In Stack Overflow, abbiamo alcune tabelle che utilizzano indici columnstore cluster e funzionano alla grande per la maggior parte del nostro carico di lavoro. Ma di recente ci siamo imbattuti in una situazione in cui "tempeste perfette" - più processi che tentavano di eliminare tutti dalla stessa CCI - avrebbero sopraffatto la CPU poiché andavano tutti in parallelo e combattevano per completare la loro operazione. Ecco come appariva in SolarWinds SQL Sentry:
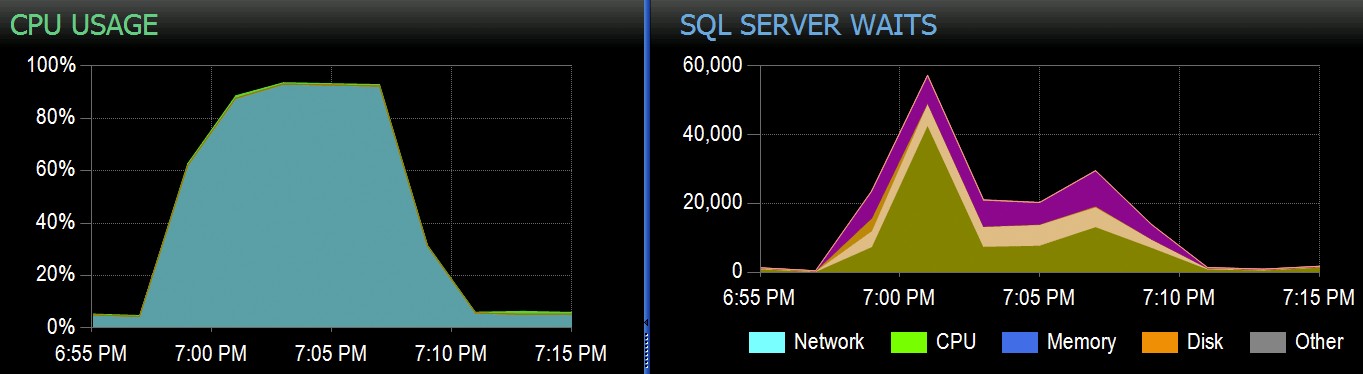
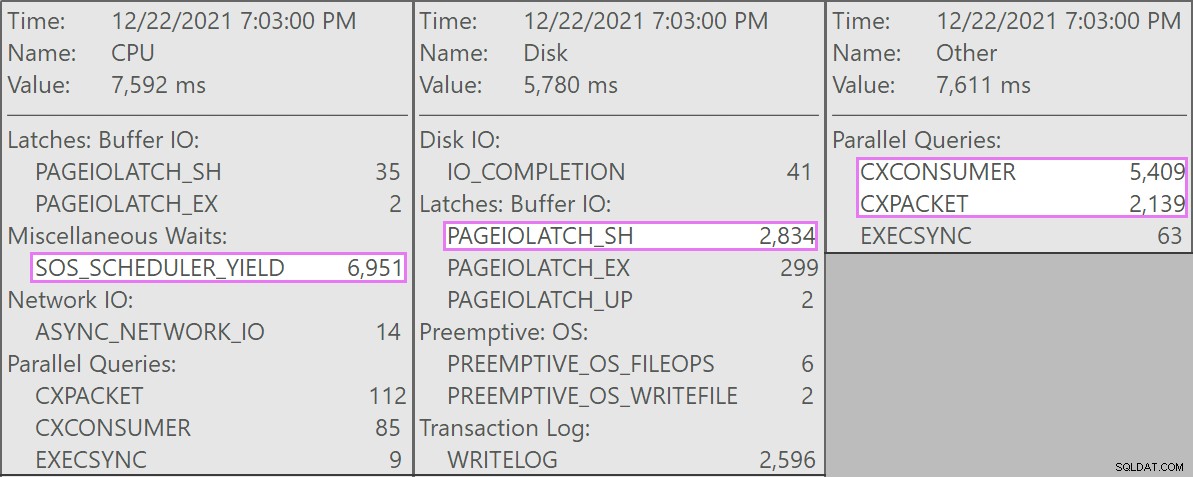
Ed ecco le attese interessanti associate a queste query:
Le query in competizione erano tutte di questa forma:
DELETE dbo.LargeColumnstoreTable WHERE col1 = @p1 AND col2 = @p2;
Il piano si presentava così:

E l'avviso sulla scansione ci ha avvisato di un I/O residuo piuttosto estremo:

La tabella ha 1,9 miliardi di righe ma è solo 32 GB (grazie, spazio di archiviazione a colonne!). Tuttavia, queste eliminazioni di una singola riga richiederebbero 10-15 secondi ciascuna, con la maggior parte di questo tempo speso su SOS_SCHEDULER_YIELD .
Per fortuna, poiché in questo scenario l'operazione di eliminazione potrebbe essere asincrona, siamo stati in grado di risolvere il problema con due modifiche (anche se sto semplificando grossolanamente):
- Abbiamo limitato
MAXDOPa livello di database, quindi queste eliminazioni non possono essere così parallele - Abbiamo migliorato la serializzazione dei processi provenienti dall'applicazione (in pratica, abbiamo messo in coda le eliminazioni tramite un unico dispatcher)
In qualità di DBA, possiamo controllare facilmente MAXDOP , a meno che non venga sovrascritto a livello di query (un'altra tana del coniglio per un altro giorno). Non possiamo necessariamente controllare l'applicazione in questa misura, soprattutto se è distribuita o non nostra. Come possiamo serializzare le scritture in questo caso senza modificare drasticamente la logica dell'applicazione?
Una configurazione simulata
Non cercherò di creare localmente una tabella di due miliardi di righe, non importa la tabella esatta, ma possiamo approssimare qualcosa su scala più piccola e provare a riprodurre lo stesso problema.
Facciamo finta che questo sia il SuggestedEdits table (in realtà non lo è). Ma è un esempio facile da usare perché possiamo estrarre lo schema da Stack Exchange Data Explorer. Usando questo come base, possiamo creare una tabella equivalente (con alcune piccole modifiche per semplificare il popolamento) e inserire su di essa un indice columnstore cluster:
CREATE TABLE dbo.FakeSuggestedEdits ( Id int IDENTITY(1,1), PostId int NOT NULL DEFAULT CONVERT(int, ABS(CHECKSUM(NEWID()))) % 200, CreationDate datetime2 NOT NULL DEFAULT sysdatetime(), ApprovalDate datetime2 NOT NULL DEFAULT sysdatetime(), RejectionDate datetime2 NULL, OwnerUserId int NOT NULL DEFAULT 7, Comment nvarchar (800) NOT NULL DEFAULT NEWID(), Text nvarchar (max) NOT NULL DEFAULT NEWID(), Title nvarchar (250) NOT NULL DEFAULT NEWID(), Tags nvarchar (250) NOT NULL DEFAULT NEWID(), RevisionGUID uniqueidentifier NOT NULL DEFAULT NEWSEQUENTIALID(), INDEX CCI_FSE CLUSTERED COLUMNSTORE );
Per popolarlo con 100 milioni di righe, possiamo incrociare sys.all_objects e sys.all_columns cinque volte (sul mio sistema, questo produrrà 2,68 milioni di righe ogni volta, ma YMMV):
-- 2680350 * 5 ~ 3 minutes INSERT dbo.FakeSuggestedEdits(CreationDate) SELECT TOP (10) /*(2000000) */ modify_date FROM sys.all_objects AS o CROSS JOIN sys.columns AS c; GO 5
Quindi, possiamo controllare lo spazio:
EXEC sys.sp_spaceused @objname = N'dbo.FakeSuggestedEdits';
È solo 1,3 GB, ma dovrebbe essere sufficiente:

Imitazione dell'eliminazione di Columnstore in cluster
Ecco una semplice query che corrisponde approssimativamente a ciò che la nostra applicazione stava facendo sulla tabella:
DECLARE @p1 int = ABS(CHECKSUM(NEWID())) % 10000000, @p2 int = 7; DELETE dbo.FakeSuggestedEdits WHERE Id = @p1 AND OwnerUserId = @p2;
Tuttavia, il piano non è proprio una combinazione perfetta:
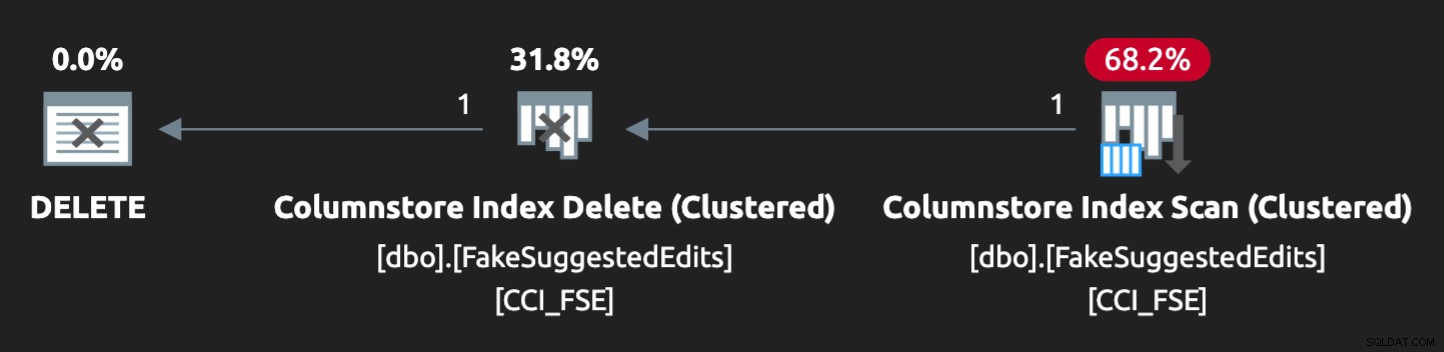
Per farlo funzionare in parallelo e produrre contese simili sul mio scarso laptop, ho dovuto forzare un po' l'ottimizzatore con questo suggerimento:
OPTION (QUERYTRACEON 8649);
Ora sembra giusto:

Riproduzione del problema
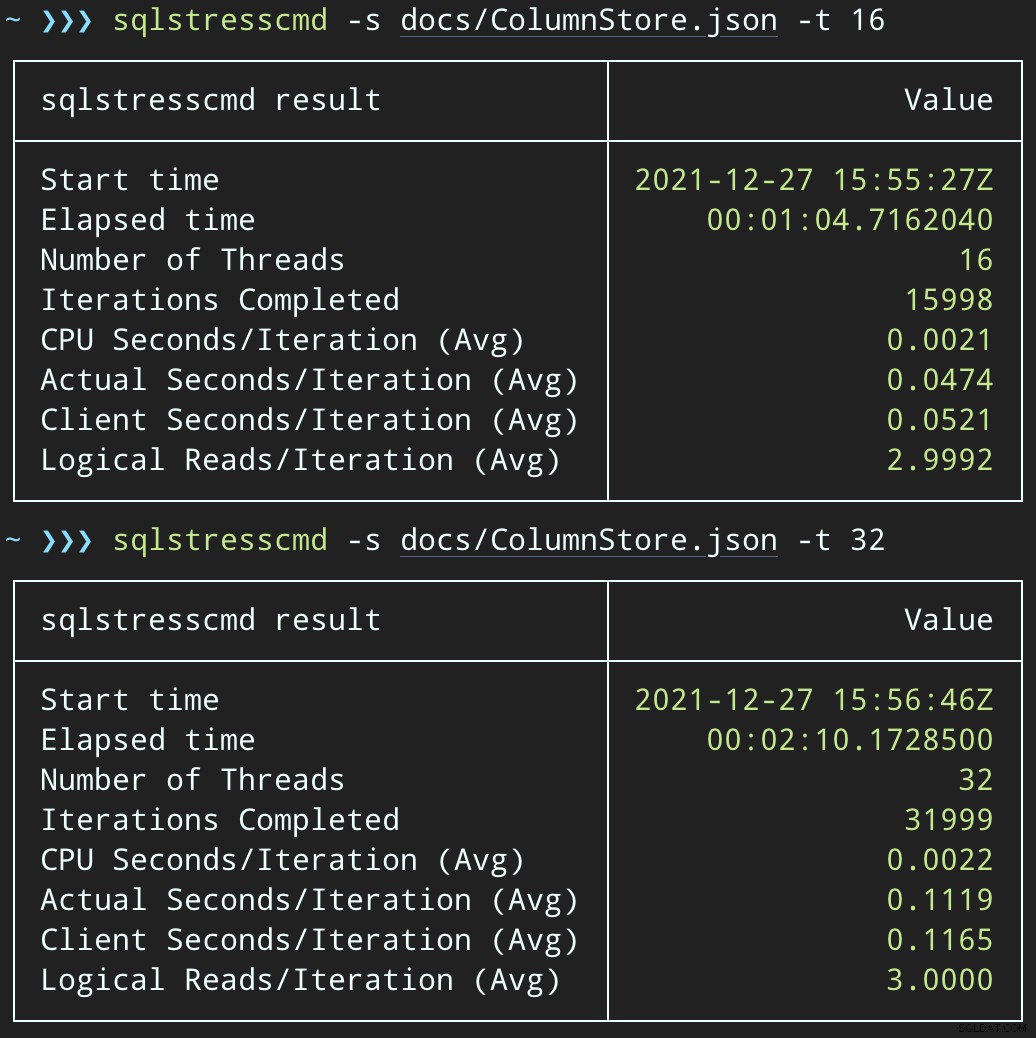
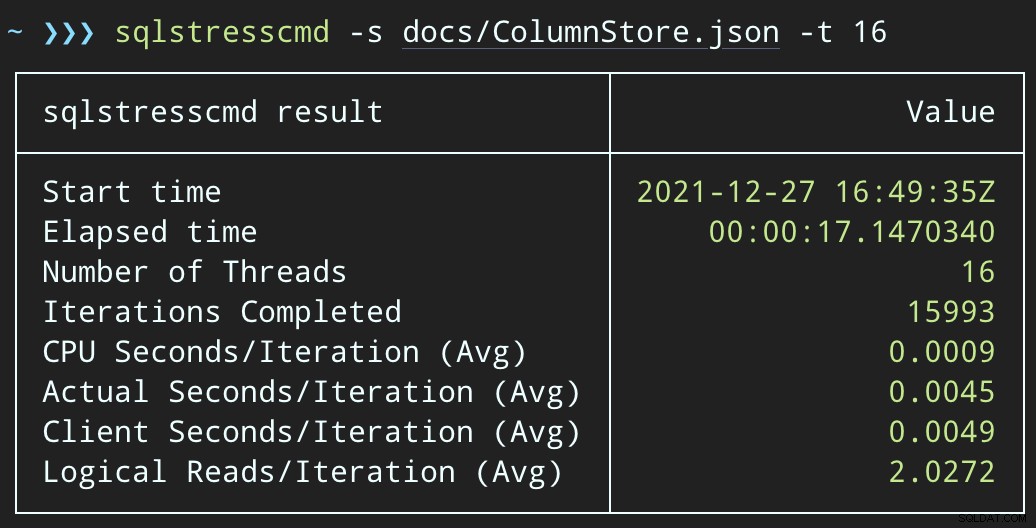
Quindi, possiamo creare un aumento di attività di eliminazione simultanee utilizzando SqlStressCmd per eliminare 1.000 righe casuali utilizzando 16 e 32 thread:
sqlstresscmd -s docs/ColumnStore.json -t 16 sqlstresscmd -s docs/ColumnStore.json -t 32
Possiamo osservare lo sforzo che questo mette sulla CPU:
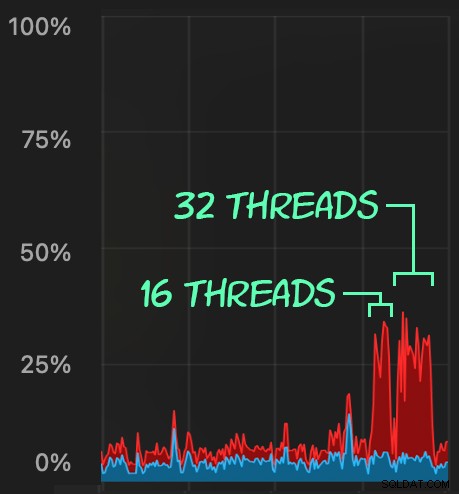
Lo sforzo sulla CPU dura durante i batch rispettivamente di circa 64 e 130 secondi:
Nota:l'output di SQLQueryStress a volte è un po' fuori dalle iterazioni, ma ho confermato che il lavoro che gli chiedi di fare viene svolto con precisione.
Una potenziale soluzione alternativa:una coda di eliminazione
Inizialmente, ho pensato di introdurre una tabella di coda nel database, che potremmo usare per scaricare l'attività di eliminazione:
CREATE TABLE dbo.SuggestedEditDeleteQueue ( QueueID int IDENTITY(1,1) PRIMARY KEY, EnqueuedDate datetime2 NOT NULL DEFAULT sysdatetime(), ProcessedDate datetime2 NULL, Id int NOT NULL, OwnerUserId int NOT NULL );
Tutto ciò di cui abbiamo bisogno è un trigger INSTEAD OF per intercettare queste eliminazioni non autorizzate provenienti dall'applicazione e metterle in coda per l'elaborazione in background. Sfortunatamente, non puoi creare un trigger su una tabella con un indice columnstore cluster:
Msg 35358, livello 16, stato 1CREATE TRIGGER sulla tabella 'dbo.FakeSuggestedEdits' non riuscito perché non è possibile creare un trigger su una tabella con un indice columnstore cluster. Considerare di applicare la logica del trigger in qualche altro modo oppure, se è necessario utilizzare un trigger, utilizzare invece un indice heap o B-tree.
Avremo bisogno di una modifica minima al codice dell'applicazione, in modo che chiami una stored procedure per gestire l'eliminazione:
CREATE PROCEDURE dbo.DeleteSuggestedEdit @Id int, @OwnerUserId int AS BEGIN SET NOCOUNT ON; DELETE dbo.FakeSuggestedEdits WHERE Id = @Id AND OwnerUserId = @OwnerUserId; END
Questo non è uno stato permanente; questo è solo per mantenere il comportamento lo stesso mentre si cambia solo una cosa nell'app. Una volta che l'app è stata modificata e ha chiamato correttamente questa stored procedure invece di inviare query di eliminazione ad hoc, la stored procedure può cambiare:
CREATE PROCEDURE dbo.DeleteSuggestedEdit @Id int, @OwnerUserId int AS BEGIN SET NOCOUNT ON; INSERT dbo.SuggestedEditDeleteQueue(Id, OwnerUserId) SELECT @Id, @OwnerUserId; END
Testare l'impatto della coda
Ora, se cambiamo SqlQueryStress per chiamare invece la stored procedure:
DECLARE @p1 int = ABS(CHECKSUM(NEWID())) % 10000000, @p2 int = 7; EXEC dbo.DeleteSuggestedEdit @Id = @p1, @OwnerUserId = @p2;
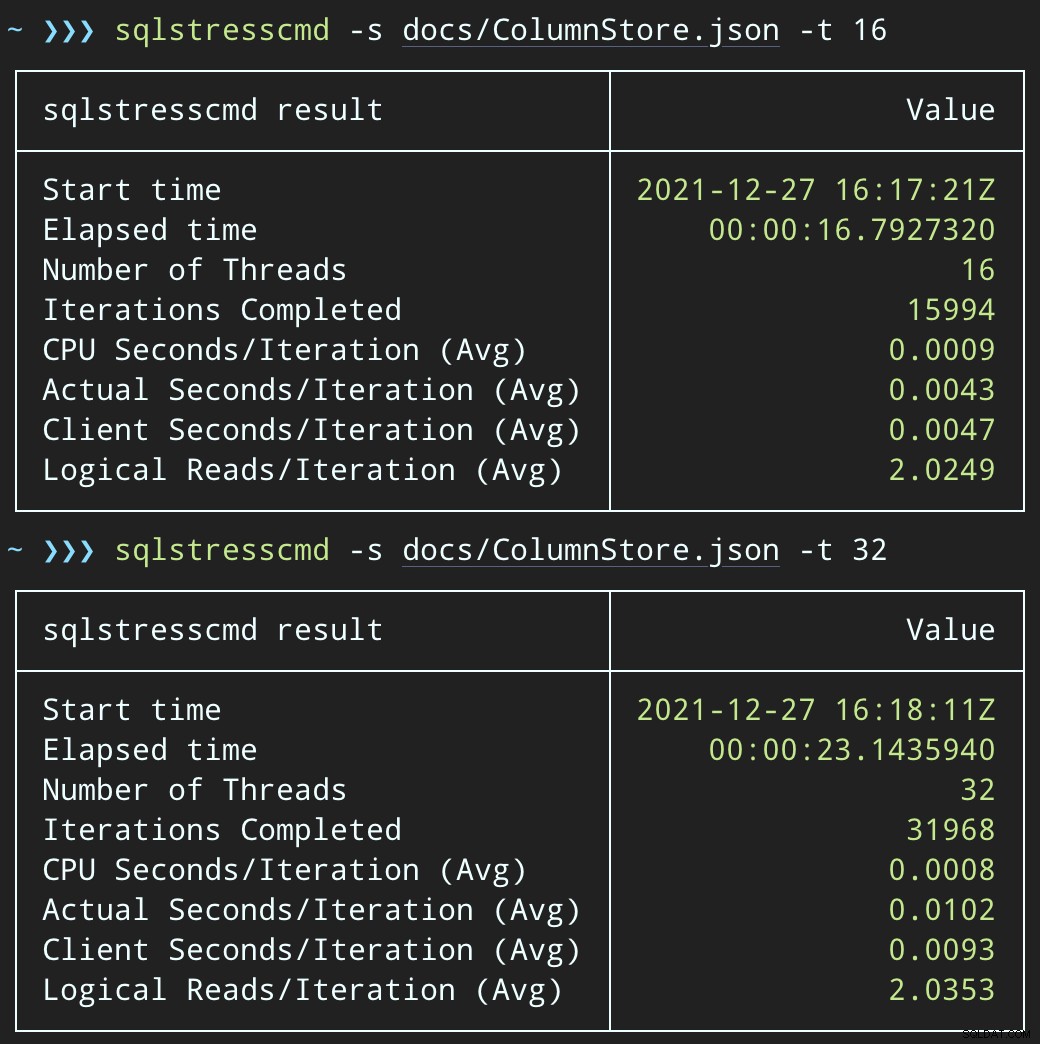
E invia batch simili (mettendo 16.000 o 32.000 righe nella coda):
DECLARE @p1 int = ABS(CHECKSUM(NEWID())) % 10000000, @p2 int = 7; EXEC dbo.@Id = @p1 AND OwnerUserId = @p2;
L'impatto sulla CPU è leggermente superiore:
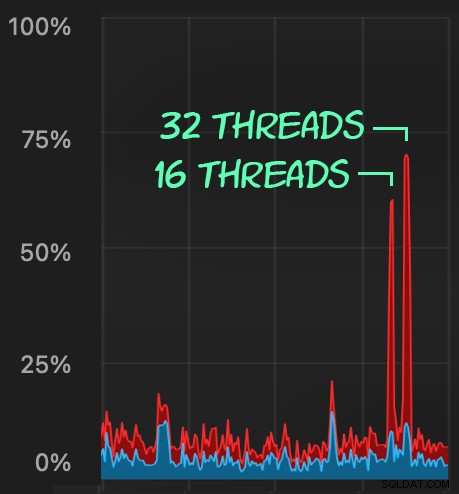
Ma i carichi di lavoro finiscono molto più rapidamente, rispettivamente 16 e 23 secondi:
Questa è una riduzione significativa del dolore che le applicazioni proveranno quando entrano in periodi di elevata simultaneità.
Dobbiamo ancora eseguire l'eliminazione, però
Dobbiamo ancora elaborare quelle eliminazioni in background, ma ora possiamo introdurre il batching e avere il pieno controllo sulla velocità e su eventuali ritardi che vogliamo iniettare tra le operazioni. Ecco la struttura di base di una procedura memorizzata per elaborare la coda (certamente senza il controllo transazionale, la gestione degli errori o la pulizia della tabella delle code completamente acquisiti):
CREATE PROCEDURE dbo.ProcessSuggestedEditQueue
@JobSize int = 10000,
@BatchSize int = 100,
@DelayInSeconds int = 2 -- must be between 1 and 59
AS
BEGIN
SET NOCOUNT ON;
DECLARE @d TABLE(Id int, OwnerUserId int);
DECLARE @rc int = 1,
@jc int = 0,
@wf nvarchar(100) = N'WAITFOR DELAY ' + CHAR(39)
+ '00:00:' + RIGHT('0' + CONVERT(varchar(2),
@DelayInSeconds), 2) + CHAR(39);
WHILE @rc > 0 AND @jc < @JobSize
BEGIN
DELETE @d;
UPDATE TOP (@BatchSize) q SET ProcessedDate = sysdatetime()
OUTPUT inserted.Id, inserted.OwnerUserId INTO @d
FROM dbo.SuggestedEditDeleteQueue AS q WITH (UPDLOCK, READPAST)
WHERE ProcessedDate IS NULL;
SET @rc = @@ROWCOUNT;
IF @rc = 0 BREAK;
DELETE fse
FROM dbo.FakeSuggestedEdits AS fse
INNER JOIN @d AS d
ON fse.Id = d.Id
AND fse.OwnerUserId = d.OwnerUserId;
SET @jc += @rc;
IF @jc > @JobSize BREAK;
EXEC sys.sp_executesql @wf;
END
RAISERROR('Deleted %d rows.', 0, 1, @jc) WITH NOWAIT;
END Ora, l'eliminazione delle righe richiederà più tempo:la media di 10.000 righe è di 223 secondi, di cui ~100 è un ritardo intenzionale. Ma nessun utente sta aspettando, quindi chi se ne frega? Il profilo della CPU è quasi zero e l'app può continuare ad aggiungere elementi alla coda in modo altamente simultaneo come vuole, con quasi zero conflitti con il lavoro in background. Durante l'elaborazione di 10.000 righe, ho aggiunto altre 16.000 righe alla coda e ha utilizzato la stessa CPU di prima, impiegando solo un secondo in più rispetto a quando il lavoro non era in esecuzione:
E il piano ora si presenta così, con righe stimate/effettive molto migliori:
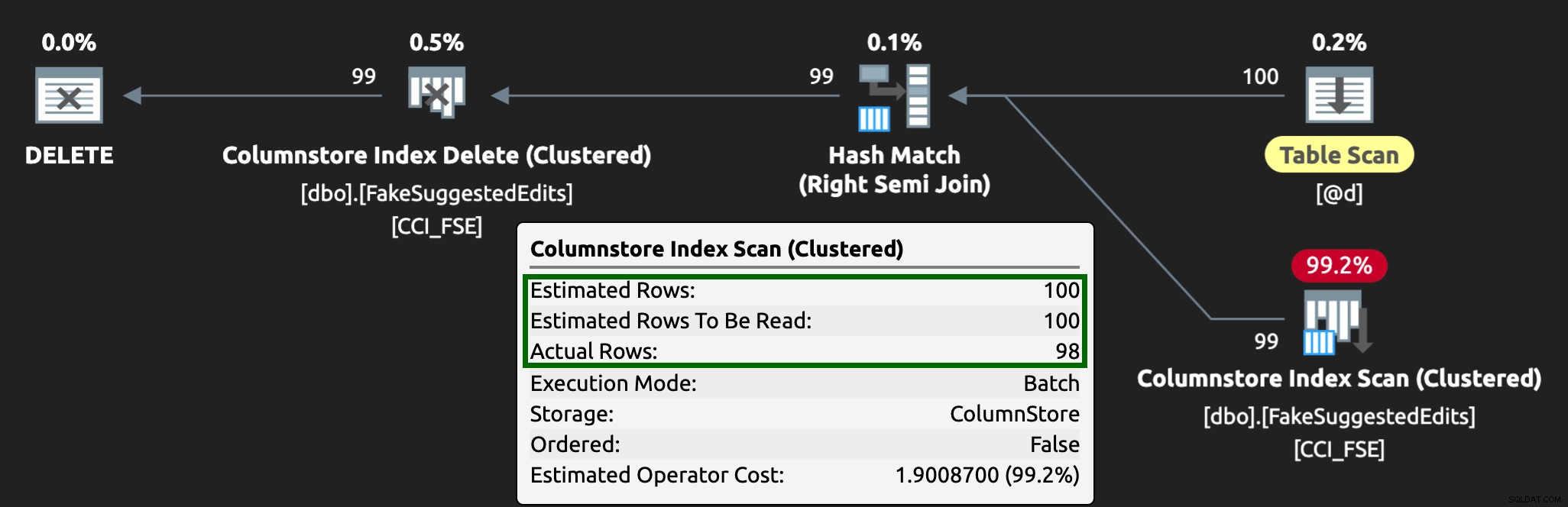
Vedo che questo approccio alla tabella delle code è un modo efficace per gestire un'elevata simultaneità DML, ma richiede almeno un po' di flessibilità con le applicazioni che inviano DML:questo è uno dei motivi per cui mi piace molto che le applicazioni chiamino procedure archiviate, poiché dacci molto più controllo più vicino ai dati.
Altre opzioni
Se non hai la possibilità di modificare le query di eliminazione provenienti dall'applicazione o, se non puoi rinviare le eliminazioni a un processo in background, puoi considerare altre opzioni per ridurre l'impatto delle eliminazioni:
- Un indice non cluster sulle colonne del predicato per supportare le ricerche di punti (possiamo farlo in isolamento senza modificare l'applicazione)
- Utilizzo solo delle eliminazioni software (richiede comunque modifiche all'applicazione)
Sarà interessante vedere se queste opzioni offrono vantaggi simili, ma le salverò per un post futuro.