Questa è la seconda parte della multi-serie Benchmarking Managed PostgreSQL Cloud Solutions . Nella parte 1 ho presentato una panoramica degli strumenti disponibili, ho discusso il motivo dell'utilizzo della procedura di benchmark AWS per Aurora, nonché le versioni di PostgreSQL da utilizzare e ho esaminato Amazon Aurora PostgreSQL 10.6.
In questa parte, pgbench e sysbench verranno eseguiti su Amazon RDS per PostgreSQL 11.1. Al momento della stesura di questo articolo, l'ultima versione di PostgreSQL è la 11.2 rilasciata circa un mese fa.
Vale la pena soffermarsi un secondo per rivedere rapidamente le versioni di PostgreSQL attualmente disponibili nel cloud:
- Amazon Aurora PostgreSQL 10.6
- Amazon RDS per PostgreSQL 11.1
- Google Cloud SQL per PostgreSQL 9.6
- Microsoft Azure PostgreSQL 10.5
Amazon è ancora una volta vincente, con la sua offerta RDS, fornendo la versione più recente di PostgreSQL. Come annunciato nel forum RDS, AWS ha reso disponibile PostgreSQL 11.1 il 13 marzo, quattro mesi dopo il rilascio della community.
Impostazione dell'ambiente
Alcune note sui vincoli relativi alla creazione dell'ambiente e all'esecuzione del benchmark, punti che sono stati discussi più in dettaglio durante la Parte 1 di questa serie:
- Nessuna modifica alle impostazioni GUC predefinite del provider cloud.
- Le connessioni sono limitate a un massimo di 1.000 poiché la patch AWS per pgbench non è stata applicata correttamente. In una nota correlata, ho dovuto scaricare la patch di temporizzazione AWS da questo invio di pgsql-hacker poiché non era più disponibile al link menzionato nella guida.
- La rete avanzata deve essere abilitata per l'istanza client.
- Il database non include una replica.
- La memoria del database non è crittografata.
- Sia il client che le istanze di destinazione si trovano nella stessa zona di disponibilità.
Innanzitutto, configura il client e le istanze del database:
- Il client è un'istanza EC2 r4.8xlarge on demand:
- vCPU:32 (16 core x 2 thread/core)
- RAM:244 GiB
- Stoccaggio:EBS ottimizzato
- Rete:10 Gigabit
 Configurazione dell'istanza client
Configurazione dell'istanza client - Il cluster DB è un db.r4.2xlarge su richiesta:
- vCPU:8
- RAM:61GiB
- Stoccaggio:EBS ottimizzato
- Rete:larghezza di banda massima di 1.750 Mbps su una connessione fino a 10 Gbps
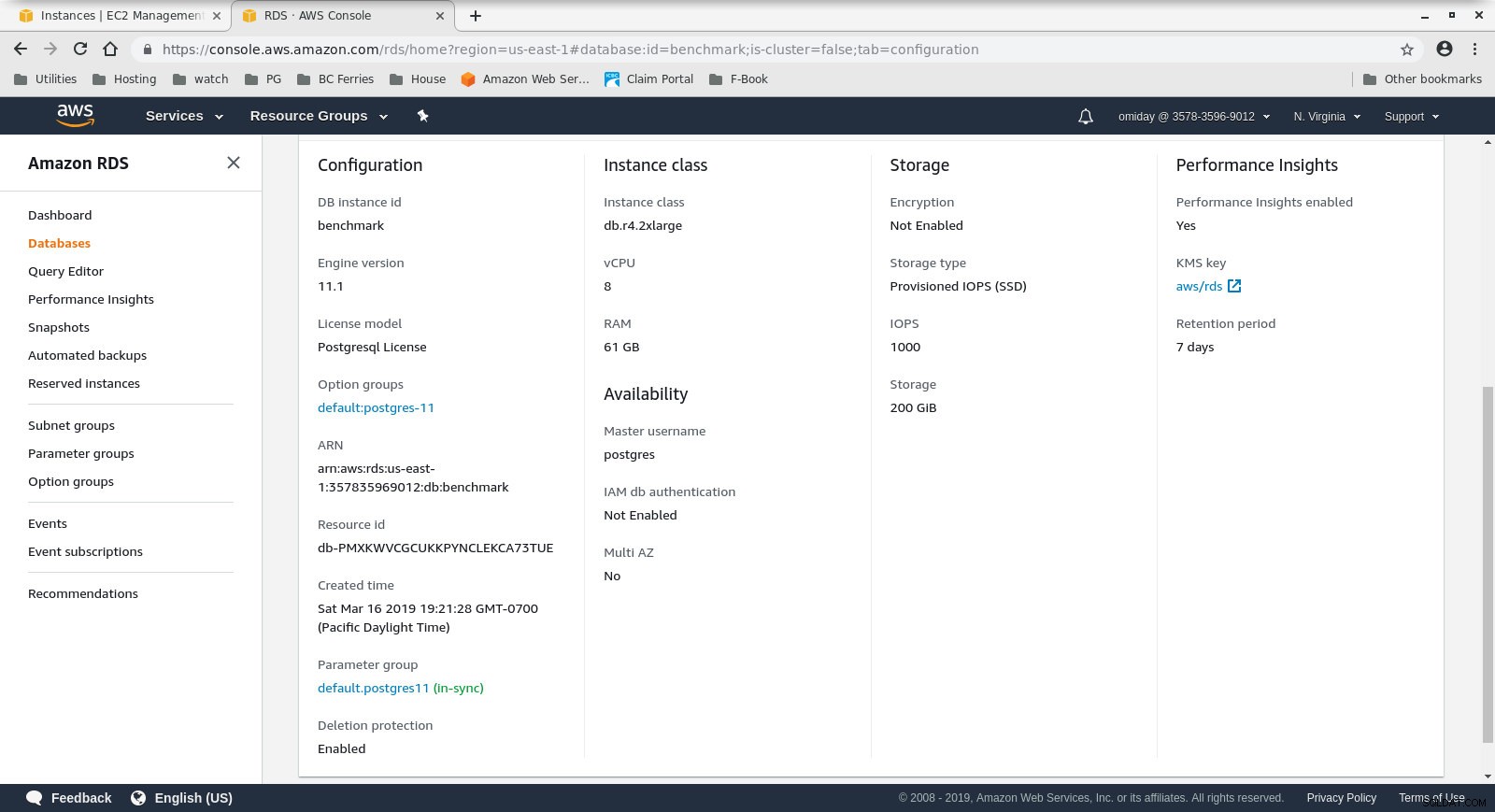 Configurazione dell'istanza del database
Configurazione dell'istanza del database
Successivamente, installa e configura gli strumenti di benchmark, pgbench e sysbench, seguendo le istruzioni nella guida di Amazon.
L'ultimo passaggio per preparare l'ambiente è la configurazione dei parametri di connessione di PostgreSQL. Un modo per farlo è inizializzare le variabili di ambiente in .bashrc. Inoltre, dobbiamo impostare i percorsi dei binari e delle librerie PostgreSQL:
export PGHOST=benchmark.ctfirtyhadgr.us-east-1.rds.amazonaws.com
export PGHOST=benchmark.ctfirtyhadgr.us-east-1.rds.amazonaws.com
export PGUSER=postgres
export PGPASSWORD=postgres
export PGDATABASE=postgres
export PATH=$PATH:/usr/local/pgsql/bin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/pgsql/lib
Verify that everything is in place:
[example@sqldat.com ~]# psql --version
psql (PostgreSQL) 11.1
[example@sqldat.com ~]# pgbench --version
pgbench (PostgreSQL) 11.1
[example@sqldat.com ~]# sysbench --version
sysbench 0.5Esecuzione dei benchmark
pgench
Innanzitutto, inizializza il database pgbench.
[example@sqldat.com ~]# pgbench -i --fillfactor=90 --scale=10000Il processo di inizializzazione richiede del tempo e durante l'esecuzione ha generato il seguente output:
dropping old tables...
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
creating tables...
generating data...
100000 of 1000000000 tuples (0%) done (elapsed 0.06 s, remaining 599.79 s)
200000 of 1000000000 tuples (0%) done (elapsed 0.15 s, remaining 739.16 s)
300000 of 1000000000 tuples (0%) done (elapsed 0.22 s, remaining 742.21 s)
400000 of 1000000000 tuples (0%) done (elapsed 0.33 s, remaining 814.64 s)
500000 of 1000000000 tuples (0%) done (elapsed 0.41 s, remaining 825.82 s)
600000 of 1000000000 tuples (0%) done (elapsed 0.51 s, remaining 854.13 s)
700000 of 1000000000 tuples (0%) done (elapsed 0.66 s, remaining 937.01 s)
800000 of 1000000000 tuples (0%) done (elapsed 1.52 s, remaining 1897.42 s)
900000 of 1000000000 tuples (0%) done (elapsed 1.66 s, remaining 1840.08 s)
...
500600000 of 1000000000 tuples (50%) done (elapsed 814.78 s, remaining 812.83 s)
500700000 of 1000000000 tuples (50%) done (elapsed 814.81 s, remaining 812.53 s)
500800000 of 1000000000 tuples (50%) done (elapsed 814.83 s, remaining 812.23 s)
500900000 of 1000000000 tuples (50%) done (elapsed 815.11 s, remaining 812.19 s)
501000000 of 1000000000 tuples (50%) done (elapsed 815.20 s, remaining 811.94 s)
...
999200000 of 1000000000 tuples (99%) done (elapsed 1645.02 s, remaining 1.32 s)
999300000 of 1000000000 tuples (99%) done (elapsed 1645.17 s, remaining 1.15 s)
999400000 of 1000000000 tuples (99%) done (elapsed 1645.20 s, remaining 0.99 s)
999500000 of 1000000000 tuples (99%) done (elapsed 1645.23 s, remaining 0.82 s)
999600000 of 1000000000 tuples (99%) done (elapsed 1645.26 s, remaining 0.66 s)
999700000 of 1000000000 tuples (99%) done (elapsed 1645.28 s, remaining 0.49 s)
999800000 of 1000000000 tuples (99%) done (elapsed 1645.51 s, remaining 0.33 s)
999900000 of 1000000000 tuples (99%) done (elapsed 1645.77 s, remaining 0.16 s)
1000000000 of 1000000000 tuples (100%) done (elapsed 1646.03 s, remaining 0.00 s)
vacuuming...
creating primary keys...
total time: 5538.86 s (drop 0.00 s, tables 0.01 s, insert 1647.08 s, commit 0.03 s, primary 1251.60 s, foreign 0.00 s, vacuum 2640.14 s)
done.Una volta completata quella parte, verifica che il database PostgreSQL sia stato popolato. La seguente versione semplificata della query sull'utilizzo del disco può essere utilizzata per restituire la dimensione del database PostgreSQL:
SELECT
d.datname AS Name,
pg_catalog.pg_get_userbyid(d.datdba) AS Owner,
pg_catalog.pg_size_pretty(pg_catalog.pg_database_size(d.datname)) AS SIZE
FROM pg_catalog.pg_database d
WHERE d.datname = 'postgres';…e l'output:
name | owner | size
----------+----------+--------
postgres | postgres | 160 GB
(1 row)Con tutti i preparativi completati possiamo iniziare il test di lettura/scrittura di pgbench:
[example@sqldat.com ~]# pgbench --protocol=prepared -P 60 --time=600 --client=1000 --jobs=2048Dopo 10 minuti otteniamo i risultati:
starting vacuum...end.
progress: 60.0 s, 878.3 tps, lat 1101.258 ms stddev 339.491
progress: 120.0 s, 885.2 tps, lat 1132.301 ms stddev 292.551
progress: 180.0 s, 656.3 tps, lat 1522.102 ms stddev 666.017
progress: 240.0 s, 436.8 tps, lat 2277.140 ms stddev 524.603
progress: 300.0 s, 742.2 tps, lat 1363.558 ms stddev 578.541
progress: 360.0 s, 866.4 tps, lat 1146.972 ms stddev 301.861
progress: 420.0 s, 878.2 tps, lat 1143.939 ms stddev 304.396
progress: 480.0 s, 872.7 tps, lat 1139.892 ms stddev 304.421
progress: 540.0 s, 881.0 tps, lat 1132.373 ms stddev 311.890
progress: 600.0 s, 729.3 tps, lat 1366.517 ms stddev 867.784
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 10000
query mode: prepared
number of clients: 1000
number of threads: 1000
duration: 600 s
number of transactions actually processed: 470582
latency average = 1274.340 ms
latency stddev = 544.179 ms
tps = 782.084354 (including connections establishing)
tps = 783.610726 (excluding connections establishing)sistema di analisi
Il primo passo è aggiungere alcuni dati:
sysbench --test=/usr/local/share/sysbench/oltp.lua \
--pgsql-host=aurora.cluster-ctfirtyhadgr.us-east-1.rds.amazonaws.com \
--pgsql-db=postgres \
--pgsql-user=postgres \
--pgsql-password=postgres \
--pgsql-port=5432 \
--oltp-tables-count=250\
--oltp-table-size=450000 \
prepareIl comando crea 250 tabelle, ciascuna con 2 indici:
sysbench 0.5: multi-threaded system evaluation benchmark
Creating table 'sbtest1'...
Inserting 450000 records into 'sbtest1'
Creating secondary indexes on 'sbtest1'...
Creating table 'sbtest2'...
...
Creating table 'sbtest250'...
Inserting 450000 records into 'sbtest250'
Creating secondary indexes on 'sbtest250'...Diamo un'occhiata agli indici:
postgres=> \di
List of relations
Schema | Name | Type | Owner | Table
--------+-----------------------+-------+----------+------------------
public | k_1 | index | postgres | sbtest1
public | k_10 | index | postgres | sbtest10
public | k_100 | index | postgres | sbtest100
public | k_101 | index | postgres | sbtest101
public | k_102 | index | postgres | sbtest102
public | k_103 | index | postgres | sbtest103
...
public | k_97 | index | postgres | sbtest97
public | k_98 | index | postgres | sbtest98
public | k_99 | index | postgres | sbtest99
public | pgbench_accounts_pkey | index | postgres | pgbench_accounts
public | pgbench_branches_pkey | index | postgres | pgbench_branches
public | pgbench_tellers_pkey | index | postgres | pgbench_tellers
public | sbtest100_pkey | index | postgres | sbtest100
public | sbtest101_pkey | index | postgres | sbtest101
public | sbtest102_pkey | index | postgres | sbtest102
public | sbtest103_pkey | index | postgres | sbtest103
public | sbtest104_pkey | index | postgres | sbtest104
public | sbtest105_pkey | index | postgres | sbtest105
...
public | sbtest97_pkey | index | postgres | sbtest97
public | sbtest98_pkey | index | postgres | sbtest98
public | sbtest99_pkey | index | postgres | sbtest99
public | sbtest9_pkey | index | postgres | sbtest9
(503 rows)Sembra buono... per iniziare il test basta eseguire:
sysbench --test=/usr/local/share/sysbench/oltp.lua \
--pgsql-host=aurora.cluster-ctfirtyhadgr.us-east-1.rds.amazonaws.com \
--pgsql-db=postgres \
--pgsql-user=postgres \
--pgsql-password=postgres \
--pgsql-port=5432 \
--oltp-tables-count=250 \
--oltp-table-size=450000 \
--max-requests=0 \
--forced-shutdown \
--report-interval=60 \
--oltp_simple_ranges=0 \
--oltp-distinct-ranges=0 \
--oltp-sum-ranges=0 \
--oltp-order-ranges=0 \
--oltp-point-selects=0 \
--rand-type=uniform \
--max-time=600 \
--num-threads=1000 \
runUna nota di cautela:
L'archiviazione RDS non è "elastica", il che significa che lo spazio di archiviazione allocato durante la creazione dell'istanza deve essere sufficientemente grande da contenere la quantità di dati generati durante il benchmark, altrimenti RDS fallirà con:
FATAL: PQexec() failed: 7 PANIC: could not write to file "pg_wal/xlogtemp.29144": No space left on device
server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
FATAL: failed query: COMMIT
FATAL: failed to execute function `event': 3
WARNING: terminating connection because of crash of another server process
DETAIL: The postmaster has commanded this server process to roll back the current transaction and exit, because another server process exited abnormally and possibly corrupted shared memory.
HINT: In a moment you should be able to reconnect to the database and repeat your command.
WARNING: terminating connection because of crash of another server processLa dimensione dello spazio di archiviazione può essere aumentata senza fermare il database, tuttavia, mi ci sono voluti circa 30 minuti per farlo crescere da 200 GiB a 500 GiB:
 Aumento dello spazio di archiviazione su RDS
Aumento dello spazio di archiviazione su RDS Ed ecco i risultati del test sysbench:
sysbench 0.5: multi-threaded system evaluation benchmark
Running the test with following options:
Number of threads: 1000
Report intermediate results every 60 second(s)
Random number generator seed is 0 and will be ignored
Forcing shutdown in 630 seconds
Initializing worker threads...
Threads started!
[ 60s] threads: 1000, tps: 1070.40, reads: 0.00, writes: 4309.35, response time: 1808.81ms (95%), errors: 0.02, reconnects: 0.00
[ 120s] threads: 1000, tps: 889.68, reads: 0.00, writes: 3575.35, response time: 1951.12ms (95%), errors: 0.02, reconnects: 0.00
[ 180s] threads: 1000, tps: 574.57, reads: 0.00, writes: 2320.62, response time: 3936.73ms (95%), errors: 0.00, reconnects: 0.00
[ 240s] threads: 1000, tps: 232.10, reads: 0.00, writes: 928.43, response time: 10994.37ms (95%), errors: 0.00, reconnects: 0.00
[ 300s] threads: 1000, tps: 242.40, reads: 0.00, writes: 969.60, response time: 9412.39ms (95%), errors: 0.00, reconnects: 0.00
[ 360s] threads: 1000, tps: 257.73, reads: 0.00, writes: 1030.98, response time: 8833.64ms (95%), errors: 0.02, reconnects: 0.00
[ 420s] threads: 1000, tps: 264.65, reads: 0.00, writes: 1036.60, response time: 9192.42ms (95%), errors: 0.00, reconnects: 0.00
[ 480s] threads: 1000, tps: 278.07, reads: 0.00, writes: 1134.27, response time: 7133.76ms (95%), errors: 0.00, reconnects: 0.00
[ 540s] threads: 1000, tps: 250.40, reads: 0.00, writes: 1001.53, response time: 9628.97ms (95%), errors: 0.00, reconnects: 0.00
[ 600s] threads: 1000, tps: 249.97, reads: 0.00, writes: 996.92, response time: 10724.58ms (95%), errors: 0.00, reconnects: 0.00
OLTP test statistics:
queries performed:
read: 0
write: 1038401
other: 519199
total: 1557600
transactions: 259598 (428.59 per sec.)
read/write requests: 1038401 (1714.36 per sec.)
other operations: 519199 (857.18 per sec.)
ignored errors: 3 (0.00 per sec.)
reconnects: 0 (0.00 per sec.)
General statistics:
total time: 605.7086s
total number of events: 259598
total time taken by event execution: 602999.7582s
response time:
min: 55.02ms
avg: 2322.82ms
max: 13133.36ms
approx. 95 percentile: 8400.39ms
Threads fairness:
events (avg/stddev): 259.5980/3.20
execution time (avg/stddev): 602.9998/2.77Metriche benchmark
I parametri possono essere acquisiti utilizzando gli strumenti di monitoraggio AWS CloudWatch e Performance Insights. Ecco alcuni esempi per i curiosi:
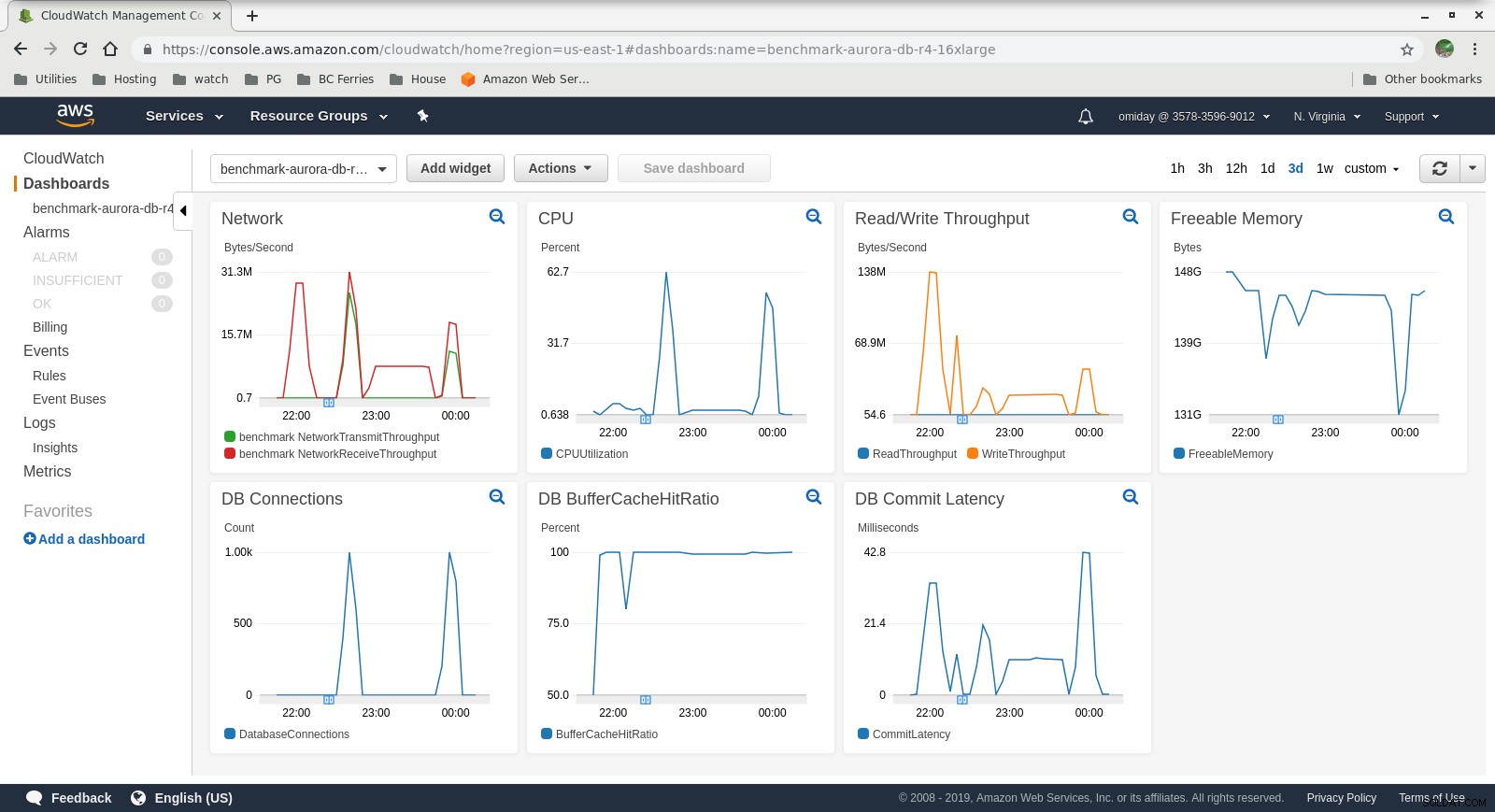 Metriche CloudWatch dell'istanza database
Metriche CloudWatch dell'istanza database 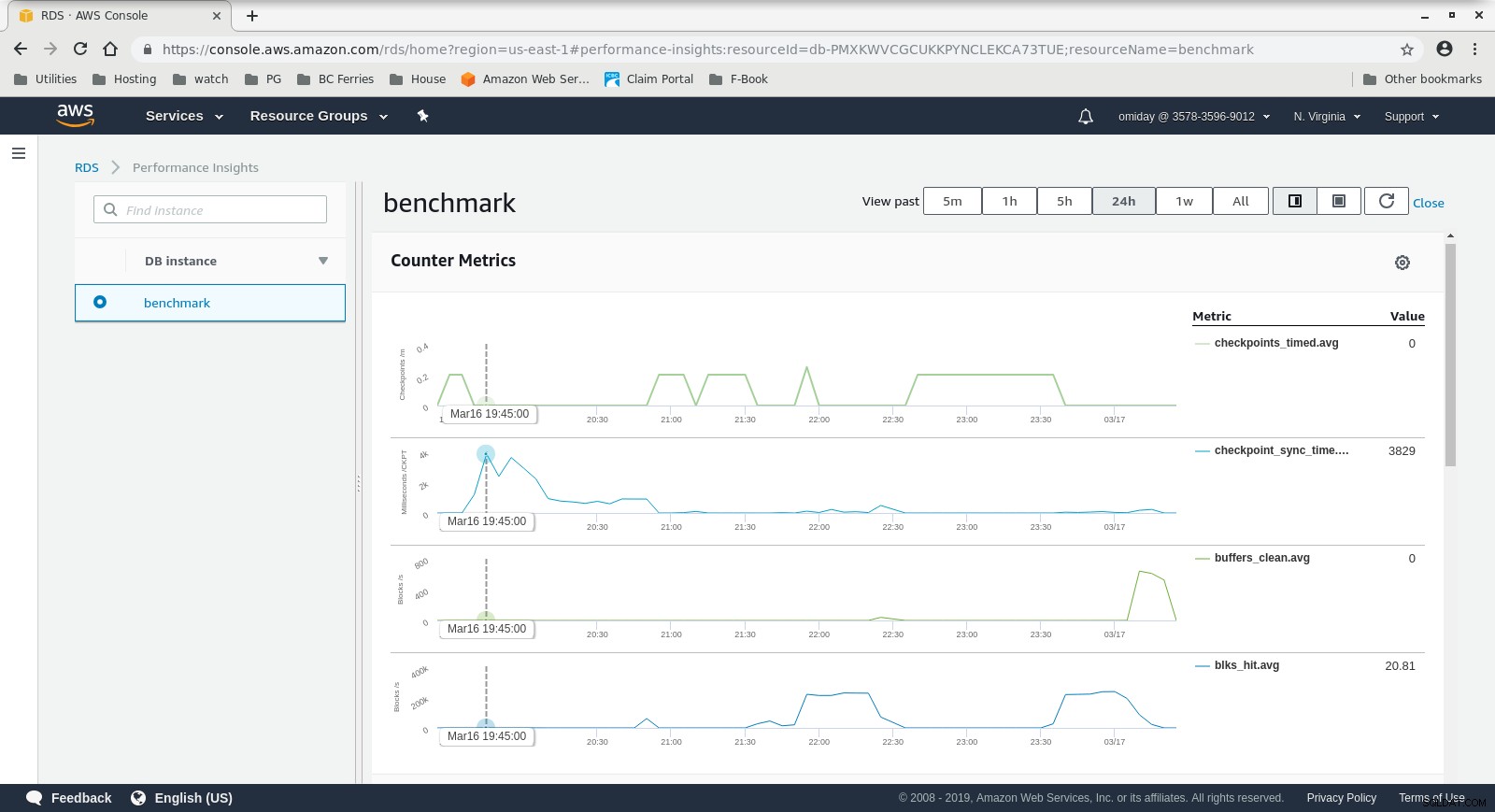 RDS Performance Insights - Counter Metrics
RDS Performance Insights - Counter Metrics 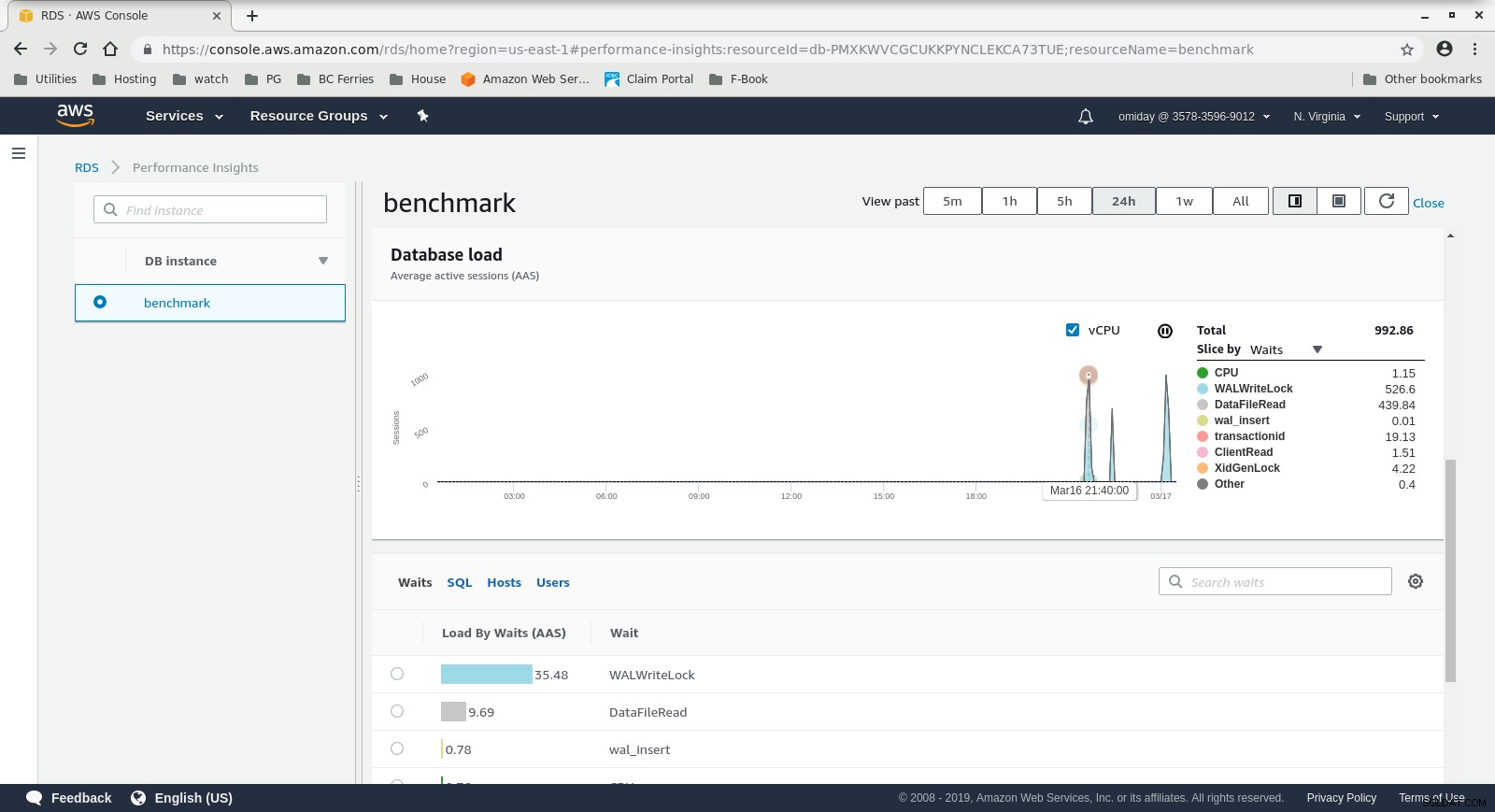 RDS Performance Insights - Caricamento database
RDS Performance Insights - Caricamento database Risultati
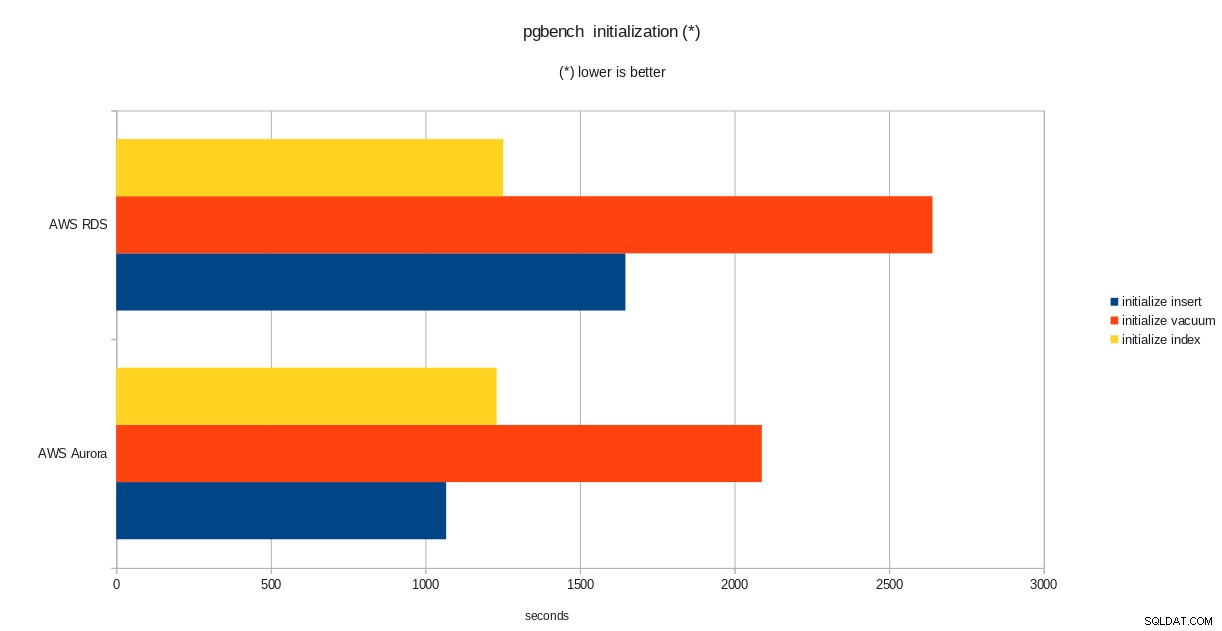 risultati dell'inizializzazione di pgbench
risultati dell'inizializzazione di pgbench 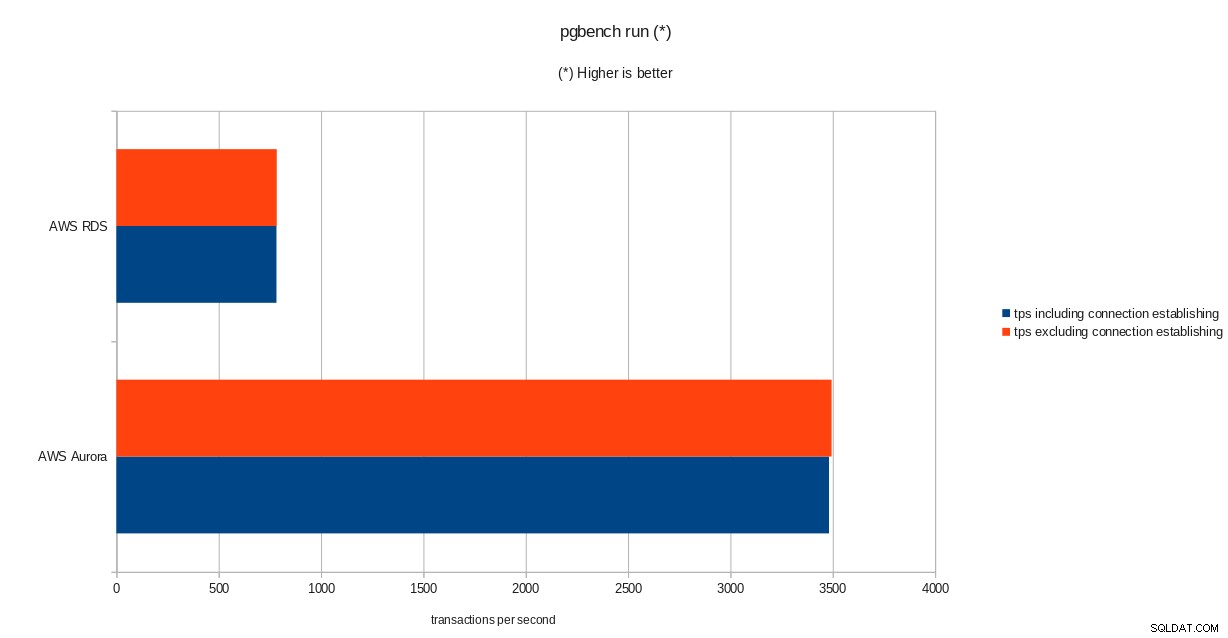 pgbench risultati dell'esecuzione
pgbench risultati dell'esecuzione 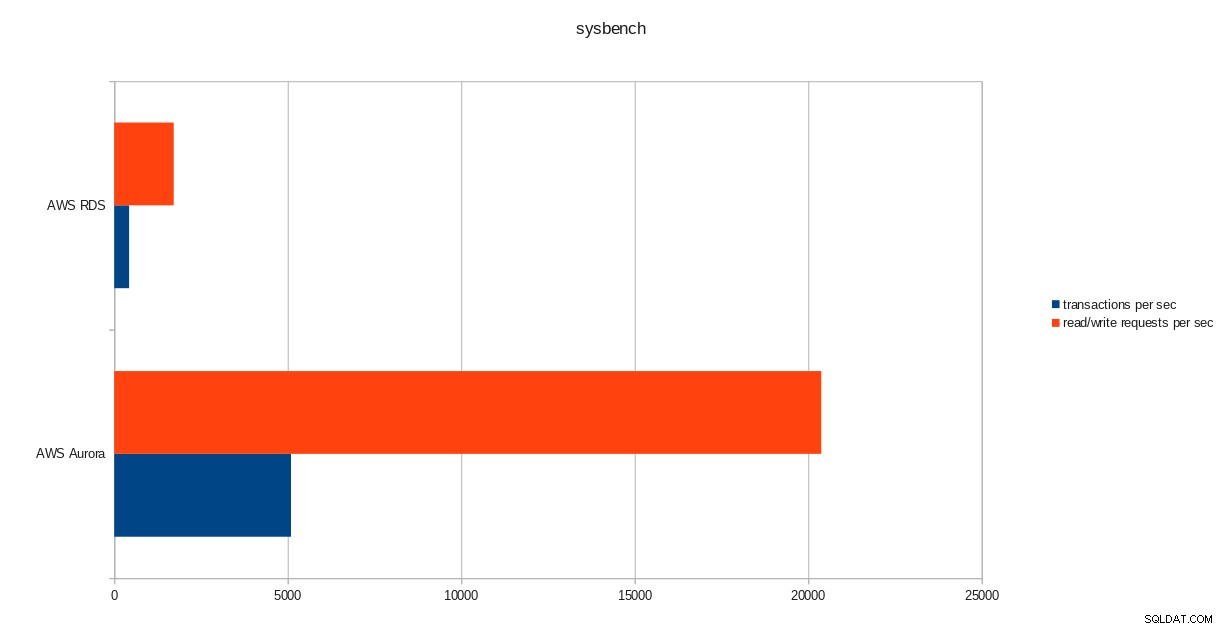 risultati di sysbench
risultati di sysbench Conclusione
Nonostante l'esecuzione di PostgreSQL versione 10.6, Amazon Aurora supera chiaramente RDS che è alla versione 11.1 e ciò non sorprende. Secondo le FAQ di Aurora, Amazon ha fatto di tutto per migliorare le prestazioni complessive del database, basato su un motore di archiviazione riprogettato.
Il prossimo della serie
La parte successiva riguarderà Google Cloud SQL per PostgreSQL.