Introduzione
- Ci sono alcune regole specifiche che devono essere seguite durante la creazione degli oggetti del database. Per migliorare le prestazioni di un database, è necessario assegnare a una tabella una chiave primaria, indici cluster e non cluster e vincoli. Anche se seguiamo tutte queste regole, in una tabella possono comunque verificarsi righe duplicate.
- È sempre buona norma utilizzare le chiavi del database. L'uso delle chiavi del database ridurrà le possibilità di ottenere record duplicati in una tabella. Ma se in una tabella sono già presenti record duplicati, esistono metodi specifici utilizzati per rimuovere questi record duplicati.
Modi per rimuovere le righe duplicate
- Utilizzo di DELETE JOIN istruzione per rimuovere le righe duplicate
L'istruzione DELETE JOIN è fornita in MySQL che aiuta a rimuovere le righe duplicate da una tabella.
Considera un database con il nome "studentdb". Creeremo una tabella studente al suo interno.
mysql> USE studentdb;
Database changed
mysql> CREATE TABLE student (Stud_ID INT, Stud_Name VARCHAR(20), Stud_City VARCHAR(20), Stud_email VARCHAR(255), Stud_Age INT);
Query OK, 0 rows affected (0.15 sec)
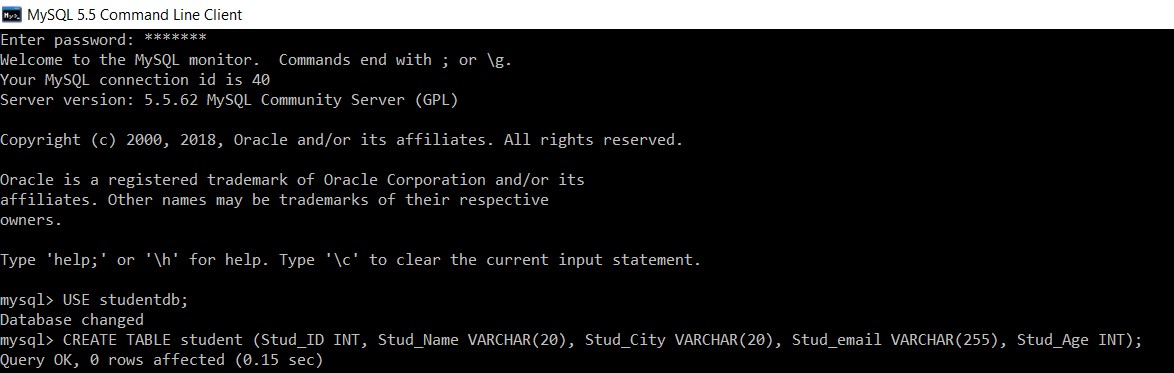
Abbiamo creato con successo una tabella 'student' nel database 'studentdb'.
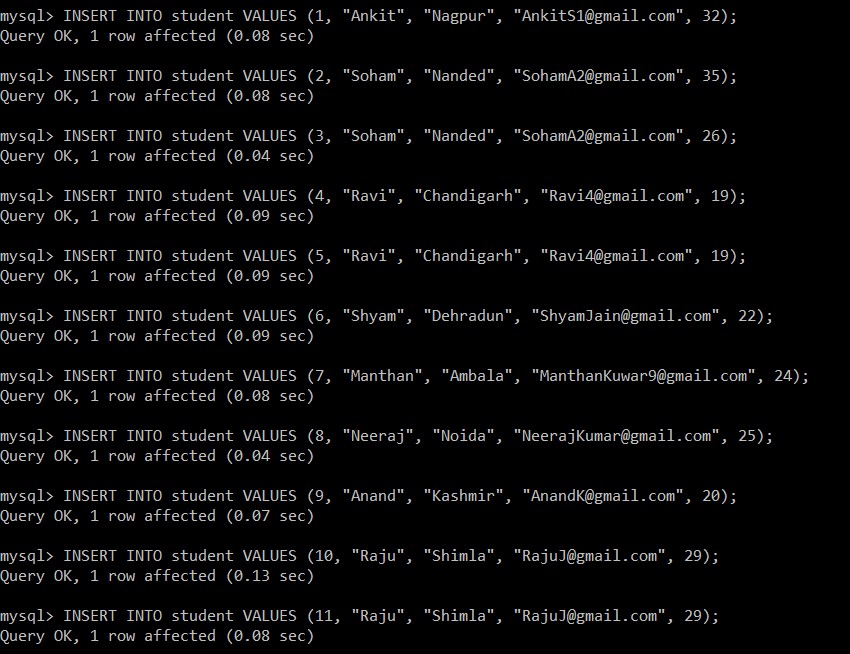
Ora scriveremo le seguenti query per inserire i dati nella tabella degli studenti.
mysql> INSERT INTO student VALUES (1, "Ankit", "Nagpur", "example@sqldat.com", 32);
Query OK, 1 row affected (0.08 sec)
mysql> INSERT INTO student VALUES (2, "Soham", "Nanded", "example@sqldat.com", 35);
Query OK, 1 row affected (0.08 sec)
mysql> INSERT INTO student VALUES (3, "Soham", "Nanded", "example@sqldat.com", 26);
Query OK, 1 row affected (0.04 sec)
mysql> INSERT INTO student VALUES (4, "Ravi", "Chandigarh", "example@sqldat.com", 19);
Query OK, 1 row affected (0.09 sec)
mysql> INSERT INTO student VALUES (5, "Ravi", "Chandigarh", "example@sqldat.com", 19);
Query OK, 1 row affected (0.09 sec)
mysql> INSERT INTO student VALUES (6, "Shyam", "Dehradun", "example@sqldat.com", 22);
Query OK, 1 row affected (0.09 sec)
mysql> INSERT INTO student VALUES (7, "Manthan", "Ambala", "example@sqldat.com", 24);
Query OK, 1 row affected (0.08 sec)
mysql> INSERT INTO student VALUES (8, "Neeraj", "Noida", "example@sqldat.com", 25);
Query OK, 1 row affected (0.04 sec)
mysql> INSERT INTO student VALUES (9, "Anand", "Kashmir", "example@sqldat.com", 20);
Query OK, 1 row affected (0.07 sec)
mysql> INSERT INTO student VALUES (10, "Raju", "Shimla", "example@sqldat.com", 29);
Query OK, 1 row affected (0.13 sec)
mysql> INSERT INTO student VALUES (11, "Raju", "Shimla", "example@sqldat.com", 29);
Query OK, 1 row affected (0.08 sec)
Ora recupereremo tutti i record dalla tabella degli studenti. Prenderemo in considerazione questa tabella e database per tutti i seguenti esempi.
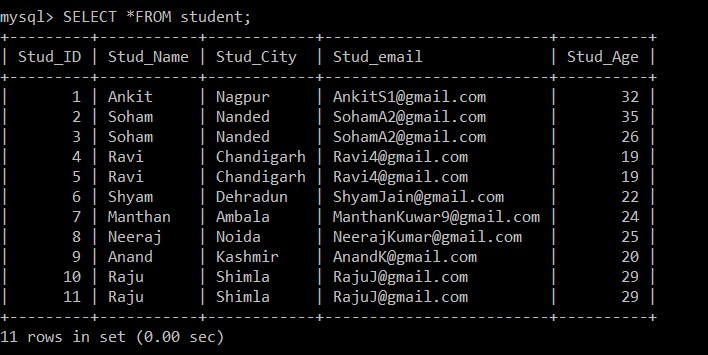
mysql> SELECT *FROM student;
+---------+-----------+------------+-------------------------+----------+
| Stud_ID | Stud_Name | Stud_City | Stud_email | Stud_Age |
+---------+-----------+------------+-------------------------+----------+
| 1 | Ankit | Nagpur | example@sqldat.com | 32 |
| 2 | Soham | Nanded | example@sqldat.com | 35 |
| 3 | Soham | Nanded | example@sqldat.com | 26 |
| 4 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 5 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 6 | Shyam | Dehradun | example@sqldat.com | 22 |
| 7 | Manthan | Ambala | example@sqldat.com | 24 |
| 8 | Neeraj | Noida | example@sqldat.com | 25 |
| 9 | Anand | Kashmir | example@sqldat.com | 20 |
| 10 | Raju | Shimla | example@sqldat.com | 29 |
| 11 | Raju | Shimla | example@sqldat.com | 29 |
+---------+-----------+------------+-------------------------+----------+
11 rows in set (0.00 sec)
Esempio 1:
Scrivi una query per eliminare le righe duplicate dalla tabella degli studenti utilizzando DELETE JOIN dichiarazione.
mysql> DELETE s1 FROM student s1 INNER JOIN student s2 WHERE s1.Stud_ID < s2.Stud_ID AND s1.Stud_email = s2.Stud_email;Abbiamo utilizzato la query DELETE con INNER JOIN. Per implementare l'INNER JOIN su una singola tabella, abbiamo creato due istanze s1 e s2. Quindi, con l'aiuto della clausola WHERE, abbiamo verificato due condizioni per scoprire le righe duplicate nella tabella dello studente. Se l'ID e-mail in due record diversi è lo stesso e l'ID studente è diverso, verrà trattato come un record duplicato in base alla condizione della clausola WHERE.
Risultato:
Query OK, 3 rows affected (0.20 sec)I risultati della query precedente mostrano che sono presenti tre record duplicati nella tabella dello studente.

Utilizzeremo la query SELECT per trovare i record duplicati che sono stati eliminati.
mysql> SELECT *FROM student;
+---------+-----------+------------+-------------------------+----------+
| Stud_ID | Stud_Name | Stud_City | Stud_email | Stud_Age |
+---------+-----------+------------+-------------------------+----------+
| 1 | Ankit | Nagpur | example@sqldat.com | 32 |
| 3 | Soham | Nanded | example@sqldat.com | 26 |
| 5 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 6 | Shyam | Dehradun | example@sqldat.com | 22 |
| 7 | Manthan | Ambala | example@sqldat.com | 24 |
| 8 | Neeraj | Noida | example@sqldat.com | 25 |
| 9 | Anand | Kashmir | example@sqldat.com | 20 |
| 11 | Raju | Shimla | example@sqldat.com | 29 |
+---------+-----------+------------+-------------------------+----------+
8 rows in set (0.00 sec)
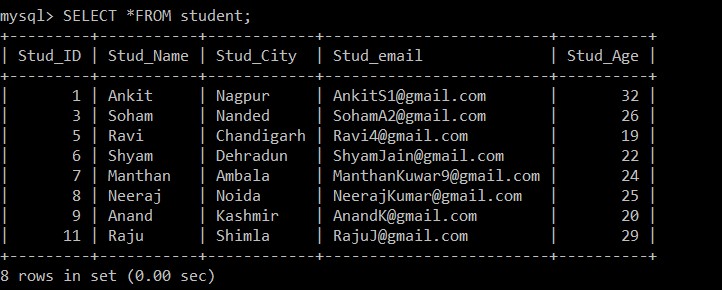
Ora, ci sono solo 8 record che sono presenti nella tabella degli studenti poiché i tre record duplicati vengono eliminati dalla tabella attualmente selezionata. Secondo la seguente condizione:
s1.Stud_ID < s2.Stud_ID AND s1.Stud_email = s2.Stud_email;Se gli ID e-mail di due record qualsiasi sono gli stessi, poiché viene utilizzato il segno minore di tra l'ID studente, verrà conservato solo il record con ID dipendente maggiore e l'altro record duplicato verrà eliminato tra i due record.
Esempio 2:
Scrivi una query per eliminare le righe duplicate dalla tabella degli studenti utilizzando l'istruzione delete join mantenendo il record duplicato con un ID dipendente minore ed eliminando l'altro.
mysql> DELETE s1 FROM student s1 INNER JOIN student s2 WHERE s1.Stud_ID > s2.Stud_ID AND s1.Stud_email = s2.Stud_email;Abbiamo utilizzato la query DELETE con INNER JOIN. Per implementare l'INNER JOIN su una singola tabella, abbiamo creato due istanze s1 e s2. Quindi, con l'aiuto della clausola WHERE, abbiamo verificato due condizioni per scoprire le righe duplicate nella tabella dello studente. Se l'ID e-mail presente in due record diversi è lo stesso e l'ID studente è diverso, verrà trattato come un record duplicato in base alla condizione della clausola WHERE.
Risultato:
Query OK, 3 rows affected (0.09 sec)I risultati della query precedente mostrano che sono presenti tre record duplicati nella tabella dello studente.

Utilizzeremo la query SELECT per trovare i record duplicati che sono stati eliminati.
mysql> SELECT *FROM student;
+---------+-----------+------------+-------------------------+----------+
| Stud_ID | Stud_Name | Stud_City | Stud_email | Stud_Age |
+---------+-----------+------------+-------------------------+----------+
| 1 | Ankit | Nagpur | example@sqldat.com | 32 |
| 2 | Soham | Nanded | example@sqldat.com | 35 |
| 4 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 6 | Shyam | Dehradun | example@sqldat.com | 22 |
| 7 | Manthan | Ambala | example@sqldat.com | 24 |
| 8 | Neeraj | Noida | example@sqldat.com | 25 |
| 9 | Anand | Kashmir | example@sqldat.com | 20 |
| 10 | Raju | Shimla | example@sqldat.com | 29 |
+---------+-----------+------------+-------------------------+----------+
8 rows in set (0.00 sec)
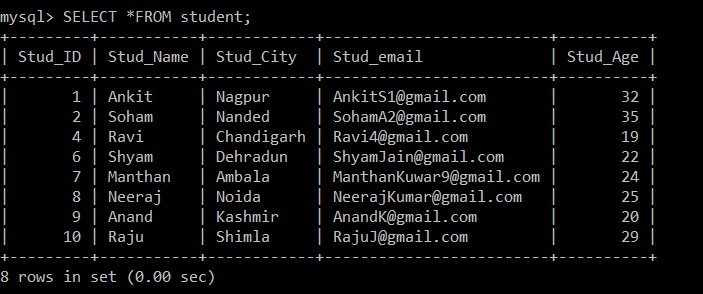
Ora, ci sono solo 8 record che sono presenti nella tabella degli studenti poiché i tre record duplicati vengono eliminati dalla tabella attualmente selezionata. Secondo la seguente condizione:
s1.Stud_ID > s2.Stud_ID AND s1.Stud_email = s2.Stud_email;Se gli ID e-mail di due record qualsiasi sono gli stessi poiché viene utilizzato il segno maggiore di tra l'ID studente, verrà conservato solo il record con l'ID dipendente inferiore e l'altro record duplicato verrà eliminato tra i due record.
- Utilizzo di una tabella intermedia per rimuovere le righe duplicate
È necessario seguire i seguenti passaggi durante la rimozione delle righe duplicate con l'aiuto di una tabella intermedia.
- Dovrebbe essere creata una nuova tabella, che sarà la stessa della tabella effettiva.
- Aggiungi righe distinte dalla tabella effettiva alla tabella appena creata.
- Rilascia la tabella attuale e rinomina la nuova tabella con lo stesso nome di una tabella reale.
Esempio:
Scrivi una query per eliminare i record duplicati dalla tabella studenti utilizzando una tabella intermedia.
Passaggio 1:
In primo luogo, creeremo una tabella intermedia che sarà la stessa della tabella dei dipendenti.
mysql> CREATE TABLE temp_student LIKE student;
Query OK, 0 rows affected (0.14 sec)

Qui, 'employee' è la tabella originale e 'temp_student' è la tabella intermedia.
Passaggio 2:
Ora recupereremo solo i record univoci dalla tabella degli studenti e inseriremo tutti i record recuperati nella tabella temp_student.
mysql> INSERT INTO temp_student SELECT *FROM student GROUP BY Stud_email;
Query OK, 8 rows affected (0.12 sec)
Records: 8 Duplicates: 0 Warnings: 0

Qui, prima di inserire i record distinti dalla tabella studente in temp_student, tutti i record duplicati vengono filtrati da Stud_email. Quindi, solo i record con ID email univoco sono stati inseriti in temp_student.
Passaggio 3:
Quindi, rimuoveremo la tabella degli studenti e rinomineremo la tabella temp_student nella tabella degli studenti.
mysql> DROP TABLE student;
Query OK, 0 rows affected (0.08 sec)
mysql> ALTER TABLE temp_student RENAME TO student;
Query OK, 0 rows affected (0.08 sec)
La tabella degli studenti viene rimossa correttamente e temp_student viene rinominata nella tabella degli studenti, che contiene solo i record univoci.
Quindi, dobbiamo verificare che la tabella studente ora contenga solo i record univoci. Per verificarlo, abbiamo utilizzato la query SELECT per visualizzare i dati contenuti nella tabella studenti.
mysql> SELECT *FROM student;Risultato:
+---------+-----------+------------+-------------------------+----------+
| Stud_ID | Stud_Name | Stud_City | Stud_email | Stud_Age |
+---------+-----------+------------+-------------------------+----------+
| 9 | Anand | Kashmir | example@sqldat.com | 20 |
| 1 | Ankit | Nagpur | example@sqldat.com | 32 |
| 7 | Manthan | Ambala | example@sqldat.com | 24 |
| 8 | Neeraj | Noida | example@sqldat.com | 25 |
| 10 | Raju | Shimla | example@sqldat.com | 29 |
| 4 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 6 | Shyam | Dehradun | example@sqldat.com | 22 |
| 2 | Soham | Nanded | example@sqldat.com | 35 |
+---------+-----------+------------+-------------------------+----------+
8 rows in set (0.00 sec)
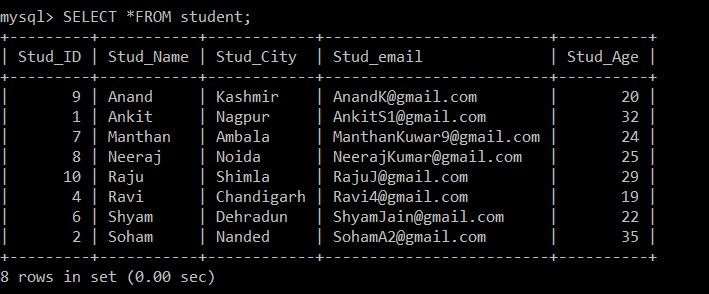
Ora, ci sono solo 8 record che sono presenti nella tabella degli studenti poiché i tre record duplicati vengono eliminati dalla tabella attualmente selezionata. Nel passaggio 2, durante il recupero dei record distinti dalla tabella originale e l'inserimento in una tabella intermedia, è stata utilizzata una clausola GROUP BY su Stud_email, quindi tutti i record sono stati inseriti in base agli ID e-mail degli studenti. Qui, per impostazione predefinita, solo il record con un ID dipendente inferiore viene mantenuto tra i record duplicati e l'altro viene eliminato.