Al giorno d'oggi, la replica è un dato di fatto in un ambiente ad alta disponibilità e tolleranza ai guasti praticamente per qualsiasi tecnologia di database che stai utilizzando. È un argomento che abbiamo visto più e più volte, ma che non invecchia mai.
Se utilizzi TimescaleDB, il tipo più comune di replica è la replica in streaming, ma come funziona?
In questo blog esamineremo alcuni concetti relativi alla replica e ci concentreremo sulla replica in streaming per TimescaleDB, che è una funzionalità ereditata dal motore PostgreSQL sottostante. Quindi, vedremo come ClusterControl può aiutarci a configurarlo.
Pertanto, la replica in streaming si basa sulla spedizione dei record WAL e sulla loro applicazione al server di standby. Quindi, per prima cosa, vediamo cos'è WAL.
WAL
Write Ahead Log (WAL) è un metodo standard per garantire l'integrità dei dati, è abilitato automaticamente per impostazione predefinita.
I WAL sono i registri REDO in TimescaleDB. Ma cosa sono i registri REDO?
I registri REDO contengono tutte le modifiche apportate al database e vengono utilizzati da replica, ripristino, backup in linea e ripristino point-in-time (PITR). Eventuali modifiche che non sono state applicate alle pagine dati possono essere ripristinate dai registri REDO.
L'utilizzo di WAL comporta un numero significativamente ridotto di scritture su disco, perché solo il file di registro deve essere scaricato su disco per garantire che una transazione sia stata salvata, anziché ogni file di dati modificato dalla transazione.
Un record WAL specificherà, bit per bit, le modifiche apportate ai dati. Ciascun record WAL verrà aggiunto a un file WAL. La posizione di inserimento è un Log Sequence Number (LSN) che è un byte offset nei log, che aumenta con ogni nuovo record.
I WAL sono archiviati nella directory pg_wal, nella directory dei dati. Questi file hanno una dimensione predefinita di 16 MB (la dimensione può essere modificata alterando l'opzione --with-wal-segsize configure durante la creazione del server). Hanno un nome incrementale univoco, nel seguente formato:"00000001 00000000 00000000".
Il numero di file WAL contenuti in pg_wal dipenderà dal valore assegnato ai parametri min_wal_size e max_wal_size nel file di configurazione postgresql.conf.
Un parametro che dobbiamo impostare durante la configurazione di tutte le nostre installazioni di TimescaleDB è wal_level. Determina quante informazioni vengono scritte nel WAL. Il valore predefinito è minimo, che scrive solo le informazioni necessarie per il ripristino da un arresto anomalo o dall'arresto immediato. L'archivio aggiunge la registrazione richiesta per l'archiviazione WAL; hot_standby aggiunge inoltre le informazioni necessarie per eseguire query di sola lettura su un server in standby; e, infine, logical aggiunge le informazioni necessarie per supportare la decodifica logica. Questo parametro richiede un riavvio, quindi può essere difficile modificare i database di produzione in esecuzione se lo abbiamo dimenticato.
Replica in streaming
La replica in streaming si basa sul metodo di log shipping. I record WAL vengono spostati direttamente da un server di database a un altro per essere applicati. Possiamo dire che è un PITR continuo.
Questo trasferimento viene eseguito in due modi diversi, trasferendo i record WAL un file (segmento WAL) alla volta (log shipping basato su file) e trasferendo i record WAL (un file WAL è composto da record WAL) al volo (basato su record log shipping), tra un server master e uno o più server slave, senza attendere la compilazione del file WAL.
In pratica, un processo chiamato ricevitore WAL, in esecuzione sul server slave, si collegherà al server master utilizzando una connessione TCP/IP. Nel server master esiste un altro processo, denominato mittente WAL, incaricato di inviare i registri WAL al server slave man mano che si verificano.
La replica in streaming può essere rappresentata come segue:
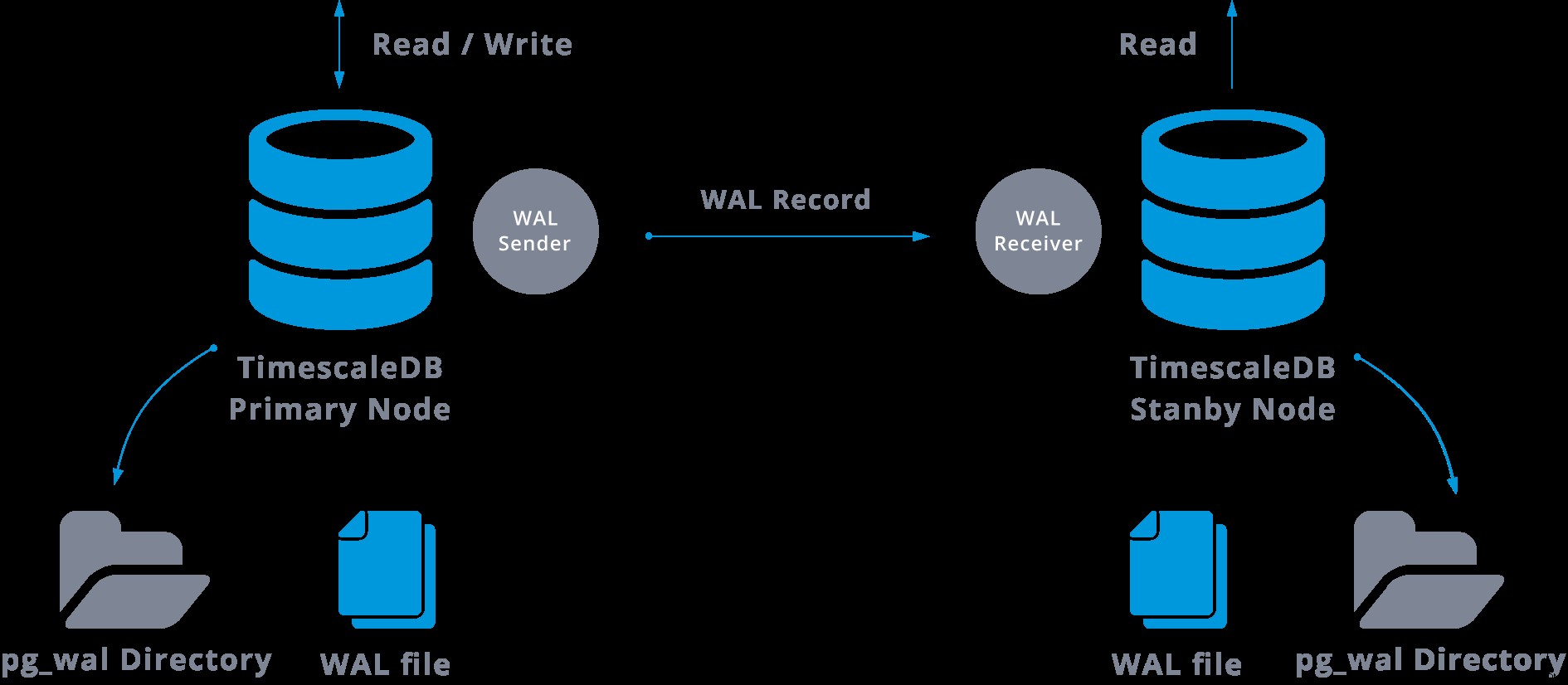
Osservando il diagramma sopra, possiamo pensare, cosa succede quando la comunicazione tra il mittente WAL e il ricevitore WAL fallisce?
Quando configuriamo la replica in streaming, abbiamo la possibilità di abilitare l'archiviazione WAL.
Questo passaggio in realtà non è obbligatorio, ma è estremamente importante per una solida configurazione della replica, poiché è necessario evitare che il server principale ricicli i vecchi file WAL che non sono ancora stati applicati allo slave. In questo caso, dovremo ricreare la replica da zero.
Quando si configura la replica con archiviazione continua, si parte da un backup e, per raggiungere lo stato on sync con il master, è necessario applicare tutte le modifiche ospitate nel WAL avvenute dopo il backup. Durante questo processo, lo standby ripristinerà prima tutto il WAL disponibile nella posizione dell'archivio (eseguito chiamando restore_command). Il restore_command fallirà quando raggiungiamo l'ultimo record WAL archiviato, quindi lo standby cercherà nella directory pg_wal per vedere se la modifica esiste lì (questo è effettivamente fatto per evitare la perdita di dati quando i server master si arrestano in modo anomalo e alcuni le modifiche che sono già state spostate nella replica e lì applicate non sono state ancora archiviate).
Se ciò non riesce e il record richiesto non esiste, inizierà a comunicare con il master tramite la replica in streaming.
Ogni volta che la replica in streaming non riesce, tornerà al passaggio 1 e ripristinerà nuovamente i record dall'archivio. Questo ciclo di recupero dall'archivio, pg_wal, e tramite la replica in streaming continua fino a quando il server non viene arrestato o il failover viene attivato da un file trigger.
Questo sarà un diagramma di tale configurazione:
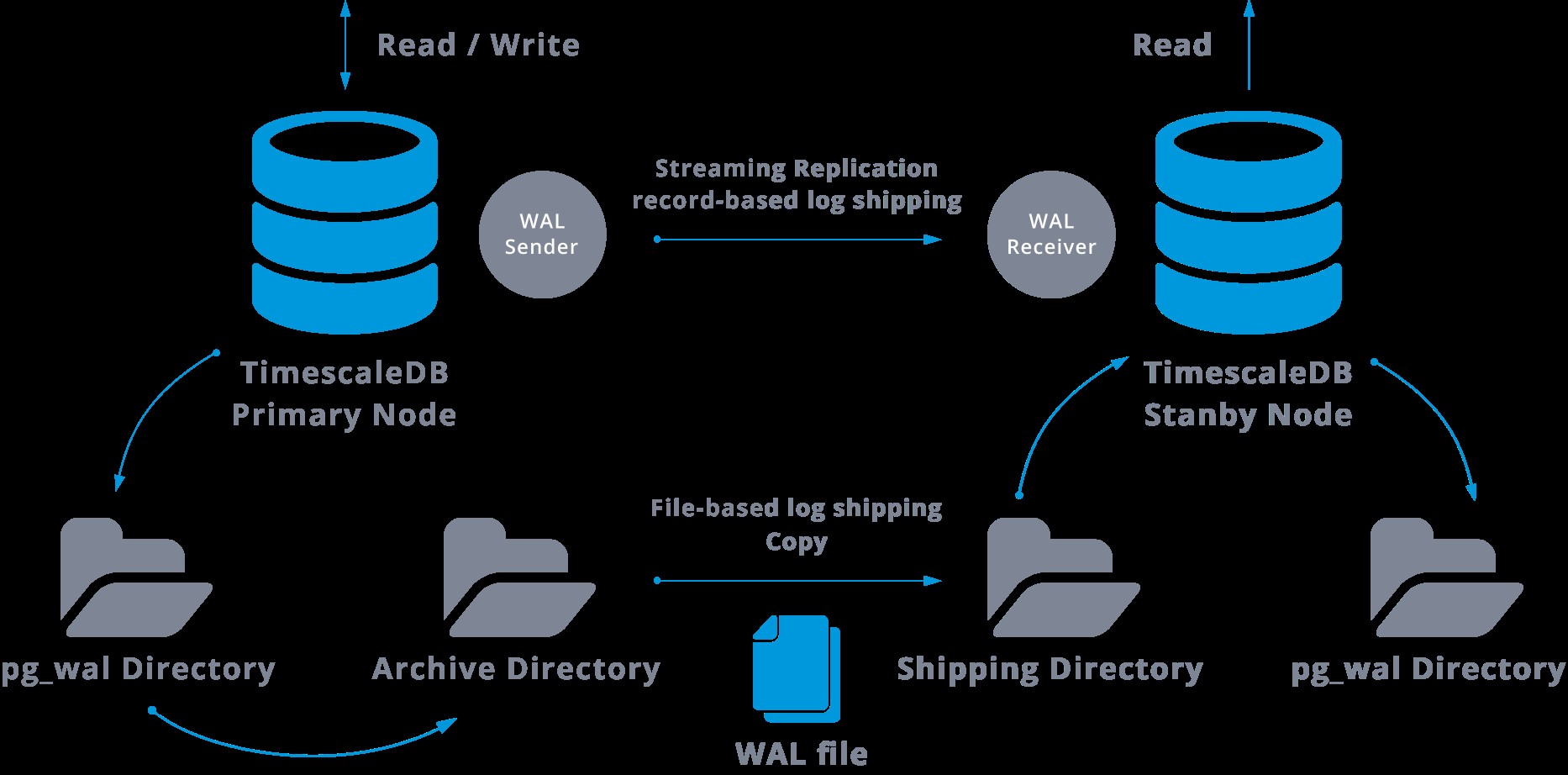
La replica in streaming è asincrona per impostazione predefinita, quindi in un dato momento possiamo avere alcune transazioni che possono essere salvate nel master e non ancora replicate nel server di standby. Ciò implica una potenziale perdita di dati.
Tuttavia, questo ritardo tra il commit e l'impatto delle modifiche nella replica dovrebbe essere davvero piccolo (alcuni millisecondi), supponendo ovviamente che il server di replica sia abbastanza potente da tenere il passo con il carico.
Per i casi in cui anche il rischio di una piccola perdita di dati non è tollerabile, possiamo utilizzare la funzione di replica sincrona.
Nella replica sincrona, ogni commit di una transazione di scrittura attenderà fino a quando non viene ricevuta la conferma che il commit è stato scritto sul disco di accesso write-ahead sia del server primario che di quello di standby.
Questo metodo riduce al minimo la possibilità di perdita di dati, poiché affinché ciò avvenga avremo bisogno che sia il master che lo standby si guastino contemporaneamente.
L'ovvio svantaggio di questa configurazione è che il tempo di risposta per ogni transazione di scrittura aumenta, poiché dobbiamo attendere che tutte le parti abbiano risposto. Quindi il tempo per un commit è, come minimo, il viaggio di andata e ritorno tra il master e la replica. Le transazioni di sola lettura non saranno interessate da ciò.
Per impostare la replica sincrona è necessario che ciascuno dei server di standby specifichi un nome_applicazione nel file primary_conninfo del file recovery.conf:primary_conninfo ='...aplication_name=slaveX' .
Dobbiamo anche specificare l'elenco dei server standby che prenderanno parte alla replica sincrona:synchronous_standby_name ='slaveX,slaveY'.
Possiamo configurare uno o più server sincroni e questo parametro specifica anche quale metodo (PRIMO e QUALSIASI) scegliere gli standby sincroni tra quelli elencati.
Per distribuire TimescaleDB con configurazioni di replica in streaming (sincrone o asincrono), possiamo utilizzare ClusterControl, come possiamo vedere qui.
Dopo aver configurato la nostra replica e averla installata e funzionante, dovremo disporre di alcune funzionalità aggiuntive per il monitoraggio e la gestione del backup. ClusterControl ci consente di monitorare e gestire backup/conservazione del nostro cluster TimescaleDB dalla stessa posizione senza alcuno strumento esterno.
Come configurare la replica in streaming su TimescaleDB
L'impostazione della replica in streaming è un'attività che richiede alcuni passaggi da seguire scrupolosamente. Se vuoi configurarlo manualmente, puoi seguire il nostro blog su questo argomento.
Tuttavia, puoi distribuire o importare il tuo TimescaleDB corrente su ClusterControl, quindi puoi configurare la replica in streaming con pochi clic. Vediamo come possiamo farlo.
Per questa attività, supponiamo che il tuo cluster TimescaleDB sia gestito da ClusterControl. Vai a ClusterControl -> Seleziona Cluster -> Azioni cluster -> Aggiungi slave di replica.
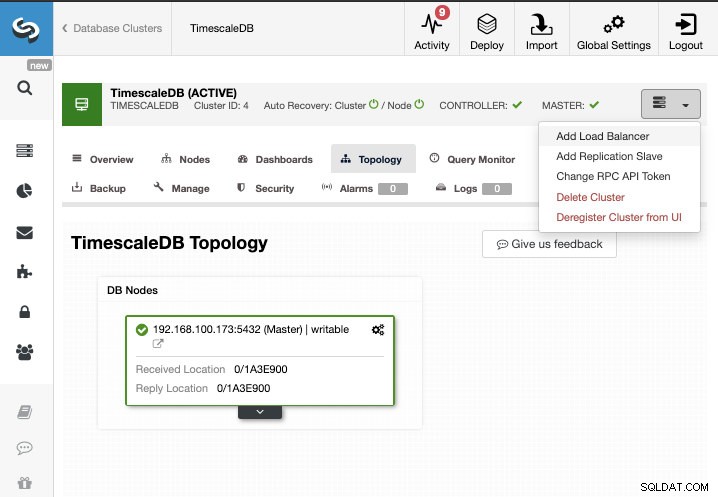
Possiamo creare un nuovo slave di replica (standby) oppure importarne uno esistente. In questo caso, ne creeremo uno nuovo.
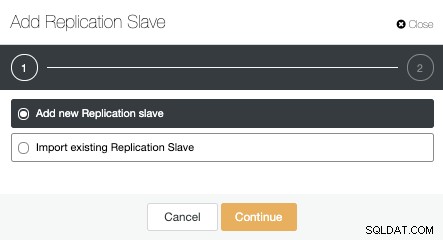
Ora dobbiamo selezionare il nodo Master, aggiungere l'indirizzo IP o il nome host per il nuovo server di standby e la porta del database. Possiamo anche specificare se vogliamo che ClusterControl installi il software e se vogliamo configurare la replica in streaming sincrona o asincrona.
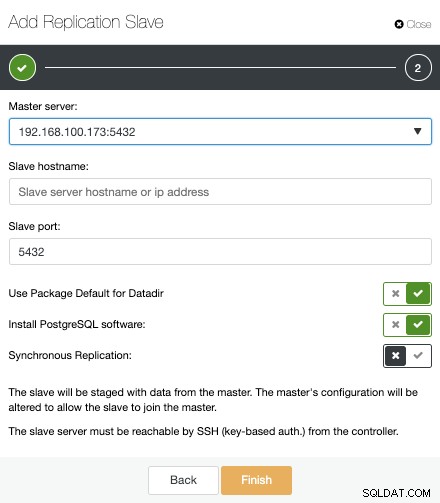
È tutto. Dobbiamo solo attendere che ClusterControl termini il lavoro. Possiamo monitorare lo stato dalla sezione Attività.
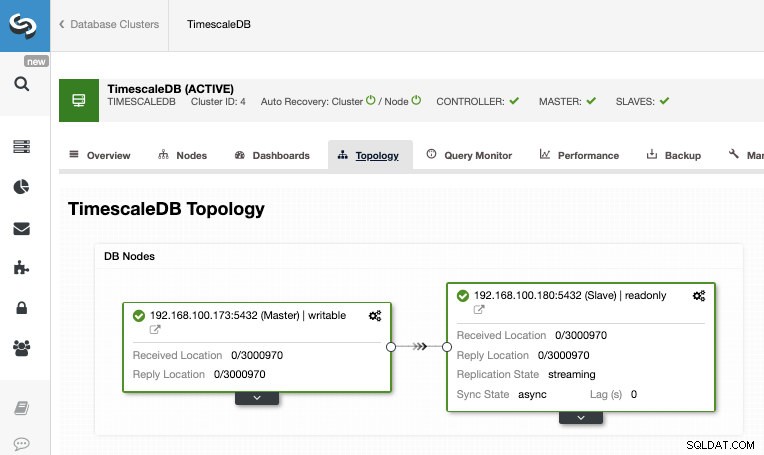
Al termine del lavoro, dovremmo avere la replica in streaming configurata e possiamo controllare la nuova topologia nella sezione ClusterControl Topology View.
Utilizzando ClusterControl, puoi anche eseguire diverse attività di gestione sul tuo TimescaleDB come backup, monitoraggio e avviso, failover automatico, aggiunta di nodi, aggiunta di sistemi di bilanciamento del carico e altro ancora.
Failover
Come abbiamo potuto vedere, TimescaleDB utilizza un flusso di record WAL (write-ahead log) per mantenere sincronizzati i database in standby. Se il server principale si guasta, lo standby contiene quasi tutti i dati del server principale e può essere rapidamente trasformato nel nuovo server di database master. Questo può essere sincrono o asincrono e può essere fatto solo per l'intero server di database.
Per garantire in modo efficace un'elevata disponibilità, non è sufficiente disporre di un'architettura master-standby. Dobbiamo anche abilitare una qualche forma automatica di failover, quindi se qualcosa fallisce possiamo avere il minor ritardo possibile nel riprendere la normale funzionalità.
TimescaleDB non include un meccanismo di failover automatico per identificare gli errori nel database master e notificare allo slave di assumerne la proprietà, quindi ciò richiederà un po' di lavoro da parte del DBA. Avrai anche un solo server funzionante, quindi è necessario ricreare l'architettura master-standby, quindi torniamo alla stessa situazione normale che avevamo prima del problema.
ClusterControl include una funzione di failover automatico per TimescaleDB per migliorare il tempo medio di ripristino (MTTR) nell'ambiente ad alta disponibilità. In caso di guasto, ClusterControl promuoverà lo slave più avanzato a master e riconfigura gli slave rimanenti per la connessione al nuovo master. HAProxy può anche essere distribuito automaticamente per offrire un unico endpoint di database alle applicazioni, in modo che non siano interessate da una modifica del server master.
Limiti
Risorse correlate ClusterControl per TimescaleDB Come distribuire facilmente TimescaleDB Replica in streaming PostgreSQL:un approfondimentoAbbiamo alcune limitazioni ben note quando si utilizza la replica in streaming:
- Non possiamo replicare in una versione o architettura diversa
- Non possiamo modificare nulla sul server di standby
- Non abbiamo molta granularità su ciò che possiamo replicare
Quindi, per superare queste limitazioni, abbiamo la funzione di replica logica. Per saperne di più su questo tipo di replica, puoi controllare il seguente blog.
Conclusione
Una topologia master-standby ha molti usi diversi come analisi, backup, disponibilità elevata e failover. In ogni caso è necessario capire come funziona la replica in streaming su TimescaleDB. È anche utile avere un sistema per gestire tutto il cluster e per darti la possibilità di creare questa topologia in modo semplice. In questo blog abbiamo visto come ottenerlo utilizzando ClusterControl e abbiamo esaminato alcuni concetti di base sulla replica in streaming.