Il ANY aggregate non è qualcosa che possiamo scrivere direttamente in Transact SQL. È una funzionalità solo interna utilizzata da Query Optimizer e dal motore di esecuzione.
Personalmente sono abbastanza affezionato a ANY aggregato, quindi è stato un po' deludente apprendere che è rotto in un modo abbastanza fondamentale. Il particolare sapore di "rotto" a cui mi riferisco qui è la varietà con risultati sbagliati.
In questo post, darò un'occhiata a due luoghi particolari in cui ANY aggregato si presenta comunemente, mostra il problema dei risultati errati e suggerisce soluzioni alternative ove necessario.
Per informazioni su ANY aggregato, vedere il mio post precedente Piani di query non documentati:ANY Aggregate.
1. Una riga per query di gruppo
Questo deve essere uno dei requisiti di query più comuni di tutti i giorni, con una soluzione molto nota. Probabilmente scrivi questo tipo di query ogni giorno, seguendo automaticamente lo schema, senza pensarci davvero.
L'idea è di numerare il set di righe di input utilizzando il ROW_NUMBER funzione finestra, partizionata dalla colonna o dalle colonne di raggruppamento. Questo è racchiuso in un'Espressione di tabella comune o tabella derivata e filtrato fino alle righe in cui il numero di riga calcolato è uguale a uno. Dal ROW_NUMBER riparte da uno per ogni gruppo, questo ci dà la riga richiesta per gruppo.
Non ci sono problemi con questo schema generale. Il tipo di una riga per query di gruppo soggetta a ANY il problema aggregato è quello in cui non ci interessa quale riga particolare è selezionata da ogni gruppo.
In tal caso, non è chiaro quale colonna debba essere utilizzata nel ORDER BY obbligatorio clausola del ROW_NUMBER funzione finestra. Dopotutto, a noi esplicitamente non importa quale riga è selezionata. Un approccio comune consiste nel riutilizzare PARTITION BY colonna/e nel ORDER BY clausola. È qui che potrebbe verificarsi il problema.
Esempio
Diamo un'occhiata a un esempio utilizzando un set di dati giocattolo:
CREATE TABLE #Data
(
c1 integer NULL,
c2 integer NULL,
c3 integer NULL
);
INSERT #Data
(c1, c2, c3)
VALUES
-- Group 1
(1, NULL, 1),
(1, 1, NULL),
(1, 111, 111),
-- Group 2
(2, NULL, 2),
(2, 2, NULL),
(2, 222, 222);
Il requisito è restituire una riga completa di dati da ciascun gruppo, dove l'appartenenza al gruppo è definita dal valore nella colonna c1 .

Dopo il ROW_NUMBER pattern, potremmo scrivere una query come la seguente (notare il ORDER BY clausola del ROW_NUMBER la funzione della finestra corrisponde a PARTITION BY clausola):
WITH
Numbered AS
(
SELECT
D.*,
rn = ROW_NUMBER() OVER (
PARTITION BY D.c1
ORDER BY D.c1)
FROM #Data AS D
)
SELECT
N.c1,
N.c2,
N.c3
FROM Numbered AS N
WHERE
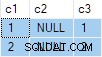
N.rn = 1; Come presentato, questa query viene eseguita correttamente, con risultati corretti. I risultati sono tecnicamente non deterministici poiché SQL Server potrebbe restituire validamente una qualsiasi delle righe in ogni gruppo. Tuttavia, se esegui tu stesso questa query, è molto probabile che vedrai lo stesso risultato che vedo io:
Il piano di esecuzione dipende dalla versione di SQL Server utilizzata e non dal livello di compatibilità del database.
In SQL Server 2014 e versioni precedenti, il piano è:

Per SQL Server 2016 o versioni successive, vedrai:

Entrambi i piani sono sicuri, ma per ragioni diverse. Il ordinamento distinto il piano contiene un ANY aggregato, ma l'Ordinamento distinto l'implementazione dell'operatore non manifesta il bug.
Il piano SQL Server 2016+ più complesso non utilizza ANY aggregare affatto. Ordina mette le righe nell'ordine necessario per l'operazione di numerazione delle righe. Il segmento l'operatore imposta un flag all'inizio di ogni nuovo gruppo. Il progetto sequenza calcola il numero di riga. Infine, il Filtro l'operatore passa solo quelle righe che hanno un numero di riga calcolato pari a uno.
Il bug
Per ottenere risultati errati con questo set di dati, è necessario utilizzare SQL Server 2014 o versioni precedenti e ANY gli aggregati devono essere implementati in un aggregato di flusso o Desideroso Hash Aggregate operatore (Aggregato di corrispondenza hash distinti di flusso non produce il bug).
Un modo per incoraggiare l'ottimizzatore a scegliere un aggregato di flusso invece di Ordinamento distinto consiste nell'aggiungere un indice cluster per fornire l'ordinamento per colonna c1 :
CREATE CLUSTERED INDEX c ON #Data (c1);
Dopo tale modifica, il piano di esecuzione diventa:

Il ANY gli aggregati sono visibili nelle Proprietà finestra quando l'aggregazione flusso è selezionato l'operatore:

Il risultato della query è:
Questo è sbagliato . SQL Server ha restituito righe che non esistono nei dati di origine. Non ci sono righe di origine in cui c2 = 1 e c3 = 1 Per esempio. Ricordiamo che i dati di origine sono:
Il piano di esecuzione calcola erroneamente separato ANY aggregati per il c2 e c3 colonne, ignorando i valori null. Ciascuno aggregato indipendentemente restituisce il primo non null valore che incontra, dando un risultato dove i valori per c2 e c3 provengono da diverse righe di origine . Questo non è ciò che richiedeva la specifica della query SQL originale.
Lo stesso risultato errato può essere prodotto con o senza l'indice cluster aggiungendo un OPTION (HASH GROUP) suggerimento per produrre un piano con un Eager Hash Aggregate invece di un aggregato di flusso .
Condizioni
Questo problema può verificarsi solo quando più ANY sono presenti aggregati e i dati aggregati contengono valori null. Come notato, il problema riguarda solo Stream Aggregate e Deager Hash Aggregate operatori; Ordinamento distinto e Flusso distinto non sono interessati.
SQL Server 2016 in poi fa uno sforzo per evitare di introdurre più ANY aggregati per il modello di query di numerazione delle righe qualsiasi riga per gruppo quando le colonne di origine non supportano valori nulla. Quando ciò accade, il piano di esecuzione conterrà Segmento , Progetto sequenza e Filtro operatori anziché un aggregato. Questa forma del piano è sempre sicura, poiché nessun ANY vengono utilizzati aggregati.
Riproduzione del bug in SQL Server 2016+
L'ottimizzatore di SQL Server non è perfetto per rilevare quando una colonna originariamente vincolata a essere NOT NULL potrebbe ancora produrre un valore intermedio nullo attraverso manipolazioni di dati.
Per riprodurre questo, inizieremo con una tabella in cui tutte le colonne sono dichiarate come NOT NULL :
IF OBJECT_ID(N'tempdb..#Data', N'U') IS NOT NULL
BEGIN
DROP TABLE #Data;
END;
CREATE TABLE #Data
(
c1 integer NOT NULL,
c2 integer NOT NULL,
c3 integer NOT NULL
);
CREATE CLUSTERED INDEX c ON #Data (c1);
INSERT #Data
(c1, c2, c3)
VALUES
-- Group 1
(1, 1, 1),
(1, 2, 2),
(1, 3, 3),
-- Group 2
(2, 1, 1),
(2, 2, 2),
(2, 3, 3);
Possiamo produrre valori nulli da questo set di dati in molti modi, la maggior parte dei quali l'ottimizzatore può rilevare con successo, evitando così di introdurre ANY aggregati durante l'ottimizzazione.
Di seguito è mostrato un modo per aggiungere valori nulli che sfuggono al radar:
SELECT
D.c1,
OA1.c2,
OA2.c3
FROM #Data AS D
OUTER APPLY (SELECT D.c2 WHERE D.c2 <> 1) AS OA1
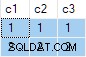
OUTER APPLY (SELECT D.c3 WHERE D.c3 <> 2) AS OA2; Tale query produce il seguente output:
Il passaggio successivo consiste nell'utilizzare la specifica della query come dati di origine per la query standard "qualsiasi riga per gruppo":
WITH
SneakyNulls AS
(
-- Introduce nulls the optimizer can't see
SELECT
D.c1,
OA1.c2,
OA2.c3
FROM #Data AS D
OUTER APPLY (SELECT D.c2 WHERE D.c2 <> 1) AS OA1
OUTER APPLY (SELECT D.c3 WHERE D.c3 <> 2) AS OA2
),
Numbered AS
(
SELECT
D.c1,
D.c2,
D.c3,
rn = ROW_NUMBER() OVER (
PARTITION BY D.c1
ORDER BY D.c1)
FROM SneakyNulls AS D
)
SELECT
N.c1,
N.c2,
N.c3
FROM Numbered AS N
WHERE
N.rn = 1; Su qualsiasi versione di SQL Server, che produce il seguente piano:
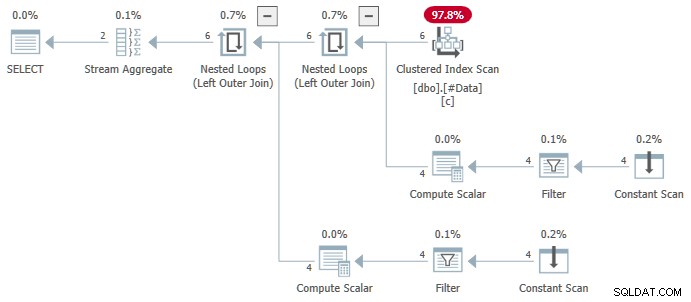
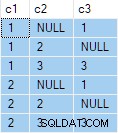
L'aggregato di flusso contiene più ANY aggregati e il risultato è errato . Nessuna delle righe restituite viene visualizzata nel set di dati di origine:
db<>dimostrazione online di violino
Soluzione alternativa
L'unica soluzione completamente affidabile fino a quando questo bug non viene risolto è evitare lo schema in cui il ROW_NUMBER ha la stessa colonna in ORDER BY clausola come è nel PARTITION BY clausola.
Quando non ci interessa quale viene selezionata una riga da ogni gruppo, è un peccato che un ORDER BY la clausola è assolutamente necessaria. Un modo per aggirare il problema è utilizzare una costante di runtime come ORDER BY @@SPID nella funzione finestra.
2. Aggiornamento non deterministico
Il problema con più ANY aggregati su input nullable non è limitato al modello di query di una riga per gruppo. Query Optimizer può introdurre un ANY interno aggregare in una serie di circostanze. Uno di questi casi è un aggiornamento non deterministico.
Un non deterministico update è dove l'istruzione non garantisce che ogni riga di destinazione verrà aggiornata al massimo una volta. In altre parole, esistono più righe di origine per almeno una riga di destinazione. La documentazione avverte esplicitamente di questo:
Fai attenzione quando specifichi la clausola FROM per fornire i criteri per l'operazione di aggiornamento.I risultati di un'istruzione UPDATE non sono definiti se l'istruzione include una clausola FROM che non è specificata in modo tale che sia disponibile un solo valore per ogni occorrenza di colonna che viene aggiornata, che è se l'istruzione UPDATE non è deterministica.
Per gestire un aggiornamento non deterministico, l'ottimizzatore raggruppa le righe in base a una chiave (indice o RID) e applica ANY aggregati alle colonne rimanenti. L'idea di base è scegliere una riga tra più candidati e utilizzare i valori di quella riga per eseguire l'aggiornamento. Ci sono evidenti parallelismi con il precedente ROW_NUMBER problema, quindi non sorprende che sia abbastanza facile dimostrare un aggiornamento errato.
A differenza del problema precedente, attualmente SQL Server non esegue nessuna procedura speciale per evitare più ANY aggregati su colonne nullable durante l'esecuzione di un aggiornamento non deterministico. Di conseguenza, quanto segue si riferisce a tutte le versioni di SQL Server , incluso SQL Server 2019 CTP 3.0.
Esempio
DECLARE @Target table
(
c1 integer PRIMARY KEY,
c2 integer NOT NULL,
c3 integer NOT NULL
);
DECLARE @Source table
(
c1 integer NULL,
c2 integer NULL,
c3 integer NULL,
INDEX c CLUSTERED (c1)
);
INSERT @Target
(c1, c2, c3)
VALUES
(1, 0, 0);
INSERT @Source
(c1, c2, c3)
VALUES
(1, 2, NULL),
(1, NULL, 3);
UPDATE T
SET T.c2 = S.c2,
T.c3 = S.c3
FROM @Target AS T
JOIN @Source AS S
ON S.c1 = T.c1;
SELECT * FROM @Target AS T; db<>dimostrazione online di violino
Logicamente, questo aggiornamento dovrebbe sempre produrre un errore:la tabella di destinazione non consente valori null in nessuna colonna. Qualunque riga corrispondente sia stata scelta dalla tabella di origine, un tentativo di aggiornare la colonna c2 o c3 a null deve verificarsi.
Sfortunatamente, l'aggiornamento ha esito positivo e lo stato finale della tabella di destinazione non è coerente con i dati forniti:
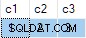
Ho segnalato questo come un bug. La soluzione è evitare di scrivere UPDATE non deterministico dichiarazioni, quindi ANY gli aggregati non sono necessari per risolvere l'ambiguità.
Come accennato, SQL Server può introdurre ANY aggrega in più circostanze rispetto ai due esempi qui riportati. Se ciò si verifica quando la colonna aggregata contiene valori null, è possibile che vengano generati risultati errati.