Questo articolo illustra il processo di distribuzione passo passo del log shipping di SQL Server. È la soluzione di ripristino di emergenza a livello di database facile da configurare e mantenere.
Il log shipping prevede tre passaggi:
- Genera il backup del log sul database primario.
- Copia il backup nel percorso di rete o nella directory specifica sul server secondario.
- Ripristina il backup del registro sul server secondario.
La tecnologia di log shipping esegue i passaggi descritti in precedenza utilizzando i processi dell'agente di SQL Server. Durante il processo di configurazione, la procedura guidata di log shipping crea quei lavori sui server primari e secondari.
Il log shipping può essere in due modalità operative.
- Modalità di ripristino . Il processo SQL ripristina i backup del registro delle transazioni nel database secondario. Lo stato del database è RIPRISTINO , e non è accessibile.
- Modalità standby . Il processo SQL ripristina i backup del registro delle transazioni nel database secondario, ma il database può rimanere in modalità di sola lettura. Pertanto, gli utenti possono eseguire operazioni di lettura su di esso. Con questa opzione, possiamo scaricare l'applicazione di reporting.
Nota:la modalità Standby presenta uno svantaggio:il database non è disponibile durante l'esecuzione del processo di ripristino. Tutti gli utenti connessi al database devono disconnettersi durante tale processo. In caso contrario, il processo di ripristino può essere ritardato .
Lo svantaggio principale del log shipping è l'assenza del supporto per il failover automatico. Per eseguire un failover, devi eseguire i seguenti passaggi:
- Genera un backup del registro di coda e copialo su un server database secondario.
- Interrompi tutti i processi di log shipping sul server primario.
- Ripristina il registro sul server secondario.
Questo processo può ritardare la disponibilità del database secondario.
Passiamo ora all'esame passo passo del processo di distribuzione. Per prima cosa abbiamo preparato la workstation impostandola nel modo seguente:
| Nome server | Ruolo |
| SQL01 | Server primario |
| SQL02 | Server secondario |
| iSCSI\SQL2017 | Server di monitoraggio |
| \\dominio\Backup di spedizione log | Condivisione di rete per copiare i backup |
Configura il server primario
SQL01 funge da server primario e database. Imposteremo il log shipping tra il database AdventureWorks2017.
Per configurare il Log shipping, connettiti all'istanza SQL01:
- Apri SQL Server Management Studio
- Espandi database
- Fai clic con il pulsante destro del mouse su AdventureWorks2017
- Passa il mouse su Attività
- Fai clic su Registri delle transazioni di spedizione.
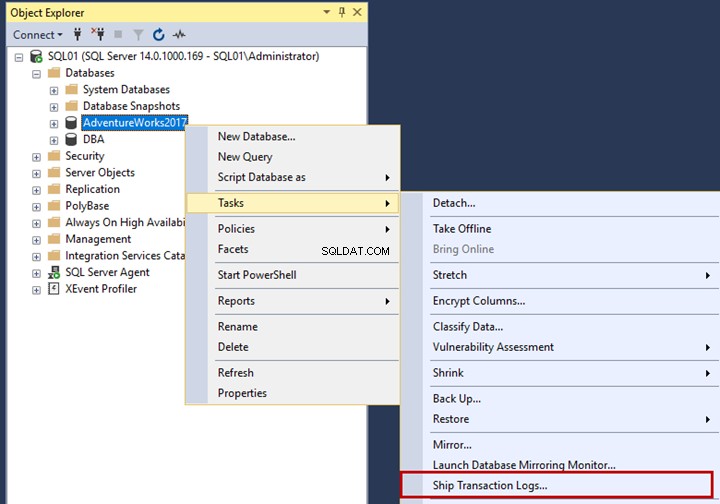
Le Proprietà del database si apre la finestra di dialogo.
Per abilitare il log shipping, fai clic su Abilita questo come database primario in una configurazione di log shipping opzione.
Per configurare la pianificazione del backup del registro delle transazioni per la spedizione del registro, fai clic su Impostazioni di backup .
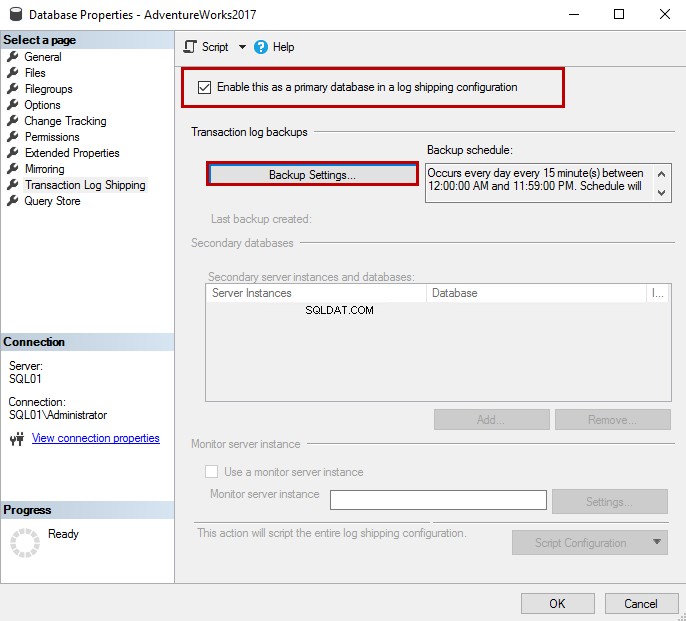
Si apre una finestra di dialogo, "Impostazioni di backup del registro delle transazioni".
Nella finestra di dialogo, specifica la condivisione di rete in cui desideri copiare i backup del registro delle transazioni:il Percorso di rete alla cartella di backup casella di testo. Puoi determinare il periodo di conservazione del backup in Elimina file più vecchi di indicato nella casella di testo. Se il processo di backup non riesce o il file di backup non si verifica per il tempo specificato nella casella di testo, SQL Server genera un avviso.
Nel log shipping, SQL Server copia i backup dei file di registro nella condivisione di rete. La procedura guidata crea automaticamente un processo di backup durante il processo di distribuzione. Crea automaticamente anche una pianificazione, ma puoi modificarla facendo clic sul pulsante Pianifica.
Nel mio caso, ho cambiato il nome del processo di backup per identificarlo. Il nome del lavoro è LogShipping_Backup_AdventureWorks2017 .
Non ho apportato modifiche alla pianificazione del lavoro e alle impostazioni di compressione del backup.
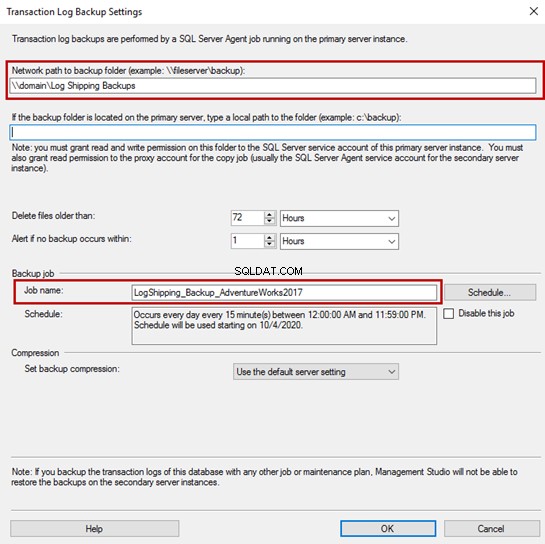
Configura il server secondario
Per aggiungere il server secondario e il database, fai clic su "Aggiungi" nelle Proprietà database finestra di dialogo.
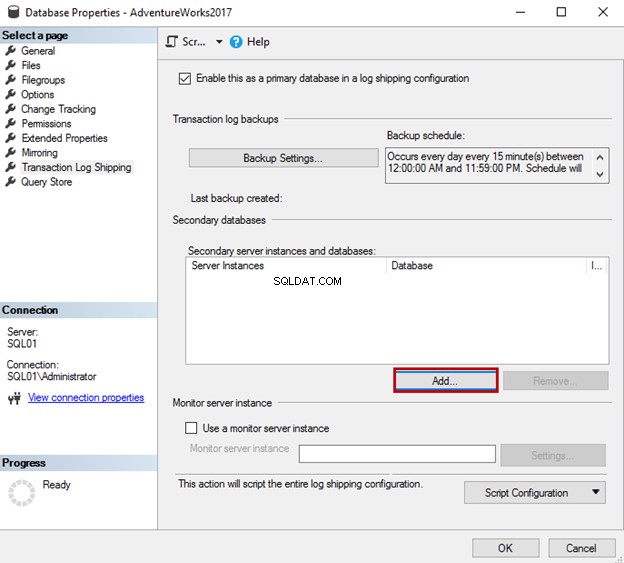
Una finestra di dialogo denominata Impostazioni database secondarie aprirà. Dobbiamo connetterci al server di database secondario. Per farlo, fai clic su "Aggiungi".
Si apre una finestra di dialogo. Inserisci il nome del server e fai clic su Connetti :
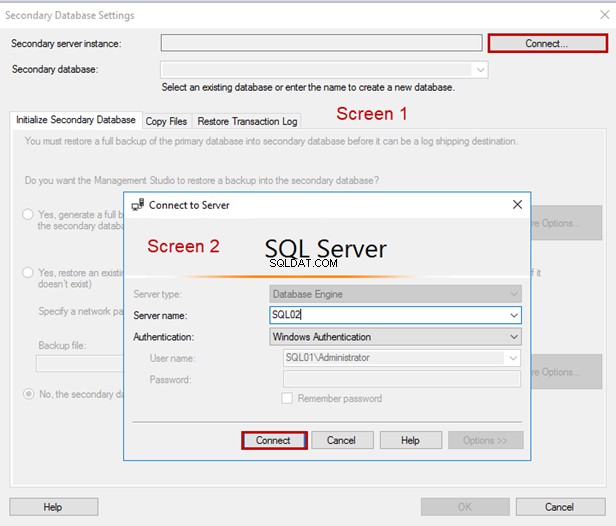
Configurazione delle impostazioni del database secondario
Inizia il database secondario
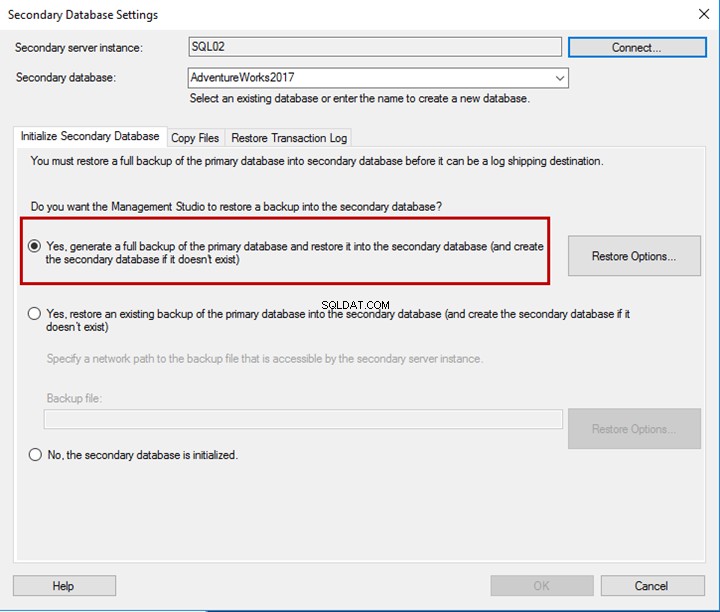
Nella scheda Inizializza database secondario, puoi impostare una delle tre opzioni seguenti per ripristinare il database:
- Se il database non esiste sul server secondario, è possibile generare un backup completo e ripristinarlo sul server secondario. In questo scenario, puoi utilizzare la prima opzione.
- Se è presente un backup completo di un database generato da altri processi di backup, o se ne hai già uno, puoi ripristinarlo sul server secondario. In questo scenario, puoi scegliere la seconda opzione.
- Se hai ripristinato il database secondario con lo stato NORECOVERY, puoi scegliere la terza opzione.
Copia file
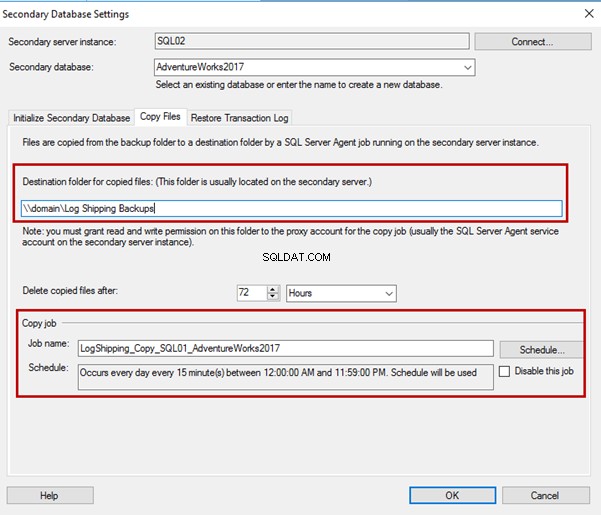
In Copia file scheda, è possibile specificare la directory di destinazione per la posizione dei file di backup copiati. Qui viene definito anche il periodo di conservazione.
La procedura guidata crea un processo SQL per copiare i file nella directory di destinazione. La cartella di destinazione del backup è \\domain\Log Shipping Backups. Il nome del processo di copia è LogShipping_Copy_SQL01_AdventureWorks2017 .
Ripristina registro transazioni
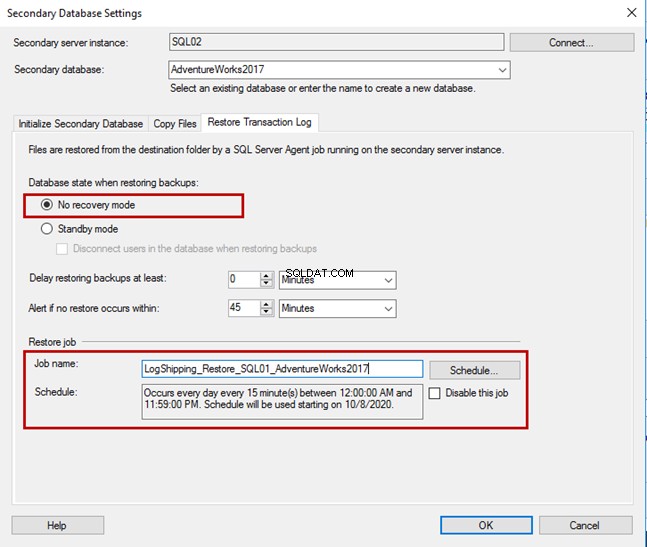
Nel Ripristina registro transazioni scheda, è possibile specificare la modalità database. Se desideri mantenere il database in modalità di sola lettura, seleziona Modalità standby oppure scegli Nessuna modalità di ripristino .
In questa demo, manteniamo lo stato del database come NORECOVERY. È possibile specificare il ritardo di ripristino del backup e configurare avvisi per i backup non ripristinati entro un intervallo specificato. Nel nostro caso, non utilizziamo le impostazioni predefinite.
Il nome del processo di ripristino è LogShipping_Restore_SQL01_AdventureWorks2017.
Una volta che la configurazione è pronta, fai clic su OK per salvare le modifiche.
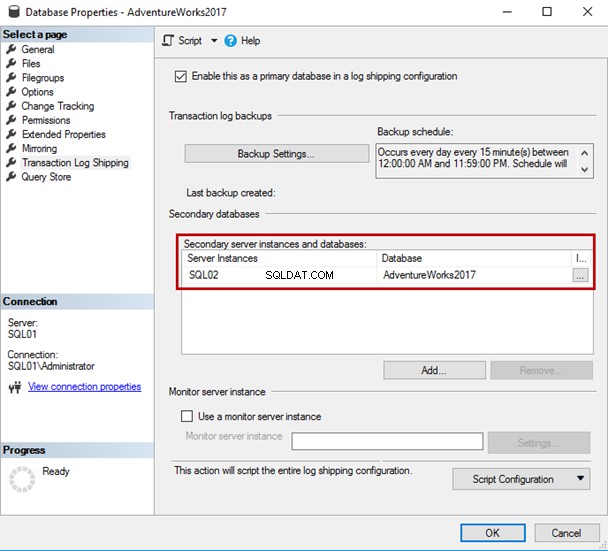
Come puoi vedere, il server secondario e il database sono stati aggiunti in "Istanze del server secondario e griglia dei database ” nelle Proprietà database schermo.
Configura istanza di monitoraggio
Se desideri configurare l'istanza del server di monitoraggio, metti un segno di spunta su Utilizza un'istanza del server di monitoraggio . Per aggiungere l'istanza di monitoraggio, fai clic su Impostazioni .
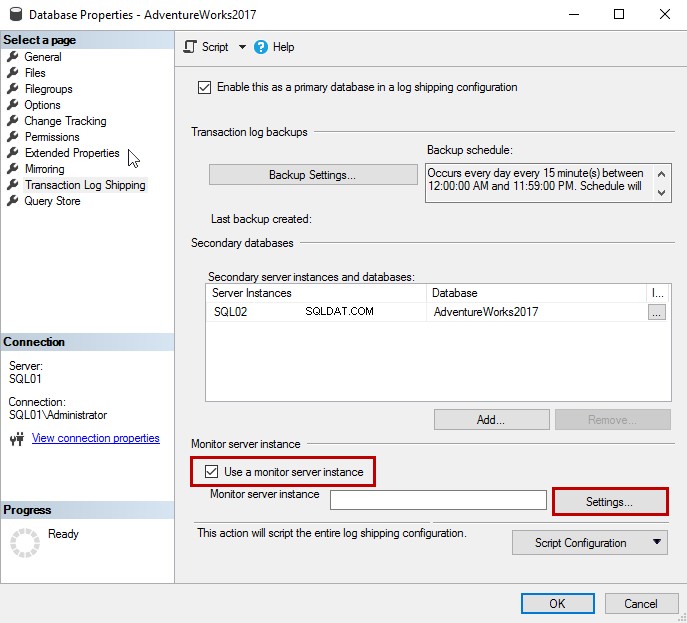
Utilizzeremo l'istanza iscsi\SQL2017 come server di monitoraggio del log shipping.
Nell'Impostazioni monitoraggio spedizione log finestra di dialogo, specifica il nome in Monitoraggio istanza del server casella di testo.
Usiamo il sa account per monitorare la spedizione del registro. Pertanto, è necessario fornire sa come nome utente e password. Puoi anche specificare il periodo di conservazione degli avvisi di monitoraggio e della cronologia.
Qui utilizziamo le impostazioni predefinite. Il nome del processo di avviso è LogShipping_Alert_iscsi\sql2017 .
Fare clic su OK per salvare la configurazione e chiudere la finestra di dialogo.
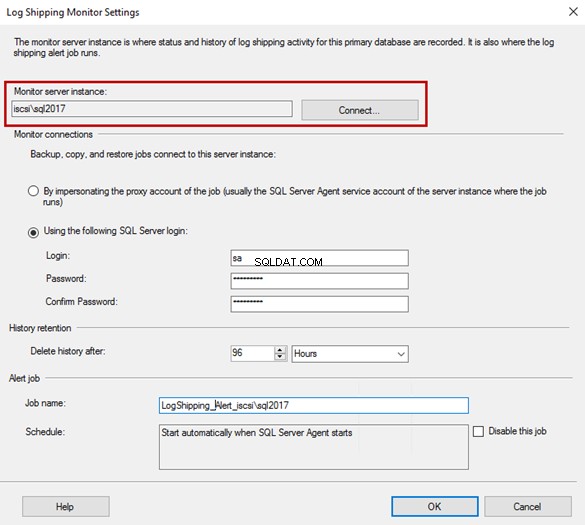
Puoi generare uno script T-SQL per l'intera configurazione facendo clic su Configurazione script pulsante. Copia lo script di configurazione negli appunti o nel file oppure aprilo in una nuova finestra dell'editor di query.
Non vogliamo scrivere l'azione. Puoi ignorare questo passaggio.
Fare clic su OK per salvare la configurazione del log shipping e il processo inizierà:
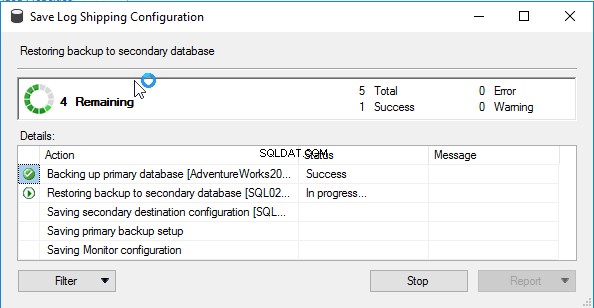
Una volta che la spedizione dei log è stata configurata, puoi vedere la finestra di dialogo di successo:
Testare lo scenario di failover
USE [AdventureWorks2017]
GO
CREATE TABLE [Person](
[BusinessEntityID] [int] NOT NULL,
[PersonType] [nchar](2) NOT NULL,
[NameStyle] [dbo].[NameStyle] NOT NULL,
[Title] [nvarchar](8) NULL,
[FirstName] [dbo].[Name] NOT NULL,
[MiddleName] [dbo].[Name] NULL,
[LastName] [dbo].[Name] NOT NULL,
[Suffix] [nvarchar](10) NULL,
[EmailPromotion] [int] NOT NULL,
[ModifiedDate] [datetime] NOT NULL,
CONSTRAINT [PK_Person_BusinessEntityID] PRIMARY KEY CLUSTERED
(
[BusinessEntityID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GOEseguire la query seguente per inserire i dati demo:
insert into [Person]([BusinessEntityID],[PersonType],[NameStyle],[Title],[FirstName] ,[MiddleName],[LastName] ,[Suffix] ,[EmailPromotion],[ModifiedDate])
select top 10 [BusinessEntityID],[PersonType],[NameStyle],[Title],[FirstName] ,[MiddleName],[LastName] ,[Suffix] ,[EmailPromotion],[ModifiedDate]
from Person.PersonPer eseguire il failover, esegui un backup del registro di coda del database adventureworks2017. Esegui la seguente query:
Backup Log adventureworks2017 to disk='\\domain\LogShippingBackups\Tail_Log_Backup.trn' with norecoveryCollegarsi a SQL02 (server secondario) e ripristinare il backup del log di coda utilizzando RESTORE WITH RECOVERY. Esegui il seguente codice:
RESTORE LOG [AdventureWorks2017] FROM DISK = N'\\domain\LogShippingBackups\Tail_Log_Backup.trn' WITH RECOVERYUna volta ripristinato correttamente il backup del registro di coda, eseguire la query per verificare che i dati siano stati copiati sul server secondario:
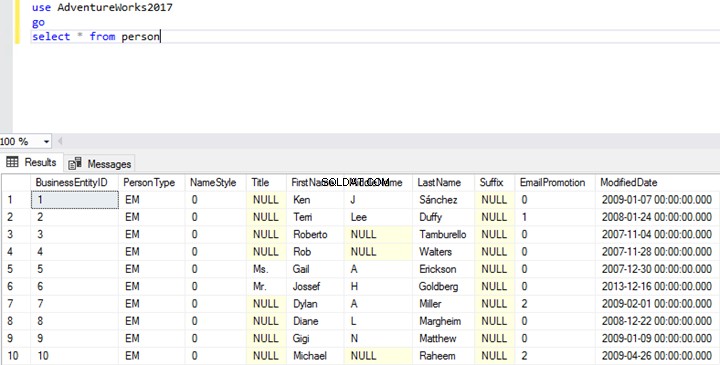
Select * from personRisultato della query:
Come vedi, i dati vengono ripristinati sul server secondario.
Conclusione
In questo articolo abbiamo spiegato il processo di log shipping di SQL Server e come configurarlo. Abbiamo anche dimostrato il processo di failover passo dopo passo del log shipping.