L'esecuzione di un cluster Galera in un cloud ibrido dovrebbe consistere in almeno due siti geografici diversi, che collegano gli host nel cloud locale o privato con quelli nel cloud pubblico. Sia che tu utilizzi un cloud privato infrangibile o piattaforme cloud pubbliche, il Disaster Recovery (DR) è davvero un problema chiave. Non si tratta di copiare i dati su un sito di backup ed essere in grado di ripristinarli, ma di continuità aziendale e della velocità con cui è possibile ripristinare i servizi in caso di disastro.
In questo post del blog, esamineremo diversi modi per progettare i cluster Galera per la tolleranza agli errori in un ambiente cloud ibrido.
Impostazione Attivo-Attivo
Galera Cluster dovrebbe essere in esecuzione con un numero dispari di nodi in un cluster e in genere inizia con 3 nodi. Questo perché Galera Cluster utilizza il quorum per determinare automaticamente il componente primario, in cui la maggior parte dei nodi connessi dovrebbe essere in grado di servire il cluster alla volta, in caso di partizionamento del cluster.
Per una configurazione di cloud ibrido con configurazione attiva-attiva, Galera richiede almeno 3 siti diversi, formando un cluster Galera su WAN. In genere, è necessario un terzo sito che agisca da arbitro, votando per il quorum e preservando la "componente principale" se uno qualsiasi dei siti è irraggiungibile. Questo può essere impostato come minimo di un cluster a 3 nodi su 3 siti diversi (1 nodo per sito), simile al diagramma seguente:
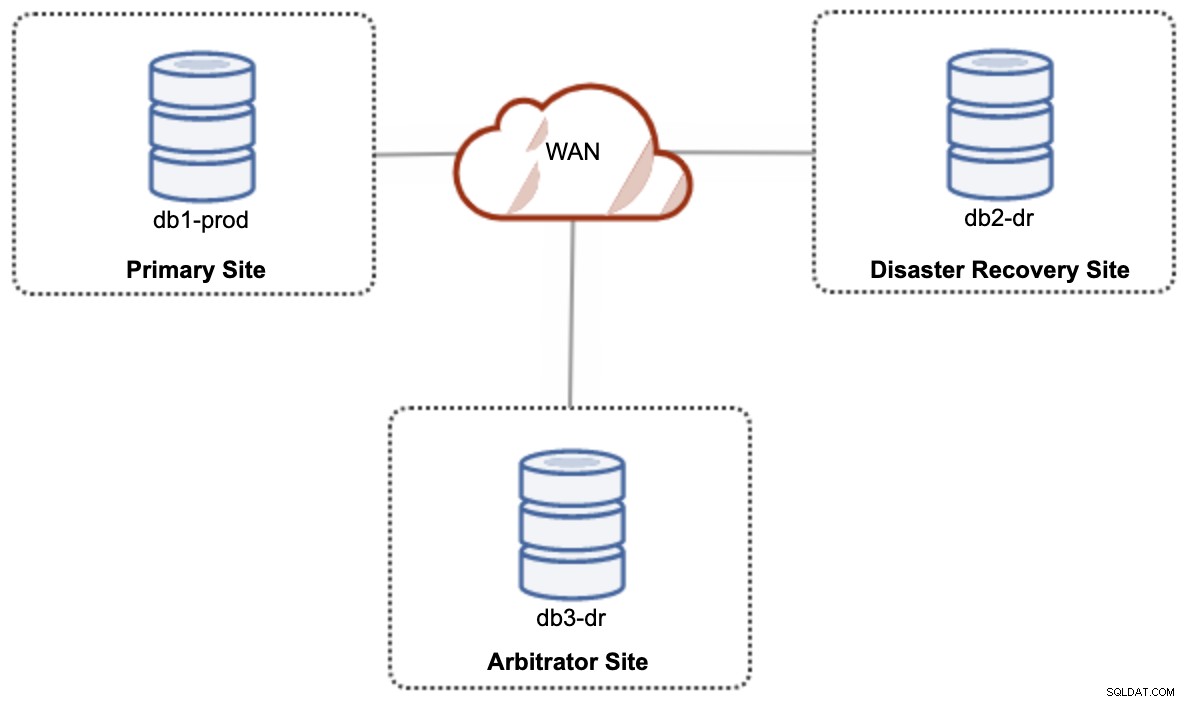
Tuttavia, per motivi di prestazioni e affidabilità, si consiglia di avere un 7 -node cluster, come mostrato nel diagramma seguente:
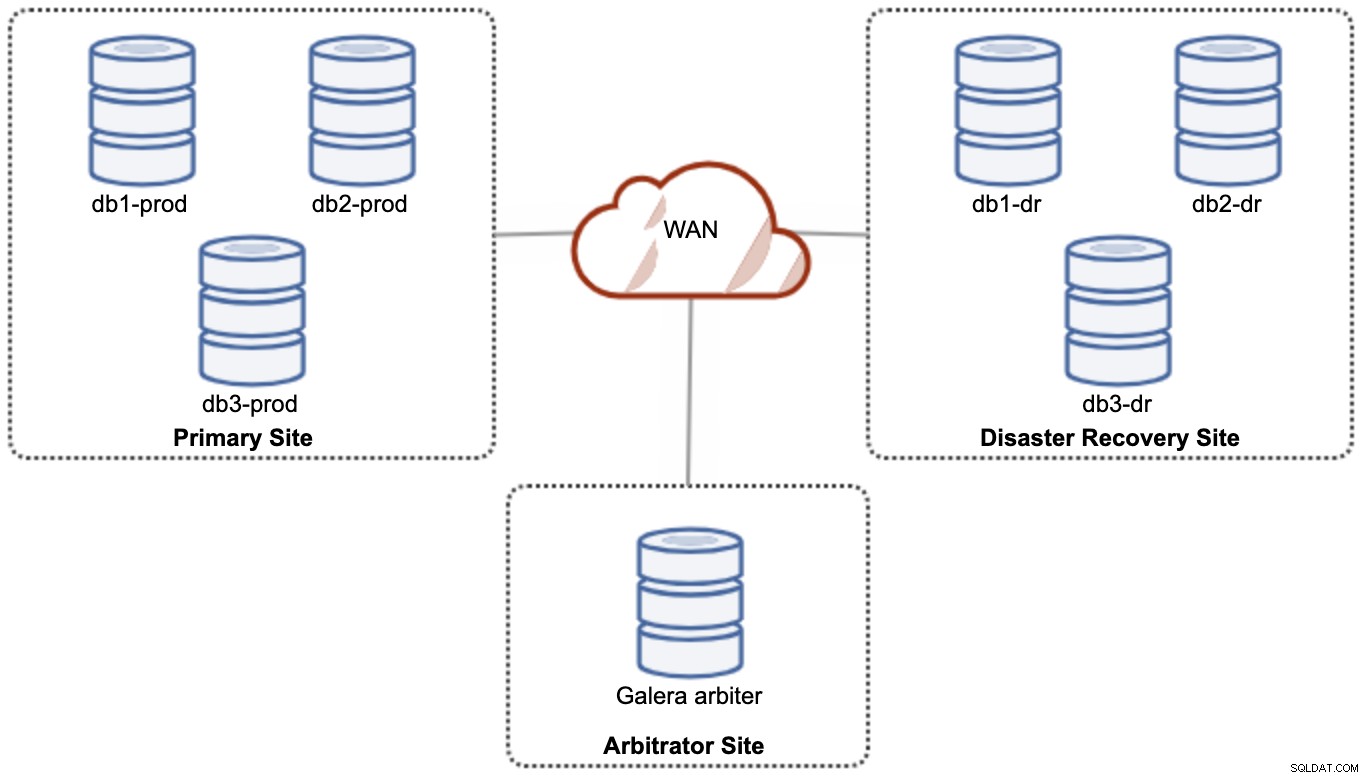
Questa è considerata la migliore topologia per supportare una configurazione attivo-attivo, in cui il sito DR dovrebbe essere disponibile quasi immediatamente, senza alcun intervento. Entrambi i siti possono ricevere letture/scritture in qualsiasi momento a condizione che il cluster sia nel quorum.
Tuttavia, è molto costoso avere 3 siti e 7 nodi di database (il settimo nodo può essere sostituito con un garbd poiché è molto improbabile che venga utilizzato per fornire dati ai client/applicazioni). Questa di solito non è una distribuzione popolare all'inizio del progetto a causa dell'enorme costo iniziale e della sensibilità della comunicazione e della replica del gruppo Galera alla latenza della rete.
Impostazione attiva-passiva
In una configurazione attivo-passivo, sono necessari almeno 2 siti ed è attivo un solo sito alla volta, noto come sito primario e i nodi del sito secondario replicano solo i dati provenienti dal sito primario server/cluster. Per Galera Cluster, possiamo utilizzare la replica asincrona MySQL (replica master-slave) oppure possiamo anche usare la replica virtualmente sincrona di Galera con alcune modifiche per attenuare la sua replica del writeset in modo che funga da replica asincrona.
Il sito secondario deve essere protetto da scritture accidentali, utilizzando il flag di sola lettura, il firewall dell'applicazione, il proxy inverso o qualsiasi altro mezzo poiché il flusso di dati proviene sempre dal sito primario al sito secondario, a meno che un failover ha avviato e promosso il sito secondario come principale.
Utilizzo della replica asincrona
Un aspetto positivo della replica asincrona è che la replica non ha alcun impatto sul server/cluster di origine, ma può rimanere indietro rispetto al master. Questa configurazione renderà il sito primario e quello di ripristino di emergenza indipendenti l'uno dall'altro, collegati in modo approssimativo con la replica asincrona. Questo può essere impostato come un cluster minimo di 4 nodi su 2 siti diversi, in modo simile al diagramma seguente:
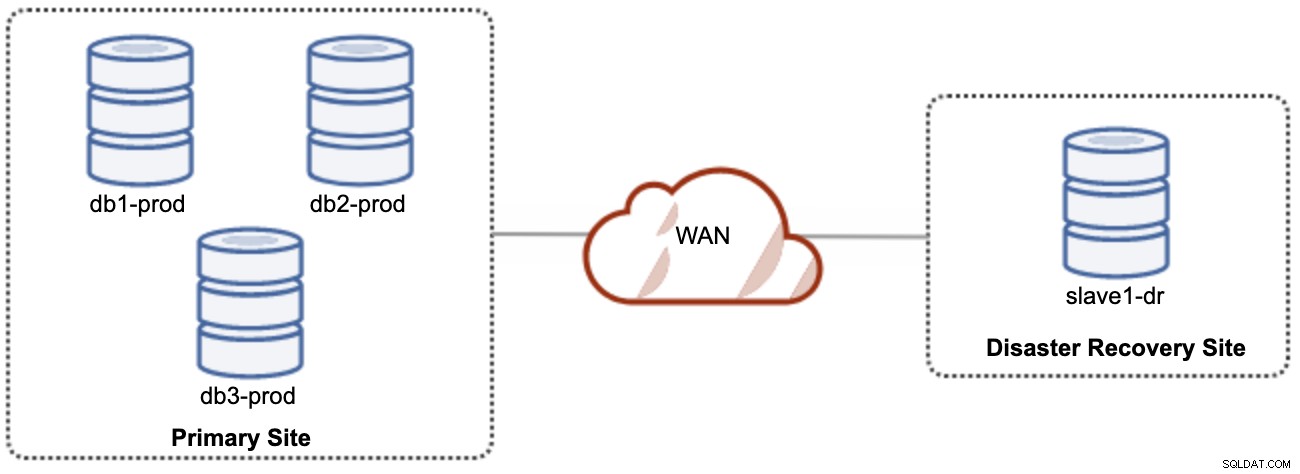
Uno dei nodi Galera nel sito DR sarà uno slave, che replica da uno dei nodi Galera (master) nel sito primario. Entrambi i siti devono produrre log binari con GTID e log_slave_updates sono abilitati:gli aggiornamenti provenienti dal flusso di replica asincrono verranno applicati agli altri nodi del cluster. Tuttavia, per l'utilizzo in produzione, consigliamo di avere due set di cluster su entrambi i siti, come mostrato nel diagramma seguente:
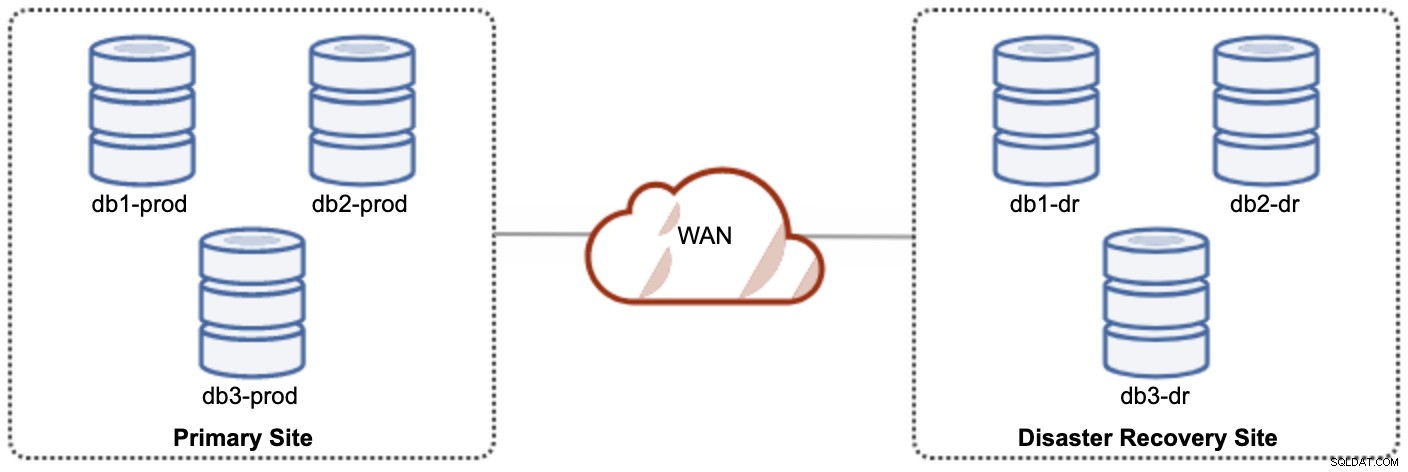
Avendo due cluster separati, saranno accoppiati in modo lasco e non si influenzeranno a vicenda, ad es. un errore del cluster nel sito primario non influirà sul sito di ripristino di emergenza. Dal punto di vista delle prestazioni, la latenza WAN non influirà sugli aggiornamenti sul cluster attivo. Questi vengono spediti in modo asincrono al sito di backup. Il cluster di ripristino di emergenza potrebbe potenzialmente essere eseguito su istanze più piccole in un ambiente cloud pubblico, purché possano stare al passo con il cluster principale. Le istanze possono essere aggiornate se necessario. Le applicazioni devono inviare le scritture al sito principale e il sito secondario deve essere impostato per l'esecuzione in modalità di sola lettura. Il sito di ripristino di emergenza può essere utilizzato per altri scopi come il backup del database, il backup dei registri binari e la creazione di report o l'elaborazione di query analitiche (OLAP).
Il lato negativo è che c'è la possibilità di perdita di dati durante il failover/fallback se lo slave era in ritardo. Pertanto, si consiglia di abilitare la replica semisincrona per ridurre il rischio di perdita di dati. Si noti che l'utilizzo della replica semi-sincrona non fornisce ancora solide garanzie contro la perdita di dati, rispetto alla replica virtualmente sincrona di Galera. Leggi attentamente questo manuale MySQL, ad esempio queste frasi:
"Con la replica semisincrona, se l'origine si arresta in modo anomalo e viene eseguito un failover su una replica, l'origine non riuscita non deve essere riutilizzata come origine della replica e deve essere eliminata. Potrebbe contenere transazioni che erano non riconosciuto da nessuna replica, che quindi non è stata salvata prima del failover."
Il processo di failover è piuttosto semplice. Per promuovere il sito di ripristino di emergenza, disattivare semplicemente il flag di sola lettura e iniziare a indirizzare l'applicazione ai nodi del database nel sito di ripristino di emergenza. La strategia di fallback è tuttavia un po' complicata e richiede una certa esperienza nella gestione temporanea dei dati su entrambi i siti, nel cambio del ruolo master/slave di un cluster e nel reindirizzamento del flusso di replica slave nella direzione opposta.
Utilizzo della replica Galera
Per la configurazione attiva-passiva, possiamo posizionare la maggior parte dei nodi situati nel sito principale mentre la minoranza dei nodi situata nel sito di ripristino di emergenza, come mostrato nella schermata seguente per un 3- nodo Galera Cluster:
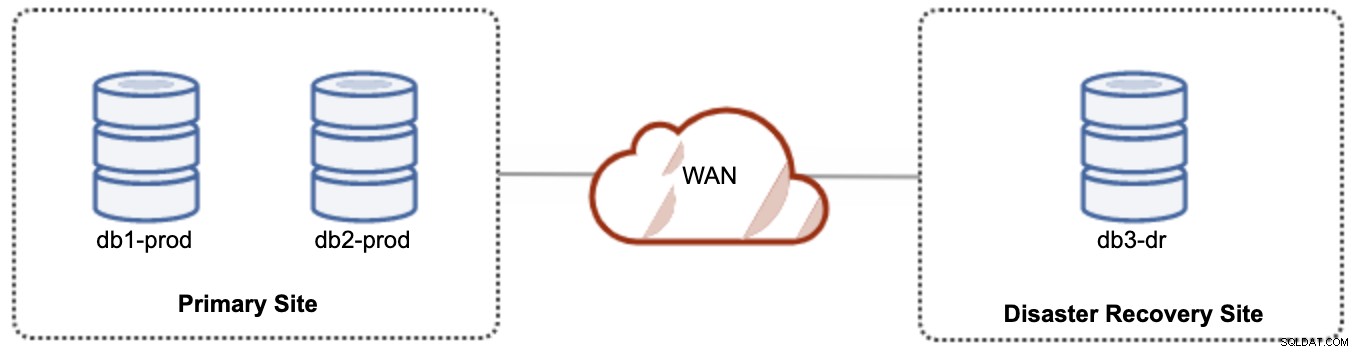
Se il sito principale è inattivo, il cluster non riuscirà perché è fuori quorum. Il nodo Galera nel sito di ripristino di emergenza (db3-dr) dovrà essere avviato manualmente come componente principale del nodo singolo. Una volta ripristinato il sito principale, entrambi i nodi sul sito primario (db1-prod e db2-prod) devono rientrare in galera3 per essere sincronizzati. Avere una gcache piuttosto grande dovrebbe aiutare a ridurre il rischio di SST su WAN. Questa architettura è facile da configurare e amministrare ed è molto conveniente.
Il failover è manuale, poiché l'amministratore deve promuovere il singolo nodo come componente principale (bootstrap db3-dr o utilizzare set pc.bootstrap=1 nel parametro wsrep_provider_options. Ci sarebbero tempi di inattività nel frattempo . Le prestazioni potrebbero essere un problema, poiché il sito DR verrà eseguito con un numero inferiore di nodi (poiché il sito DR è sempre la minoranza) per eseguire tutto il carico. Potrebbe essere possibile aumentare la scalabilità orizzontale con più nodi dopo il passaggio al Sito DR ma attenzione al carico aggiuntivo.
Si noti che Galera Cluster è sensibile alla rete a causa della sua natura virtualmente sincrona. Più i nodi Galera sono lontani in un dato cluster, maggiore è la latenza e la sua capacità di scrittura per distribuire e certificare i set di scritture. Inoltre, se la connettività non è stabile, può verificarsi facilmente il partizionamento del cluster, che potrebbe attivare la sincronizzazione del cluster sui nodi del joiner. In alcuni casi, ciò può introdurre instabilità nel cluster. Ciò richiede un po' di ottimizzazione dei parametri di Galera, come mostrato in questo post del blog, Deploying a Hybrid Infrastructure Environment for Percona XtraDB Cluster.
Pensieri finali
Galera Cluster è un'ottima tecnologia che può essere implementata in diversi modi:un cluster esteso su più siti, più cluster mantenuti sincronizzati tramite replica asincrona, una combinazione di replica sincrona e asincrona e così via. La soluzione effettiva sarà dettata da fattori come la latenza della WAN, l'eventuale coerenza dei dati e il budget elevati.