Il partizionamento delle tabelle in SQL Server è essenzialmente un modo per far sembrare più tabelle fisiche (set di righe) come un'unica tabella. Questa astrazione viene eseguita interamente dal Query Processor, un design che semplifica le cose per gli utenti, ma che richiede complesse esigenze di Query Optimizer. Questo post esamina due esempi che superano le capacità dell'ottimizzatore in SQL Server 2008 in poi.
Unisciti alle questioni relative all'ordine delle colonne
Questo primo esempio mostra come l'ordine testuale di ON le condizioni della clausola possono influire sul piano di query prodotto durante l'unione di tabelle partizionate. Per cominciare, abbiamo bisogno di uno schema di partizionamento, una funzione di partizionamento e due tabelle:
CREATE PARTITION FUNCTION PF (integer)
AS RANGE RIGHT
FOR VALUES
(
10000, 20000, 30000, 40000, 50000,
60000, 70000, 80000, 90000, 100000,
110000, 120000, 130000, 140000, 150000
);
CREATE PARTITION SCHEME PS
AS PARTITION PF
ALL TO ([PRIMARY]);
GO
CREATE TABLE dbo.T1
(
c1 integer NOT NULL,
c2 integer NOT NULL,
c3 integer NOT NULL,
CONSTRAINT PK_T1
PRIMARY KEY CLUSTERED (c1, c2, c3)
ON PS (c1)
);
CREATE TABLE dbo.T2
(
c1 integer NOT NULL,
c2 integer NOT NULL,
c3 integer NOT NULL,
CONSTRAINT PK_T2
PRIMARY KEY CLUSTERED (c1, c2, c3)
ON PS (c1)
); Successivamente, carichiamo entrambe le tabelle con 150.000 righe. I dati non contano molto; questo esempio utilizza una tabella di numeri standard contenente tutti i valori interi da 1 a 150.000 come origine dati. Entrambe le tabelle vengono caricate con gli stessi dati.
INSERT dbo.T1 WITH (TABLOCKX)
(c1, c2, c3)
SELECT
N.n * 1,
N.n * 2,
N.n * 3
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 150000;
INSERT dbo.T2 WITH (TABLOCKX)
(c1, c2, c3)
SELECT
N.n * 1,
N.n * 2,
N.n * 3
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 150000;
La nostra query di test esegue un semplice inner join di queste due tabelle. Anche in questo caso, la query non è importante o intesa per essere particolarmente realistica, viene utilizzata per dimostrare uno strano effetto quando si uniscono tabelle partizionate. La prima forma della query utilizza un ON clausola scritta nell'ordine delle colonne c3, c2, c1:
SELECT *
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON t1.c3 = t2.c3
AND t1.c2 = t2.c2
AND t1.c1 = t2.c1; Il piano di esecuzione prodotto per questa query (su SQL Server 2008 e versioni successive) prevede un hash join parallelo, con un costo stimato di 2,6953 :
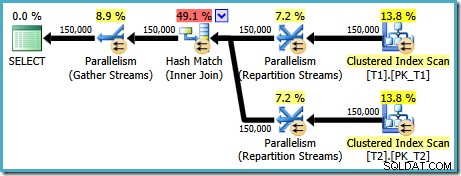
Questo è un po' inaspettato. Entrambe le tabelle hanno un indice cluster nell'ordine (c1, c2, c3), partizionato per c1, quindi ci si aspetterebbe un join di unione, sfruttando l'ordine dell'indice. Proviamo a scrivere ON clausola nell'ordine (c1, c2, c3) invece:
SELECT *
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON t1.c1 = t2.c1
AND t1.c2 = t2.c2
AND t1.c3 = t2.c3; Il piano di esecuzione ora utilizza il merge join previsto, con un costo stimato di 1,64119 (in calo da 2,6953 ). L'ottimizzatore decide anche che non vale la pena usare l'esecuzione parallela:
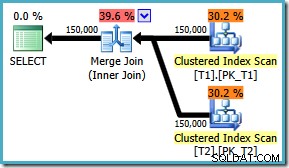
Notando che il piano di merge join è chiaramente più efficiente, possiamo tentare di forzare un merge join per l'originale ON ordine delle clausole utilizzando un suggerimento per la query:
SELECT *
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON t1.c3 = t2.c3
AND t1.c2 = t2.c2
AND t1.c1 = t2.c1
OPTION (MERGE JOIN); Il piano risultante utilizza un merge join come richiesto, ma presenta anche gli ordinamenti su entrambi gli input e torna a utilizzare il parallelismo. Il costo stimato di questo piano è un enorme 8,71063 :
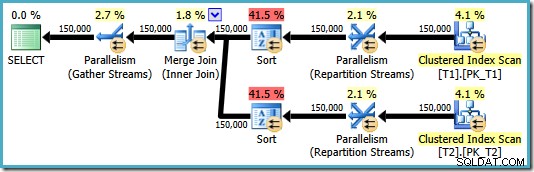
Entrambi gli operatori di ordinamento hanno le stesse proprietà:
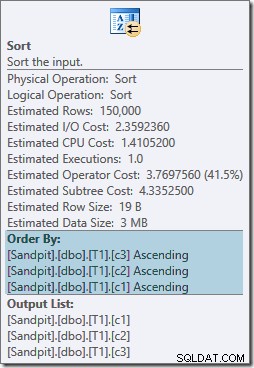
L'ottimizzatore pensa che il merge join necessiti che i suoi input siano ordinati nel rigoroso ordine scritto di ON clausola, introducendo di conseguenza ordinamenti espliciti. L'ottimizzatore è consapevole del fatto che un merge join richiede che i suoi input siano ordinati allo stesso modo, ma sa anche che l'ordine delle colonne non ha importanza. Unisci join su (c1, c2, c3) è ugualmente felice con gli input ordinati su (c3, c2, c1) così come con gli input ordinati su (c2, c1, c3) o qualsiasi altra combinazione.
Sfortunatamente, questo ragionamento viene interrotto in Query Optimizer quando è coinvolto il partizionamento. Questo è un bug dell'ottimizzatore che è stato corretto in SQL Server 2008 R2 e versioni successive, sebbene il flag di traccia 4199 è necessario per attivare la correzione:
SELECT *
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON t1.c3 = t2.c3
AND t1.c2 = t2.c2
AND t1.c1 = t2.c1
OPTION (QUERYTRACEON 4199);
Normalmente abiliti questo flag di traccia usando DBCC TRACEON o come opzione di avvio, perché QUERYTRACEON hint non è documentato per l'uso con 4199. Il flag di traccia è richiesto in SQL Server 2008 R2, SQL Server 2012 e SQL Server 2014 CTP1.
Ad ogni modo, indipendentemente da come è abilitato il flag, la query ora produce l'unione di unione ottimale qualunque sia il ON ordinamento delle clausole:
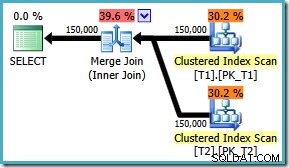
Non esiste nessuna correzione per SQL Server 2008 , la soluzione alternativa è scrivere ON clausola nell'ordine "giusto"! Se incontri una query come questa su SQL Server 2008, prova a forzare un merge join e guarda gli ordinamenti per determinare il modo "corretto" per scrivere il ON della tua query clausola.
Questo problema non si verifica in SQL Server 2005 perché quella versione ha implementato query partizionate utilizzando APPLY modello:

Il piano di query di SQL Server 2005 unisce una partizione di ogni tabella alla volta, utilizzando una tabella in memoria (la scansione costante) contenente i numeri di partizione da elaborare. Ogni partizione viene unita separatamente sul lato interno del join e l'ottimizzatore 2005 è abbastanza intelligente da vedere che ON l'ordine delle colonne delle clausole non ha importanza.
Questo ultimo piano è un esempio di unione di unione collocata , una funzionalità che è stata persa durante il passaggio da SQL Server 2005 alla nuova implementazione del partizionamento in SQL Server 2008. Un suggerimento su Connect per ripristinare i join di unione collocati è stato chiuso perché non risolverà.
Raggruppa in base agli ordini
La seconda particolarità che voglio esaminare segue un tema simile, ma riguarda l'ordine delle colonne in un GROUP BY clausola anziché ON clausola di inner join. Avremo bisogno di una nuova tabella per dimostrare:
CREATE TABLE dbo.T3
(
RowID integer IDENTITY NOT NULL,
UserID integer NOT NULL,
SessionID integer NOT NULL,
LocationID integer NOT NULL,
CONSTRAINT PK_T3
PRIMARY KEY CLUSTERED (RowID)
ON PS (RowID)
);
INSERT dbo.T3 WITH (TABLOCKX)
(UserID, SessionID, LocationID)
SELECT
ABS(CHECKSUM(NEWID())) % 50,
ABS(CHECKSUM(NEWID())) % 30,
ABS(CHECKSUM(NEWID())) % 10
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 150000; La tabella ha un indice non cluster allineato, dove "aligned" significa semplicemente che è partizionato allo stesso modo dell'indice cluster (o heap):
CREATE NONCLUSTERED INDEX nc1 ON dbo.T3 (UserID, SessionID, LocationID) ON PS (RowID);
La nostra query di test raggruppa i dati nelle tre colonne dell'indice non cluster e restituisce un conteggio per ogni gruppo:
SELECT LocationID, UserID, SessionID, COUNT_BIG(*) FROM dbo.T3 GROUP BY LocationID, UserID, SessionID;
Il piano di query esegue la scansione dell'indice non cluster e utilizza un aggregato di corrispondenza hash per contare le righe in ogni gruppo:
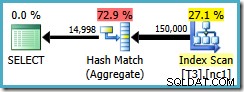
Ci sono due problemi con Hash Aggregate:
- È un operatore di blocco. Nessuna riga viene restituita al client finché tutte le righe non sono state aggregate.
- Richiede una concessione di memoria per contenere la tabella hash.
In molti scenari del mondo reale, preferiremmo uno Stream Aggregate qui perché quell'operatore blocca solo per gruppo e non richiede una concessione di memoria. Utilizzando questa opzione, l'applicazione client inizierà a ricevere i dati prima, non dovrebbe attendere che venga concessa la memoria e SQL Server può utilizzare la memoria per altri scopi.
Possiamo richiedere a Query Optimizer di utilizzare uno Stream Aggregate per questa query aggiungendo un OPTION (ORDER GROUP) suggerimento per la query. Ciò si traduce nel seguente piano di esecuzione:

L'operatore Sort blocca completamente e richiede anche una concessione di memoria, quindi questo piano sembra essere peggiore del semplice utilizzo di un aggregato hash. Ma perché è necessario il tipo? Le proprietà mostrano che le righe vengono ordinate nell'ordine specificato dal nostro GROUP BY clausola:
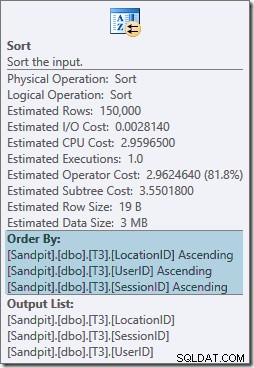
Questo ordinamento è previsto poiché l'allineamento alla partizione dell'indice (in SQL Server 2008 in poi) significa che il numero di partizione viene aggiunto come colonna iniziale dell'indice. In effetti, le chiavi di indice non cluster sono (partizione, utente, sessione, posizione) dovute al partizionamento. Le righe nell'indice sono ancora ordinate per utente, sessione e posizione, ma solo all'interno di ciascuna partizione.
Se limitiamo la query a una singola partizione, l'ottimizzatore dovrebbe essere in grado di utilizzare l'indice per alimentare uno Stream Aggregate senza eseguire l'ordinamento. Nel caso in cui ciò richieda qualche spiegazione, specificare una singola partizione significa che il piano di query può eliminare tutte le altre partizioni dalla scansione dell'indice non cluster, risultando in un flusso di righe ordinato per (utente, sessione, posizione).
Possiamo ottenere questa eliminazione della partizione in modo esplicito usando il $PARTITION funzione:
SELECT LocationID, UserID, SessionID, COUNT_BIG(*) FROM dbo.T3 WHERE $PARTITION.PF(RowID) = 1 GROUP BY LocationID, UserID, SessionID;
Sfortunatamente, questa query utilizza ancora un aggregato hash, con un costo del piano stimato di 0,287878 :
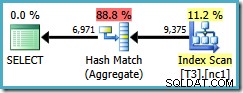
La scansione ora riguarda solo una partizione, ma l'ordinamento (utente, sessione, posizione) non ha aiutato l'ottimizzatore a utilizzare un aggregato di flusso. Potresti obiettare che (utente, sessione, posizione) l'ordine non è utile perché il GROUP BY è (posizione, utente, sessione), ma l'ordine delle chiavi non ha importanza per un'operazione di raggruppamento.
Aggiungiamo un ORDER BY clausola nell'ordine delle chiavi dell'indice per dimostrare il punto:
SELECT LocationID, UserID, SessionID, COUNT_BIG(*) FROM dbo.T3 WHERE $PARTITION.PF(RowID) = 1 GROUP BY LocationID, UserID, SessionID ORDER BY UserID, SessionID, LocationID;
Si noti che il ORDER BY La clausola corrisponde all'ordine della chiave dell'indice non cluster, sebbene GROUP BY clausola no. Il piano di esecuzione per questa query è:
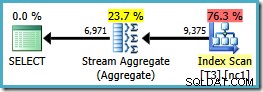
Ora abbiamo lo Stream Aggregate che cercavamo, con un costo del piano stimato di 0,0423925 (rispetto a 0,287878 per il piano Hash Aggregate – quasi 7 volte di più).
L'altro modo per ottenere uno Stream Aggregate qui è riordinare il GROUP BY colonne in modo che corrispondano alle chiavi di indice non cluster:
SELECT LocationID, UserID, SessionID, COUNT_BIG(*) FROM dbo.T3 AS T1 WHERE $PARTITION.PF(RowID) = 1 GROUP BY UserID, SessionID, LocationID;
Questa query produce lo stesso piano Stream Aggregate mostrato immediatamente sopra, con esattamente lo stesso costo. Questa sensibilità a GROUP BY l'ordine delle colonne è specifico per le query di tabelle partizionate in SQL Server 2008 e versioni successive.
Potresti riconoscere che la causa principale del problema qui è simile al caso precedente che coinvolgeva un Merge Join. Sia Merge Join che Stream Aggregate richiedono l'input ordinato in base alle chiavi di join o aggregazione, ma nessuno dei due si preoccupa dell'ordine di tali chiavi. Un Merge Join su (x, y, z) è altrettanto felice di ricevere righe ordinate per (y, z, x) o (z, y, x) e lo stesso vale per Stream Aggregate.
Questa limitazione dell'ottimizzatore si applica anche a DISTINCT nelle stesse circostanze. La query seguente genera un piano Hash Aggregate con un costo stimato di 0,286539 :
SELECT DISTINCT LocationID, UserID, SessionID FROM dbo.T3 AS T1 WHERE $PARTITION.PF(RowID) = 1;
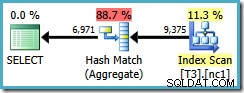
Se scriviamo il DISTINCT colonne nell'ordine delle chiavi di indice non cluster...
SELECT DISTINCT UserID, SessionID, LocationID FROM dbo.T3 AS T1 WHERE $PARTITION.PF(RowID) = 1;
… siamo ricompensati con un piano Stream Aggregate con un costo di 0,041455 :

Per riassumere, si tratta di una limitazione di Query Optimizer in SQL Server 2008 e versioni successive (incluso SQL Server 2014 CTP 1) che non viene risolta utilizzando il flag di traccia 4199 come nel caso dell'esempio Merge Join. Il problema si verifica solo con le tabelle partizionate con un GROUP BY o DISTINCT su tre o più colonne utilizzando un indice partizionato allineato, in cui viene elaborata una singola partizione.
Come con l'esempio Merge Join, questo rappresenta un passo indietro rispetto al comportamento di SQL Server 2005. SQL Server 2005 non ha aggiunto una chiave iniziale implicita agli indici partizionati, utilizzando un APPLY tecnica invece. In SQL Server 2005, tutte le query presentate qui utilizzano $PARTITION per specificare un risultato di singola partizione nei piani di query che esegue l'eliminazione della partizione e utilizza Stream Aggregates senza riordinare il testo della query.
Le modifiche all'elaborazione delle tabelle partizionate in SQL Server 2008 hanno migliorato le prestazioni in diverse aree importanti, principalmente correlate all'elaborazione parallela efficiente delle partizioni. Sfortunatamente, queste modifiche hanno avuto effetti collaterali che non sono stati tutti risolti nelle versioni successive.