Il failover è la capacità di un sistema di continuare a funzionare anche se si verifica un errore. Suggerisce che le funzioni del sistema siano assunte dai componenti secondari se i componenti primari si guastano o se è necessario. Quindi, se lo traduci in un ambiente multi-cloud PostgreSQL, significa che quando il tuo nodo primario si guasta (o un altro motivo come menzioneremo nella prossima sezione) nel tuo provider cloud primario, devi essere in grado di promuovere il nodo di standby in quello secondario per mantenere in funzione i sistemi.
In generale, tutti i provider cloud offrono un'opzione di failover nello stesso provider cloud, ma potrebbe essere necessario eseguire il failover su un altro provider cloud diverso. Ovviamente puoi farlo manualmente, ma puoi anche utilizzare alcune delle funzionalità di ClusterControl come il failover automatico o promuovere l'azione slave per farlo in modo semplice e intuitivo.
In questo blog, vedrai perché dovresti aver bisogno del failover, come farlo manualmente e come usare ClusterControl per questa attività. Supponiamo che tu abbia un'installazione ClusterControl in esecuzione e che il tuo cluster di database sia già stato creato in due diversi provider cloud.
A cosa serve il failover?
Ci sono diversi possibili usi del failover.
Guasto principale
Se il tuo nodo principale è inattivo o anche se il tuo provider cloud principale ha dei problemi, devi eseguire il failover per garantire la disponibilità del tuo sistema. In questo caso, potrebbe essere necessario disporre di un modo automatico per farlo per ridurre i tempi di fermo.
Migrazione
Se desideri migrare i tuoi sistemi da un Cloud Provider a un altro riducendo al minimo i tempi di inattività, puoi utilizzare il failover. È possibile creare una replica nel provider cloud secondario e, una volta sincronizzata, è necessario arrestare il sistema, promuovere la replica e il failover prima di indirizzare il sistema al nuovo nodo primario nel provider cloud secondario.
Manutenzione
Se devi eseguire qualsiasi attività di manutenzione sul tuo nodo primario PostgreSQL, puoi promuovere la tua replica, eseguire l'attività e ricostruire il tuo vecchio nodo primario come nodo di standby.
Dopo questo, puoi promuovere il vecchio primario e ripetere il processo di ricostruzione sul nodo di standby, tornando allo stato iniziale.
In questo modo potresti lavorare sul tuo server, senza correre il rischio di essere offline o perdere informazioni durante l'esecuzione di qualsiasi attività di manutenzione.
Aggiornamenti
È possibile aggiornare la versione di PostgreSQL (a partire da PostgreSQL 10) o persino aggiornare il sistema operativo utilizzando la replica logica senza tempi di inattività, come è possibile fare con altri motori.
I passaggi sarebbero gli stessi della migrazione a un nuovo provider cloud, solo che la tua replica sarebbe in una versione PostgreSQL o OS più recente e devi utilizzare la replica logica poiché non puoi utilizzare lo streaming replica tra diverse versioni.
Il failover non riguarda solo il database, ma anche l'applicazione. Come fanno a sapere a quale database connettersi? Probabilmente non vorrai dover modificare la tua applicazione, poiché ciò estenderà solo i tempi di inattività, quindi puoi configurare un Load Balancer che quando il tuo nodo primario è inattivo, punterà automaticamente al server che è stato promosso.
Avere una singola istanza di Load Balancer non è l'opzione migliore in quanto può diventare un singolo punto di errore. Pertanto, puoi anche implementare il failover per Load Balancer, utilizzando un servizio come Keepalived. In questo modo, se hai un problema con il tuo Load Balancer primario, Keepalived migrerà l'IP virtuale al tuo Load Balancer secondario e tutto continuerà a funzionare in modo trasparente.
Un'altra opzione è l'uso del DNS. Promuovendo il nodo di standby nel Cloud Provider secondario, modifichi direttamente l'indirizzo IP del nome host che punta al nodo primario. In questo modo eviti di dover modificare la tua applicazione e, sebbene non possa essere eseguita automaticamente, è un'alternativa se non vuoi implementare un Load Balancer.
Come eseguire il failover manuale di PostgreSQL
Prima di eseguire un failover manuale, è necessario controllare lo stato della replica. Potrebbe essere possibile che, quando è necessario eseguire il failover, il nodo di standby non è aggiornato, a causa di un errore di rete, un carico elevato o un altro problema, quindi è necessario assicurarsi che il nodo di standby abbia tutto (o quasi tutte le informazioni. Se hai più di un nodo in standby, dovresti anche controllare quale è il nodo più avanzato e sceglierlo per il failover.
postgres=# SELECT CASE WHEN pg_last_wal_receive_lsn()=pg_last_wal_replay_lsn()
postgres-# THEN 0
postgres-# ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
postgres-# END AS log_delay;
log_delay
-----------
0
(1 row)Quando scegli il nuovo nodo primario, puoi prima eseguire il comando pg_lsclusters per ottenere le informazioni sul cluster:
$ pg_lsclusters
Ver Cluster Port Status Owner Data directory Log file
12 main 5432 online,recovery postgres /var/lib/postgresql/12/main log/postgresql-%Y-%m-%d_%H%M%S.logQuindi, devi solo eseguire il comando pg_ctlcluster con l'azione di promozione:
$ pg_ctlcluster 12 main promoteInvece del comando precedente, puoi eseguire il comando pg_ctl in questo modo:
$ /usr/lib/postgresql/12/bin/pg_ctl promote -D /var/lib/postgresql/12/main/
waiting for server to promote.... done
server promotedQuindi, il tuo nodo di standby verrà promosso a primario e puoi convalidarlo eseguendo la seguente query nel tuo nuovo nodo primario:
postgres=# select pg_is_in_recovery();
pg_is_in_recovery
-------------------
f
(1 row)Se il risultato è "f", è il tuo nuovo nodo primario.
Ora, devi modificare l'indirizzo IP del database primario nella tua applicazione, nel Load Balancer, nel DNS o nell'implementazione che stai utilizzando e, come accennato, la modifica manuale aumenterà i tempi di inattività. Devi anche assicurarti che la tua connettività tra i provider potrebbe funzionare correttamente, l'applicazione può accedere al nuovo nodo primario, l'utente dell'applicazione ha i privilegi per accedervi da un provider cloud diverso e dovresti ricostruire i nodi di standby in remoto o anche nel provider cloud locale, per replicare dal nuovo primario, altrimenti non avrai una nuova opzione di failover se necessario.
Come eseguire il failover di PostgreSQL utilizzando ClusterControl
ClusterControl ha una serie di funzionalità relative alla replica PostgreSQL e al failover automatico. Assumiamo che tu abbia installato il tuo server ClusterControl e che stia gestendo il tuo ambiente Multi-Cloud PostgreSQL.
Con ClusterControl, puoi aggiungere tutti i nodi standby o nodi Load Balancer di cui hai bisogno senza alcuna restrizione IP di rete. Significa che non è necessario che il nodo di standby si trovi nella stessa rete del nodo primario o anche nello stesso provider cloud. In termini di failover, ClusterControl consente di farlo manualmente o automaticamente.
Failover manuale
Per eseguire un failover manuale, vai su ClusterControl -> Seleziona Cluster -> Nodi e nelle Azioni del nodo di uno dei tuoi nodi di standby, seleziona "Promuovi slave".
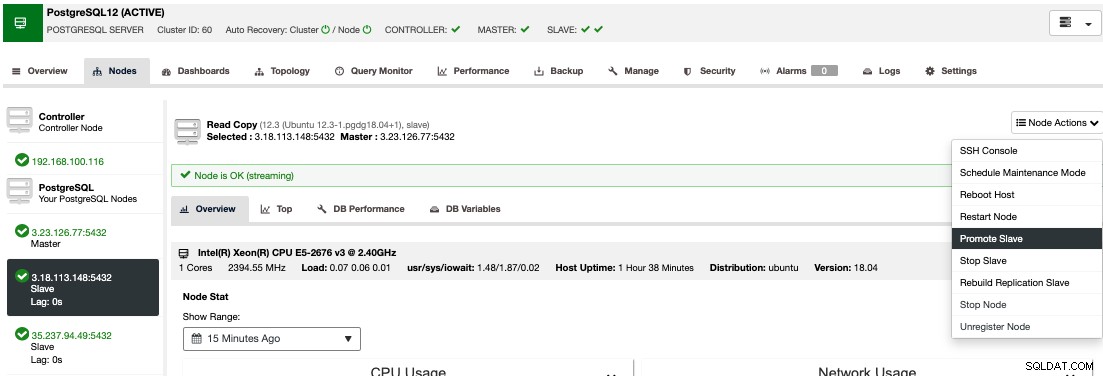
In questo modo, dopo pochi secondi, il tuo nodo di standby diventa primario, e quello che era il tuo principale in precedenza, viene trasformato in uno standby. Quindi, se la tua replica era in un altro provider cloud, il tuo nuovo nodo primario sarà lì, attivo e funzionante.
Failover automatico
Nel caso di failover automatico, ClusterControl rileva gli errori nel nodo primario e promuove un nodo standby con i dati più aggiornati come nuovo primario. Funziona anche sul resto dei nodi di standby per replicarli da questo nuovo primario.

Con l'opzione "Autorecovery" attiva, ClusterControl eseguirà un failover automatico come oltre ad avvisarti del problema. In questo modo, i tuoi sistemi possono ripristinarsi in pochi secondi e senza il tuo intervento.
ClusterControl ti offre la possibilità di configurare una whitelist/blacklist per definire come vuoi che i tuoi server vengano presi (o non presi in considerazione) quando decidi un candidato principale.
ClusterControl esegue anche diversi controlli sul processo di failover, ad esempio, per impostazione predefinita, se riesci a ripristinare il tuo vecchio nodo primario guasto, non verrà reintrodotto automaticamente nel cluster, né come primario né come standby, dovrai farlo manualmente. Ciò eviterà la possibilità di perdita o incoerenza dei dati nel caso in cui il tuo standby (che hai promosso) fosse ritardato al momento dell'errore. Potresti anche voler analizzare il problema in dettaglio, ma quando lo aggiungi al tuo cluster, potresti perdere le informazioni diagnostiche.
Bilanciatori di carico
Come accennato in precedenza, Load Balancer è uno strumento importante da considerare per il failover, soprattutto se si desidera utilizzare il failover automatico nella topologia del database.
Affinché il failover sia trasparente sia per l'utente che per l'applicazione, è necessario un componente intermedio, poiché non è sufficiente per promuovere un nuovo nodo primario. Per questo, puoi usare HAProxy + Keepalived.
Per implementare questa soluzione con ClusterControl, vai su Cluster Actions -> Add Load Balancer -> HAProxy sul tuo cluster PostgreSQL. Nel caso in cui desideri implementare il failover per il tuo Load Balancer, devi configurare almeno due istanze HAProxy, quindi puoi configurare Keepalived (Azioni cluster -> Aggiungi Load Balancer -> Keepalived). Puoi trovare maggiori informazioni su questa implementazione in questo post del blog.
Dopo questo, avrai la seguente topologia:

HAProxy è configurato per impostazione predefinita con due porte diverse, una di lettura-scrittura e uno di sola lettura.
Nella porta di lettura-scrittura, hai il tuo nodo principale come online e il resto dei nodi come offline. Nella porta di sola lettura, hai sia il nodo primario che quello standby online. In questo modo è possibile bilanciare il traffico di lettura tra i nodi. Durante la scrittura, verrà utilizzata la porta di lettura-scrittura, che punterà al nodo primario corrente.

Quando HAProxy rileva che uno dei nodi, primario o standby, è non accessibile, lo contrassegna automaticamente come offline. HAProxy non invierà alcun traffico ad esso. Questo controllo viene eseguito dagli script di controllo dello stato configurati da ClusterControl al momento della distribuzione. Questi controllano se le istanze sono attive, se sono in fase di ripristino o sono di sola lettura.
Quando ClusterControl promuove un nuovo nodo primario, HAProxy contrassegna quello vecchio come offline (per entrambe le porte) e mette il nodo promosso online nella porta di lettura-scrittura. In questo modo, i tuoi sistemi continuano a funzionare normalmente.
Se l'HAProxy attivo (che ha assegnato un indirizzo IP virtuale a cui si connettono i sistemi) fallisce, Keepalived migra automaticamente questo IP virtuale all'HAProxy passivo. Ciò significa che i tuoi sistemi potranno continuare a funzionare normalmente.
Replica da cluster a cluster nel cloud
Per avere un ambiente multi-cloud, puoi utilizzare l'azione ClusterControl Aggiungi slave sul tuo cluster PostgreSQL, ma anche la funzione di replica da cluster a cluster. Al momento, questa funzionalità ha una limitazione per PostgreSQL che ti consente di avere un solo nodo remoto, ma stiamo lavorando per rimuovere questa limitazione presto in una versione futura.
Per implementarlo, puoi controllare la sezione "Replica da cluster a cluster nel cloud" in questo post del blog.

Quando è a posto, puoi promuovere il cluster remoto che genererà un cluster PostgreSQL indipendente con un nodo primario in esecuzione sul provider cloud secondario.

Quindi, nel caso ne avessi bisogno, avrai lo stesso cluster in esecuzione in un nuovo provider cloud in pochi secondi.
Conclusione
Disporre di un processo di failover automatico è obbligatorio se si desidera ridurre il più possibile i tempi di inattività e anche l'utilizzo di diverse tecnologie come HAProxy e Keepalived migliorerà questo failover.
Le funzionalità ClusterControl che abbiamo menzionato sopra ti consentiranno di eseguire rapidamente il failover tra diversi Cloud Provider e gestire l'installazione in modo semplice e intuitivo.
La cosa più importante da tenere in considerazione prima di eseguire un processo di failover tra diversi Cloud Provider è la connettività. Devi assicurarti che la tua applicazione o le tue connessioni al database funzionino come di consueto utilizzando il provider cloud principale ma anche quello secondario in caso di failover e, per motivi di sicurezza, devi limitare il traffico solo da fonti note, quindi solo tra il Cloud Provider e non consentirlo da alcuna fonte esterna.