Introduzione
Il log shipping delle transazioni è una tecnologia molto nota utilizzata in SQL Server per mantenere una copia del database attivo nel sito di ripristino di emergenza. La tecnologia dipende da tre processi chiave:il processo di backup, il processo di copia e il processo di ripristino. Mentre il processo di backup viene eseguito sul server primario, i processi di copia e ripristino vengono eseguiti sul server secondario. In sostanza, il processo prevede backup periodici del registro delle transazioni su una condivisione da cui il processo di copia si sposta sul server secondario; successivamente, il processo di ripristino applica i backup del registro al server secondario. Prima che tutto questo abbia inizio, il Database Secondario deve essere inizializzato con un backup completo dal server Primario ripristinato con l'opzione NORECOVERY.
Microsoft fornisce una serie di stored procedure che possono essere utilizzate per configurare Log Shipping end-to-end, nonché equivalenti della GUI a partire dall'elemento delle proprietà di ogni database per il quale potresti voler configurare Log Shipping. Da notare che il Database Secondario può essere configurato in modalità NORECOVERY oppure in modalità STANDBY. In modalità NORECOVERY il database non è mai disponibile per le query, ma in modalità STANDBY è possibile eseguire query sul database secondario quando non è in corso alcuna operazione di ripristino del registro delle transazioni.
Impostazione dell'ambiente
Per iniziare, creiamo due istanze SQL Server su AWS con un'immagine Amazon EC2 identica. Questa istanza Amazon EC2 esegue SQL Server 2017 RTM-CU5 su Windows Server 2016. Quindi ripristiniamo una copia del database WideWorldImporters utilizzando un set di backup acquisito da GitHub sulla prima istanza, la nostra istanza primaria. Utilizziamo lo stesso set di backup per creare due database identici denominati BranchDB e CorporateDB.
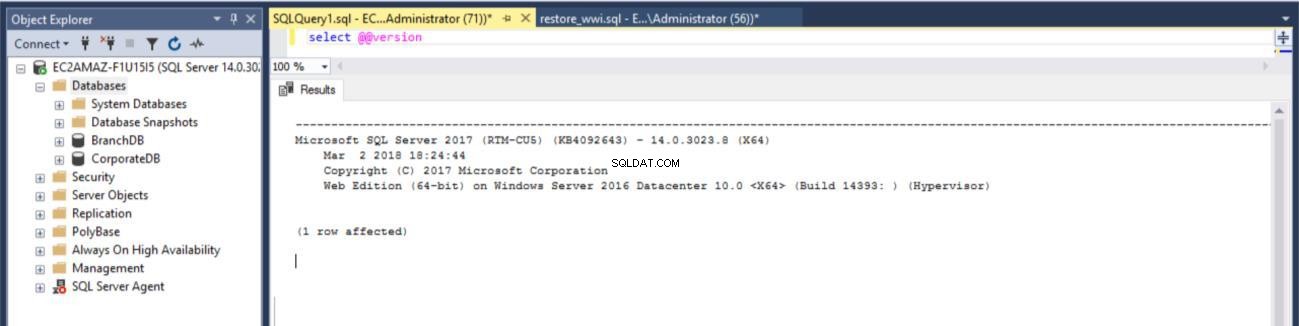
Fig. 1 versione di SQL Server
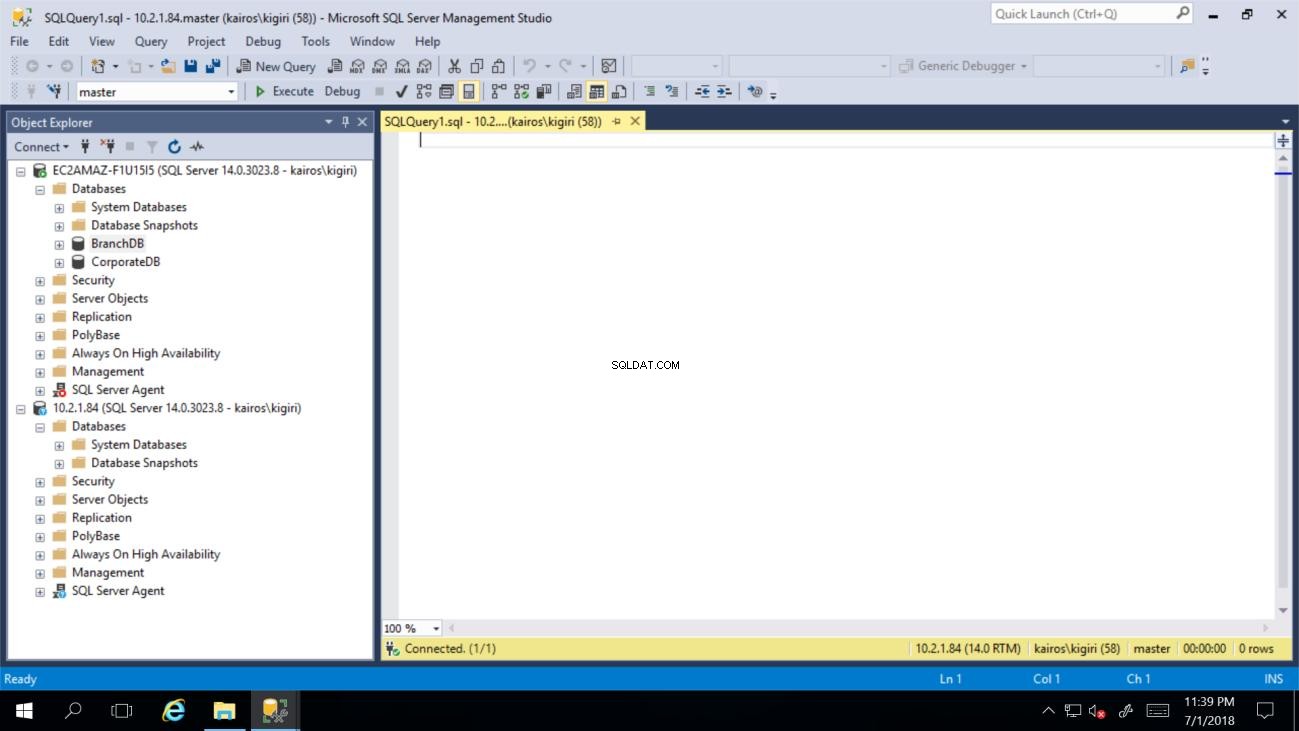
Fig. 2 BranchDB e CorporateDB su istanza primaria (istanza secondaria vuota)
Listato 1:ripristino del database di esempio di WideWorldImporters
restore filelistonly from disk='WideWorldImporters-Full.bak' restore database CorporateDB from disk='WideWorldImporters-Full.bak' with stats=10,recovery, move 'WWI_Primary' to 'M:\MSSQL\Data\WWI_Primary.mdf' , move 'WWI_UserData' to 'M:\MSSQL\Data\WWI_UserData.ndf' , move 'WWI_Log' to 'N:\MSSQL\Log\WWI_Log.ldf', move 'WWI_InMemory_Data_1' to 'M:\MSSQL\Data\WWI_InMemory_Data_1.ndf' restore database BranchDB from disk='WideWorldImporters-Full.bak' with stats=10,recovery, move 'WWI_Primary' to 'M:\MSSQL\Data\WWI_Primary1.mdf' , move 'WWI_UserData' to 'M:\MSSQL\Data\WWI_UserData1.ndf' , move 'WWI_Log' to 'N:\MSSQL\Log\WWI_Log1.ldf', move 'WWI_InMemory_Data_1' to 'M:\MSSQL\Data\WWI_InMemory_Data_11.ndf
Ora abbiamo due istanze, l'istanza primaria che ospita i due database primari (BranchDB e CorporateDB e l'istanza secondaria senza database utente. Procediamo con la configurazione del Transaction Log Shipping su entrambi i database ma li differenziamo applicando un ritardo al ripristino della configurazione del primo database. Ricordiamo che i database sono in realtà identici in termini di dati che contengono. Il grafico seguente mostra le opzioni chiave selezionate nella Configurazione Log Shipping.
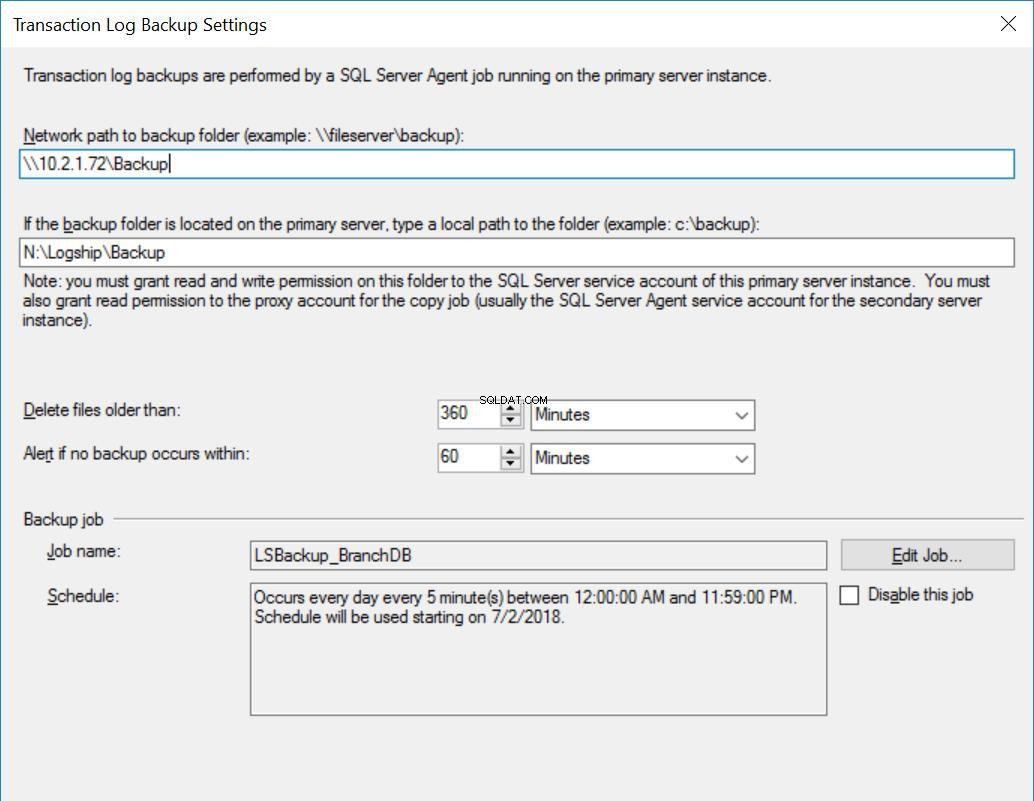
Fig. 3 Impostazioni di backup per BranchDB
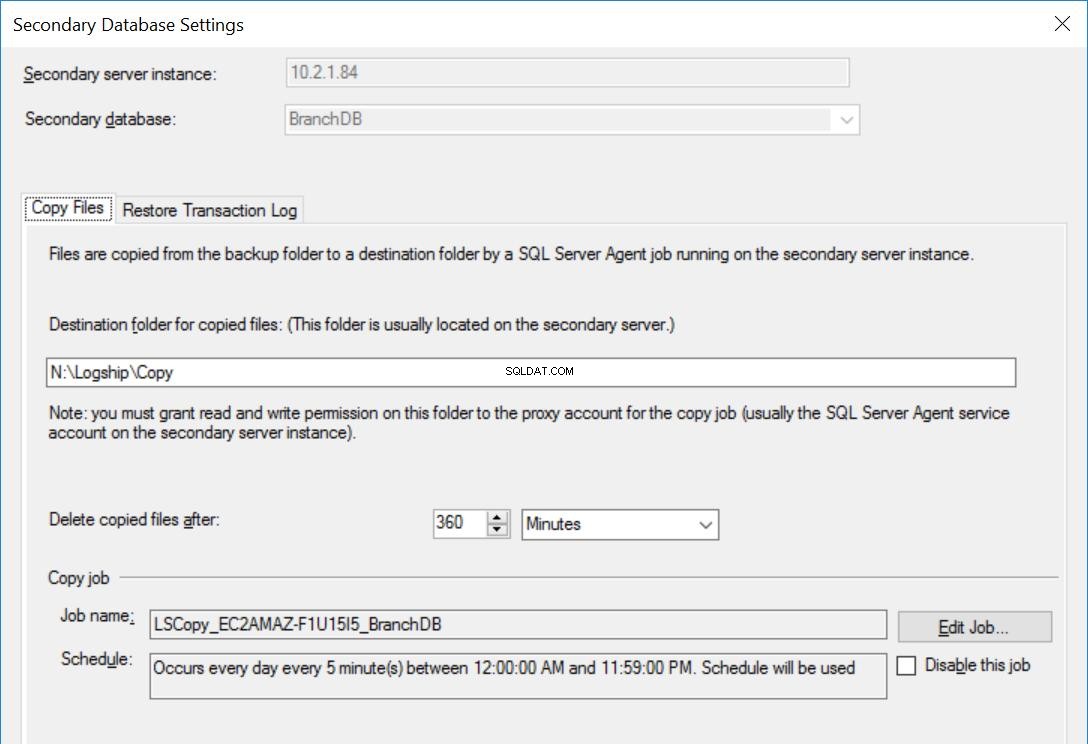
Fig. 4 Copia impostazioni per BranchDB
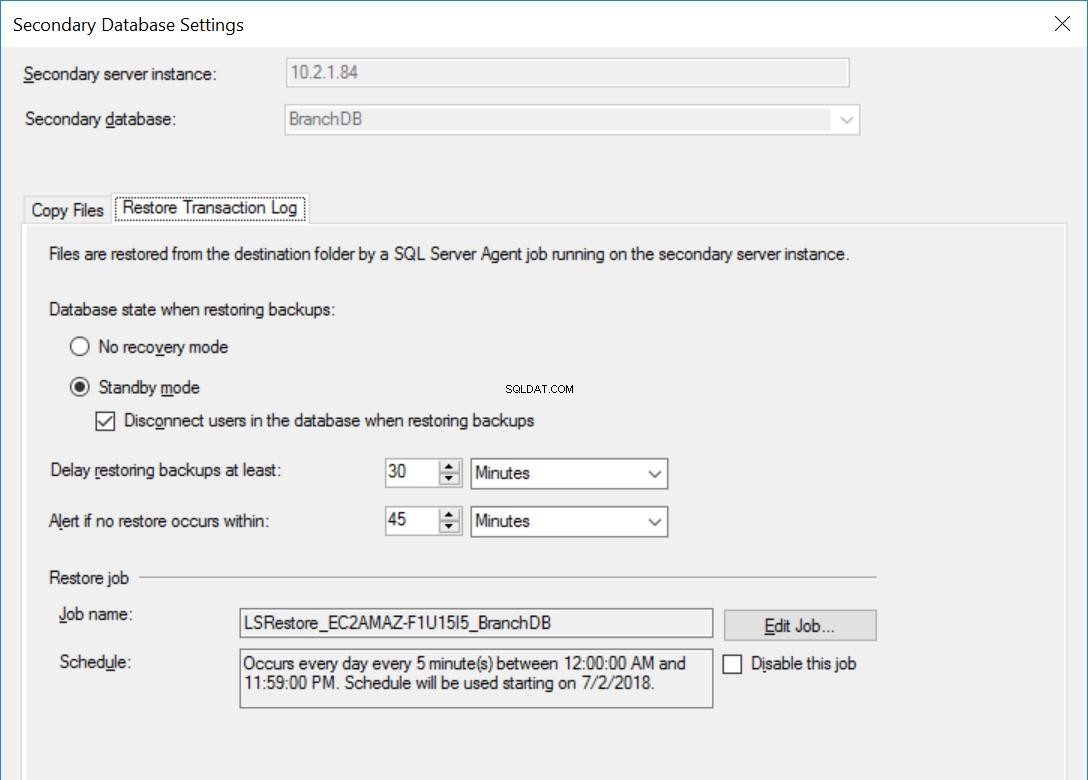
Fig. 5 Ripristina le impostazioni per BranchDB
Ogni processo di Log Shipping è configurato per l'esecuzione ogni cinque minuti. Per elaborare "Ritardo ripristino backup", è necessario utilizzare la modalità di ripristino standby nella configurazione Log Shipping. È logico poiché ha il database secondario in modalità standby e indica che possiamo interrogare il database secondario ogni volta che un ripristino del registro delle transazioni non è in corso. Il valore che specifichiamo in questa opzione (30 minuti in questo caso) ci offre una buona finestra durante la quale possiamo eseguire i rapporti dal database secondario oltre al requisito fondamentale di questo articolo che è essere in grado di recuperare dall'errore dell'utente.
Inoltre, dobbiamo menzionare che il ripristino dei backup del registro delle transazioni viene effettivamente ritardato. Il suo timestamp è successivo al valore del ritardo. Ciò significa che tutti i backup del registro delle transazioni verranno copiati sul server secondario, che è basato sulla pianificazione e specificato nel processo di copia. In effetti, il processo di ripristino verrà comunque eseguito secondo la pianificazione, ma i backup del registro delle transazioni (che non risalgono a 30 minuti prima) non verranno ripristinati. In sostanza, il database BranchDB Standby è 30 minuti indietro rispetto al database primario BranchDB. Per dimostrare questo ritardo, nella prossima sezione creeremo una tabella in entrambi i database e creeremo un lavoro che inserisce un record ogni minuto. Esamineremo questa tabella nei database secondari.
Le Impostazioni per il Database CorporateDB sono le stesse delle Figg. da 3 a 5, ad eccezione del processo di ripristino che NON è impostato per ritardare i backup del registro delle transazioni.
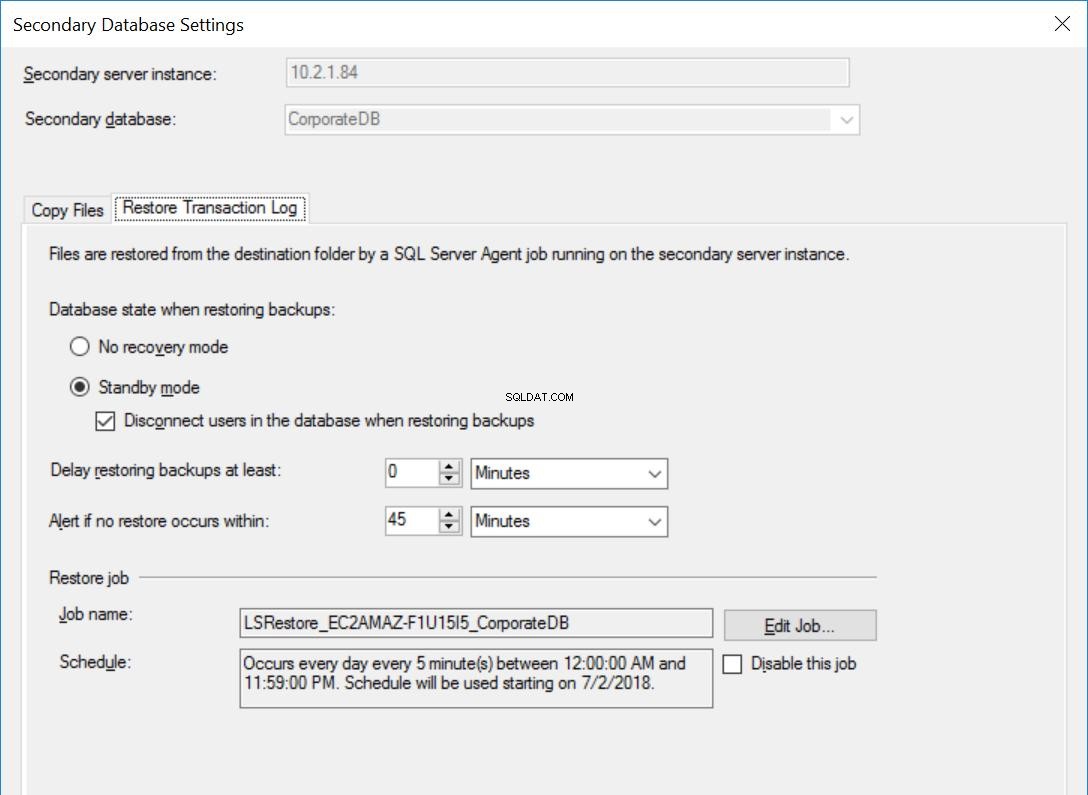
Fig. 6 Ripristina le impostazioni per CorporateDB
Verifica della configurazione
Una volta completata la configurazione, possiamo verificare che la configurazione sia OK e iniziare con l'osservazione del suo lavoro. Il rapporto sulla spedizione del registro delle transazioni ci mostra che il DB Branch è effettivamente in ritardo rispetto al CorporateDB in termini di ripristini:
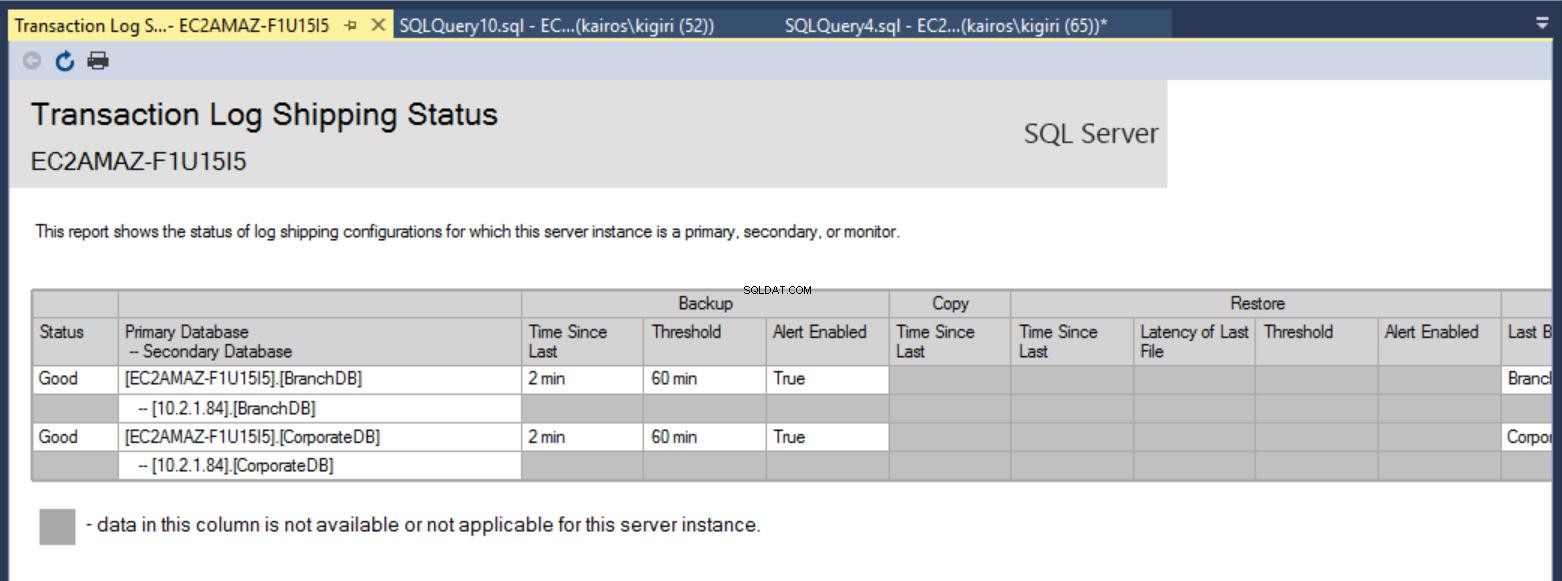
Fig. 7a Rapporto di spedizione del registro delle transazioni sul server primario
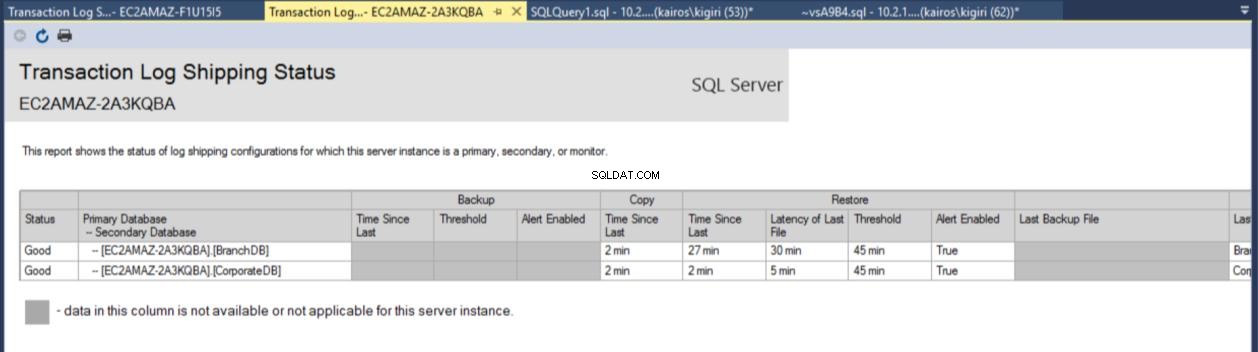
Fig. 7b Rapporto di spedizione del registro delle transazioni sul server secondario
Inoltre, noterai il messaggio di seguito nella cronologia dei lavori di ripristino per BranchDB:
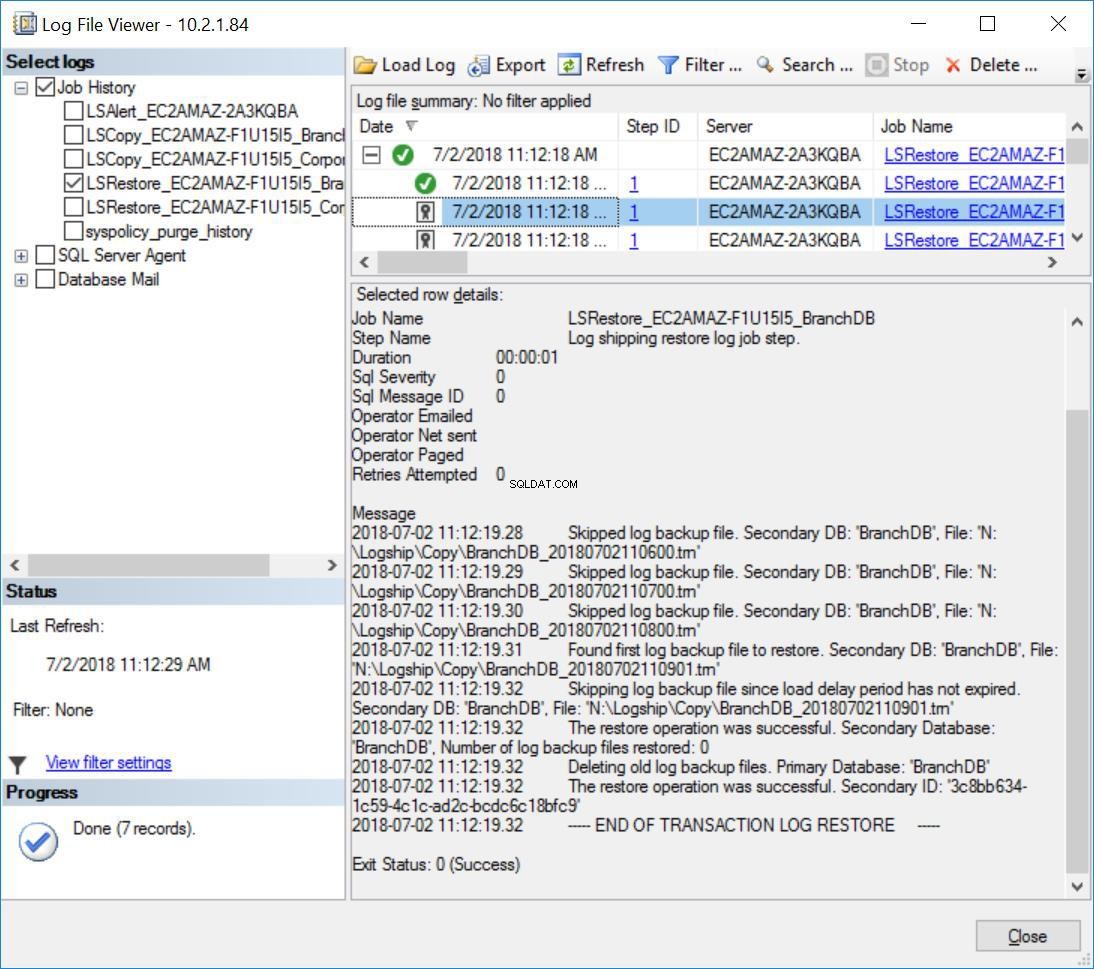
Fig. 8 Ripristini del registro delle transazioni saltati sul server secondario
Possiamo andare oltre con questa verifica creando una tabella e utilizzando un processo per popolare questa tabella con righe ogni minuto. Il lavoro è un modo semplice per simulare ciò che un'applicazione potrebbe fare su una tabella utente. Questo può mostrarci che questo ritardo è sicuramente mostrato nei dati dell'utente.
Listato 2 – Crea tabella log tracker
use BranchDB go create table log_ship_tracker ( ID int identity (100,1) ,Database_Name sysname default db_name() ,RecordTime datetime default getdate() ,ServerName sysname default @@servername) use CorporateDB go create table log_ship_tracker ( ID int identity (100,1) ,Database_Name sysname default db_name() ,RecordTime datetime default getdate() ,ServerName sysname default @@servername)
Listato 3 – Crea lavoro per popolare la tabella di tracciamento log
/* ==Scripting Parameters== Source Server Version : SQL Server 2017 (14.0.3023) Source Database Engine Edition : Microsoft SQL Server Standard Edition Source Database Engine Type : Standalone SQL Server Target Server Version : SQL Server 2017 Target Database Engine Edition : Microsoft SQL Server Standard Edition Target Database Engine Type : Standalone SQL Server */ USE [msdb] GO /****** Object: Job [InsertRecords] Script Date: 7/2/2018 3:32:00 PM ******/ BEGIN TRANSACTION DECLARE @ReturnCode INT SELECT @ReturnCode = 0 /****** Object: JobCategory [[Uncategorized (Local)]] Script Date: 7/2/2018 3:32:00 PM ******/ IF NOT EXISTS (SELECT name FROM msdb.dbo.syscategories WHERE name=N'[Uncategorized (Local)]' AND category_class=1) BEGIN EXEC @ReturnCode = msdb.dbo.sp_add_category @class=N'JOB', @type=N'LOCAL', @name=N'[Uncategorized (Local)]' IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback END DECLARE @jobId BINARY(16) EXEC @ReturnCode = msdb.dbo.sp_add_job @job_name=N'InsertRecords', @enabled=1, @notify_level_eventlog=0, @notify_level_email=0, @notify_level_netsend=0, @notify_level_page=0, @delete_level=0, @description=N'No description available.', @category_name=N'[Uncategorized (Local)]', @owner_login_name=N'kairos\kigiri', @job_id = @jobId OUTPUT IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback /****** Object: Step [InsertRecords] Script Date: 7/2/2018 3:32:00 PM ******/ EXEC @ReturnCode = msdb.dbo.sp_add_jobstep @example@sqldat.com, @step_name=N'InsertRecords', @step_id=1, @cmdexec_success_code=0, @on_success_action=1, @on_success_step_id=0, @on_fail_action=2, @on_fail_step_id=0, @retry_attempts=0, @retry_interval=0, @os_run_priority=0, @subsystem=N'TSQL', @command=N'use BranchDB go insert into log_ship_tracker values (db_name(),getdate(),@@servername) use CorporateDB go insert into log_ship_tracker values (db_name(),getdate(),@@servername) GO', @database_name=N'master', @flags=0 IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback EXEC @ReturnCode = msdb.dbo.sp_update_job @job_id = @jobId, @start_step_id = 1 IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback EXEC @ReturnCode = msdb.dbo.sp_add_jobschedule @example@sqldat.com, @name=N'Schedule', @enabled=1, @freq_type=4, @freq_interval=1, @freq_subday_type=4, @freq_subday_interval=1, @freq_relative_interval=0, @freq_recurrence_factor=0, @active_start_date=20180702, @active_end_date=99991231, @active_start_time=0, @active_end_time=235959, @schedule_uid=N'03e5f1b2-2e0b-4b30-8d60-3643c84aa08d' IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback EXEC @ReturnCode = msdb.dbo.sp_add_jobserver @job_id = @jobId, @server_name = N'(local)' IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback COMMIT TRANSACTION GOTO EndSave QuitWithRollback: IF (@@TRANCOUNT > 0) ROLLBACK TRANSACTION EndSave: GO
Quando interroghiamo la tabella rispettivamente sui database primari, possiamo confermare (utilizzando la colonna RecordTime) che le righe corrispondono in BranchDB e CorporateDB. Quando esaminiamo la tabella nei database secondari, allo stesso modo, vediamo chiaramente che abbiamo un intervallo di 30 minuti tra BranchDB e CorporateDB.
Listato 4 – Interrogazione della tabella Log Tracker
select top 10 @@servername [Current_Server],* from BranchDB.dbo.log_ship_tracker order by RecordTime desc select top 10 @@servername [Current_Server], * from CorporateDB.dbo.log_ship_tracker order by RecordTime desc
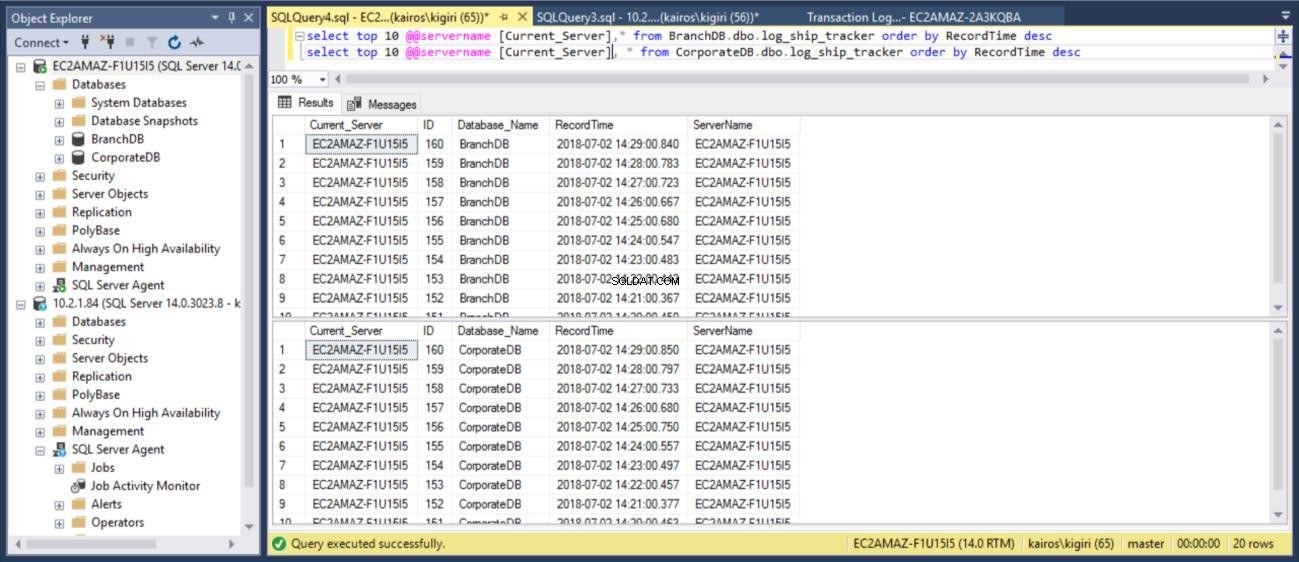
Fig. 9 Tabelle Log Tracker corrispondono nei database primari
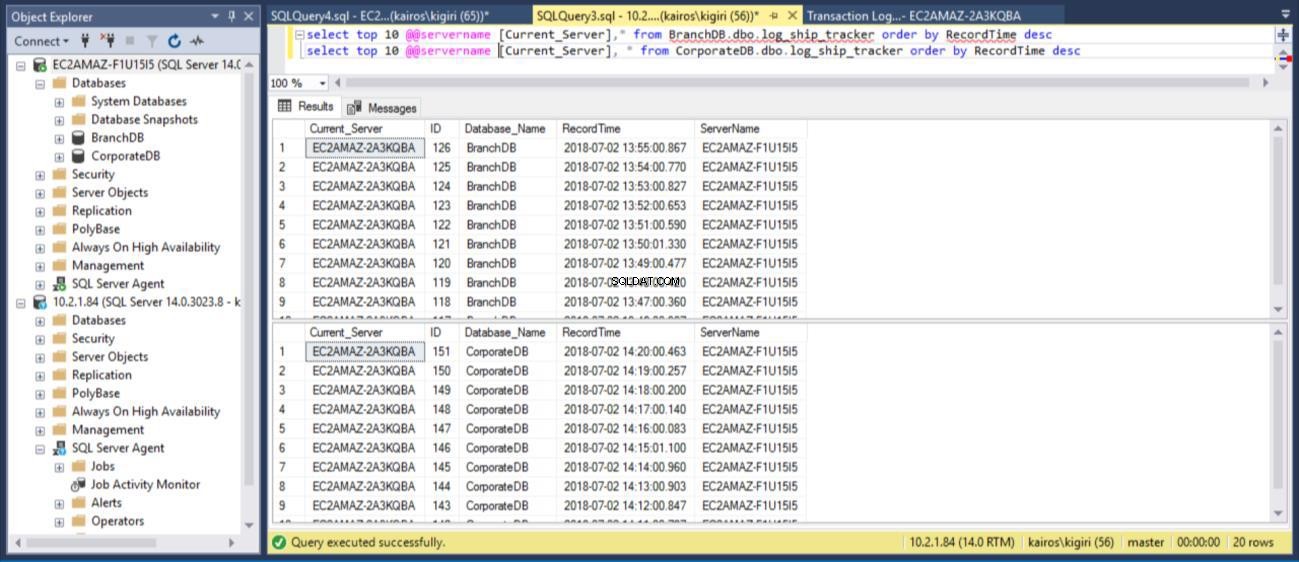
Fig. 10 tabelle Log Tracker hanno un gap di circa 30 minuti nei database secondari
Recupero da errore utente
Ora parliamo del vantaggio chiave di questo ritardo. Nello scenario in cui un utente elimina inavvertitamente una tabella, possiamo recuperare rapidamente i dati dal database secondario purché non sia trascorso il periodo di ritardo. In questo esempio, eliminiamo la tabella Sales.Orderlines su ENTRAMBI i database e verifichiamo che la tabella non esista più in ENTRAMBI i database.
Listato 5 – Eliminazione della tabella delle linee d'ordine
drop table BranchDB.Sales.Orderlines drop table CorporateDB.Sales.Orderlines GO use BranchDB go select @@servername [Current_Server] , db_name() [Database_Name] , name , schema_name(schema_id) [schema] , type_desc , create_date , modify_date from sys.tables where name='Orderlines' GO use CorporateDB go select @@servername [Current_Server] , db_name() [Database_Name] , name , schema_name(schema_id) [schema] , type_desc , create_date , modify_date from sys.tables where name='Orderlines' GO
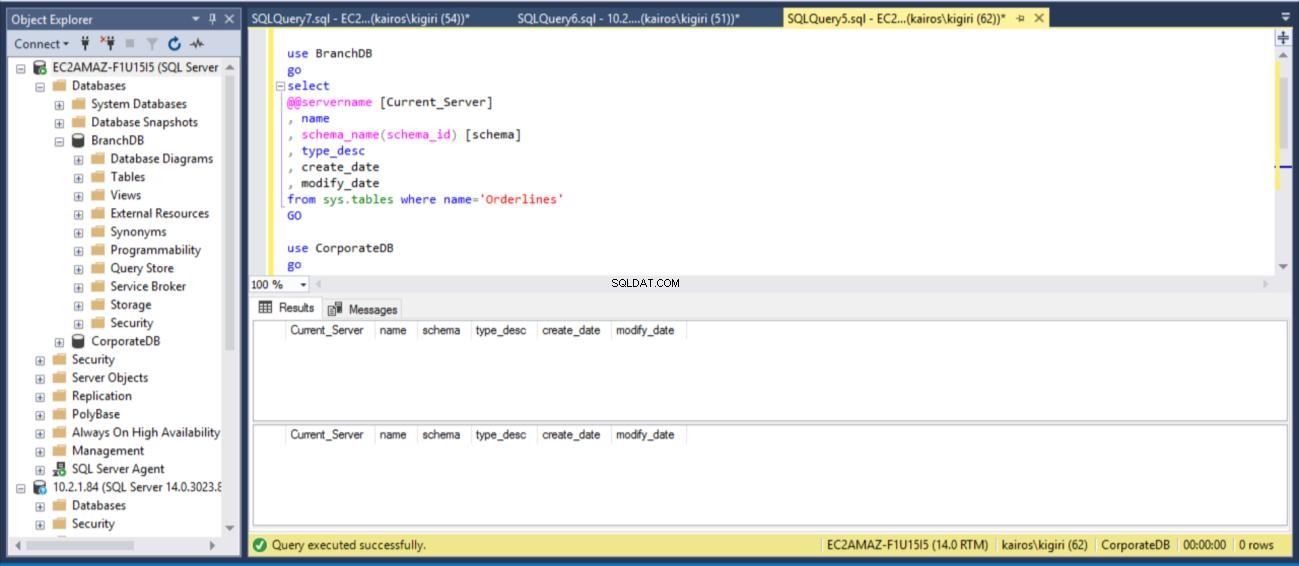
Fig. 11 Dropping Table Sales.Ordini
Quando cerchiamo la tabella sul server secondario, scopriamo che la tabella è ancora disponibile in ENTRAMBI i database. Pertanto, per CorporateDB abbiamo meno di cinque minuti per recuperare i dati. (Fig. 12). Ma una volta eseguito il successivo ripristino Cycle, perdiamo la tabella nel database del database aziendale. Per ripristinare questa tabella, è necessario eseguire il ripristino point-in-time utilizzando un backup completo in un ambiente separato e quindi estrarre questa tabella specifica. Sarai d'accordo che ci vorrà del tempo. Per la tabella BranchDB Orderlines, abbiamo un po' più di tempo e possiamo recuperare la tabella con una singola istruzione SQL su un server collegato (vedi Listato 6).
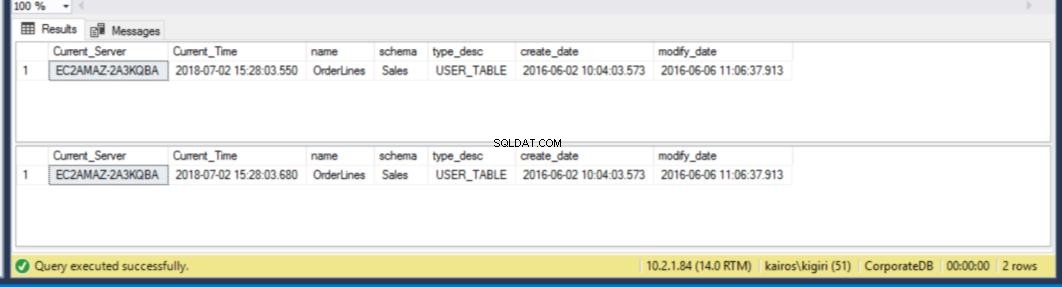
Fig. 12 Conto alla rovescia di cinque minuti:la tabella esiste in entrambi i database secondari
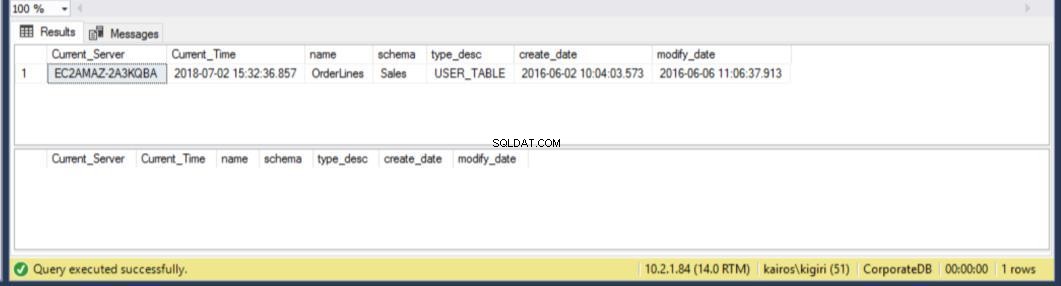
Fig. 13 25 minuti aggiuntivi per recuperare la tabella BranchDB
Listato 6 – Recupera tabella ordini
USE [master] GO /****** Object: LinkedServer [10.2.1.84] Script Date: 7/2/2018 4:14:59 PM ******/ EXEC master.dbo.sp_addlinkedserver @server = N'10.2.1.84', @srvproduct=N'SQL Server' /* For security reasons the linked server remote logins password is changed with ######## */ EXEC master.dbo.sp_addlinkedsrvlogin @rmtsrvname=N'10.2.1.84',@useself=N'True',@locallogin=NULL,@rmtuser=NULL,@rmtpasswo rd=NULL GO select * into BranchDB.Sales.Orderlines from [10.2.1.84].BranchDB.Sales.Orderlines
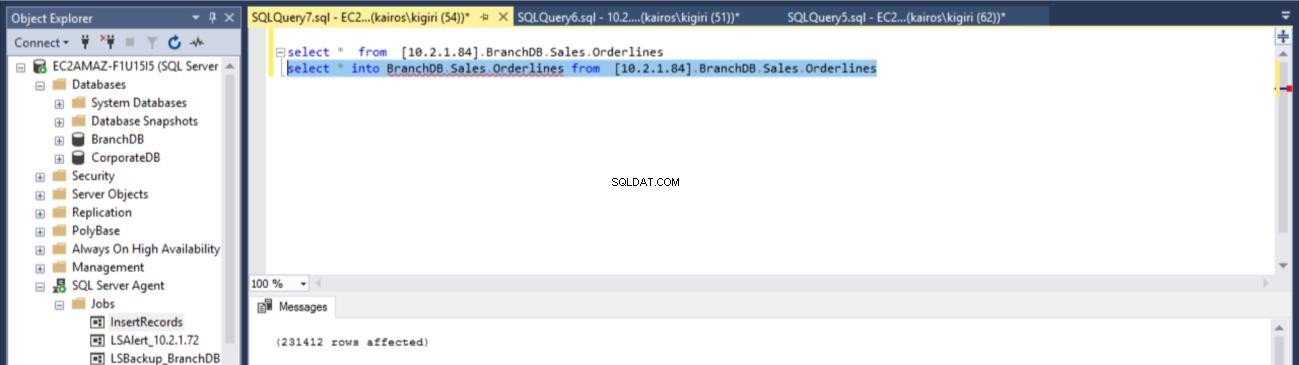
Fig. 14 Recuperare la tabella Sales.Orderlines di BranchDB
Quindi verifichiamo sul server primario (database BranchDB) che la tabella sia stata ripristinata.
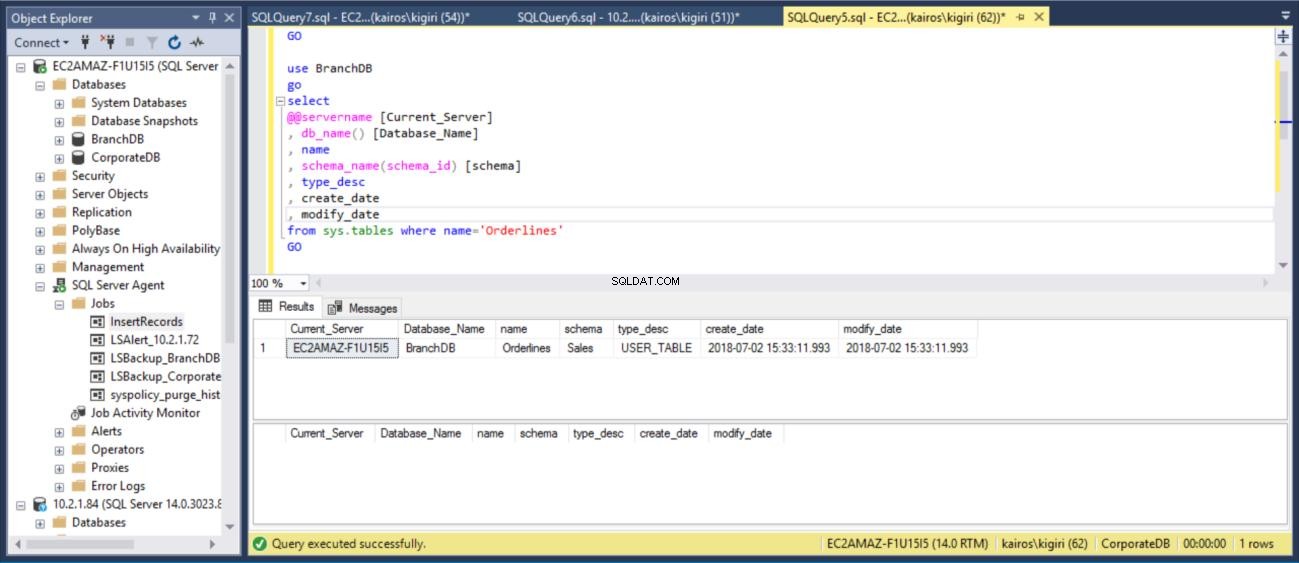
Fig. 15 Recuperare la tabella Sales.Orderlines di BranchDB
Conclusione
SQL Server offre diversi modi per eseguire il ripristino dalla perdita di dati dovuta a diverse cause principali:guasto del disco, danneggiamento, errore dell'utente e così via. Il ripristino point-in-time dai backup è probabilmente il più noto di questi metodi. Per alcuni semplici casi di errore dell'utente o casi simili, in cui uno o due oggetti vengono persi, l'utilizzo di Transaction Log Shipping con Delayed Recovery è un buon approccio da considerare. Tuttavia, va notato che un database secondario, che è configurato rigorosamente per le esigenze di DR, deve essere selezionato per RPO inferiori.