La maggior parte dei database dovrebbe utilizzare chiavi esterne per imporre l'integrità referenziale (RI) ove possibile. Tuttavia, c'è di più in questa decisione che semplicemente decidere di utilizzare i vincoli FK e crearli. Ci sono una serie di considerazioni da affrontare per garantire che il database funzioni nel modo più fluido possibile.
Questo articolo copre una di queste considerazioni che non riceve molta pubblicità:ridurre al minimo il blocco , dovresti riflettere attentamente sugli indici utilizzati per imporre l'univocità sul lato padre di tali relazioni di chiave esterna.
Questo vale se stai usando il blocco read commit o basato sul controllo delle versioni leggere l'isolamento dello snapshot commit (RCSI). Entrambi possono verificarsi blocchi quando le relazioni di chiavi esterne vengono controllate dal motore di SQL Server.
Sotto l'isolamento dello snapshot (SI), c'è un ulteriore avvertimento. Lo stesso problema essenziale può portare a fallimenti di transazione imprevisti (e probabilmente illogici). a causa di apparenti conflitti di aggiornamento.
Questo articolo è diviso in due parti. La prima parte esamina il blocco della chiave esterna con il blocco dell'isolamento dello snapshot di lettura con commit e lettura con commit. La seconda parte riguarda i conflitti di aggiornamento correlati con l'isolamento dello snapshot.
1. Blocco dei controlli delle chiavi esterne
Diamo prima un'occhiata a come la progettazione dell'indice può influire quando si verifica un blocco a causa di controlli di chiavi esterne.
La seguente demo deve essere eseguita in read commit isolamento. Per SQL Server l'impostazione predefinita è il blocco della lettura con commit; Il database SQL di Azure usa RCSI come impostazione predefinita. Sentiti libero di scegliere quello che preferisci o di eseguire gli script una volta per ogni impostazione per verificare tu stesso che il comportamento sia lo stesso.
-- Use locking read committed
ALTER DATABASE CURRENT
SET READ_COMMITTED_SNAPSHOT OFF;
-- Or use row-versioning read committed
ALTER DATABASE CURRENT
SET READ_COMMITTED_SNAPSHOT ON; Crea due tabelle collegate da una relazione di chiave esterna:
CREATE TABLE dbo.Parent
(
ParentID integer NOT NULL,
ParentNaturalKey varchar(10) NOT NULL,
ParentValue integer NOT NULL,
CONSTRAINT [PK dbo.Parent ParentID]
PRIMARY KEY (ParentID),
CONSTRAINT [AK dbo.Parent ParentNaturalKey]
UNIQUE (ParentNaturalKey)
);
CREATE TABLE dbo.Child
(
ChildID integer NOT NULL,
ChildNaturalKey varchar(10) NOT NULL,
ChildValue integer NOT NULL,
ParentID integer NULL,
CONSTRAINT [PK dbo.Child ChildID]
PRIMARY KEY (ChildID),
CONSTRAINT [AK dbo.Child ChildNaturalKey]
UNIQUE (ChildNaturalKey),
CONSTRAINT [FK dbo.Child to dbo.Parent]
FOREIGN KEY (ParentID)
REFERENCES dbo.Parent (ParentID)
); Aggiungi una riga alla tabella padre:
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
DECLARE
@ParentID integer = 1,
@ParentNaturalKey varchar(10) = 'PNK1',
@ParentValue integer = 100;
INSERT dbo.Parent
(
ParentID,
ParentNaturalKey,
ParentValue
)
VALUES
(
@ParentID,
@ParentNaturalKey,
@ParentValue
);
Su una seconda connessione , aggiorna l'attributo della tabella padre non chiave ParentValue all'interno di una transazione, ma non eseguire il commit ancora:
DECLARE
@ParentID integer = 1,
@ParentNaturalKey varchar(10) = 'PNK1',
@ParentValue integer = 200;
BEGIN TRANSACTION;
UPDATE dbo.Parent
SET ParentValue = @ParentValue
WHERE ParentID = @ParentID; Sentiti libero di scrivere il predicato di aggiornamento usando la chiave naturale se preferisci, non fa alcuna differenza per i nostri scopi attuali.
Torna alla prima connessione , prova ad aggiungere un record figlio:
DECLARE
@ChildID integer = 101,
@ChildNaturalKey varchar(10) = 'CNK1',
@ChildValue integer = 999,
@ParentID integer = 1;
INSERT dbo.Child
(
ChildID,
ChildNaturalKey,
ChildValue,
ParentID
)
VALUES
(
@ChildID,
@ChildNaturalKey,
@ChildValue,
@ParentID
); Questa dichiarazione di inserimento bloccherà , indipendentemente dal fatto che tu abbia scelto blocco o controllo delle versioni lettura impegnata isolamento per questo test.
Spiegazione
Il piano di esecuzione per l'inserimento del record figlio è:
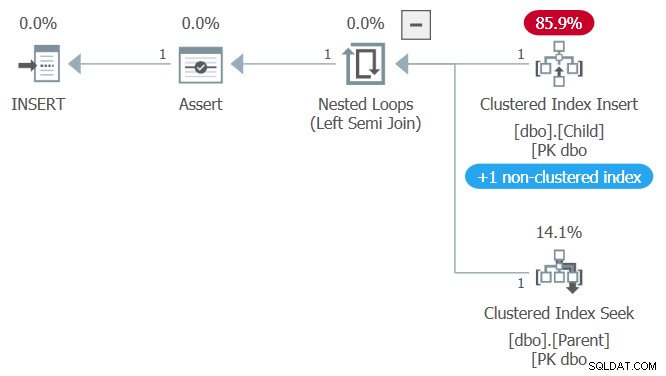
Dopo aver inserito la nuova riga nella tabella figlio, il piano di esecuzione verifica il vincolo di chiave esterna. Il controllo viene saltato se l'ID padre inserito è nullo (ottenuto tramite un predicato "passa attraverso" sul semi join sinistro). Nel caso in esame, l'ID padre aggiunto non è null, quindi il controllo della chiave esterna è eseguito.
SQL Server verifica il vincolo di chiave esterna cercando una riga corrispondente nella tabella padre. Il motore non può utilizzare il controllo delle versioni delle righe per farlo, deve essere sicuro che i dati che sta controllando siano gli ultimi dati impegnati , non una vecchia versione. Il motore lo garantisce aggiungendo un READCOMMITTEDLOCK interno suggerimento della tabella per il controllo della chiave esterna sulla tabella padre.
Il risultato finale è che SQL Server tenta di acquisire un blocco condiviso sulla riga corrispondente nella tabella padre, che blocca perché l'altra sessione contiene un blocco in modalità esclusiva incompatibile a causa dell'aggiornamento non ancora eseguito.
Per essere chiari, il suggerimento di blocco interno si applica solo al controllo della chiave esterna. Il resto del piano utilizza ancora RCSI, se hai scelto l'implementazione del livello di isolamento di lettura commit.
Evitare il blocco
Esegui il commit o il rollback della transazione aperta nella seconda sessione, quindi reimposta l'ambiente di test:
DROP TABLE IF EXISTS
dbo.Child, dbo.Parent; Crea nuovamente le tabelle di test, ma questa volta invece di accettare le impostazioni predefinite, scegliamo di rendere la chiave primaria non cluster e il vincolo univoco raggruppato:
CREATE TABLE dbo.Parent
(
ParentID integer NOT NULL,
ParentNaturalKey varchar(10) NOT NULL,
ParentValue integer NOT NULL,
CONSTRAINT [PK dbo.Parent ParentID]
PRIMARY KEY NONCLUSTERED (ParentID),
CONSTRAINT [AK dbo.Parent ParentNaturalKey]
UNIQUE CLUSTERED (ParentNaturalKey)
);
CREATE TABLE dbo.Child
(
ChildID integer NOT NULL,
ChildNaturalKey varchar(10) NOT NULL,
ChildValue integer NOT NULL,
ParentID integer NULL,
CONSTRAINT [PK dbo.Child ChildID]
PRIMARY KEY NONCLUSTERED (ChildID),
CONSTRAINT [AK dbo.Child ChildNaturalKey]
UNIQUE CLUSTERED (ChildNaturalKey),
CONSTRAINT [FK dbo.Child to dbo.Parent]
FOREIGN KEY (ParentID)
REFERENCES dbo.Parent (ParentID)
); Aggiungi una riga alla tabella padre come prima:
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
DECLARE
@ParentID integer = 1,
@ParentNaturalKey varchar(10) = 'PNK1',
@ParentValue integer = 100;
INSERT dbo.Parent
(
ParentID,
ParentNaturalKey,
ParentValue
)
VALUES
(
@ParentID,
@ParentNaturalKey,
@ParentValue
); Nella seconda sessione , esegui l'aggiornamento senza eseguirne nuovamente il commit. Sto usando la chiave naturale questa volta solo per la varietà:non è importante per il risultato. Usa di nuovo la chiave surrogata se preferisci.
DECLARE
@ParentID integer = 1,
@ParentNaturalKey varchar(10) = 'PNK1',
@ParentValue integer = 200;
BEGIN TRANSACTION
UPDATE dbo.Parent
SET ParentValue = @ParentValue
WHERE ParentNaturalKey = @ParentNaturalKey; Ora esegui nuovamente l'inserto figlio nella prima sessione :
DECLARE
@ChildID integer = 101,
@ChildNaturalKey varchar(10) = 'CNK1',
@ChildValue integer = 999,
@ParentID integer = 1;
INSERT dbo.Child
(
ChildID,
ChildNaturalKey,
ChildValue,
ParentID
)
VALUES
(
@ChildID,
@ChildNaturalKey,
@ChildValue,
@ParentID
); Questa volta l'inserto bambino non si blocca . Questo è vero sia che tu stia utilizzando l'isolamento di lettura commit basato sul blocco o sul controllo delle versioni. Non è un refuso o un errore:RCSI qui non fa differenza.
Spiegazione
Il piano di esecuzione per l'inserimento del record figlio questa volta è leggermente diverso:
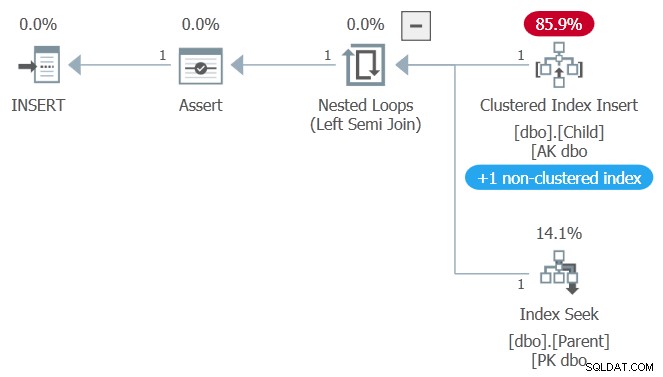
Tutto è come prima (incluso l'invisibile READCOMMITTEDLOCK suggerimento) tranne il controllo della chiave esterna ora utilizza il non cluster indice univoco che applica la chiave primaria della tabella padre. Nel primo test, questo indice è stato raggruppato.
Allora perché non blocchiamo questa volta?
L'aggiornamento della tabella padre non ancora vincolato nella seconda sessione ha un blocco esclusivo nell'indice cluster riga perché è in corso la modifica della tabella di base. La modifica al ParentValue la colonna non influiscono sulla chiave primaria non cluster su ParentID , in modo che la riga dell'indice non cluster non sia bloccata .
Il controllo della chiave esterna può quindi acquisire il necessario lock condiviso sull'indice della chiave primaria non cluster senza contese e l'inserimento della tabella figlio riusce immediatamente .
Quando il primario è stato raggruppato, il controllo della chiave esterna richiedeva un blocco condiviso sulla stessa risorsa (riga dell'indice in cluster) che era bloccata esclusivamente dall'istruzione di aggiornamento.
Il comportamento può essere sorprendente, ma non è un bug . Assegnare alla chiave esterna il controllo del proprio metodo di accesso ottimizzato evita conflitti di blocco logicamente non necessari. Non è necessario bloccare la ricerca della chiave esterna perché ParentID l'attributo non è interessato dall'aggiornamento simultaneo.
2. Conflitti di aggiornamento evitabili
Se esegui i test precedenti con il livello di isolamento snapshot (SI), il risultato sarà lo stesso. La riga figlio inserisce blocchi quando la chiave di riferimento viene applicata da un indice cluster e non blocca quando l'applicazione delle chiavi utilizza un non cluster indice univoco.
C'è però un'importante differenza potenziale quando si utilizza SI. Sotto l'isolamento di lettura commit (blocco o RCSI), l'inserimento della riga figlio alla fine riesce dopo che l'aggiornamento nella seconda sessione esegue il commit o il rollback. Utilizzando SI, esiste il rischio di interruzione di una transazione a causa di un apparente conflitto di aggiornamento.
Questo è un po' più complicato da dimostrare perché una transazione snapshot non inizia con BEGIN TRANSACTION istruzione — inizia con il primo accesso ai dati utente dopo quel punto.
Lo script seguente imposta la dimostrazione SI, con una tabella fittizia aggiuntiva utilizzata solo per garantire che la transazione di snapshot sia veramente iniziata. Utilizza la variante di test in cui la chiave primaria di riferimento viene applicata utilizzando un cluster univoco indice (l'impostazione predefinita):
ALTER DATABASE CURRENT SET ALLOW_SNAPSHOT_ISOLATION ON;
GO
DROP TABLE IF EXISTS
dbo.Dummy, dbo.Child, dbo.Parent;
GO
CREATE TABLE dbo.Dummy
(
x integer NULL
);
CREATE TABLE dbo.Parent
(
ParentID integer NOT NULL,
ParentNaturalKey varchar(10) NOT NULL,
ParentValue integer NOT NULL,
CONSTRAINT [PK dbo.Parent ParentID]
PRIMARY KEY (ParentID),
CONSTRAINT [AK dbo.Parent ParentNaturalKey]
UNIQUE (ParentNaturalKey)
);
CREATE TABLE dbo.Child
(
ChildID integer NOT NULL,
ChildNaturalKey varchar(10) NOT NULL,
ChildValue integer NOT NULL,
ParentID integer NULL,
CONSTRAINT [PK dbo.Child ChildID]
PRIMARY KEY (ChildID),
CONSTRAINT [AK dbo.Child ChildNaturalKey]
UNIQUE (ChildNaturalKey),
CONSTRAINT [FK dbo.Child to dbo.Parent]
FOREIGN KEY (ParentID)
REFERENCES dbo.Parent (ParentID)
); Inserimento della riga principale:
DECLARE
@ParentID integer = 1,
@ParentNaturalKey varchar(10) = 'PNK1',
@ParentValue integer = 100;
INSERT dbo.Parent
(
ParentID,
ParentNaturalKey,
ParentValue
)
VALUES
(
@ParentID,
@ParentNaturalKey,
@ParentValue
); Ancora nella prima sessione , avvia la transazione snapshot:
-- Session 1 SET TRANSACTION ISOLATION LEVEL SNAPSHOT; BEGIN TRANSACTION; -- Ensure snapshot transaction is started SELECT COUNT_BIG(*) FROM dbo.Dummy AS D;
Nella seconda sessione (in esecuzione a qualsiasi livello di isolamento):
-- Session 2
DECLARE
@ParentID integer = 1,
@ParentNaturalKey varchar(10) = 'PNK1',
@ParentValue integer = 200;
BEGIN TRANSACTION;
UPDATE dbo.Parent
SET ParentValue = @ParentValue
WHERE ParentID = @ParentID; Tentativo di inserire la riga figlio nella prima sessione blocchi come previsto:
-- Session 1
DECLARE
@ChildID integer = 101,
@ChildNaturalKey varchar(10) = 'CNK1',
@ChildValue integer = 999,
@ParentID integer = 1;
INSERT dbo.Child
(
ChildID,
ChildNaturalKey,
ChildValue,
ParentID
)
VALUES
(
@ChildID,
@ChildNaturalKey,
@ChildValue,
@ParentID
); La differenza si verifica quando concludiamo la transazione nella seconda sessione. Se lo annulliamo , l'inserto della riga figlio della prima sessione viene completato correttamente .
Se invece ci impegniamo la transazione aperta:
-- Session 2 COMMIT TRANSACTION;
La prima sessione segnala un conflitto di aggiornamento e torna indietro:

Spiegazione
Questo conflitto di aggiornamento si verifica nonostante la chiave esterna in fase di convalida non è stato modificato entro l'aggiornamento della seconda sessione.
Il motivo è essenzialmente lo stesso della prima serie di test. Quando l'indice cluster viene utilizzato per l'applicazione della chiave di riferimento, la transazione snapshot incontra una riga che è stato modificato da quando è iniziato. Questo non è consentito con l'isolamento dello snapshot.
Quando la chiave viene applicata utilizzando un indice non cluster , la transazione snapshot vede solo la riga dell'indice non modificata non cluster, quindi non c'è alcun blocco e non viene rilevato alcun "conflitto di aggiornamento".
Esistono molte altre circostanze in cui l'isolamento dello snapshot può segnalare conflitti di aggiornamento imprevisti o altri errori. Vedi il mio articolo precedente per esempi.
Conclusioni
Ci sono molte considerazioni da tenere in considerazione quando si sceglie l'indice cluster per una tabella di archivio di righe. I problemi qui descritti sono solo un altro fattore da valutare.
Ciò è particolarmente vero se utilizzerai l'isolamento dello snapshot. Nessuno gode di una transazione interrotta , specialmente uno che è discutibilmente illogico. Se utilizzerai RCSI, il blocco durante la lettura convalidare le chiavi esterne potrebbe essere imprevisto e potrebbe portare a deadlock.
Il predefinito per una PRIMARY KEY vincolo è creare il suo indice di supporto come raggruppato , a meno che un altro indice o vincolo nella definizione della tabella non sia esplicito sull'essere raggruppati. È una buona abitudine essere espliciti sul tuo intento progettuale, quindi ti incoraggio a scrivere CLUSTERED o NONCLUSTERED ogni volta.
Indici duplicati?
Potrebbero esserci momenti in cui consideri seriamente, per valide ragioni, di avere un indice cluster e un indice non cluster con la stesse chiavi .
L'intento potrebbe essere quello di fornire un accesso in lettura ottimale per le query degli utenti tramite il cluster index (evitando le ricerche di chiavi), consentendo anche la convalida con blocco minimo (e conflitto di aggiornamenti) per le chiavi esterne tramite il compatto non cluster indice come mostrato qui.
Questo è realizzabile, ma ci sono un paio di inconvenienti a cui prestare attenzione:
-
Dato più di un indice di destinazione adatto, SQL Server non fornisce un modo per garantire quale indice verrà utilizzato per l'applicazione della chiave esterna.
Dan Guzman ha documentato le sue osservazioni in Secrets of Foreign Key Index Binding, ma queste potrebbero essere incomplete e, in ogni caso, non sono documentate, quindi potrebbero cambiare .
Puoi aggirare il problema assicurandoti che vi sia solo un obiettivo index al momento della creazione della chiave esterna, ma complica le cose e invita a problemi futuri se il vincolo della chiave esterna viene mai eliminato e ricreato.
-
Se utilizzi la sintassi della chiave esterna abbreviata, SQL Server sarà solo associa il vincolo alla chiave primaria , indipendentemente dal fatto che sia non cluster o cluster.
Il frammento di codice seguente mostra l'ultima differenza:
CREATE TABLE dbo.Parent
(
ParentID integer NOT NULL UNIQUE CLUSTERED
);
-- Shorthand (implicit) syntax
-- Fails with error 1773
CREATE TABLE dbo.Child
(
ChildID integer NOT NULL PRIMARY KEY NONCLUSTERED,
ParentID integer NOT NULL
REFERENCES dbo.Parent
);
-- Explicit syntax succeeds
CREATE TABLE dbo.Child
(
ChildID integer NOT NULL PRIMARY KEY NONCLUSTERED,
ParentID integer NOT NULL
REFERENCES dbo.Parent (ParentID)
); Le persone si sono abituate a ignorare in gran parte i conflitti di lettura-scrittura in RCSI e SI. Speriamo che questo articolo ti abbia dato qualcosa in più a cui pensare quando implementi la progettazione fisica per le tabelle correlate da una chiave esterna.