Il mio amico Peter Larsson mi ha inviato una sfida T-SQL che prevedeva la corrispondenza tra domanda e offerta. Per quanto riguarda le sfide, è formidabile. È un'esigenza abbastanza comune nella vita reale; è semplice da descrivere ed è abbastanza facile da risolvere con prestazioni ragionevoli utilizzando una soluzione basata sul cursore. La parte difficile è risolverlo utilizzando una soluzione efficiente basata su set.
Quando Peter mi invia un puzzle, di solito rispondo con una soluzione suggerita e di solito trova una soluzione brillante e con prestazioni migliori. A volte sospetto che mi mandi enigmi per motivarsi a trovare un'ottima soluzione.
Poiché l'attività rappresenta un'esigenza comune ed è molto interessante, ho chiesto a Peter se gli dispiacerebbe se condividessi l'argomento e le sue soluzioni con i lettori di sqlperformance.com, ed è stato felice di permettermelo.
Questo mese presenterò la sfida e la classica soluzione basata sul cursore. Negli articoli successivi presenterò soluzioni basate su set, comprese quelle su cui abbiamo lavorato io e Peter.
La sfida
La sfida consiste nell'interrogare una tabella chiamata Aste, che crei utilizzando il seguente codice:
DROP TABLE IF EXISTS dbo.Auctions;
CREATE TABLE dbo.Auctions
(
ID INT NOT NULL IDENTITY(1, 1)
CONSTRAINT pk_Auctions PRIMARY KEY CLUSTERED,
Code CHAR(1) NOT NULL
CONSTRAINT ck_Auctions_Code CHECK (Code = 'D' OR Code = 'S'),
Quantity DECIMAL(19, 6) NOT NULL
CONSTRAINT ck_Auctions_Quantity CHECK (Quantity > 0)
); Questa tabella contiene le voci della domanda e dell'offerta. Le voci di domanda sono contrassegnate con il codice D e le voci di fornitura con S. Il tuo compito è abbinare le quantità di domanda e offerta in base all'ordine ID, scrivendo il risultato in una tabella temporanea. Le voci potrebbero rappresentare ordini di acquisto e vendita di criptovaluta come BTC/USD, ordini di acquisto e vendita di azioni come MSFT/USD o qualsiasi altro articolo o bene in cui è necessario far corrispondere l'offerta con la domanda. Si noti che alle voci delle aste manca un attributo di prezzo. Come accennato, è necessario abbinare le quantità della domanda e dell'offerta in base all'ordine ID. Questo ordinamento potrebbe essere derivato dal prezzo (crescente per le voci di offerta e decrescente per le voci di domanda) o da qualsiasi altro criterio pertinente. In questa sfida, l'idea era di mantenere le cose semplici e presumere che l'ID rappresentasse già l'ordine rilevante per la corrispondenza.
Ad esempio, utilizza il codice seguente per riempire la tabella Aste con un piccolo insieme di dati di esempio:
SET NOCOUNT ON; DELETE FROM dbo.Auctions; SET IDENTITY_INSERT dbo.Auctions ON; INSERT INTO dbo.Auctions(ID, Code, Quantity) VALUES (1, 'D', 5.0), (2, 'D', 3.0), (3, 'D', 8.0), (5, 'D', 2.0), (6, 'D', 8.0), (7, 'D', 4.0), (8, 'D', 2.0), (1000, 'S', 8.0), (2000, 'S', 6.0), (3000, 'S', 2.0), (4000, 'S', 2.0), (5000, 'S', 4.0), (6000, 'S', 3.0), (7000, 'S', 2.0); SET IDENTITY_INSERT dbo.Auctions OFF;
Dovresti abbinare le quantità della domanda e dell'offerta in questo modo:
- Una quantità di 5,0 viene abbinata per Domanda 1 e Offerta 1000, esaurendo la Domanda 1 e lasciando 3,0 di Offerta 1000
- Una quantità di 3,0 viene abbinata per Domanda 2 e Offerta 1000, esaurendo sia la Domanda 2 che l'Offerta 1000
- Una quantità di 6,0 viene abbinata per Domanda 3 e Offerta 2000, lasciando 2,0 di Domanda 3 e esaurendo l'offerta 2000
- Una quantità di 2,0 viene abbinata per Domanda 3 e Offerta 3000, esaurendo sia la Domanda 3 che l'Offerta 3000
- Una quantità di 2,0 viene abbinata per Domanda 5 e Offerta 4000, esaurendo sia la Domanda 5 che l'Offerta 4000
- Una quantità di 4,0 viene abbinata per la domanda 6 e l'offerta 5000, lasciando 4,0 della domanda 6 ed esaurendo l'offerta 5000
- Una quantità di 3,0 viene abbinata per la domanda 6 e l'offerta 6000, lasciando 1,0 della domanda 6 ed esaurendo l'offerta 6000
- Una quantità di 1,0 viene abbinata per Domanda 6 e Offerta 7000, esaurendo la Domanda 6 e lasciando 1,0 di Offerta 7000
- Una quantità di 1,0 è abbinata per la Domanda 7 e l'Offerta 7000, lasciando 3,0 della Domanda 7 ed esaurendo l'Offerta 7000; La domanda 8 non è abbinata ad alcuna voce di offerta e pertanto viene lasciata con l'intera quantità 2.0
La tua soluzione dovrebbe scrivere i seguenti dati nella tabella temporanea risultante:
DemandID SupplyID TradeQuantity ----------- ----------- -------------- 1 1000 5.000000 2 1000 3.000000 3 2000 6.000000 3 3000 2.000000 5 4000 2.000000 6 5000 4.000000 6 6000 3.000000 6 7000 1.000000 7 7000 1.000000
Grande serie di dati campione
Per testare le prestazioni delle soluzioni, avrai bisogno di un set più ampio di dati di esempio. Per aiutare con questo, puoi usare la funzione GetNums, che crei eseguendo il seguente codice:
CREATE FUNCTION dbo.GetNums(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum;
GO Questa funzione restituisce una sequenza di numeri interi nell'intervallo richiesto.
Con questa funzione attiva, puoi utilizzare il seguente codice fornito da Peter per popolare la tabella Aste con dati di esempio, personalizzando gli input secondo necessità:
DECLARE
-- test with 50K, 100K, 150K, 200K in each of variables @Buyers and @Sellers
-- so total rowcount is double (100K, 200K, 300K, 400K)
@Buyers AS INT = 200000,
@Sellers AS INT = 200000,
@BuyerMinQuantity AS DECIMAL(19, 6) = 0.000001,
@BuyerMaxQuantity AS DECIMAL(19, 6) = 99.999999,
@SellerMinQuantity AS DECIMAL(19, 6) = 0.000001,
@SellerMaxQuantity AS DECIMAL(19, 6) = 99.999999;
DELETE FROM dbo.Auctions;
INSERT INTO dbo.Auctions(Code, Quantity)
SELECT Code, Quantity
FROM ( SELECT 'D' AS Code,
(ABS(CHECKSUM(NEWID())) % (1000000 * (@BuyerMaxQuantity - @BuyerMinQuantity)))
/ 1000000E + @BuyerMinQuantity AS Quantity
FROM dbo.GetNums(1, @Buyers)
UNION ALL
SELECT 'S' AS Code,
(ABS(CHECKSUM(NEWID())) % (1000000 * (@SellerMaxQuantity - @SellerMinQuantity)))
/ 1000000E + @SellerMinQuantity AS Quantity
FROM dbo.GetNums(1, @Sellers) ) AS X
ORDER BY NEWID();
SELECT Code, COUNT(*) AS Items
FROM dbo.Auctions
GROUP BY Code; Come puoi vedere, puoi personalizzare il numero di acquirenti e venditori, nonché le quantità minime e massime di acquirenti e venditori. Il codice sopra specifica 200.000 acquirenti e 200.000 venditori, per un totale di 400.000 righe nella tabella Aste. L'ultima query indica quante voci di domanda (D) e di offerta (S) sono state scritte nella tabella. Restituisce il seguente output per i suddetti input:
Code Items ---- ----------- D 200000 S 200000
Testerò le prestazioni di varie soluzioni utilizzando il codice sopra, impostando il numero di acquirenti e venditori ciascuno sul seguente:50.000, 100.000, 150.000 e 200.000. Ciò significa che otterrò il seguente numero totale di righe nella tabella:100.000, 200.000, 300.000 e 400.000. Ovviamente puoi personalizzare gli input a tuo piacimento per testare le prestazioni delle tue soluzioni.
Soluzione basata su cursore
Peter ha fornito la soluzione basata sul cursore. È piuttosto semplice, che è uno dei suoi importanti vantaggi. Verrà utilizzato come benchmark.
La soluzione utilizza due cursori:uno per i movimenti di domanda ordinati per ID e l'altro per i movimenti di fornitura ordinati per ID. Per evitare una scansione completa e un ordinamento per cursore, crea il seguente indice:
CREATE UNIQUE NONCLUSTERED INDEX idx_Code_ID_i_Quantity ON dbo.Auctions(Code, ID) INCLUDE(Quantity);
Ecco il codice completo della soluzione:
SET NOCOUNT ON;
DROP TABLE IF EXISTS #PairingsCursor;
CREATE TABLE #PairingsCursor
(
DemandID INT NOT NULL,
SupplyID INT NOT NULL,
TradeQuantity DECIMAL(19, 6) NOT NULL
);
DECLARE curDemand CURSOR LOCAL FORWARD_ONLY READ_ONLY FOR
SELECT ID AS DemandID, Quantity FROM dbo.Auctions WHERE Code = 'D' ORDER BY ID;
DECLARE curSupply CURSOR LOCAL FORWARD_ONLY READ_ONLY FOR
SELECT ID AS SupplyID, Quantity FROM dbo.Auctions WHERE Code = 'S' ORDER BY ID;
DECLARE @DemandID AS INT, @DemandQuantity AS DECIMAL(19, 6),
@SupplyID AS INT, @SupplyQuantity AS DECIMAL(19, 6);
OPEN curDemand;
FETCH NEXT FROM curDemand INTO @DemandID, @DemandQuantity;
OPEN curSupply;
FETCH NEXT FROM curSupply INTO @SupplyID, @SupplyQuantity;
WHILE @@FETCH_STATUS = 0
BEGIN
IF @DemandQuantity <= @SupplyQuantity
BEGIN
INSERT #PairingsCursor(DemandID, SupplyID, TradeQuantity)
VALUES(@DemandID, @SupplyID, @DemandQuantity);
SET @SupplyQuantity -= @DemandQuantity;
FETCH NEXT FROM curDemand INTO @DemandID, @DemandQuantity;
END;
ELSE
BEGIN
IF @SupplyQuantity > 0
BEGIN
INSERT #PairingsCursor(DemandID, SupplyID, TradeQuantity)
VALUES(@DemandID, @SupplyID, @SupplyQuantity);
SET @DemandQuantity -= @SupplyQuantity;
END;
FETCH NEXT FROM curSupply INTO @SupplyID, @SupplyQuantity;
END;
END;
CLOSE curDemand;
DEALLOCATE curDemand;
CLOSE curSupply;
DEALLOCATE curSupply; Come puoi vedere, il codice inizia creando una tabella temporanea. Quindi dichiara i due cursori e preleva una riga da ciascuno, scrivendo la quantità di domanda corrente nella variabile @DemandQuantity e la quantità di fornitura corrente in @SupplyQuantity. Quindi elabora le voci in un ciclo finché l'ultimo recupero è andato a buon fine. Il codice applica la seguente logica nel corpo del ciclo:
Se la quantità richiesta corrente è inferiore o uguale alla quantità offerta corrente, il codice effettua le seguenti operazioni:
- Scrive una riga nella tabella temporanea con l'abbinamento corrente, con la quantità richiesta (@DemandQuantity) come quantità abbinata
- Sottrae la quantità richiesta corrente dalla quantità offerta corrente (@SupplyQuantity)
- Recupera la riga successiva dal cursore della domanda
In caso contrario, il codice esegue le seguenti operazioni:
- Verifica se la quantità di fornitura corrente è maggiore di zero e, in tal caso, effettua le seguenti operazioni:
- Scrive una riga nella tabella temporanea con l'abbinamento corrente, con la quantità di fornitura come quantità abbinata
- Sottrae la quantità di offerta corrente dalla quantità di domanda corrente
- Recupera la riga successiva dal cursore di fornitura
Una volta terminato il ciclo, non ci sono più coppie da abbinare, quindi il codice ripulisce solo le risorse del cursore.
Dal punto di vista delle prestazioni, ottieni il tipico sovraccarico del recupero e del ciclo del cursore. Inoltre, questa soluzione esegue un singolo passaggio ordinato sui dati della domanda e un singolo passaggio ordinato sui dati dell'offerta, ciascuno utilizzando una scansione di ricerca e intervallo nell'indice creato in precedenza. I piani per le query del cursore sono mostrati nella Figura 1.

Figura 1:Piani per le query del cursore
Poiché il piano esegue una scansione dell'intervallo di ricerca e ordinato di ciascuna delle parti (domanda e offerta) senza alcuno smistamento, ha un ridimensionamento lineare. Ciò è stato confermato dai numeri di prestazioni che ho ottenuto durante il test, come mostrato nella Figura 2.
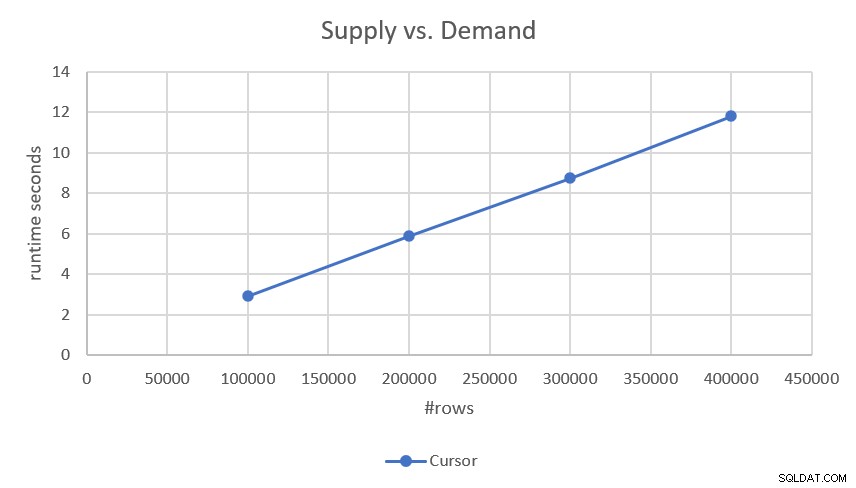
Figura 2:prestazioni della soluzione basata su cursore
Se sei interessato a tempi di esecuzione più precisi, eccoli qui:
- 100.000 righe (50.000 richieste e 50.000 forniture):2,93 secondi
- 200.000 righe:5,89 secondi
- 300.000 righe:8,75 secondi
- 400.000 righe:11,81 secondi
Dato che la soluzione ha una scalabilità lineare, puoi facilmente prevedere il tempo di esecuzione con altre scale. Ad esempio, con un milione di righe (ad esempio, 500.000 richieste e 500.000 forniture) l'esecuzione dovrebbe richiedere circa 29,5 secondi.
La sfida è iniziata
La soluzione basata sul cursore ha un ridimensionamento lineare e, in quanto tale, non è male. Ma comporta il tipico recupero del cursore e il looping overhead. Ovviamente, puoi ridurre questo sovraccarico implementando lo stesso algoritmo utilizzando una soluzione basata su CLR. La domanda è:puoi trovare una soluzione basata su set dalle prestazioni ottimali per questa attività?
Come accennato, a partire dal prossimo mese esplorerò soluzioni basate su set, sia con prestazioni scadenti che con buone prestazioni. Nel frattempo, se sei all'altezza della sfida, prova a trovare soluzioni personalizzate basate sui set.
Per verificare la correttezza della tua soluzione, confronta prima il suo risultato con quello mostrato qui per il piccolo insieme di dati campione. Puoi anche verificare la validità del risultato della tua soluzione con un ampio set di dati campione verificando che la differenza simmetrica tra il risultato della soluzione del cursore e il tuo sia vuota. Supponendo che il risultato del cursore sia archiviato in una tabella temporanea chiamata #PairingsCursor e il tuo in una tabella temporanea chiamata #MyPairings, puoi utilizzare il codice seguente per ottenere ciò:
(SELECT * FROM #PairingsCursor EXCEPT SELECT * FROM #MyPairings) UNION ALL (SELECT * FROM #MyPairings EXCEPT SELECT * FROM #PairingsCursor);
Il risultato dovrebbe essere vuoto.
Buona fortuna!
[ Vai alle soluzioni:Parte 1 | Parte 2 | parte 3]