Nella parte precedente abbiamo testato il tempo di backup e l'efficacia della compressione per diversi livelli e metodi di compressione del backup. In questo blog continueremo i nostri sforzi e parleremo di più impostazioni che, probabilmente, la maggior parte degli utenti non cambia davvero ma potrebbero avere un effetto visibile sul processo di backup.
Il setup è lo stesso della parte precedente:utilizzeremo il cluster di replica master-slave MariaDB con ProxySQL e Keepalived.
Abbiamo generato 7,6 GB di dati utilizzando sysbench:
sysbench /root/sysbench/src/lua/oltp_read_write.lua --threads=4 --mysql-host=10.0.0.111 --mysql-user=sbtest --mysql-password=sbtest --mysql-port=6033 --tables=32 --table-size=1000000 prepareUtilizzo di PIGZ
Questa volta abiliteremo Usa PIGZ per gzip parallelo per i nostri backup. Come prima, testeremo ogni livello di compressione per vedere come si comporta.
Stiamo archiviando il backup localmente sull'istanza, l'istanza è configurata con 4 vCPU.
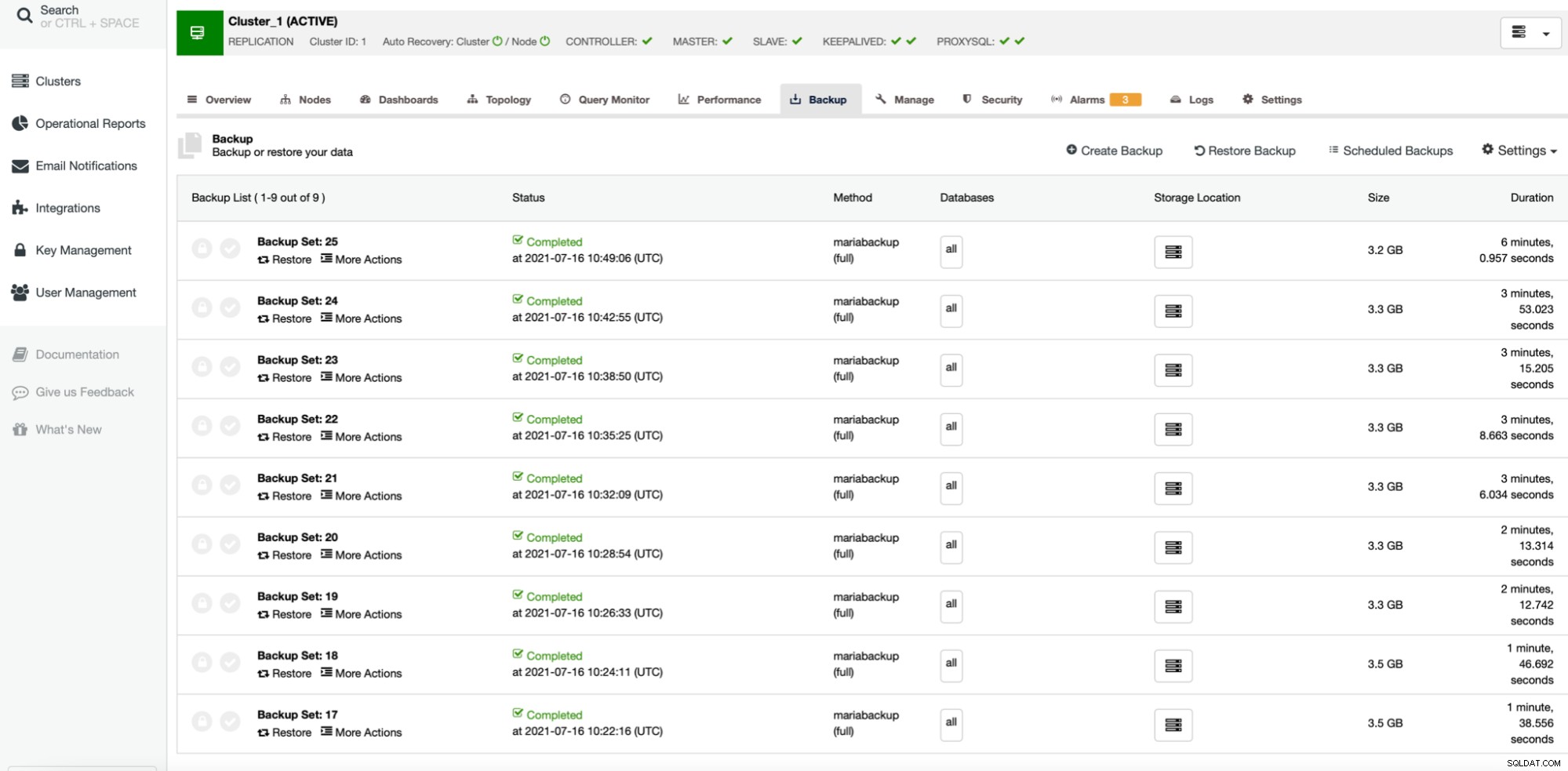
Il risultato è una sorta di previsto. Il processo di backup è stato significativamente più veloce rispetto a quando abbiamo utilizzato un solo core della CPU. La dimensione del backup rimane praticamente la stessa, non c'è un vero motivo per cambiare in modo significativo. È chiaro che l'uso di pigz migliora il tempo di backup. C'è un lato oscuro dell'uso di gzip parallelo, ed è l'utilizzo della CPU:
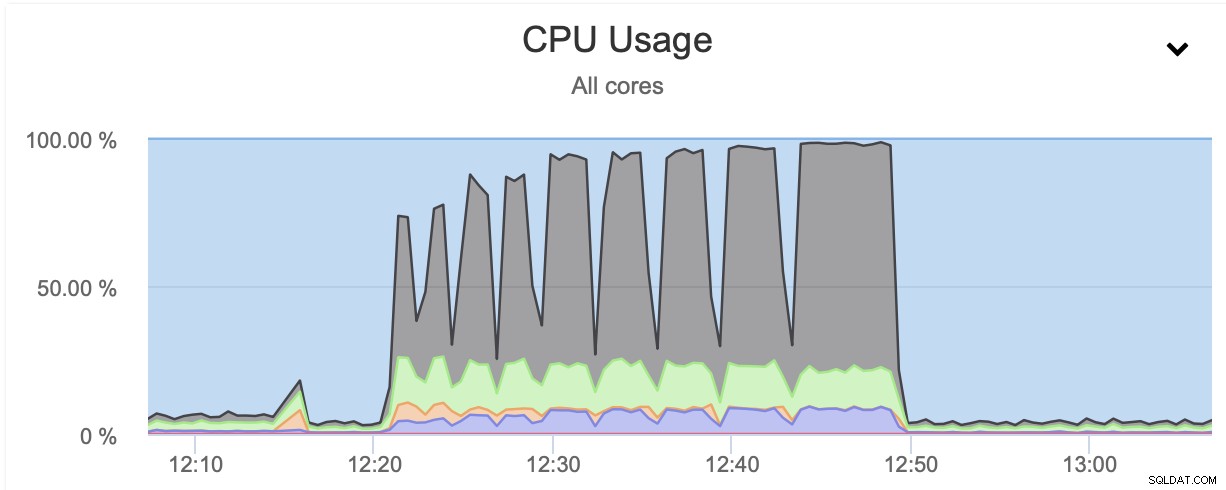
Come puoi vedere, l'utilizzo della CPU sale alle stelle e raggiunge quasi il 100% per livelli di compressione più elevati. Aumentare l'utilizzo della CPU sul server del database non è necessariamente l'idea migliore poiché, in genere, vogliamo che la CPU sia disponibile per il database. D'altra parte, se ci capita di avere una replica dedicata all'esecuzione di backup e, diciamo, query più pesanti, un nodo che non viene utilizzato per servire un tipo di traffico OLTP, possiamo abilitare gzip parallelo per ridurre notevolmente il backup tempo. Come si vede chiaramente, non è un'opzione per tutti ma è sicuramente qualcosa che puoi trovare utile in alcuni scenari particolari. Tieni solo a mente che l'utilizzo della CPU è qualcosa che devi tenere traccia in quanto influirà sulla latenza delle query e, come attraverso di essa, influirà sull'esperienza dell'utente, qualcosa che dovremmo sempre considerare quando lavoriamo con i database.
Thread di copia parallela di Xtrabackup
Un'altra impostazione che vogliamo evidenziare è Xtrabackup Parallel Copy Threads. Per capire di cosa si tratta, parliamo un po' di come funziona Xtrabackup (o MariaBackup). In breve, questi strumenti eseguono due azioni contemporaneamente. Copiano i dati, i file fisici, dal server del database alla posizione di backup mentre monitorano i registri di ripristino di InnoDB per eventuali aggiornamenti. Il backup è costituito dai file e dal record di tutte le modifiche a InnoDB avvenute durante il processo di backup. Questo, con backup lock o FLUSH TABLES WITH READ LOCK, permette di creare backup coerenti nel momento in cui il trasferimento dei dati è terminato. I thread di copia parallela di Xtrabackup definiscono il numero di thread che eseguiranno il trasferimento dei dati. Se lo impostiamo su 1, verrà copiato un file contemporaneamente. Se lo imposteremo su 8, teoricamente è possibile trasferire fino a 8 file contemporaneamente. Ovviamente, deve esserci spazio di archiviazione sufficientemente veloce per beneficiare effettivamente di tale impostazione. Eseguiamo diversi test, modificando i thread di copia parallela di Xtrabackup da 1 a 2 e da 4 a 8. Eseguiremo i test sul livello di compressione 6 (quello predefinito) con e senza gzip parallelo abilitato.
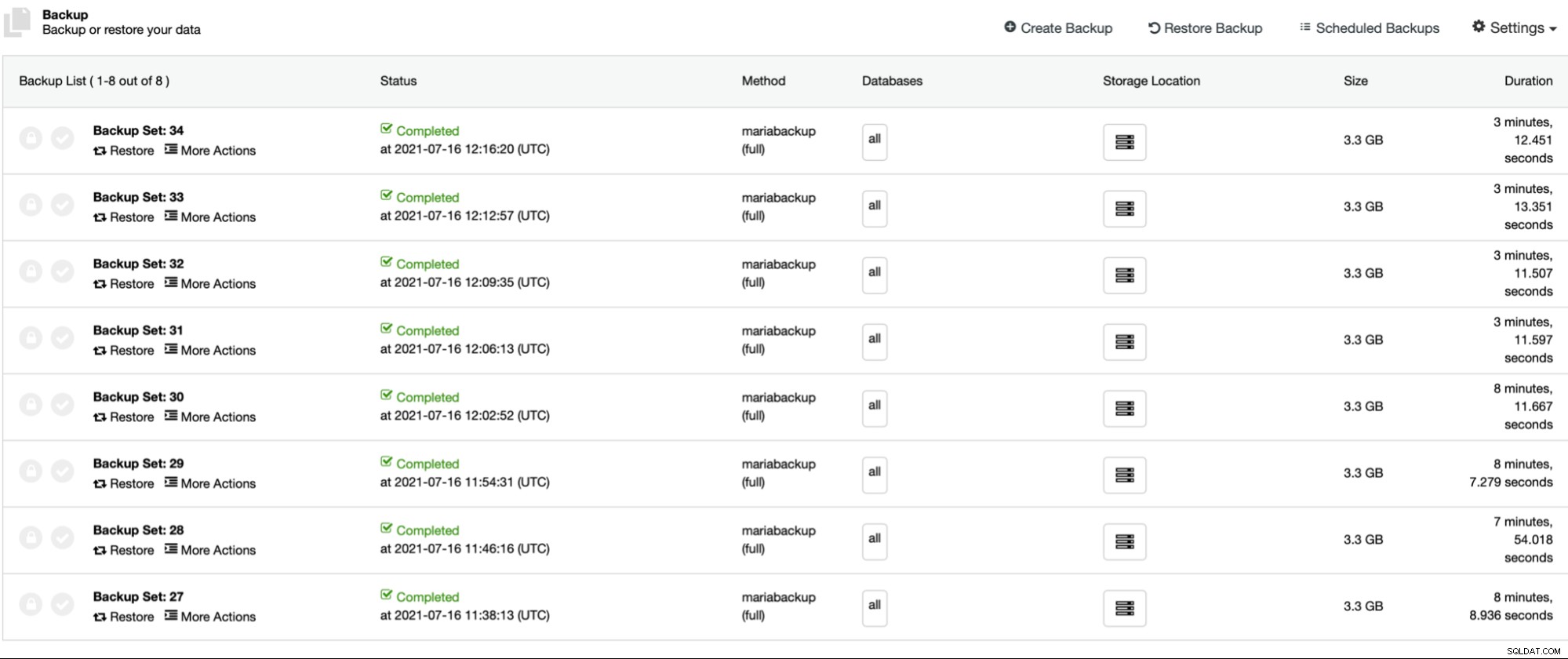
I primi quattro backup (27 - 30) sono stati creati senza gzip parallelo, a partire da 1 a 2, 4 e 8 fili di copia paralleli. Quindi abbiamo ripetuto lo stesso processo per i backup da 31 a 34, questa volta utilizzando gzip parallelo. Come puoi vedere, nel nostro caso non c'è quasi nessuna differenza tra i thread di copia paralleli. Molto probabilmente questo avrà un impatto maggiore se aumenteremo le dimensioni del set di dati. Inoltre, migliorerebbe le prestazioni di backup se utilizzassimo uno storage più veloce e affidabile. Come al solito, il tuo chilometraggio varierà e in ambienti diversi questa impostazione potrebbe influire sul processo di backup più di quanto vediamo qui.
Limitazione della rete
Infine, in questa parte della nostra breve serie vorremmo parlare della capacità di limitare l'utilizzo della rete.
Come avrai visto, i backup possono essere archiviati localmente sul nodo o può anche essere trasmesso in streaming all'host del controller. Ciò avviene in rete e, per impostazione predefinita, verrà eseguito "il più velocemente possibile".
In alcuni casi, in cui il throughput della tua rete è limitato (istanze cloud, ad esempio), potresti voler ridurre l'utilizzo della rete causato da MariaBackup impostando un limite al trasferimento di rete. Quando lo fai, ClusterControl utilizzerà lo strumento "pv" per limitare la larghezza di banda disponibile per il processo.
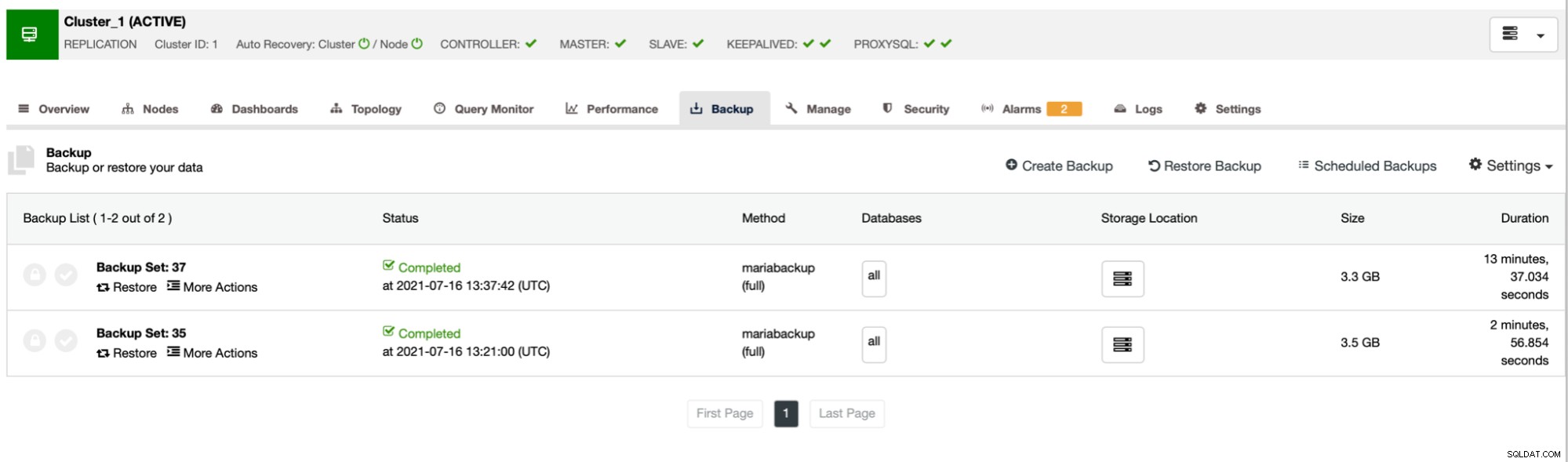
Come puoi vedere, il primo backup ha richiesto circa 3 minuti ma quando abbiamo ha ridotto il throughput della rete, il backup ha richiesto 13 minuti e 37 secondi.
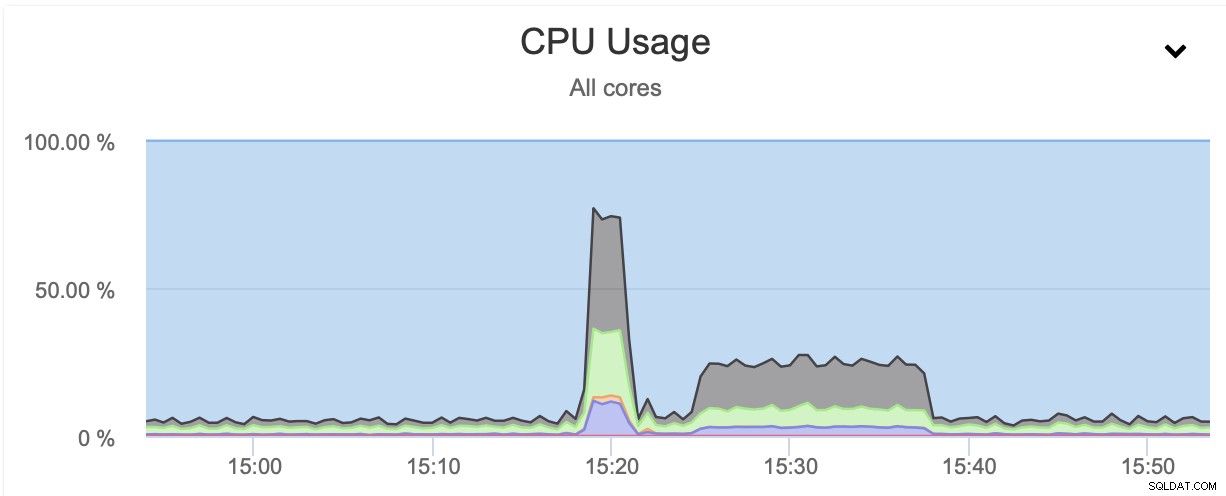
In entrambi i casi abbiamo usato pigz e il livello di compressione 1. Il grafico sopra mostra che la limitazione della rete ha anche ridotto l'utilizzo della CPU. Ha senso, se pigz deve attendere che la rete trasferisca i dati, non deve spingere forte sulla CPU poiché deve rimanere inattiva per la maggior parte del tempo.
Speriamo che tu abbia trovato questo breve blog interessante e forse ti incoraggerà a sperimentare alcune delle funzionalità e delle opzioni non così comunemente utilizzate di MariaBackup. Se desideri condividere parte della tua esperienza, vorremmo sentirti nei commenti qui sotto.