[ Parte 1 | Parte 2 | Parte 3]
Recentemente qualcuno al lavoro ha chiesto più spazio per ospitare un tavolo in rapida crescita. All'epoca aveva 3,75 miliardi di righe, presentate su 143 milioni di pagine e occupavano circa 1,14 TB. Ovviamente possiamo sempre lanciare più disco su un tavolo, ma volevo vedere se potevamo ridimensionarlo in modo più efficiente rispetto all'attuale tendenza lineare. Sembra un ottimo lavoro per la compressione, giusto? Ma volevo anche provare altre soluzioni, incluso columnstore, che le persone sono sorprendentemente riluttanti a provare. Non sono Niko, ma volevo fare uno sforzo per vedere cosa potrebbe fare per noi qui.
Tieni presente che al momento non mi sto concentrando sul reporting del carico di lavoro o su altre prestazioni delle query di lettura:voglio semplicemente vedere quale impatto posso avere sull'impronta di archiviazione (e memoria) di questi dati.
Ecco la tabella originale. Ho cambiato i nomi di tabelle e colonne per proteggere gli innocenti, ma tutto il resto è relativamente accurato.
CREATE TABLE dbo.tblOriginal
(
OID bigint IDENTITY(1,1) NOT NULL PRIMARY KEY, -- there are gaps!
IN1 int NOT NULL,
IN2 int NOT NULL,
VC1 varchar(3) NULL,
BI1 bigint NULL,
IN3 int NULL,
VC2 varchar(128) NOT NULL,
VC3 varchar(128) NOT NULL,
VC4 varchar(128) NULL,
NM1 numeric(24,12) NULL,
NM2 numeric(24,12) NULL,
NM3 numeric(24,12) NULL,
BI2 bigint NULL,
IN4 int NULL,
BI3 bigint NULL,
NM4 numeric(24,12) NULL,
IN5 int NULL,
NM5 numeric(24,12) NULL,
DT1 date NULL,
VC5 varchar(128) NULL,
BI4 bigint NULL,
BI5 bigint NULL,
BI6 bigint NULL,
BT1 bit NOT NULL,
NV1 nvarchar(512) NULL,
VB1 AS (HASHBYTES('MD5',VC2+VC3)),
IN6 int NULL,
IN7 int NULL,
IN8 int NULL
);
Ci sono altre piccole cose lì dentro che sono più larghe di quanto dovrebbero essere e/o che la compressione delle righe potrebbe ripulire, come quelle numeric(24,12) e bigint colonne che potrebbero essere sovradimensionate prematuramente, ma non tornerò al team dell'applicazione e scoprirò se ci sono piccole efficienze lì, e salterò la compressione delle righe per questo esercizio e mi concentrerò sulla compressione della pagina e del columnstore.
Questa è una copia dei dati, su un server inattivo (8 core, 64 GB di RAM), con molto spazio su disco (ben oltre 6 TB). Quindi, per prima cosa, aggiungiamo un paio di filegroup, uno per il columnstore cluster standard e uno per una versione partizionata della tabella (dove tutta la partizione tranne la più recente verrà compressa con COLUMNSTORE_ARCHIVE , dal momento che tutti i dati più vecchi ora sono "solamente letti e di rado"):
ALTER DATABASE OCopy ADD FILEGROUP FG_CCI; ALTER DATABASE OCopy ADD FILEGROUP FG_CCI_PARTITIONED;
E poi alcuni file per questi filegroup (un file per core, bello e di dimensioni uniformi a 256 GB):
ALTER DATABASE OCopy ADD FILE (name = N'CCI_1', size = 250000, filename = 'K:\Data\o_cci_1.mdf') TO FILEGROUP FG_CCI; -- ... 6 more ... ALTER DATABASE OCopy ADD FILE (name = N'CCI_8', size = 250000, filename = 'K:\Data\o_cci_8.mdf') TO FILEGROUP FG_CCI; ALTER DATABASE OCopy ADD FILE (name = N'CCI_P_1', size = 250000, filename = 'K:\Data\o_p_1.mdf') TO FILEGROUP FG_CCI_PARTITIONED; -- ... 6 more ... ALTER DATABASE OCopy ADD FILE (name = N'CCI_P_8', size = 250000, filename = 'K:\Data\o_p_8.mdf') TO FILEGROUP FG_CCI_PARTITIONED;
Su questo particolare hardware (YMMV!), ci sono voluti circa 10 secondi per file e ha prodotto quanto segue:
Per generare le partizioni, ho ingenuamente diviso i dati "in modo uniforme" - o almeno così pensavo. Ho appena preso i 3,75 miliardi di righe e ho partizionato in qualcosa che pensavo sarebbe gestibile:38 partizioni con 100 milioni di righe nelle prime 37 partizioni e il resto nell'ultima. (Ricorda, questa è solo la parte 1! C'è un presupposto intrinseco qui sulla distribuzione uniforme dei valori nella tabella di origine e anche su ciò che è ottimale per la popolazione del gruppo di righe nella tabella di destinazione.) La creazione dello schema di partizione e della funzione per questo è come segue:
CREATE PARTITION FUNCTION PF_OID([bigint]) AS RANGE LEFT FOR VALUES (100000000, 200000000, /* ... 33 more ... */ , 3600000000, 3700000000); CREATE PARTITION SCHEME PS_OID AS PARTITION PF_OID ALL TO (FG_CCI_PARTITIONED);
Uso RANGE LEFT perché, come continua a ricordarmi Cathrine Wilhelmsen, ciò significa che il valore di confine è una parte della partizione alla sua sinistra. In altre parole, i valori che sto specificando sono i valori massimi in ciascuna partizione (con le date, di solito vuoi RANGE RIGHT ).
Ho quindi creato due copie della tabella, una su ciascun filegroup. Il primo aveva un indice columnstore cluster standard, l'unica differenza era l'OID la colonna non è un IDENTITY e la colonna calcolata è solo un varbinary(8000) :
CREATE TABLE dbo.tblCCI ( OID bigint NOT NULL, -- ... other columns ... ) ON FG_CCI; GO CREATE CLUSTERED COLUMNSTORE INDEX CCI_IX ON dbo.tblCCI;
Il secondo è stato costruito sullo schema di partizione, quindi era necessario prima un PK denominato, che poi doveva essere sostituito da un indice columnstore cluster (sebbene Brent Ozar mostri in questo breve post che esiste una sintassi non intuitiva che lo farà in meno passaggi ):
CREATE TABLE dbo.tblCCI_Partitioned ( OID bigint NOT NULL, -- ... other columns ..., CONSTRAINT PK_CCI_Part PRIMARY KEY CLUSTERED (OID) ON PS_OID (OID) ); GO ALTER TABLE dbo.tblCCI_Partitioned DROP CONSTRAINT PK_CCI_Part; GO CREATE CLUSTERED COLUMNSTORE INDEX CCI_Part ON dbo.tblCCI_Partitioned ON PS_OID (OID);
Quindi, per inserire la compressione dell'archivio su tutte le partizioni tranne l'ultima, ho eseguito quanto segue:
ALTER TABLE dbo.tblCCI_Part
REBUILD PARTITION = ALL WITH
(
DATA_COMPRESSION = COLUMNSTORE ON PARTITIONS (38),
DATA_COMPRESSION = COLUMNSTORE_ARCHIVE ON PARTITIONS (1 TO 37)
); Ora, ero pronto per popolare queste tabelle con i dati, misurare il tempo impiegato e la dimensione risultante e confrontare. Ho modificato un utile script di batching di Andy Mallon e ho inserito le righe in entrambe le tabelle in sequenza, con una dimensione batch di 10 milioni di righe. C'è molto di più nello script reale (incluso l'aggiornamento di una tabella di coda con l'avanzamento), ma fondamentalmente:
DECLARE @BatchSize int = 10000000, @MaxID bigint, @LastID bigint = 0;
SELECT @MaxID = MAX(OID) FROM dbo.tblOriginal;
WHILE @LastID < @MaxID
BEGIN
INSERT dbo.tblCCI
(
-- all columns except the computed column
)
SELECT -- all columns except the computed column
FROM dbo.tblOriginal AS o
WHERE o.CostID >= @LastID
AND o.CostID < @LastID + @BatchSize;
SET @LastID += @BatchSize;
END Dopo aver popolato entrambe le tabelle columnstore dall'origine originale (non compressa), ho ricostruito nuovamente quelle partizioni per ripulire qualsiasi gruppo di righe e confusione del dizionario. Infine, ho applicato la compressione della pagina, sul posto, alla tabella di origine. Ecco i tempi e i risultati di compressione di ogni tipo:
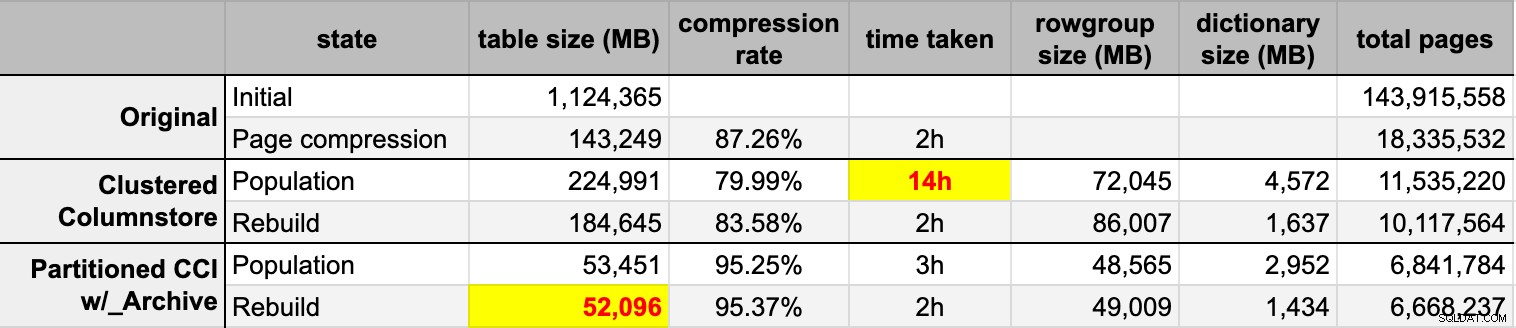
Sono sia impressionato che deluso. Impressionato perché questi dati si comprimono molto bene – ridurre l'ingombro dello storage fino al 5% dell'originale 1 TB è sorprendente. Deluso perché:
- Non ho osservato alcuna pressione di memoria o registro.
- Non si sono verificati eventi di crescita del file.
- Purtroppo non pensavo di tenere traccia delle attese. No, non ho intenzione di riprovare. :-)
Nei prossimi post, e dopo aver esaminato i miei appunti da un'incredibile presentazione del columnstore di Joe Obbish al PASS Summit (a cui mi collegherei direttamente, se solo PASS sapesse come utilizzare l'interfaccia utente), parlerò un po' delle modifiche che farò make alla configurazione del server e al mio script di popolamento per vedere se riesco a ottenere prestazioni migliori dal popolamento di columnstore.
[ Parte 1 | Parte 2 | Parte 3]