Leggere dalla memoria sarà sempre più performante che andare su disco, quindi per tutte le tecnologie di database dovresti usare quanta più memoria possibile. Se non si è sicuri della configurazione o si verifica un errore, ciò potrebbe generare un utilizzo elevato della memoria o addirittura un problema di memoria insufficiente.
In questo blog, vedremo come controllare l'utilizzo della memoria PostgreSQL e quale parametro dovresti prendere in considerazione per ottimizzarlo. Per questo, iniziamo vedendo una panoramica dell'architettura di PostgreSQL.
Architettura PostgreSQL
L'architettura di PostgreSQL si basa su tre parti fondamentali:Processi, Memoria e Disco.
La memoria può essere classificata in due categorie:
- Memoria locale :viene caricato da ciascun processo di back-end per uso personale per l'elaborazione delle query. È suddiviso in sotto-aree:
- Mem di lavoro:il mem di lavoro viene utilizzato per ordinare le tuple in base alle operazioni ORDER BY e DISTINCT e per unire le tabelle.
- Memoria dei lavori di manutenzione:alcuni tipi di operazioni di manutenzione utilizzano quest'area. Ad esempio, VACUUM, se non stai specificando autovacuum_work_mem.
- Buffer temporanei:viene utilizzato per memorizzare tabelle temporanee.
- Memoria condivisa :Viene allocato dal server PostgreSQL all'avvio e viene utilizzato da tutti i processi. È suddiviso in sotto-aree:
- Pool di buffer condiviso:dove PostgreSQL carica pagine con tabelle e indici dal disco, per lavorare direttamente dalla memoria, riducendo l'accesso al disco.
- Buffer WAL:i dati WAL sono il log delle transazioni in PostgreSQL e contengono le modifiche nel database. Il buffer WAL è l'area in cui i dati WAL vengono archiviati temporaneamente prima di scriverli su disco nei file WAL. Questo viene fatto ogni qualche tempo predefinito chiamato checkpoint. Questo è molto importante per evitare la perdita di informazioni in caso di guasto del server.
- Registro commit:salva lo stato di tutte le transazioni per il controllo della concorrenza.
Come sapere cosa sta succedendo
Se hai un utilizzo elevato della memoria, devi prima confermare quale processo sta generando il consumo.
Utilizzo del comando Linux "Top"
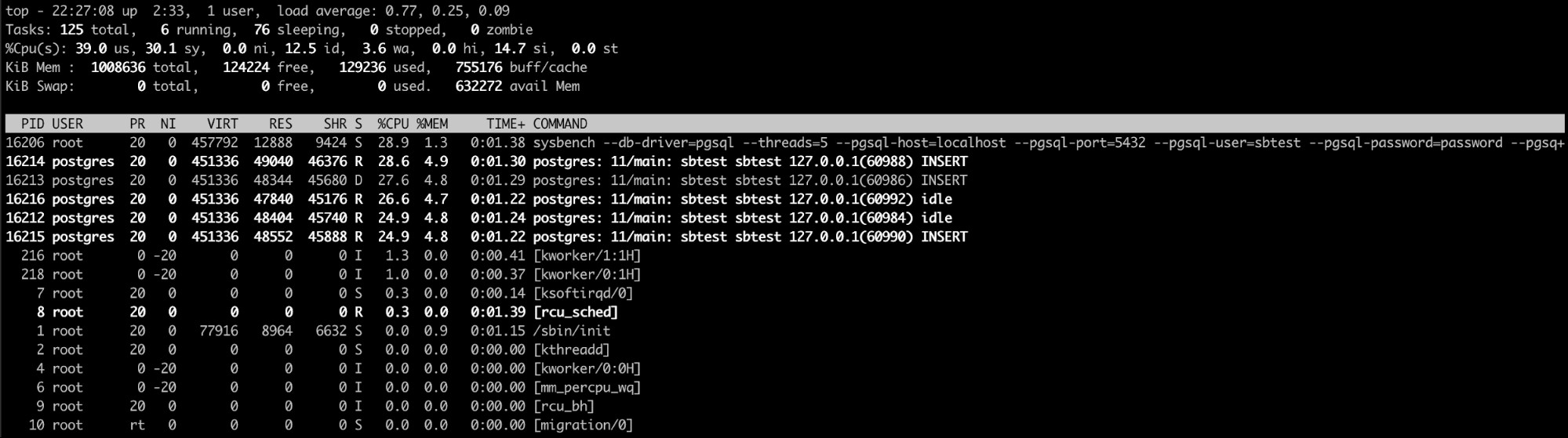
Il comando linux in alto è probabilmente l'opzione migliore qui (o anche un comando simile uno come htop). Con questo comando, puoi vedere il processo/i processi che stanno consumando troppa memoria.
Quando confermi che PostgreSQL è responsabile di questo problema, il passaggio successivo è verificare il motivo.
Utilizzo del registro PostgreSQL
Controllare sia PostgreSQL che i log di sistema è sicuramente un buon modo per avere maggiori informazioni su ciò che sta accadendo nel tuo database/sistema. Potresti vedere messaggi come:
Resource temporarily unavailable
Out of memory: Kill process 1161 (postgres) score 366 or sacrifice childSe non hai abbastanza memoria libera.
O anche più errori di messaggi di database come:
FATAL: password authentication failed for user "username"
ERROR: duplicate key value violates unique constraint "sbtest21_pkey"
ERROR: deadlock detectedQuando si verificano comportamenti imprevisti sul lato database. Quindi, i log sono utili per rilevare questo tipo di problemi e anche di più. Puoi automatizzare questo monitoraggio analizzando i file di registro alla ricerca di opere come "FATAL", "ERROR" o "Kill", in modo da ricevere un avviso quando accade.
Utilizzo di Pg_top
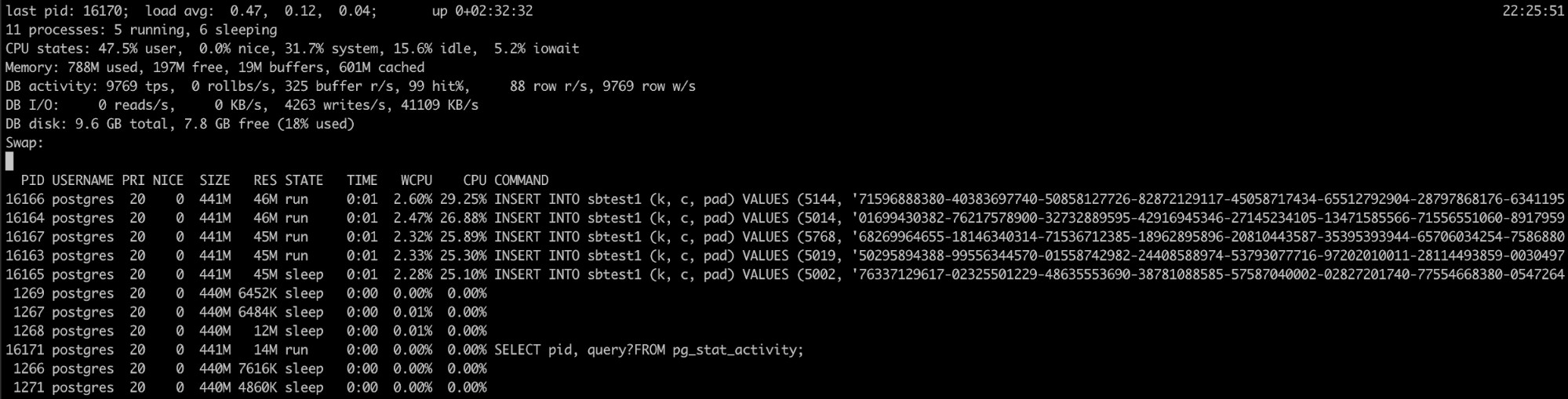
Se sai che il processo PostgreSQL ha un elevato utilizzo della memoria, ma i log non hanno aiutato, hai un altro strumento che può essere utile qui, pg_top.
Questo strumento è simile al principale strumento Linux, ma è specifico per PostgreSQL. Quindi, usandolo, avrai informazioni più dettagliate su ciò che sta eseguendo il tuo database e potrai persino uccidere le query o eseguire un processo di spiegazione se rilevi qualcosa di sbagliato. Puoi trovare maggiori informazioni su questo strumento qui.
Ma cosa succede se non riesci a rilevare alcun errore e il database utilizza ancora molta RAM. Quindi, probabilmente dovrai controllare la configurazione del database.
Quali parametri di configurazione tenere in considerazione
Se tutto sembra a posto ma hai ancora il problema di utilizzo elevato, dovresti controllare la configurazione per confermare se è corretta. Quindi, i seguenti sono parametri che dovresti prendere in considerazione in questo caso.
buffer_condivisi
Questa è la quantità di memoria utilizzata dal server del database per i buffer di memoria condivisa. Se questo valore è troppo basso, il database utilizzerà più disco, il che causerebbe una maggiore lentezza, ma se è troppo alto, potrebbe generare un utilizzo elevato della memoria. Secondo la documentazione, se hai un server di database dedicato con 1 GB o più di RAM, un valore iniziale ragionevole per shared_buffers è il 25% della memoria nel tuo sistema.
work_mem
Specifica la quantità di memoria che verrà utilizzata da ORDER BY, DISTINCT e JOIN prima di scrivere sui file temporanei su disco. Come con shared_buffers, se configuriamo questo parametro su un valore troppo basso, possiamo avere più operazioni in corso sul disco, ma un valore troppo alto è pericoloso per l'utilizzo della memoria. Il valore predefinito è 4 MB.
max_connessioni
Work_mem va anche di pari passo con il valore max_connections, poiché ogni connessione eseguirà queste operazioni contemporaneamente e ogni operazione potrà utilizzare tutta la memoria specificata da questo valore prima di essa inizia a scrivere i dati in file temporanei. Questo parametro determina il numero massimo di connessioni simultanee al nostro database, se configuriamo un numero elevato di connessioni e non teniamo conto di questo, puoi iniziare ad avere problemi di risorse. Il valore predefinito è 100.
temp_buffers
I buffer temporanei vengono utilizzati per memorizzare le tabelle temporanee utilizzate in ogni sessione. Questo parametro imposta la quantità massima di memoria per questa attività. Il valore predefinito è 8 MB.
manutenzione_lavoro_mem
Questa è la memoria massima che può consumare un'operazione come l'aspirazione, l'aggiunta di indici o chiavi esterne. La cosa buona è che è possibile eseguire solo un'operazione di questo tipo in una sessione e non è la cosa più comune eseguirne diverse contemporaneamente nel sistema. Il valore predefinito è 64 MB.
autovacuum_work_mem
Il vuoto usa Maintenance_work_mem per impostazione predefinita, ma possiamo separarlo usando questo parametro. Possiamo specificare la quantità massima di memoria che può essere utilizzata da ciascun lavoratore dell'autovacuum qui.
wal_buffers
La quantità di memoria condivisa utilizzata per i dati WAL che non è stata ancora scritta su disco. L'impostazione predefinita è 3% di shared_buffers, ma non inferiore a 64 kB né superiore alla dimensione di un segmento WAL, in genere 16 MB.
Conclusione
Esistono diversi motivi per avere un utilizzo elevato della memoria e il rilevamento del problema principale potrebbe richiedere molto tempo. In questo blog, abbiamo menzionato diversi modi per controllare l'utilizzo della memoria di PostgreSQL e quale parametro dovresti prendere in considerazione per ottimizzarlo, per evitare un utilizzo eccessivo della memoria.