[ Parte 1 | Parte 2 | Parte 3]
Nello spirito delle recenti invettive di Grant Fritchey, e degli sforzi di Erin Stellato da quando penso prima che ci incontrassimo, voglio salire sul carro dei vincitori per strombazzare e promuovere l'idea di abbandonare le tracce a favore di Extended Events. Quando qualcuno dice traccia , la maggior parte delle persone pensa immediatamente a Profiler . Sebbene Profiler sia il suo incubo speciale, oggi volevo parlare della traccia predefinita di SQL Server.
Nel nostro ambiente, è abilitato su tutti gli oltre 200 server di produzione e raccoglie un sacco di spazzatura che non analizzeremo mai. Tanta spazzatura, infatti, che eventi importanti che potremmo trovare utili per la risoluzione dei problemi vengono implementati dai file di traccia prima che ne abbiamo la possibilità. Così ho iniziato a considerare la prospettiva di disattivarlo, perché:
- non è non gratuito (l'overhead dell'osservatore dell'attività di traccia stessa, l'I/O coinvolto nella scrittura nei file di traccia e lo spazio che consumano);
- sulla maggior parte dei server, non è mai stato visto; su altri, raramente; e,
- è facile da riattivare per una risoluzione dei problemi specifica e isolata.
Un paio di altre cose influiscono sul valore della traccia predefinita. Non è configurabile in alcun modo:non puoi modificare gli eventi che raccoglie, non puoi aggiungere filtri e non puoi controllare quanti file conserva (5), quanto possono diventare grandi (20 MB ciascuno) o dove sono archiviati (SERVERPROPERTY('ErrorLogFileName') ). Quindi siamo completamente alla mercé del carico di lavoro:su un dato server, non possiamo prevedere quanto indietro potrebbero andare i dati (eventi con TextData più grandi i valori, ad esempio, possono occupare molto più spazio ed eliminare gli eventi meno recenti più rapidamente). A volte può tornare indietro di una settimana, altre volte può tornare indietro di pochi minuti.
Analisi dello stato attuale
Ho eseguito il codice seguente su 224 istanze di produzione, solo per capire che tipo di rumore sta riempiendo la traccia predefinita nel nostro ambiente. Questo è probabilmente più complicato di quanto dovrebbe essere e non è nemmeno così complesso come la query finale che ho usato, ma è un buon punto di partenza per analizzare la ripartizione dei tipi di eventi di alto livello che vengono attualmente acquisiti:
;WITH filesrc ([path]) AS
(
SELECT REVERSE(SUBSTRING(p, CHARINDEX(N'\', p), 260)) + N'log.trc'
FROM (SELECT REVERSE([path]) FROM sys.traces WHERE is_default = 1) s(p)
),
tracedata AS
(
SELECT Context = CASE
WHEN DDL = 1 THEN
CASE WHEN LEFT(ObjectName,8) = N'_WA_SYS_'
THEN 'AutoStat: ' + DBType
WHEN LEFT(ObjectName,2) IN (N'PK', N'UQ', N'IX') AND ObjectName LIKE N'%[_#]%'
THEN UPPER(LEFT(ObjectName,2)) + ': tempdb'
WHEN ObjectType = 17747 AND ObjectName LIKE N'TELEMETRY%'
THEN 'Telemetry'
ELSE 'Other DDL in ' + DBType END
WHEN EventClass = 116 THEN
CASE WHEN TextData LIKE N'%checkdb%' THEN 'DBCC CHECKDB'
-- several more of these ...
ELSE UPPER(CONVERT(nchar(32), TextData)) END
ELSE DBType END,
EventName = CASE WHEN DDL = 1 THEN 'DDL' ELSE EventName END,
EventSubClass,
EventClass,
StartTime
FROM
(
SELECT DDL = CASE WHEN t.EventClass IN (46,47,164) THEN 1 ELSE 0 END,
TextData = LOWER(CONVERT(nvarchar(512), t.TextData)),
EventName = e.[name],
t.EventClass,
t.EventSubClass,
ObjectName = UPPER(t.ObjectName),
t.ObjectType,
t.StartTime,
DBType = CASE WHEN t.DatabaseID = 2 OR t.ObjectName LIKE N'#%' THEN 'tempdb'
WHEN t.DatabaseID IN (1,3,4) THEN 'System database'
WHEN t.DatabaseID IS NOT NULL THEN 'User database' ELSE '?' END
FROM filesrc CROSS APPLY sys.fn_trace_gettable(filesrc.[path], DEFAULT) AS t
LEFT OUTER JOIN sys.trace_events AS e ON t.EventClass = e.trace_event_id
) AS src WHERE (EventSubClass IS NULL)
OR (EventSubClass = CASE WHEN DDL = 1 THEN 1 ELSE EventSubClass END) -- ddl_phase
)
SELECT [Instance] = @@SERVERNAME,
EventName,
Context,
EventCount = COUNT(*),
FirstSeen = MIN(StartTime),
LastSeen = MAX(StartTime)
INTO #t FROM tracedata
GROUP BY GROUPING SETS ((), (EventName, Context)); (Il predicato EventSubClass serve per impedire il doppio conteggio degli eventi DDL.Per una mappa dei valori EventClass, li ho elencati in questa risposta su Stack Exchange.)
E i risultati non sono belli (risultati tipici di un server casuale). Quanto segue non rappresenta l'output esatto di quella query, ma ho passato un po' di tempo ad aggregare i risultati in un formato più digeribile, per vedere quanti dati erano utili e quanto rumore (clicca per ingrandire):
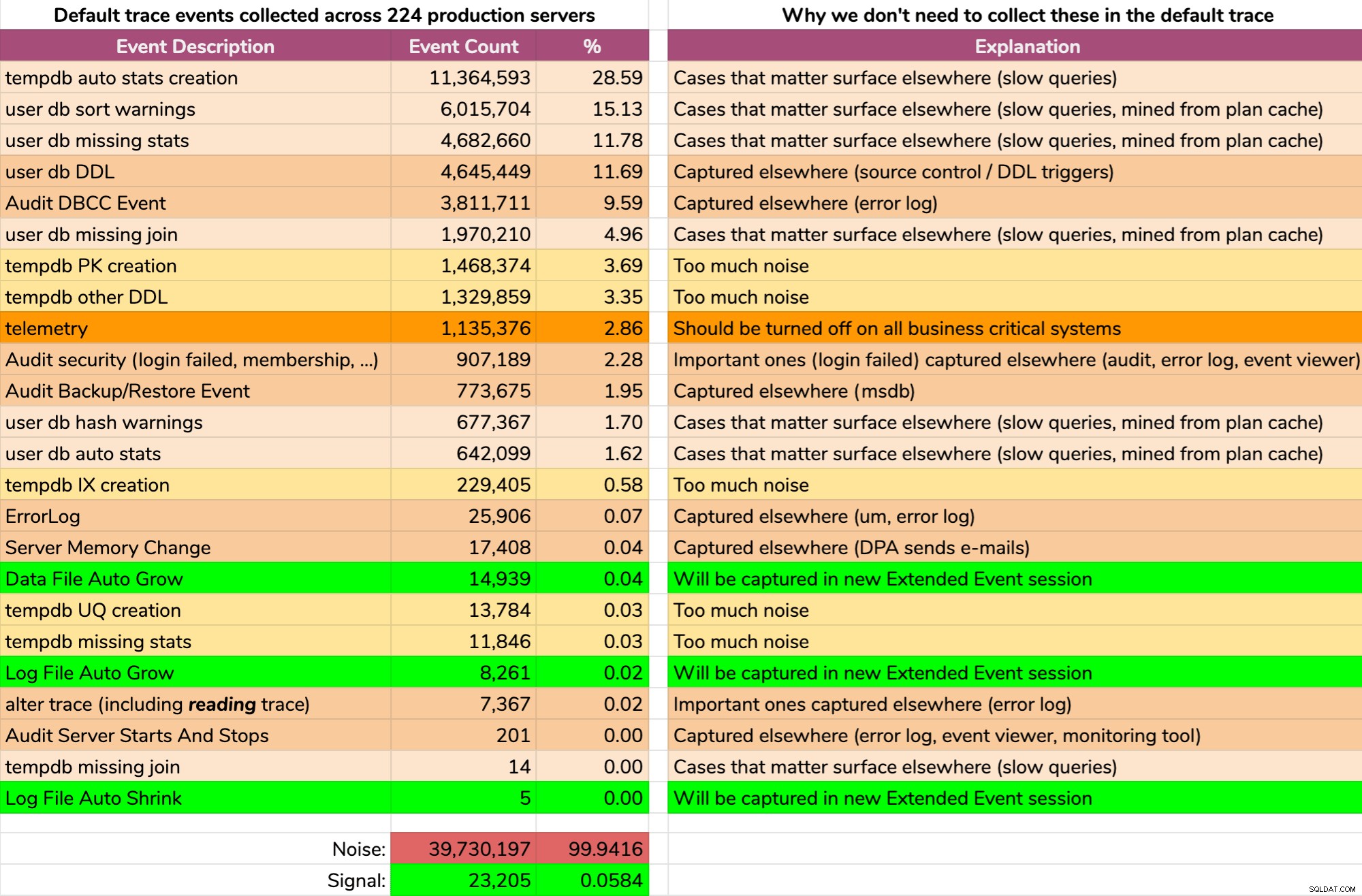
Quasi tutto il rumore (99,94%). L'unica cosa utile che ci serviva dalla traccia predefinita era la crescita dei file e la riduzione degli eventi, poiché erano l'unica cosa che non stavamo catturando altrove in un modo o nell'altro. Ma anche su questo non siamo sempre in grado di fare affidamento, perché i dati rotolano via così velocemente.
Un altro modo in cui ho suddiviso i dati:evento più vecchio per istanza. Alcune istanze hanno avuto così tanto rumore che non potevano conservare i dati di traccia predefiniti per più di pochi minuti! Ho offuscato i nomi dei server ma si tratta di dati reali (questi sono i 20 server con la cronologia più breve – clicca per ingrandire):
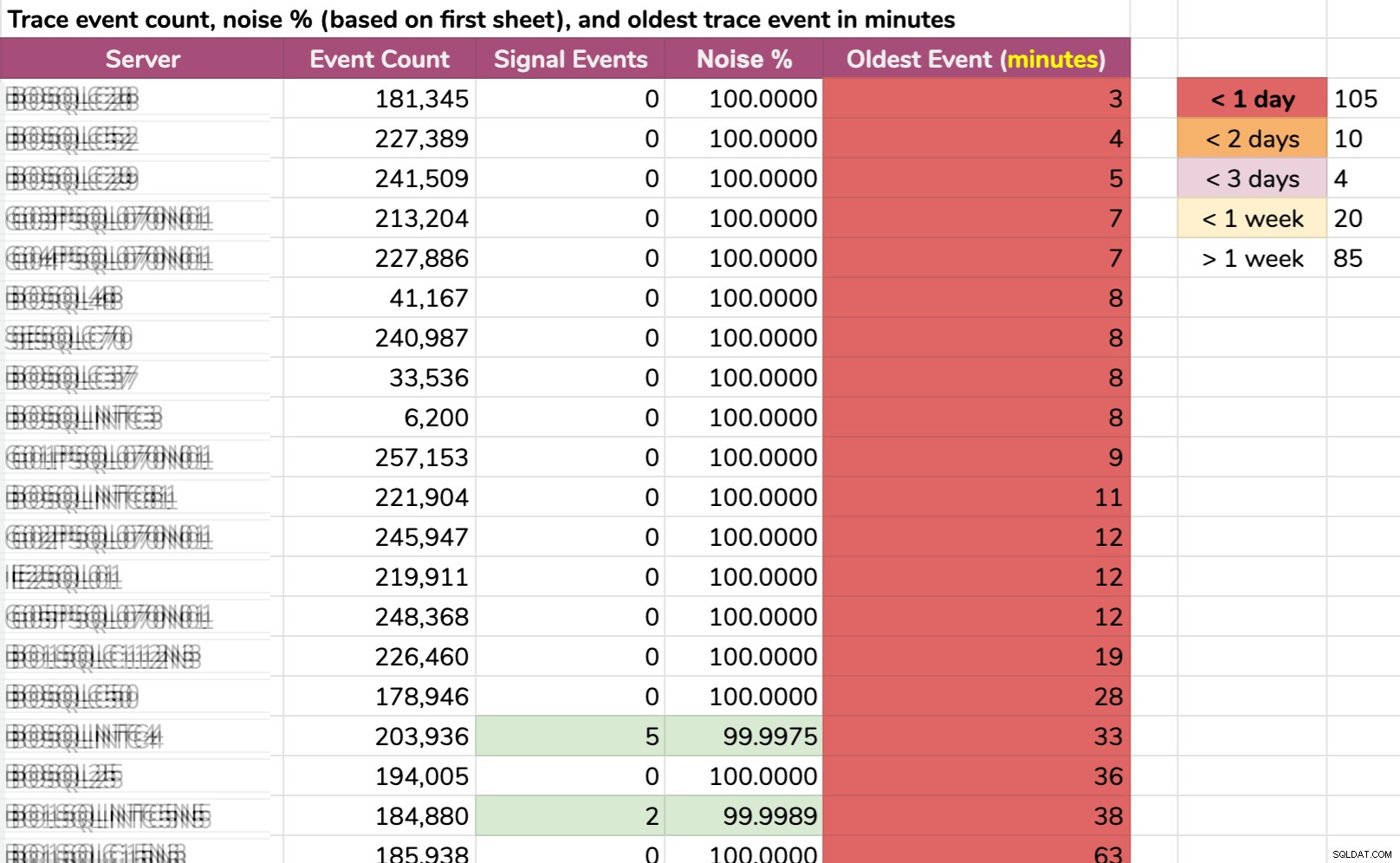
Anche se la traccia stesse raccogliendo solo informazioni rilevanti ed è successo qualcosa di interessante, dovremmo agire rapidamente per catturarlo, a seconda del server. Se è successo:
- 20 minuti fa , sarebbe già sparito su 15 istanze .
- questa volta ieri , sarebbe sparito su 105 istanze .
- due giorni fa , sarebbe sparito su 115 istanze .
- più di una settimana fa , sarebbe sparito su 139 istanze .
Avevamo anche una manciata di server dall'altra parte, ma non sono interessanti in questo contesto; quei server sono così semplicemente perché lì non accade nulla di interessante (ad es. non sono occupati o fanno parte di un carico di lavoro critico).
Il lato positivo...
L'analisi della traccia predefinita ha rivelato alcune configurazioni errate su alcuni dei nostri server:
- Diversi server avevano ancora telemetria abilitata . Sono favorevole ad aiutare Microsoft in determinati ambienti, ma non a costi generali su sistemi business-critical.
- Alcune attività di sincronizzazione in background aggiungevano membri ai ruoli alla cieca , più e più volte, senza controllare se erano già in quei ruoli. Questo non è di per sé dannoso, soprattutto perché questi eventi non riempiranno più la traccia predefinita, ma probabilmente riempiranno anche gli audit di rumore e probabilmente ci sono altre operazioni di riapplicazione cieca che si verificano nello stesso schema.
- Qualcuno ha abilitato la riduzione automatica da qualche parte (maledizione!), quindi era qualcosa che volevo rintracciare e impedire che accadesse di nuovo (anche il nuovo XE catturerà questi eventi).
Ciò ha portato a attività di follow-up per risolvere questi problemi e/o aggiungere condizioni all'automazione esistente già in atto. In questo modo possiamo prevenire che si ripetano senza fare affidamento solo sulla fortuna che si verificano su di loro in qualche futura revisione di traccia predefinita, prima che vengano implementati.
…ma il problema rimane
Altrimenti, tutto è o informazioni su cui non possiamo agire o, come descritto nel grafico sopra, eventi che abbiamo già acquisito altrove. E ancora, gli unici dati che mi interessano dalla traccia predefinita che non acquisiamo già con altri mezzi sono gli eventi relativi alla crescita e alla riduzione dei file (anche se la traccia predefinita acquisisce solo la varietà automatica).
Ma il problema più grande non è proprio il volume del rumore. Riesco a gestire file di traccia di grandi dimensioni con molta spazzatura, poiché le clausole WHERE sono state inventate esattamente per questo scopo. Il vero problema è che gli eventi importanti stavano scomparendo troppo rapidamente.
La risposta
La risposta, almeno nel nostro scenario, era semplice:disabilitare la traccia predefinita, poiché non vale la pena eseguirla se non è possibile fare affidamento su di essa.
Ma data la quantità di rumore sopra, cosa dovrebbe sostituirlo? Qualcosa?
Potresti volere una sessione di eventi estesi che catturi tutto la traccia predefinita acquisita. Se è così, Jonathan Kehayias ti copre. Questo ti darebbe le stesse informazioni, ma con il controllo su cose come la conservazione, dove i dati vengono archiviati e, man mano che ti senti più a tuo agio, la possibilità di rimuovere alcuni degli eventi più rumorosi o meno utili, gradualmente, nel tempo.
Il mio piano era un po' più aggressivo ed è diventato rapidamente un processo "semplice" per eseguire quanto segue su tutti i server nell'ambiente (tramite CMS):
Tieni presente che Non sto suggerendo di disabilitare ciecamente la traccia predefinita , spiegando solo perché ho scelto di farlo nel nostro ambiente. Nei prossimi post di questa serie, mostrerò la nuova sessione Eventi estesi, la vista che espone i dati sottostanti, il codice che ho utilizzato per distribuire queste modifiche a tutti i server e potenziali effetti collaterali da tenere a mente.
[ Parte 1 | Parte 2 | Parte 3]