Le modifiche alla rappresentazione interna delle tabelle partizionate tra SQL Server 2005 e SQL Server 2008 hanno comportato un miglioramento dei piani di query e delle prestazioni nella maggior parte dei casi (soprattutto quando è coinvolta l'esecuzione parallela). Sfortunatamente, le stesse modifiche hanno fatto sì che alcune cose che funzionavano bene in SQL Server 2005 improvvisamente non funzionassero così bene in SQL Server 2008 e versioni successive. Questo post esamina un esempio in cui Query Optimizer di SQL Server 2005 ha prodotto un piano di esecuzione superiore rispetto alle versioni successive.
Tabella e dati campione
Gli esempi in questo post utilizzano la tabella e i dati partizionati seguenti:
CREATE PARTITION FUNCTION PF (integer)
AS RANGE RIGHT
FOR VALUES
(
10000, 20000, 30000, 40000, 50000,
60000, 70000, 80000, 90000, 100000,
110000, 120000, 130000, 140000, 150000
);
CREATE PARTITION SCHEME PS
AS PARTITION PF
ALL TO ([PRIMARY]);
GO
CREATE TABLE dbo.T4
(
RowID integer IDENTITY NOT NULL,
SomeData integer NOT NULL,
CONSTRAINT PK_T4
PRIMARY KEY CLUSTERED (RowID)
ON PS (RowID)
);
INSERT dbo.T4 WITH (TABLOCKX)
(SomeData)
SELECT
ABS(CHECKSUM(NEWID()))
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 150000;
CREATE NONCLUSTERED INDEX nc1
ON dbo.T4 (SomeData)
ON PS (RowID); Layout dati partizionato
La nostra tabella ha un indice cluster partizionato. In questo caso, la chiave di clustering funge anche da chiave di partizionamento (sebbene questo non sia un requisito, in generale). Il partizionamento genera unità di archiviazione fisiche separate (set di righe) che il Query Processor presenta agli utenti come un'unica entità.
Il diagramma seguente mostra le prime tre partizioni della nostra tabella (clicca per ingrandire):
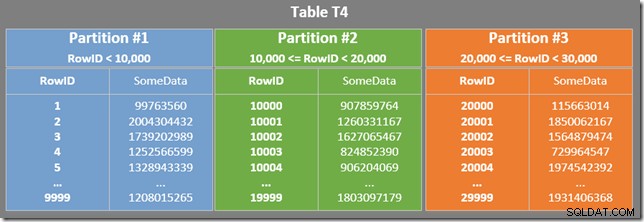
L'indice non cluster è partizionato allo stesso modo (è "allineato"):

Ogni partizione dell'indice non cluster copre un intervallo di valori RowID. All'interno di ogni partizione, i dati vengono ordinati da SomeData (ma i valori RowID non verranno ordinati in generale).
Il problema MIN/MAX
È ragionevolmente noto che MIN e MAX gli aggregati non si ottimizzano bene sulle tabelle partizionate (a meno che la colonna da aggregare non sia anche la colonna di partizionamento). Questa limitazione (che esiste ancora in SQL Server 2014 CTP 1) è stata scritta molte volte nel corso degli anni; la mia copertura preferita è in questo articolo di Itzik Ben-Gan. Per illustrare brevemente il problema, considera la seguente query:
SELECT MIN(SomeData) FROM dbo.T4;
Il piano di esecuzione su SQL Server 2008 o versioni successive è il seguente:

Questo piano legge tutte le 150.000 righe dall'indice e uno Stream Aggregate calcola il valore minimo (il piano di esecuzione è essenzialmente lo stesso se richiediamo invece il valore massimo). Il piano di esecuzione di SQL Server 2005 è leggermente diverso (anche se non migliore):
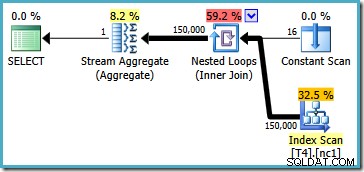
Questo piano esegue l'iterazione sui numeri di partizione (elencati nella scansione costante) eseguendo la scansione completa di una partizione alla volta. Alla fine, tutte le 150.000 righe vengono ancora lette ed elaborate dallo Stream Aggregate.
Guarda indietro alla tabella partizionata e ai diagrammi dell'indice e pensa a come la query potrebbe essere elaborata in modo più efficiente sul nostro set di dati. L'indice non cluster sembra una buona scelta per risolvere la query perché contiene valori SomeData in un ordine che potrebbe essere sfruttato durante il calcolo dell'aggregato.
Ora, il fatto che l'indice sia partizionato complica un po' le cose:ogni partizione dell'indice è ordinato dalla colonna SomeData, ma non possiamo semplicemente leggere il valore più basso da un particolare partizione per ottenere la risposta corretta all'intera query.
Una volta compresa la natura essenziale del problema, un essere umano può vedere che una strategia efficiente sarebbe quella di trovare il singolo valore più basso di SomeData in ogni partizione dell'indice, quindi prendi il valore più basso dai risultati per partizione.
Questa è essenzialmente la soluzione alternativa che Itzik presenta nel suo articolo; riscrivi la query per calcolare un aggregato per partizione (usando APPLY sintassi) e quindi aggregare nuovamente su quei risultati per partizione. Usando questo approccio, il riscritto MIN query produce questo piano di esecuzione (vedi l'articolo di Itzik per la sintassi esatta):
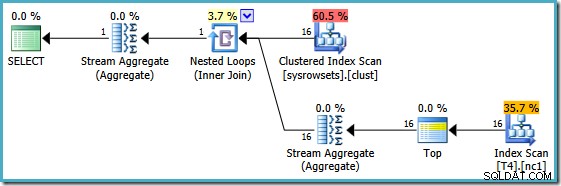
Questo piano legge i numeri di partizione da una tabella di sistema e recupera il valore più basso di SomeData in ciascuna partizione. Lo Stream Aggregate finale calcola solo il minimo sui risultati per partizione.
La caratteristica importante di questo piano è che legge una unica riga da ciascuna partizione (sfruttando l'ordinamento dell'indice all'interno di ciascuna partizione). È molto più efficiente del piano dell'ottimizzatore che ha elaborato tutte le 150.000 righe della tabella.
MIN e MAX all'interno di una singola partizione
Considerare ora la query seguente per trovare il valore minimo nella colonna SomeData, per un intervallo di valori RowID contenuti all'interno di una singola partizione :
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID < 18000;
Abbiamo visto che l'ottimizzatore ha problemi con MIN e MAX su più partizioni, ma ci si aspetterebbe che tali limitazioni non si applichino a una singola query di partizione.
La singola partizione è quella delimitata dai valori RowID 10.000 e 20.000 (fare riferimento alla definizione della funzione di partizionamento). La funzione di partizionamento è stata definita come RANGE RIGHT , quindi il valore limite 10.000 appartiene alla partizione n. 2 e il limite 20.000 appartiene alla partizione n. 3. L'intervallo di valori RowID specificato dalla nostra nuova query è quindi contenuto nella sola partizione 2.
I piani di esecuzione grafica per questa query sono gli stessi su tutte le versioni di SQL Server dal 2005 in poi:
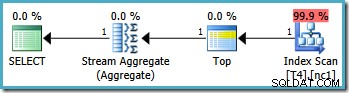
Analisi del piano
L'ottimizzatore ha preso l'intervallo RowID specificato in WHERE clausola e confrontato con la definizione della funzione di partizione per determinare che era necessario accedere solo alla partizione 2 dell'indice non cluster. Le proprietà del piano di SQL Server 2005 per la scansione dell'indice mostrano chiaramente l'accesso a partizione singola:
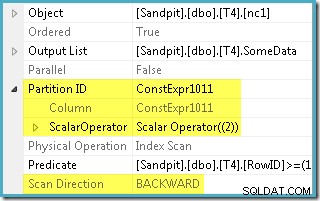
L'altra proprietà evidenziata è la direzione di scansione. L'ordine della scansione varia a seconda che la query stia cercando il valore SomeData minimo o massimo. L'indice non cluster è ordinato (per partizione, ricorda) in base ai valori SomeData crescenti, quindi la direzione di scansione dell'indice è FORWARD se la query richiede il valore minimo e BACKWARD se è necessario il valore massimo (la schermata sopra è stata presa dal MAX piano di query).
C'è anche un predicato residuo sulla scansione dell'indice per verificare che i valori RowID scansionati dalla partizione 2 corrispondano a WHERE predicato della clausola. L'ottimizzatore presuppone che i valori RowID siano distribuiti in modo abbastanza casuale attraverso l'indice non cluster, quindi si aspetta di trovare la prima riga che corrisponde a WHERE predicato della clausola abbastanza rapidamente. Il diagramma di layout dei dati partizionati mostra che i valori RowID sono effettivamente distribuiti in modo abbastanza casuale nell'indice (che è ordinato dalla colonna SomeData ricorda):
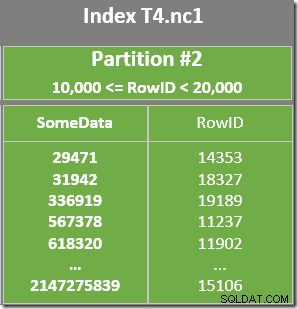
L'operatore Top nel piano di query limita la scansione dell'indice a una singola riga (dall'estremità inferiore o superiore dell'indice a seconda della direzione di scansione). Le scansioni dell'indice possono essere problematiche nei piani di query, ma l'operatore Top lo rende un'opzione efficiente qui:la scansione può produrre solo una riga, quindi si interrompe. La combinazione Top e Scansione indice ordinata esegue effettivamente una ricerca del valore più alto o più basso nell'indice che corrisponde anche a WHERE predicati delle clausole. Nel piano viene visualizzato anche uno Stream Aggregate per garantire che un NULL viene generato nel caso in cui non vengano restituite righe dalla scansione dell'indice. MIN scalare e MAX gli aggregati sono definiti per restituire un NULL quando l'input è un insieme vuoto.
Nel complesso, si tratta di una strategia molto efficiente e i piani hanno un costo stimato di appena 0,0032921 unità di conseguenza. Fin qui tutto bene.
Il problema del valore limite
Il prossimo esempio modifica l'estremità superiore dell'intervallo RowID:
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID < 20000;
Nota che la query esclude il valore 20.000 utilizzando un operatore "minore di". Ricordiamo che il valore 20.000 appartiene alla partizione 3 (non alla partizione 2) perché la funzione di partizione è definita come RANGE RIGHT . SQL Server2005 l'ottimizzatore gestisce correttamente questa situazione, producendo il piano di query a partizione singola ottimale, con un costo stimato di 0,0032878 :
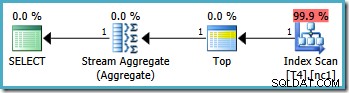
Tuttavia, la stessa query produce un piano diverso su SQL Server 2008 e versioni successive (incluso SQL Server 2014 CTP 1):
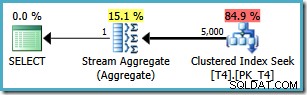
Ora abbiamo un Clustered Index Seek (invece della combinazione desiderata di Index Scan e Top operator). Tutte le 5.000 righe che corrispondono a WHERE clausole vengono elaborate tramite lo Stream Aggregate in questo nuovo piano di esecuzione. Il costo stimato di questo piano è 0,0199319 unità:più di sei volte il costo del piano SQL Server 2005.
Causa
Gli ottimizzatori di SQL Server 2008 (e versioni successive) non ottengono esattamente la logica interna quando un intervallo fa riferimento, ma esclude , un valore limite appartenente a una partizione diversa. L'ottimizzatore pensa erroneamente che si accederà a più partizioni e conclude che non può utilizzare l'ottimizzazione per partizione singola per MIN e MAX aggregati.
Soluzioni alternative
Un'opzione è riscrivere la query utilizzando gli operatori>=e <=in modo da non fare riferimento a un valore limite da un'altra partizione (nemmeno per escluderlo!):
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID <= 19999;
Ciò si traduce nel piano ottimale, toccando una singola partizione:
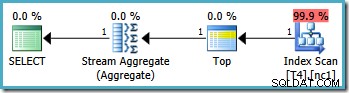
Sfortunatamente, non è sempre possibile specificare valori limite corretti in questo modo (a seconda del tipo di colonna di partizionamento). Un esempio è con i tipi di data e ora in cui è meglio utilizzare intervalli semiaperti. Un'altra obiezione a questa soluzione è più soggettiva:la funzione di partizionamento esclude un limite dall'intervallo, quindi sembra più naturale scrivere la query anche utilizzando la sintassi dell'intervallo semiaperto.
Una seconda soluzione consiste nello specificare il numero di partizione in modo esplicito (e mantenendo l'intervallo semiaperto):
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID < 20000 AND $PARTITION.PF(RowID) = 2;
Questo produce il piano ottimale, a costo di richiedere un predicato aggiuntivo e fare affidamento sull'utente per capire quale dovrebbe essere il numero di partizione.
Ovviamente sarebbe meglio se gli ottimizzatori 2008 e successivi producessero lo stesso piano ottimale di SQL Server 2005. In un mondo perfetto, una soluzione più completa affronterebbe anche il caso multi-partizione, rendendo superflua anche la soluzione alternativa descritta da Itzik.