L'utilizzo di un ambiente multi-cloud o multi-datacenter è utile per topologie geo-distribuite o anche per un piano di ripristino di emergenza, e attualmente sta diventando sempre più popolare, quindi il concetto di split-brain sta diventando anche più importante in quanto il rischio di averlo aumenta in questo tipo di scenario. Devi prevenire un cervello diviso per evitare potenziali perdite o incoerenze dei dati, che potrebbero essere un grosso problema per l'azienda.
In questo blog vedremo cos'è uno split brain e come ClusterControl può aiutarti a evitare questo importante problema.
Cos'è il cervello diviso?
Nel mondo PostgreSQL, lo split-brain si verifica quando è disponibile più di un nodo primario contemporaneamente (senza alcuno strumento di terze parti per avere un ambiente multi-master) che consente all'applicazione di scrivere in entrambi i nodi. In questo caso, avrai informazioni diverse su ciascun nodo, che generano incoerenze di dati nel cluster. Risolvere questo problema potrebbe essere difficile poiché devi unire i dati, cosa che a volte non è possibile.
PostgreSQL Split-Brain in una topologia multi-cloud
Supponiamo che tu abbia la seguente topologia multi-cloud per PostgreSQL (che è una topologia abbastanza comune al giorno d'oggi):
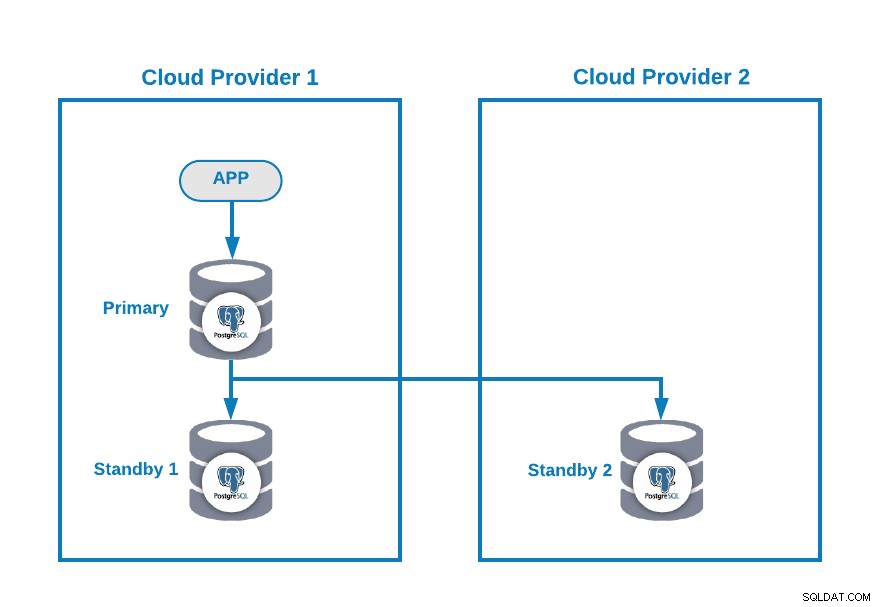
Ovviamente, puoi migliorare questo ambiente aggiungendo, ad esempio, un Application Server nel Cloud Provider 2, ma in questo caso utilizziamo questa configurazione di base.
Se il tuo nodo primario è inattivo, uno dei nodi standby dovrebbe essere promosso come nuovo primario e dovresti cambiare l'indirizzo IP nella tua applicazione per usare questo nuovo nodo primario.
Ci sono diversi modi per farlo in modo automatico. Ad esempio, puoi utilizzare un indirizzo IP virtuale assegnato al tuo nodo principale e monitorarlo. Se fallisce, promuovi uno dei nodi standby e migra l'indirizzo IP virtuale su questo nuovo nodo primario, quindi non devi modificare nulla nella tua applicazione e questo può essere fatto usando il tuo script o strumento.
Al momento non hai alcun problema, ma... se il tuo vecchio nodo primario ritorna, devi assicurarti di non avere due nodi primari nello stesso cluster contemporaneamente .
I metodi più comuni per evitare questa situazione sono:
- STONITH:spara all'altro nodo nella testa.
- SMITH:sparami alla testa.
PostgreSQL non fornisce alcun modo per automatizzare questo processo. Devi farcela da solo.
Come evitare il cervello diviso in PostgreSQL con ClusterControl
Ora, vediamo come ClusterControl può aiutarti in questo compito.
In primo luogo, puoi usarlo per distribuire o importare il tuo ambiente PostgreSQL Multi-Cloud in modo semplice, come puoi vedere in questo post del blog.
Quindi, puoi migliorare la tua topologia aggiungendo un Load Balancer (HAProxy), cosa che puoi fare anche usando ClusterControl seguendo questo blog. Quindi, avrai qualcosa del genere:
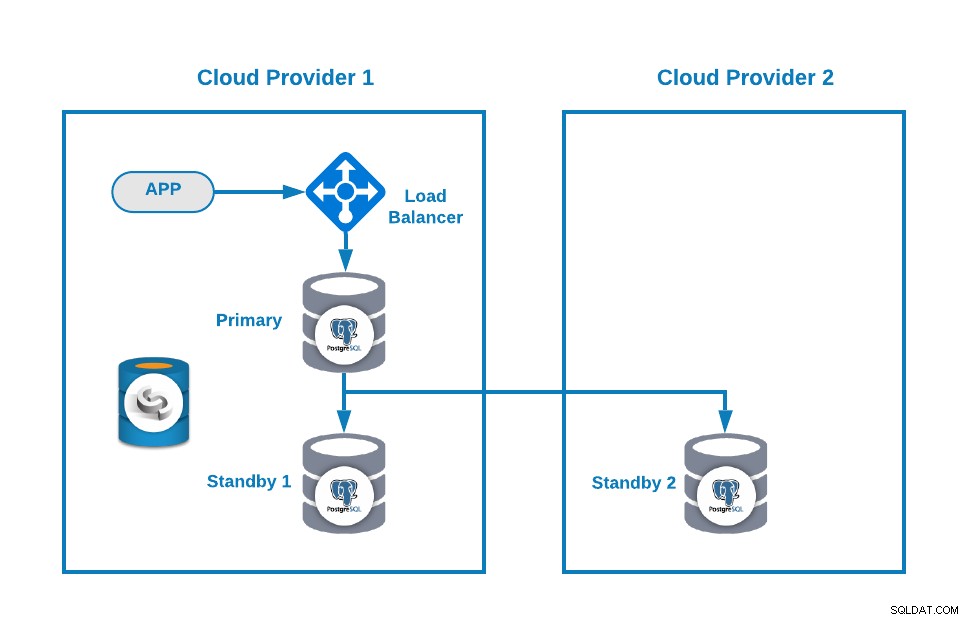
ClusterControl ha una funzione di failover automatico che rileva gli errori del master e promuove uno standby nodo con i dati più recenti come nuovo primario. Inoltre, esegue il failover sul resto dei nodi di standby per replicare dal nuovo nodo primario.
HAProxy è configurato da ClusterControl con due porte diverse per impostazione predefinita, una di lettura-scrittura e una di sola lettura. Nella porta di lettura-scrittura, hai il tuo nodo principale come online e il resto dei tuoi nodi come offline e nella porta di sola lettura hai sia il nodo primario che quello di standby online. In questo modo puoi bilanciare il traffico di lettura tra i tuoi nodi ma ti assicuri che al momento della scrittura venga utilizzata la porta di lettura-scrittura, scrivendo nel nodo primario che è il server che è online.
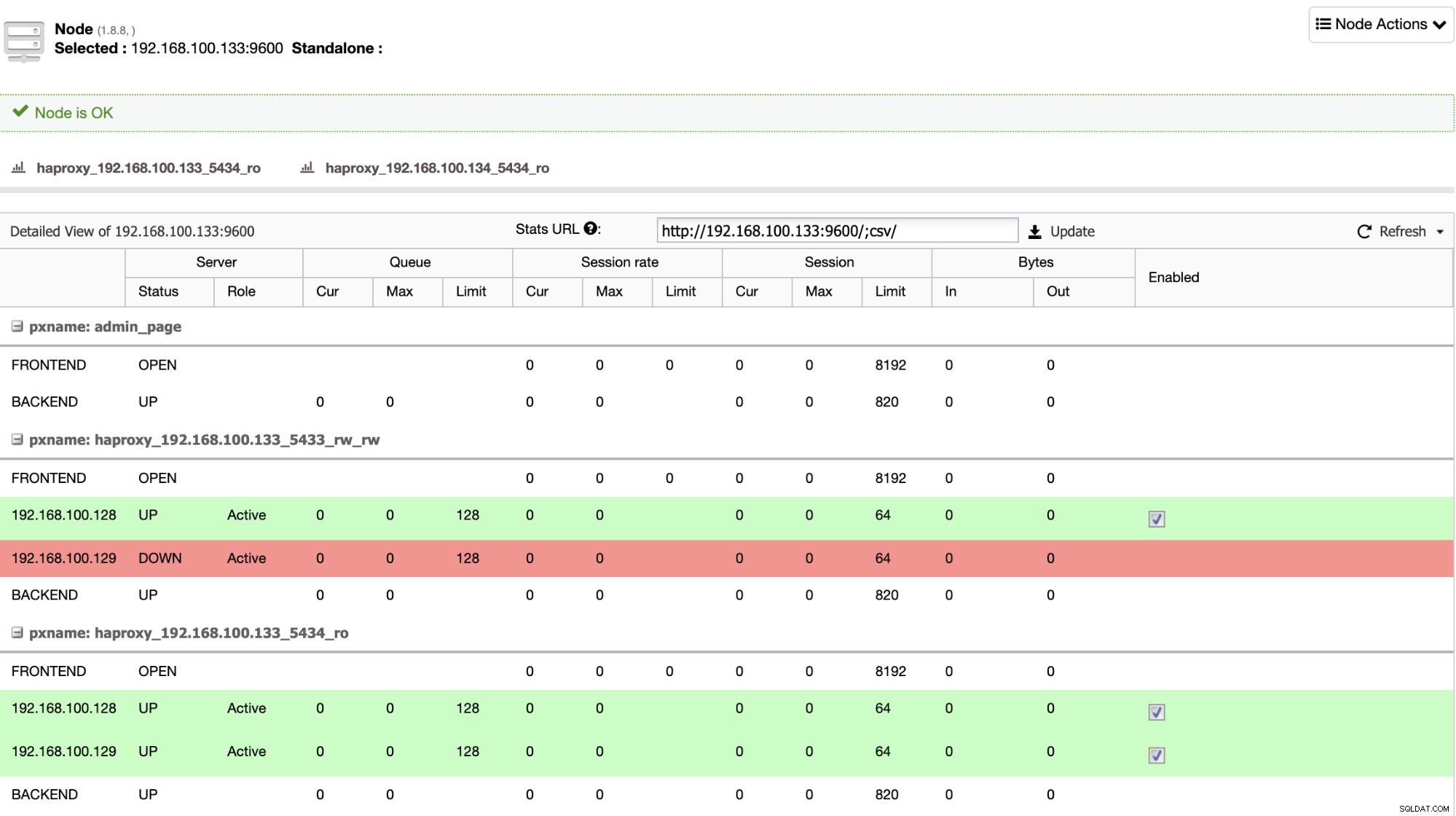
Quando HAProxy rileva che uno dei tuoi nodi, primario o standby, è non accessibile, lo contrassegna automaticamente come offline e non ne tiene conto per l'invio di traffico ad esso. Questo controllo viene eseguito dagli script di controllo dello stato configurati da ClusterControl al momento della distribuzione. Questi controllano se le istanze sono attive, se sono in fase di ripristino o sono di sola lettura.
Se il tuo vecchio nodo primario ritorna, ClusterControl eviterà anche di avviarlo, per prevenire un potenziale split-brain nel caso in cui tu abbia una connessione diretta che non utilizza Load Balancer, ma puoi aggiungerlo al cluster come nodo di standby in modo automatico o manuale utilizzando l'interfaccia utente o la CLI ClusterControl, quindi puoi promuoverlo in modo che abbia la stessa topologia in esecuzione prima del problema.
Conclusione
Con l'opzione "Ripristino automatico" attiva, ClusterControl eseguirà questo failover automatico e ti avviserà del problema. In questo modo, i tuoi sistemi possono ripristinarsi in pochi secondi senza il tuo intervento ed eviterai uno split brain in un ambiente PostgreSQL Multi-Cloud.
Puoi anche migliorare il tuo ambiente ad alta disponibilità aggiungendo più nodi ClusterControl utilizzando la funzione CMON HA descritta in questo blog.