su 0 e nessuno lo vuole.
Ok, erano molte parole. A destra c'è un'immagine che mostra il contenuto (abbreviato) dello stage tabella (fare clic per mostrare il risultato completo, evidenziando i valori limite della partizione).
Possiamo quindi derivare un'altra query da quella tabella di staging che ci mostra i valori minimo e massimo per ogni batch all'interno di ogni partizione, così come il batch aggiuntivo non contabilizzato (le righe nella tabella originale con OID maggiore del valore limite più alto):
;WITH x AS
(
SELECT OID, PartitionID FROM dbo.stage
),
y AS
(
SELECT PartitionID,
MinID = COALESCE(LAG(OID,1) OVER (ORDER BY OID),-1)+1,
MaxID = OID
FROM x
UNION ALL
SELECT PartitionID = 8,
MinID = MAX(OID)+1,
MaxID = 4000000000 -- easier than remembering the real max
FROM x
)
SELECT PartitionID,
BatchID = ROW_NUMBER() OVER (PARTITION BY PartitionID ORDER BY MinID),
MinID,
MaxID,
RowsInRange = CONVERT(int, NULL)
INTO dbo.BatchQueue
FROM y;
-- let's not leave this as a heap:
CREATE UNIQUE CLUSTERED INDEX PK_bq ON dbo.BatchQueue(PartitionID, BatchID); Questi valori sono simili a questo:
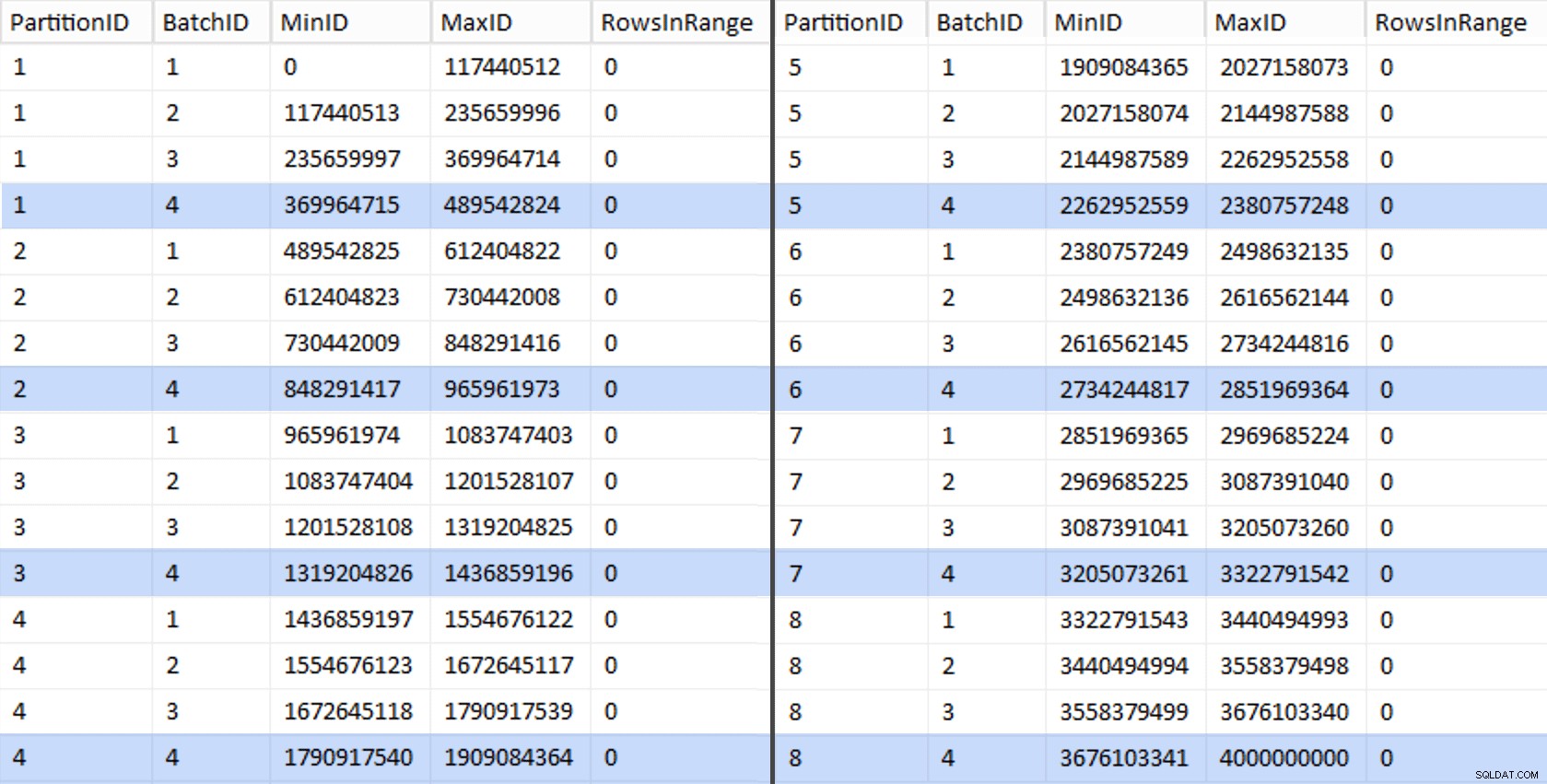
Per testare il nostro lavoro, possiamo ricavare da lì una serie di query che aggiorneranno BatchQueue con i conteggi di righe effettivi dalla tabella.
DECLARE @sql nvarchar(max) = N'';
SELECT @sql += 'UPDATE dbo.BatchQueue SET RowsInRange = (
SELECT COUNT(*)
FROM dbo.tblOriginal WITH (NOLOCK)
WHERE CostID BETWEEN ' + RTRIM(MinID) + ' AND ' + RTRIM(MaxID) + '
) WHERE MinID = ' + RTRIM(MinID) + ' AND MaxID = ' + RTRIM(MaxID) + ';'
FROM dbo.BatchQueue;
EXEC sys.sp_executesql @sql; Ci sono voluti circa 6 minuti sul mio sistema. Quindi puoi eseguire la seguente query per mostrare che ogni batch tranne l'ultimo è in grado di popolare completamente i gruppi di righe e non lasciare resto per il potenziale utilizzo del delta store:
ALTER TABLE dbo.BatchQueue ADD DeltaStore AS (RowsInRange % 1048576);
Ora la tabella si presenta così:
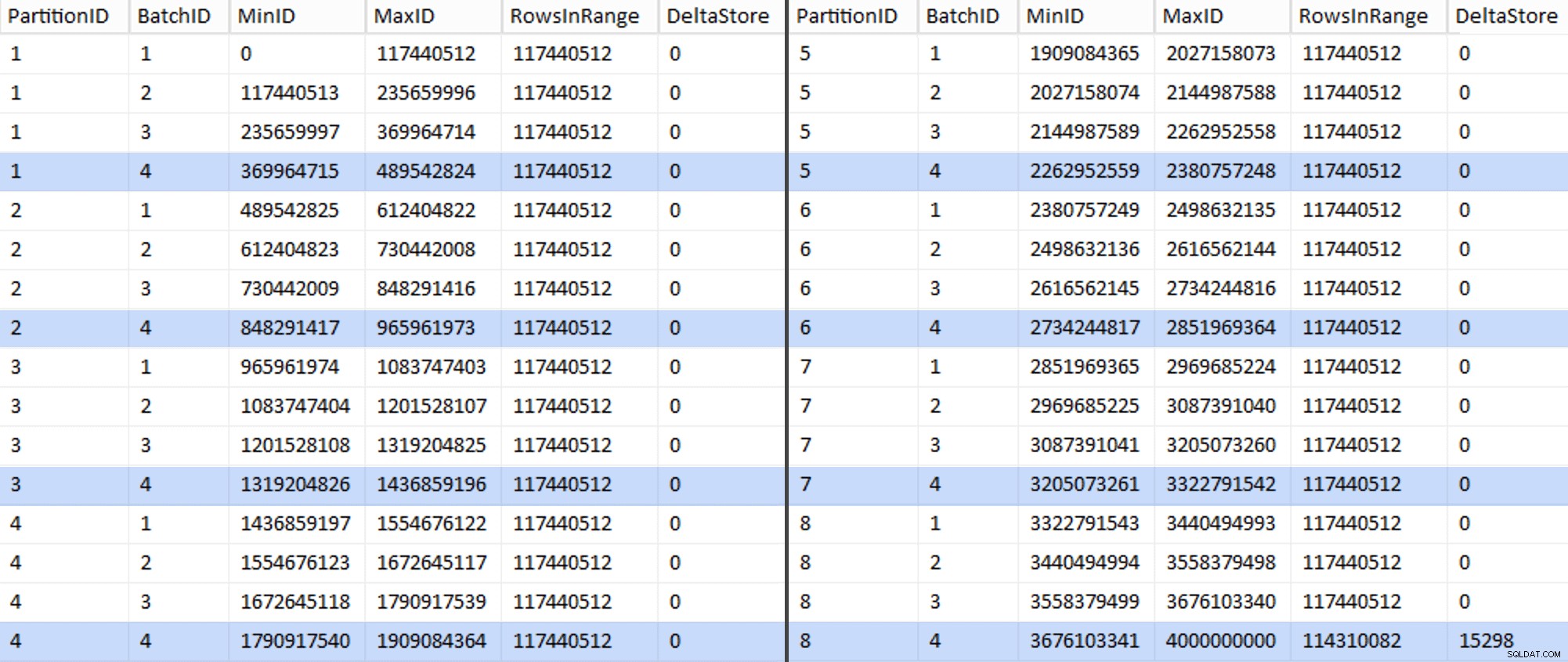
Abbastanza sicuro, ogni batch ha i 117.440.512 milioni di righe calcolate, ad eccezione dell'ultima che, almeno idealmente, conterrà il nostro unico archivio delta non compresso. Probabilmente possiamo prevenire anche questo, modificando leggermente la dimensione del batch per questa partizione in modo che tutti e quattro i batch vengano eseguiti con la stessa dimensione o modificando il numero di batch per ospitare un altro multiplo di 102.400 o 1.048.576. Dal momento che ciò richiederebbe l'ottenimento di un nuovo OID valori dalla tabella di base, aggiungendo altri 25 minuti in più al nostro sforzo di migrazione, lascerò scorrere questa partizione imperfetta, soprattutto perché non ne trarremo comunque il vantaggio completo della compressione dell'archivio.
La BatchQueue table sta iniziando a mostrare segni di utilità per l'elaborazione dei nostri batch per la migrazione dei dati alla nostra nuova tabella columnstore partizionata e in cluster. Che dobbiamo creare, ora che conosciamo i confini. Ci sono solo 7 limiti, quindi potresti sicuramente farlo manualmente, ma mi piace che SQL dinamico faccia il mio lavoro per me:
DECLARE @sql nvarchar(max) = N'';
SELECT @sql = N'CREATE PARTITION FUNCTION PF_OID([bigint])
AS RANGE LEFT FOR VALUES
(
' + STRING_AGG(MaxID, ',
') + '
);' FROM dbo.BatchQueue
WHERE PartitionID < 8
AND BatchID = 4;
PRINT @sql;
-- EXEC sys.sp_executesql @sql; Risultati:
CREATE PARTITION FUNCTION PF_OID([bigint]) AS RANGE LEFT FOR VALUES ( 489542824, 965961973, 1436859196, 1909084364, 2380757248, 2851969364, 3322791542 );
Una volta creato, possiamo creare il nostro schema di partizione e assegnare ogni partizione successiva al suo file dedicato:
CREATE PARTITION SCHEME PS_OID AS PARTITION PF_OID TO ( CCI_Part1, CCI_Part2, CCI_Part3, CCI_Part4, CCI_Part5, CCI_Part6, CCI_Part7, CCI_Part8 );
Ora possiamo creare la tabella e prepararla per la migrazione:
CREATE TABLE dbo.tblPartitionedCCI ( OID bigint NOT NULL, IN1 int NOT NULL, IN2 int NOT NULL, VC1 varchar(3) NULL, BI1 bigint NULL, IN3 int NULL, VC2 varchar(128) NOT NULL, VC3 varchar(128) NOT NULL, VC4 varchar(128) NULL, NM1 numeric(24,12) NULL, NM2 numeric(24,12) NULL, NM3 numeric(24,12) NULL, BI2 bigint NULL, IN4 int NULL, BI3 bigint NULL, NM4 numeric(24,12) NULL, IN5 int NULL, NM5 numeric(24,12) NULL, DT1 date NULL, VC5 varchar(128) NULL, BI4 bigint NULL, BI5 bigint NULL, BI6 bigint NULL, BT1 bit NOT NULL, NV1 nvarchar(512) NULL, VB1 varbinary(8000) NULL, IN6 int NULL, IN7 int NULL, IN8 int NULL, -- need to create a PK constraint on the partition scheme... CONSTRAINT PK_CCI_Part PRIMARY KEY CLUSTERED (OID) ON PS_OID(OID) ); -- ... only to drop it immediately... ALTER TABLE dbo.tblPartitionedCCI DROP CONSTRAINT PK_CCI_Part; GO -- ... so we can replace it with the CCI: CREATE CLUSTERED COLUMNSTORE INDEX CCI_Part ON dbo.tblPartitionedCCI ON PS_OID(OID); GO -- now rebuild with the compression we want: ALTER TABLE dbo.tblPartitionedCCI REBUILD PARTITION = ALL WITH ( DATA_COMPRESSION = COLUMNSTORE_ARCHIVE ON PARTITIONS (1 TO 7), DATA_COMPRESSION = COLUMNSTORE ON PARTITIONS (8) );
Nella parte 3, configurerò ulteriormente il BatchQueue tabella, creare una procedura per i processi per inviare i dati alla nuova struttura e analizzare i risultati.
[ Parte 1 | Parte 2 | Parte 3]