Siamo stati tutti viziati dalla capacità dei motori di ricerca di "aggirare" cose come errori di ortografia, differenze di ortografia dei nomi o qualsiasi altra situazione in cui il termine di ricerca potrebbe corrispondere su pagine i cui autori potrebbero preferire utilizzare un'ortografia diversa di una parola. L'aggiunta di tali funzionalità alle nostre applicazioni basate su database può arricchire e migliorare in modo simile le nostre applicazioni e, sebbene le offerte di sistemi di gestione di database relazionali commerciali (RDBMS) forniscano soluzioni personalizzate completamente sviluppate a questo problema, i costi di licenza di questi strumenti possono essere al di fuori raggiungere gli sviluppatori più piccoli o le piccole aziende di sviluppo software.
Si potrebbe obiettare che ciò potrebbe essere fatto utilizzando invece un correttore ortografico. Tuttavia, un correttore ortografico in genere non è utile quando si abbina un'ortografia corretta, ma alternativa, di un nome o di un'altra parola. L'abbinamento per suono colma questa lacuna funzionale. Questo è l'argomento del tutorial di programmazione di oggi:come interrogare suoni con Python usando Metaphones.
Cos'è Soundex?
Soundex è stato sviluppato all'inizio del XX secolo come mezzo per il censimento degli Stati Uniti per abbinare i nomi in base a come suonano. È stato quindi utilizzato da varie compagnie telefoniche per abbinare i nomi dei clienti. Continua ad essere utilizzato per la corrispondenza dei dati fonetici fino ad oggi nonostante sia limitato all'ortografia e alle pronunce dell'inglese americano. È anche limitato alle lettere inglesi. La maggior parte degli RDBMS, come SQL Server e Oracle, insieme a MySQL e alle sue varianti, implementa una funzione Soundex e, nonostante i suoi limiti, continua a essere utilizzata per trovare la corrispondenza con molte parole non inglesi.
Cos'è un doppio metafono?
Il Metafono algoritmo è stato sviluppato nel 1990 e supera alcuni dei limiti di Soundex. Nel 2000, un seguito migliorato, Double Metaphone , è stato sviluppato. Double Metaphone restituisce un valore primario e uno secondario che corrispondono a due modi in cui una singola parola potrebbe essere pronunciata. Ad oggi questo algoritmo rimane uno dei migliori algoritmi fonetici open source. Metaphone 3 è stato rilasciato nel 2009 come miglioramento di Double Metaphone, ma si tratta di un prodotto commerciale.
Sfortunatamente, molti dei principali RDBMS menzionati sopra non implementano Double Metaphone e la maggior parte importanti linguaggi di scripting non forniscono un'implementazione supportata di Double Metaphone. Tuttavia, Python fornisce un modulo che implementa Double Metaphone.
Gli esempi presentati in questo tutorial di programmazione Python utilizzano MariaDB versione 10.5.12 e Python 3.9.2, entrambi eseguiti su Kali/Debian Linux.
Come aggiungere un doppio metafono a Python
Come qualsiasi modulo Python, lo strumento pip può essere utilizzato per installare Double Metaphone. La sintassi dipende dalla tua installazione di Python. Una tipica installazione di Double Metaphone è simile al seguente esempio:
# Typical if you have only Python 3 installed $ pip install doublemetaphone # If your system has Python 2 and Python 3 installed $ /usr/bin/pip3 install DoubleMetaphone
Si noti che l'aggiunta di maiuscole è intenzionale. Il codice seguente è un esempio di come utilizzare Double Metaphone in Python:
# demo.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
def main(argv):
testwords = ["There", "Their", "They're", "George", "Sally", "week", "weak", "phil", "fill", "Smith", "Schmidt"]
for testword in testwords:
print (testword + " - ", end="")
print (doublemetaphone(testword))
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 1 - Demo script to verify functionality
Lo script Python sopra fornisce il seguente output quando viene eseguito nell'ambiente di sviluppo integrato (IDE) o nell'editor di codice:
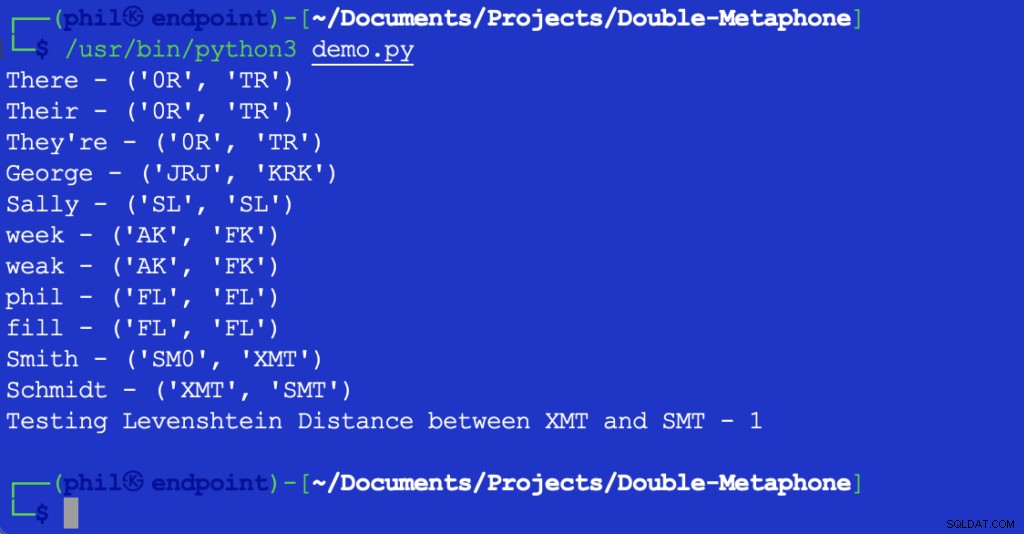
Figura 1 – Output dello script demo
Come si può vedere qui, ogni parola ha un valore fonetico sia primario che secondario. Le parole che corrispondono a valori primari o secondari sono dette corrispondenze fonetiche. Le parole che condividono almeno un valore fonetico, o che condividono la prima coppia di caratteri in qualsiasi valore fonetico, si dicono foneticamente vicine l'una all'altra.
La maggior parte le lettere visualizzate corrispondono alle loro pronunce inglesi. X può corrispondere a KS , SH o C . 0 corrisponde al esimo suono nel il o lì . Le vocali vengono abbinate solo all'inizio di una parola. A causa del numero incalcolabile di differenze negli accenti regionali, non è possibile affermare che le parole possano essere una corrispondenza oggettivamente esatta, anche se hanno gli stessi valori fonetici.
Confronto dei valori fonetici con Python
Esistono numerose risorse online che possono descrivere il funzionamento completo dell'algoritmo Double Metaphone; tuttavia, questo non è necessario per usarlo perché siamo più interessati a confrontare i valori calcolati, più di quanto ci interessa calcolare i valori. Come affermato in precedenza, se c'è almeno un valore in comune tra due parole, si può dire che questi valori sono corrispondenze fonetiche e valori fonetici simili sono foneticamente vicini .
Confrontare i valori assoluti è facile, ma come si può determinare che le stringhe siano simili? Sebbene non vi siano limitazioni tecniche che impediscono di confrontare stringhe di più parole, questi confronti sono generalmente inaffidabili. Limitati a confrontare singole parole.
Quali sono le distanze di Levenshtein?
La Distanza Levenshtein tra due stringhe è il numero di singoli caratteri che devono essere modificati in una stringa per farla corrispondere alla seconda stringa. Una coppia di stringhe che hanno una distanza di Levenshtein inferiore sono più simili tra loro di una coppia di stringhe che hanno una distanza di Levenshtein maggiore. La distanza di Levenshtein è simile a Distanza di Hamming , ma quest'ultimo è limitato a stringhe della stessa lunghezza, poiché i valori fonetici del doppio metafono possono variare in lunghezza, ha più senso confrontarli utilizzando la distanza di Levenshtein.
Libreria a distanza di Python Levenshtein
Python può essere esteso per supportare i calcoli della distanza di Levenshtein tramite un modulo Python:
# If your system has Python 2 and Python 3 installed $ /usr/bin/pip3 install python-Levenshtein
Nota che, come per l'installazione di DoubleMetaphone sopra, la sintassi della chiamata a pip può variare. Il modulo Python-Levenshtein offre molte più funzionalità rispetto ai semplici calcoli della distanza di Levenshtein.
Il codice seguente mostra un test per il calcolo della distanza di Levenshtein in Python:
# demo.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
def main(argv):
testwords = ["There", "Their", "They're", "George", "Sally", "week", "weak", "phil", "fill", "Smith", "Schmidt"]
for testword in testwords:
print (testword + " - ", end="")
print (doublemetaphone(testword))
print ("Testing Levenshtein Distance between XMT and SMT - " + str(distance('XMT', 'SMT')))
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 2 - Demo extended to verify Levenshtein Distance calculation functionality
L'esecuzione di questo script fornisce il seguente output:
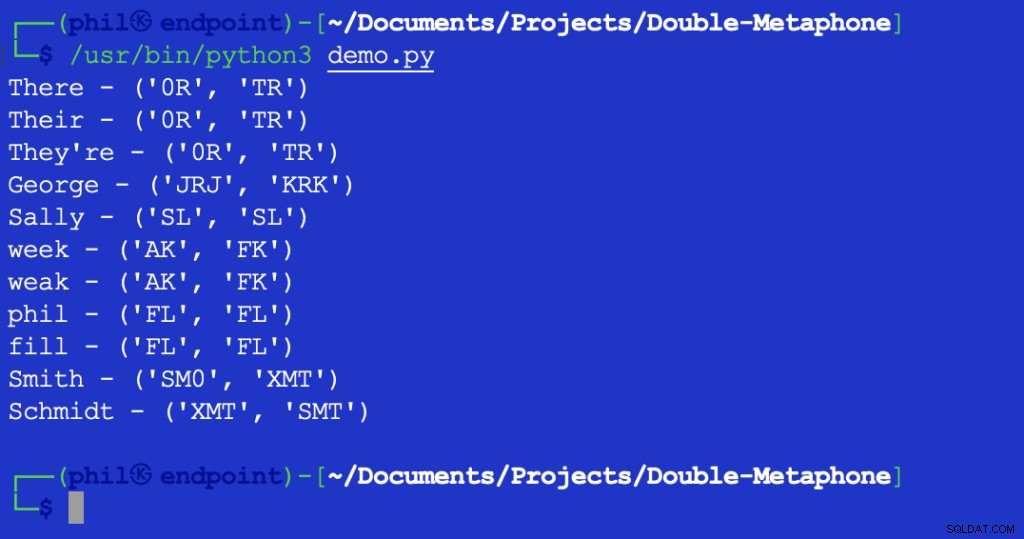
Figura 2 – Output del test della distanza di Levenshtein
Il valore restituito di 1 indica che c'è un carattere tra XMT e SMT quello è diverso. In questo caso, è il primo carattere in entrambe le stringhe.
Confronto di metafoni doppi in Python
Quello che segue non è l'essenziale dei confronti fonetici. È semplicemente uno dei tanti modi per eseguire un simile confronto. Per confrontare efficacemente la vicinanza fonetica di due stringhe date, allora ogni valore fonetico Double Metaphone di una stringa deve essere confrontato con il corrispondente valore fonetico Double Metaphone di un'altra stringa. Poiché a entrambi i valori fonetici di una data stringa viene assegnato lo stesso peso, la media di questi valori di confronto fornirà un'approssimazione ragionevolmente buona della vicinanza fonetica:
PN = [ Dist(DM11, DM21,) + Dist(DM12, DM22,) ] / 2.0
Dove:
- DM1(1) :Primo valore metafonico doppio della stringa 1,
- DM1(2) :Secondo doppio valore metafonico della stringa 1
- DM2(1) :Primo valore metafonico doppio della stringa 2
- DM2(2) :Secondo doppio valore metafonico della stringa 2
- PN :Vicinanza fonetica, con valori più bassi più vicini di valori più alti. Un valore zero indica somiglianza fonetica. Il valore più alto per questo è il numero di lettere nella stringa più corta.
Questa formula si scompone in casi come Schmidt (XMT, SMT) e Smith (SM0, XMT) dove il primo valore fonetico della prima stringa corrisponde al secondo valore fonetico della seconda stringa. In tali situazioni, entrambi Schmidt e Smith può essere considerato foneticamente simile a causa del valore condiviso. Il codice per la funzione di vicinanza dovrebbe applicare la formula sopra solo quando tutti e quattro i valori fonetici sono diversi. La formula presenta anche punti deboli quando si confrontano stringhe di lunghezze diverse.
Nota, non esiste un modo singolarmente efficace per confrontare stringhe di lunghezze diverse, anche se il calcolo della distanza di Levenshtein tra due stringhe tiene conto delle differenze nella lunghezza delle stringhe. Una possibile soluzione sarebbe confrontare entrambe le stringhe fino alla lunghezza della più corta delle due stringhe.
Di seguito è riportato un frammento di codice di esempio che implementa il codice sopra, insieme ad alcuni esempi di test:
# demo2.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
def Nearness(string1, string2):
dm1 = doublemetaphone(string1)
dm2 = doublemetaphone(string2)
nearness = 0.0
if dm1[0] == dm2[0] or dm1[1] == dm2[1] or dm1[0] == dm2[1] or dm1[1] == dm2[0]:
nearness = 0.0
else:
distance1 = distance(dm1[0], dm2[0])
distance2 = distance(dm1[1], dm2[1])
nearness = (distance1 + distance2) / 2.0
return nearness
def main(argv):
testwords = ["Philippe", "Phillip", "Sallie", "Sally", "week", "weak", "phil", "fill", "Smith", "Schmidt", "Harold", "Herald"]
for testword in testwords:
print (testword + " - ", end="")
print (doublemetaphone(testword))
print ("Testing Levenshtein Distance between XMT and SMT - " + str(distance('XMT', 'SMT')))
print ("Distance between AK and AK - " + str(distance('AK', 'AK')) + "]")
print ("Comparing week and weak - [" + str(Nearness("week", "weak")) + "]")
print ("Comparing Harold and Herald - [" + str(Nearness("Harold", "Herald")) + "]")
print ("Comparing Smith and Schmidt - [" + str(Nearness("Smith", "Schmidt")) + "]")
print ("Comparing Philippe and Phillip - [" + str(Nearness("Philippe", "Phillip")) + "]")
print ("Comparing Phil and Phillip - [" + str(Nearness("Phil", "Phillip")) + "]")
print ("Comparing Robert and Joseph - [" + str(Nearness("Robert", "Joseph")) + "]")
print ("Comparing Samuel and Elizabeth - [" + str(Nearness("Samuel", "Elizabeth")) + "]")
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 3 - Implementation of the Nearness Algorithm Above
Il codice Python di esempio fornisce il seguente output:
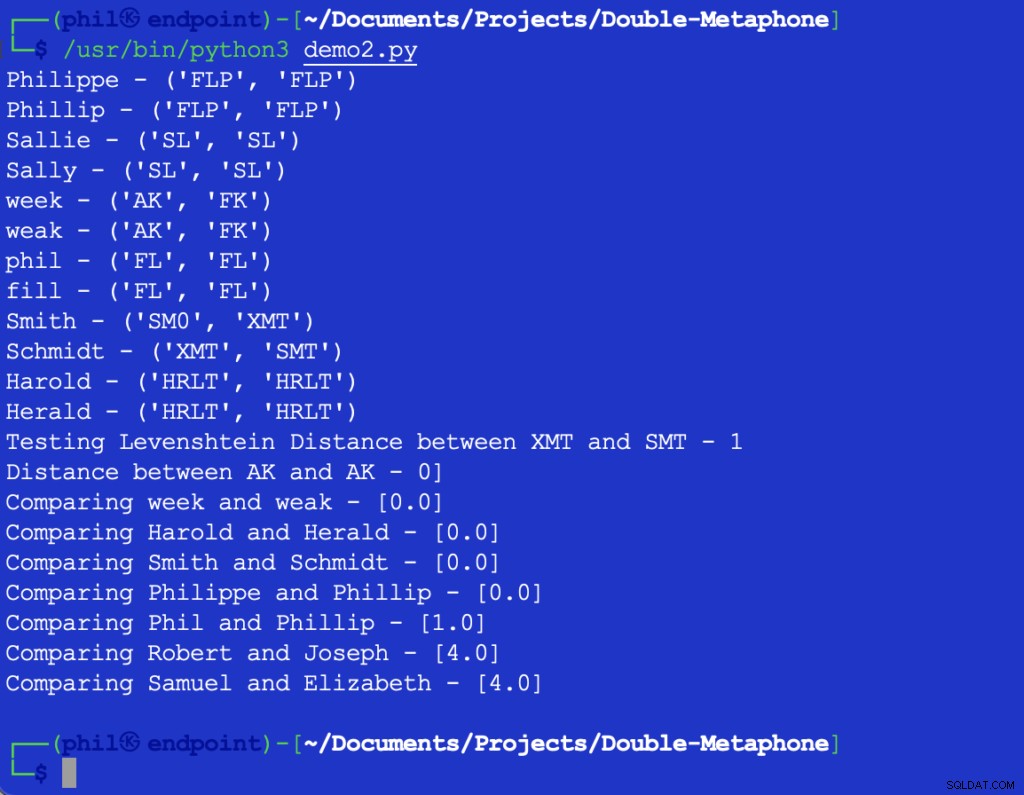
Figura 3 – Output dell'algoritmo di prossimità
Il set di campioni conferma la tendenza generale secondo cui maggiori sono le differenze nelle parole, maggiore è l'output della Vicinanza funzione.
Integrazione del database in Python
Il codice sopra viola il divario funzionale tra un dato RDBMS e un'implementazione Double Metaphone. Inoltre, implementando la Vicinanza funzione in Python, diventa facile da sostituire se si preferisce un algoritmo di confronto diverso.
Considera la seguente tabella MySQL/MariaDB:
create table demo_names (record_id int not null auto_increment, lastname varchar(100) not null default '', firstname varchar(100) not null default '', primary key(record_id)); Listing 4 - MySQL/MariaDB CREATE TABLE statement
Nella maggior parte delle applicazioni basate su database, il middleware compone istruzioni SQL per la gestione dei dati, incluso l'inserimento. Il codice seguente inserirà alcuni nomi di esempio in questa tabella, ma in pratica qualsiasi codice da un'applicazione Web o desktop che raccoglie tali dati potrebbe fare la stessa cosa.
# demo3.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
# /usr/bin/pip3 install mysql.connector
import mysql.connector
def Nearness(string1, string2):
dm1 = doublemetaphone(string1)
dm2 = doublemetaphone(string2)
nearness = 0.0
if dm1[0] == dm2[0] or dm1[1] == dm2[1] or dm1[0] == dm2[1] or dm1[1] == dm2[0]:
nearness = 0.0
else:
distance1 = distance(dm1[0], dm2[0])
distance2 = distance(dm1[1], dm2[1])
nearness = (distance1 + distance2) / 2.0
return nearness
def main(argv):
testNames = ["Smith, Jane", "Williams, Tim", "Adams, Richard", "Franks, Gertrude", "Smythe, Kim", "Daniels, Imogen", "Nguyen, Nancy",
"Lopez, Regina", "Garcia, Roger", "Diaz, Catalina"]
mydb = mysql.connector.connect(
host="localhost",
user="sound_demo_user",
password="password1",
database="sound_query_demo")
for name in testNames:
nameParts = name.split(',')
# Normally one should do bounds checking here.
firstname = nameParts[1].strip()
lastname = nameParts[0].strip()
sql = "insert into demo_names (lastname, firstname) values(%s, %s)"
values = (lastname, firstname)
insertCursor = mydb.cursor()
insertCursor.execute (sql, values)
mydb.commit()
mydb.close()
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 5 - Inserting sample data into a database.
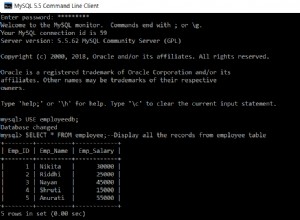
L'esecuzione di questo codice non stampa nulla, ma compila la tabella di test nel database per l'elenco successivo da utilizzare. Interrogando la tabella direttamente nel client MySQL è possibile verificare che il codice sopra abbia funzionato:
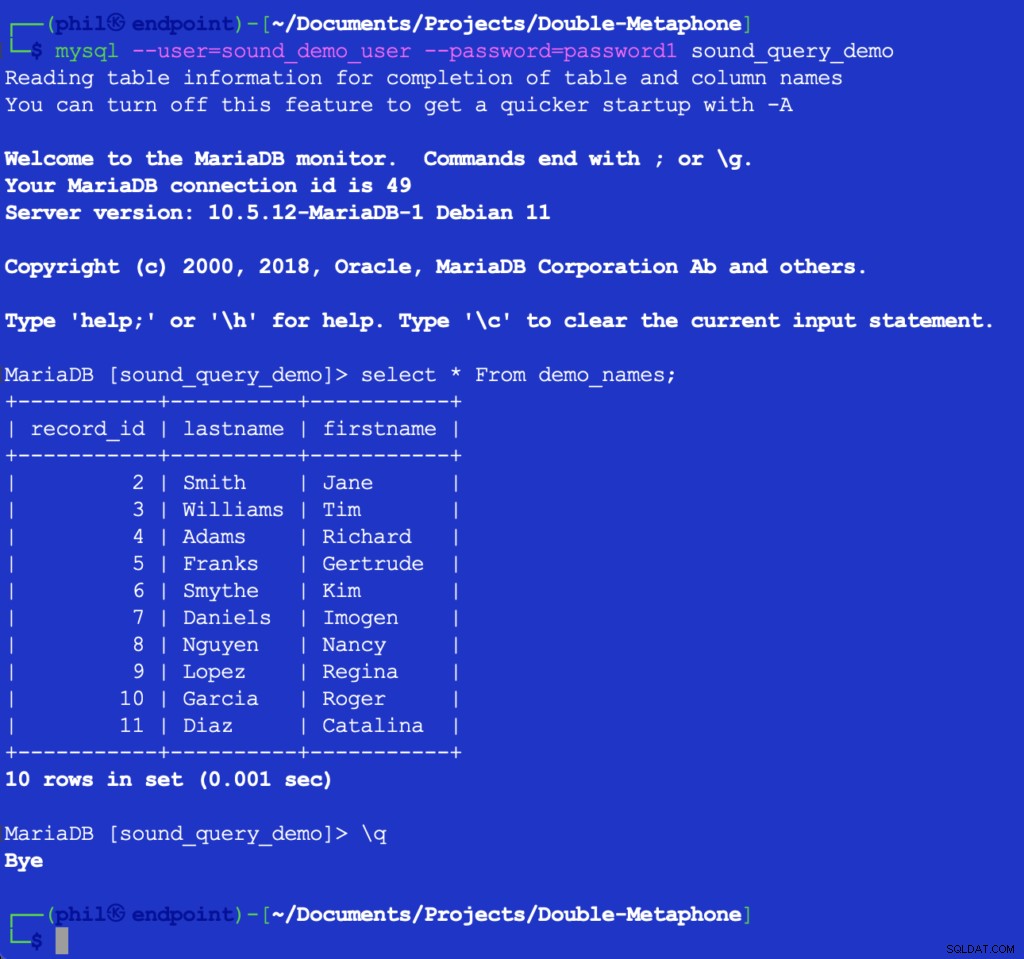
Figura 4- I dati della tabella inseriti
Il codice seguente alimenterà alcuni dati di confronto nei dati della tabella sopra ed eseguirà un confronto di prossimità su di esso:
# demo4.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
# /usr/bin/pip3 install mysql.connector
import mysql.connector
def Nearness(string1, string2):
dm1 = doublemetaphone(string1)
dm2 = doublemetaphone(string2)
nearness = 0.0
if dm1[0] == dm2[0] or dm1[1] == dm2[1] or dm1[0] == dm2[1] or dm1[1] == dm2[0]:
nearness = 0.0
else:
distance1 = distance(dm1[0], dm2[0])
distance2 = distance(dm1[1], dm2[1])
nearness = (distance1 + distance2) / 2.0
return nearness
def main(argv):
comparisonNames = ["Smith, John", "Willard, Tim", "Adamo, Franklin" ]
mydb = mysql.connector.connect(
host="localhost",
user="sound_demo_user",
password="password1",
database="sound_query_demo")
sql = "select lastname, firstname from demo_names order by lastname, firstname"
cursor1 = mydb.cursor()
cursor1.execute (sql)
results1 = cursor1.fetchall()
cursor1.close()
mydb.close()
for comparisonName in comparisonNames:
nameParts = comparisonName.split(",")
firstname = nameParts[1].strip()
lastname = nameParts[0].strip()
print ("Comparison for " + firstname + " " + lastname + ":")
for result in results1:
firstnameNearness = Nearness (firstname, result[1])
lastnameNearness = Nearness (lastname, result[0])
print ("\t[" + firstname + "] vs [" + result[1] + "] - " + str(firstnameNearness)
+ ", [" + lastname + "] vs [" + result[0] + "] - " + str(lastnameNearness))
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 5 - Nearness Comparison Demo
L'esecuzione di questo codice ci porta l'output di seguito:
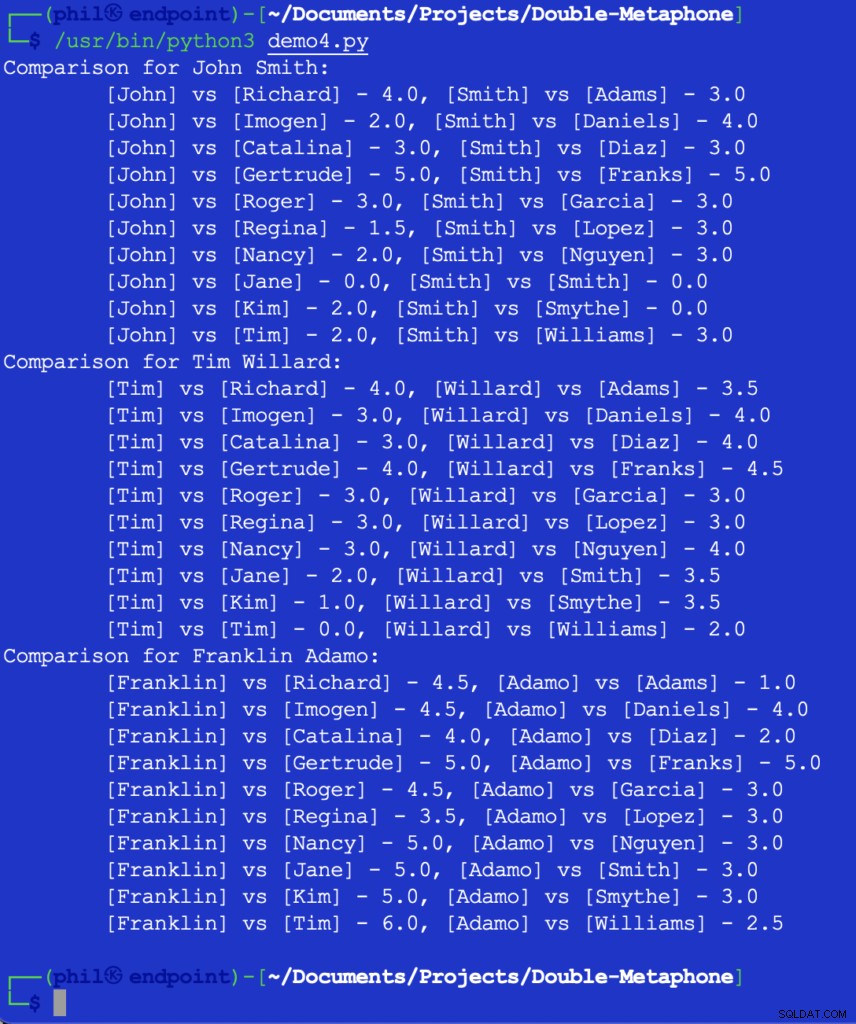
Figura 5 – Risultati del confronto di prossimità
A questo punto, spetterebbe allo sviluppatore decidere quale sarebbe la soglia per ciò che costituisce un utile confronto. Alcuni dei numeri sopra possono sembrare inaspettati o sorprendenti, ma una possibile aggiunta al codice potrebbe essere un SE istruzione per filtrare qualsiasi valore di confronto maggiore di 2 .
Può valere la pena notare che i valori fonetici stessi non sono memorizzati nel database. Questo perché sono calcolati come parte del codice Python e non c'è una reale necessità di archiviarli da nessuna parte in quanto vengono scartati quando il programma esce, tuttavia, uno sviluppatore può trovare valore archiviandoli nel database e quindi implementando il confronto funzione all'interno del database una procedura memorizzata. Tuttavia, l'unico aspetto negativo di questo è la perdita di portabilità del codice.
Considerazioni finali sull'esecuzione di query sui dati tramite suono con Python
Il confronto dei dati in base al suono non sembra ottenere l'"amore" o l'attenzione che può ottenere il confronto di dati tramite l'analisi delle immagini, ma se un'applicazione deve gestire più varianti di parole dal suono simile in più lingue, può essere un attrezzo. Una caratteristica utile di questo tipo di analisi è che uno sviluppatore non deve essere un esperto di linguistica o fonetica per utilizzare questi strumenti. Lo sviluppatore ha anche una grande flessibilità nel definire come confrontare tali dati; i confronti possono essere modificati in base alle esigenze dell'applicazione o della logica aziendale.
Si spera che questo campo di studio riceva maggiore attenzione nella sfera della ricerca e ci saranno strumenti di analisi più capaci e robusti in futuro.