La concatenazione di due o più set di dati è più comunemente espressa in T-SQL usando UNION ALL clausola. Dato che l'ottimizzatore di SQL Server può spesso riordinare elementi come join e aggregati per migliorare le prestazioni, è abbastanza ragionevole aspettarsi che SQL Server consideri anche il riordino degli input di concatenazione, laddove ciò rappresenterebbe un vantaggio. Ad esempio, l'ottimizzatore potrebbe considerare i vantaggi della riscrittura di A UNION ALL B come B UNION ALL A .
In effetti, l'ottimizzatore di SQL Server non Fai questo. Più precisamente, c'era un supporto limitato per il riordino dell'input di concatenazione nelle versioni di SQL Server fino al 2008 R2, ma questo è stato rimosso in SQL Server 2012 e da allora non è più riemerso.
SQL Server 2008 R2
Intuitivamente, l'ordine degli input di concatenazione conta solo se è presente un obiettivo di riga . Per impostazione predefinita, SQL Server ottimizza i piani di esecuzione in base al fatto che tutte le righe qualificanti verranno restituite al client. Quando è attivo un obiettivo di riga, l'ottimizzatore cerca di trovare un piano di esecuzione che produca rapidamente le prime righe.
Gli obiettivi di riga possono essere impostati in diversi modi, ad esempio utilizzando TOP , un FAST n suggerimento per la query o utilizzando EXISTS (che per sua natura deve trovare al massimo una riga). Laddove non ci sia un obiettivo di riga (ovvero il client richiede tutte le righe), generalmente non importa in quale ordine vengono letti gli input di concatenazione:ogni input verrà comunque elaborato in ogni caso.
Il supporto limitato nelle versioni fino a SQL Server 2008 R2 si applica laddove esiste l'obiettivo di esattamente una riga . In questa specifica circostanza, SQL Server riordinerà gli input di concatenazione in base al costo previsto.
Questo non viene fatto durante l'ottimizzazione basata sui costi (come ci si potrebbe aspettare), ma piuttosto come una riscrittura post-ottimizzazione dell'ultimo minuto del normale output dell'ottimizzatore. Questa disposizione ha il vantaggio di non aumentare lo spazio di ricerca del piano basato sui costi (potenzialmente un'alternativa per ogni possibile riordino), producendo comunque un piano ottimizzato per restituire rapidamente la prima riga.
Esempi
Gli esempi seguenti utilizzano due tabelle con contenuto identico:Un milione di righe di numeri interi da uno a un milione. Una tabella è un heap senza indici non cluster; l'altro ha un indice cluster univoco:
CREATE TABLE dbo.Expensive
(
Val bigint NOT NULL
);
CREATE TABLE dbo.Cheap
(
Val bigint NOT NULL,
CONSTRAINT [PK dbo.Cheap Val]
UNIQUE CLUSTERED (Val)
);
GO
INSERT dbo.Cheap WITH (TABLOCKX)
(Val)
SELECT TOP (1000000)
Val = ROW_NUMBER() OVER (ORDER BY SV1.number)
FROM master.dbo.spt_values AS SV1
CROSS JOIN master.dbo.spt_values AS SV2
ORDER BY
Val
OPTION (MAXDOP 1);
GO
INSERT dbo.Expensive WITH (TABLOCKX)
(Val)
SELECT
C.Val
FROM dbo.Cheap AS C
OPTION (MAXDOP 1); Nessun obiettivo di fila
La query seguente cerca le stesse righe in ogni tabella e restituisce la concatenazione dei due insiemi:
SELECT E.Val
FROM dbo.Expensive AS E
WHERE
E.Val BETWEEN 751000 AND 751005
UNION ALL
SELECT C.Val
FROM dbo.Cheap AS C
WHERE
C.Val BETWEEN 751000 AND 751005; Il piano di esecuzione prodotto da Query Optimizer è:
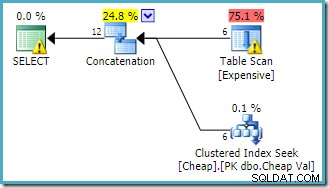
L'avviso sulla radice SELECT l'operatore ci sta avvisando dell'evidente indice mancante nella tabella heap. L'avviso sull'operatore Table Scan viene aggiunto da Sentry One Plan Explorer. Sta attirando la nostra attenzione sul costo di I/O del predicato residuo nascosto nella scansione.
L'ordine degli input per la concatenazione non ha importanza qui, perché non abbiamo fissato un obiettivo di fila. Entrambi gli input verranno letti completamente per restituire tutte le righe dei risultati. Di interesse (sebbene ciò non sia garantito) si noti che l'ordine degli input segue l'ordine testuale della query originale. Si noti inoltre che non è specificato nemmeno l'ordine delle righe del risultato finale, poiché non è stato utilizzato un ORDER BY di livello superiore clausola. Daremo per scontato che sia deliberato e che l'ordine finale sia irrilevante per il compito da svolgere.
Se invertiamo l'ordine di scrittura delle tabelle nella query in questo modo:
SELECT C.Val
FROM dbo.Cheap AS C
WHERE
C.Val BETWEEN 751000 AND 751005
UNION ALL
SELECT E.Val
FROM dbo.Expensive AS E
WHERE
E.Val BETWEEN 751000 AND 751005; Il piano di esecuzione segue la modifica, accedendo prima alla tabella cluster (di nuovo, questo non è garantito):
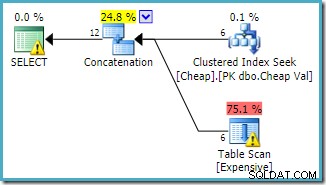
Ci si può aspettare che entrambe le query abbiano le stesse caratteristiche di prestazione, poiché eseguono le stesse operazioni, solo in un ordine diverso.
Con un obiettivo di fila
Chiaramente, la mancanza di indicizzazione sulla tabella heap renderà normalmente più costosa la ricerca di righe specifiche, rispetto alla stessa operazione sulla tabella cluster. Se chiediamo all'ottimizzatore un piano che restituisca rapidamente la prima riga, ci aspetteremmo che SQL Server riordini gli input di concatenazione in modo che venga prima consultata la tabella cluster economica.
Utilizzando la query che menziona prima la tabella heap e utilizzando un suggerimento per la query FAST 1 per specificare l'obiettivo della riga:
SELECT E.Val
FROM dbo.Expensive AS E
WHERE
E.Val BETWEEN 751000 AND 751005
UNION ALL
SELECT C.Val
FROM dbo.Cheap AS C
WHERE
C.Val BETWEEN 751000 AND 751005
OPTION (FAST 1); Il piano di esecuzione stimato prodotto su un'istanza di SQL Server 2008 R2 è:
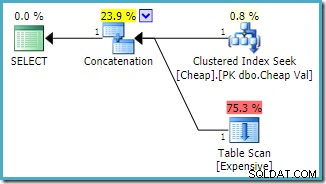
Si noti che gli input di concatenazione sono stati riordinati per ridurre il costo stimato per la restituzione della prima riga. Si noti inoltre che l'indice mancante e gli avvisi di I/O residui sono scomparsi. Nessuno dei due problemi è rilevante con questa forma del piano quando l'obiettivo è restituire una singola riga il più rapidamente possibile.
La stessa query eseguita su SQL Server 2016 (utilizzando uno dei modelli di stima della cardinalità) è:
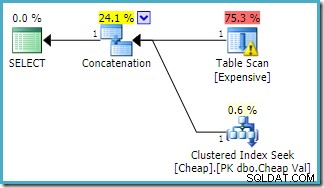
SQL Server 2016 non ha riordinato gli input di concatenazione. L'avviso di I/O di Plan Explorer è tornato, ma purtroppo l'ottimizzatore non ha prodotto un avviso di indice mancante questa volta (sebbene sia rilevante).
Riordino generale
Come accennato, la riscrittura post-ottimizzazione che riordina gli input di concatenazione è efficace solo per:
- SQL Server 2008 R2 e versioni precedenti
- Una riga di esattamente uno
Se vogliamo davvero che venga restituita solo una riga, anziché un piano ottimizzato per restituire rapidamente la prima riga (ma che alla fine restituirà comunque tutte le righe), possiamo utilizzare un TOP clausola con una tabella derivata o un'espressione di tabella comune (CTE):
SELECT TOP (1)
UA.Val
FROM
(
SELECT E.Val
FROM dbo.Expensive AS E
WHERE
E.Val BETWEEN 751000 AND 751005
UNION ALL
SELECT C.Val
FROM dbo.Cheap AS C
WHERE
C.Val BETWEEN 751000 AND 751005
) AS UA; In SQL Server 2008 R2 o versioni precedenti, questo produce il piano di input riordinato ottimale:
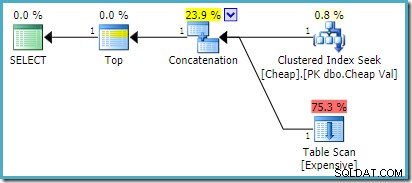
In SQL Server 2012, 2014 e 2016 non si verifica alcun riordino successivo all'ottimizzazione:
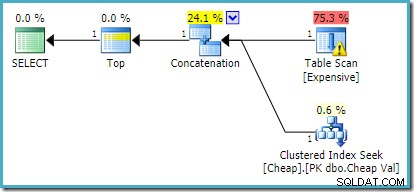
Se vogliamo che venga restituita più di una riga, ad esempio utilizzando TOP (2) , la riscrittura desiderata non verrà applicata su SQL Server 2008 R2 anche se FAST 1 viene utilizzato anche il suggerimento. In quella situazione, dobbiamo ricorrere a trucchi come usare TOP con una variabile e un OPTIMIZE FOR suggerimento:
DECLARE @TopRows bigint = 2; -- Number of rows actually needed
SELECT TOP (@TopRows)
UA.Val
FROM
(
SELECT E.Val
FROM dbo.Expensive AS E
WHERE
E.Val BETWEEN 751000 AND 751005
UNION ALL
SELECT C.Val
FROM dbo.Cheap AS C
WHERE
C.Val BETWEEN 751000 AND 751005
) AS UA
OPTION (OPTIMIZE FOR (@TopRows = 1)); -- Just a hint L'hint della query è sufficiente per impostare un obiettivo di riga pari a uno, mentre il valore di runtime della variabile garantisce che venga restituito il numero desiderato di righe (2).
Il piano di esecuzione effettivo su SQL Server 2008 R2 è:
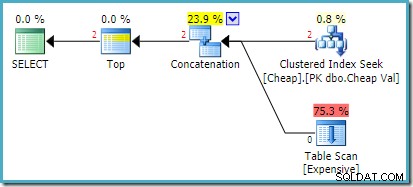
Entrambe le righe restituite provengono dall'input di ricerca riordinato e la scansione della tabella non viene eseguita affatto. Plan Explorer mostra i conteggi delle righe in rosso perché la stima riguardava una riga (a causa del suggerimento) mentre sono state rilevate due righe in fase di esecuzione.
Senza UNION ALL
Anche questo problema non è limitato alle query scritte in modo esplicito con UNION ALL . Altre costruzioni come EXISTS e OR può anche comportare che l'ottimizzatore introduca un operatore di concatenazione, che potrebbe risentire della mancanza di riordino dell'input. C'è stata una domanda recente su Database Administrators Stack Exchange con esattamente questo problema. Trasformare la query da quella domanda per utilizzare le nostre tabelle di esempio:
SELECT
CASE
WHEN
EXISTS
(
SELECT 1
FROM dbo.Expensive AS E
WHERE E.Val BETWEEN 751000 AND 751005
)
OR EXISTS
(
SELECT 1
FROM dbo.Cheap AS C
WHERE C.Val BETWEEN 751000 AND 751005
)
THEN 1
ELSE 0
END; Il piano di esecuzione su SQL Server 2016 ha la tabella heap nel primo input:
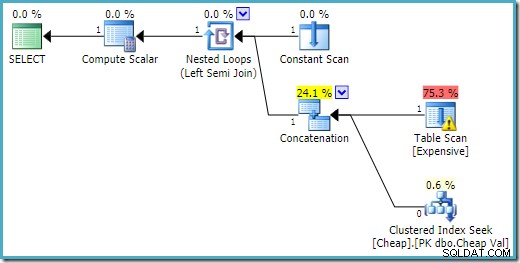
In SQL Server 2008 R2 l'ordine degli input è ottimizzato per riflettere l'obiettivo di riga singola del semi join:
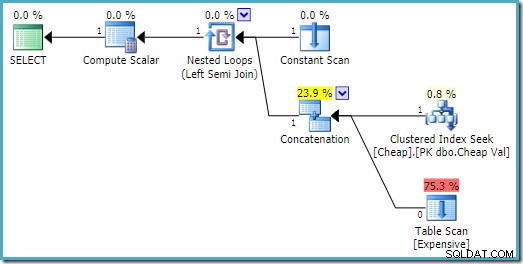
Nel piano più ottimale, la scansione dell'heap non viene mai eseguita.
Soluzioni alternative
In alcuni casi, sarà evidente all'autore della query che uno degli input di concatenazione sarà sempre più economico da eseguire rispetto agli altri. Se ciò è vero, è abbastanza valido riscrivere la query in modo che gli input di concatenazione più economici appaiano per primi in ordine scritto. Ovviamente ciò significa che lo scrittore di query deve essere consapevole di questa limitazione dell'ottimizzatore e pronto a fare affidamento su comportamenti non documentati.
Un problema più difficile sorge quando il costo degli input di concatenazione varia a seconda delle circostanze, forse a seconda dei valori dei parametri. Usando OPTION (RECOMPILE) non sarà di aiuto su SQL Server 2012 o versioni successive. Questa opzione può essere utile su SQL Server 2008 R2 o versioni precedenti, ma solo se viene soddisfatto anche il requisito dell'obiettivo di una riga.
Se ci sono dubbi sull'affidarsi al comportamento osservato (input di concatenazione del piano di query che corrispondono all'ordine del testo della query) è possibile utilizzare una guida del piano per forzare la forma del piano. Laddove ordini di input diversi siano ottimali per circostanze diverse, è possibile utilizzare più guide del piano, in cui le condizioni possono essere codificate accuratamente in anticipo. Tuttavia, non è certo l'ideale.
Pensieri finali
Query Optimizer di SQL Server contiene infatti un basato sui costi regola di esplorazione, UNIAReorderInputs , che è in grado di generare variazioni dell'ordine di input di concatenazione ed esplorare alternative durante l'ottimizzazione basata sui costi (non come una riscrittura post-ottimizzazione singola).
Questa regola non è attualmente abilitata per l'uso generale. Per quanto ne so, viene attivato solo quando una guida al piano o USE PLAN suggerimento è presente. Ciò consente al motore di forzare correttamente un piano che è stato generato per una query che si è qualificata per la riscrittura del riordino dell'input, anche quando la query corrente non è idonea.
La mia sensazione è che questa regola di esplorazione sia deliberatamente limitata a questo uso, perché le query che trarrebbero vantaggio dal riordino dell'input di concatenazione come parte dell'ottimizzazione basata sui costi non sono considerate sufficientemente comuni, o forse perché c'è la preoccupazione che lo sforzo extra non ripagherebbe spento. La mia opinione è che il riordino dell'input dell'operatore di concatenazione dovrebbe sempre essere esplorato quando è attivo un obiettivo di riga.
È anche un peccato che la riscrittura post-ottimizzazione (più limitata) non sia efficace in SQL Server 2012 o versioni successive. Ciò potrebbe essere dovuto a un bug sottile, ma non sono riuscito a trovare nulla al riguardo nella documentazione, nella knowledge base o su Connect. Ho aggiunto un nuovo elemento Connect qui.
Aggiornamento del 9 agosto 2017 :Ora è risolto sotto il flag di traccia 4199 per SQL Server 2014 e 2016, vedere KB 4023419:
FIX:la query con UNION ALL e un obiettivo di riga potrebbe essere più lenta in SQL Server 2014 o versioni successive rispetto a SQL Server 2008 R2



