Ho brevemente accennato al fatto che i dati in modalità batch sono normalizzati nel mio ultimo articolo Bitmap in modalità batch in SQL Server. Tutti i dati in un batch sono rappresentati da un valore di otto byte in questo particolare formato normalizzato, indipendentemente dal tipo di dati sottostante.
Questa affermazione solleva senza dubbio alcune domande, non ultimo su come i dati con una lunghezza molto maggiore di otto byte possano essere archiviati in quel modo. Questo articolo esplora la rappresentazione normalizzata dei dati batch, spiega perché non tutti i tipi di dati a otto byte possono rientrare entro 64 bit e mostra un esempio di come tutto ciò influisca sulle prestazioni in modalità batch.
Demo
Inizierò con un esempio che mostra il formato dei dati batch che fa una differenza importante per un piano di esecuzione. Avrai bisogno di SQL Server 2016 (o successivo) e Developer Edition (o equivalente) per riprodurre i risultati mostrati qui.
La prima cosa di cui avremo bisogno è una tabella di bigint numeri da 1 a 102.400 compresi. Questi numeri verranno utilizzati per popolare una tabella columnstore a breve (il numero di righe è il minimo necessario per ottenere un singolo segmento compresso).
DROP TABLE IF EXISTS #Numbers;
GO
CREATE TABLE #Numbers (n bigint NOT NULL PRIMARY KEY);
GO
INSERT #Numbers (n)
SELECT
n = ROW_NUMBER() OVER (ORDER BY @@SPID)
FROM master.dbo.spt_values AS SV1
CROSS JOIN master.dbo.spt_values AS SV2
ORDER BY
n
OFFSET 0 ROWS
FETCH FIRST 102400 ROWS ONLY
OPTION (MAXDOP 1); Pushdown aggregato riuscito
Lo script seguente utilizza la tabella dei numeri per creare un'altra tabella contenente gli stessi numeri sfalsati di un valore specifico. Questa tabella utilizza columnstore per l'archiviazione principale per produrre l'esecuzione in modalità batch in un secondo momento.
DROP TABLE IF EXISTS #T;
GO
CREATE TABLE #T (c1 bigint NOT NULL);
GO
DECLARE
@Start bigint = CONVERT(bigint, -4611686018427387905);
INSERT #T (c1)
SELECT
c1 = @Start + N.n
FROM #Numbers AS N;
GO
CREATE CLUSTERED COLUMNSTORE INDEX c ON #T
WITH (MAXDOP = 1); Esegui le seguenti query di test sulla nuova tabella columnstore:
SELECT
c = COUNT_BIG(*)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
m = MAX(T.c1)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
s = SUM(T.c1 + CONVERT(bigint, 4611686018427387904))
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
L'aggiunta all'interno del SUM è evitare il traboccamento. Puoi saltare il WHERE clausole (per evitare un piano banale) se si esegue SQL Server 2017.
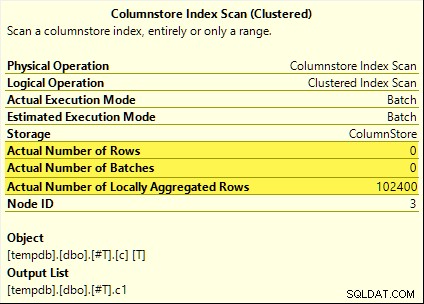
Tutte queste query traggono vantaggio dal pushdown aggregato. L'aggregato viene calcolato in Columnstore Index Scan invece della modalità batch Hash Aggregate operatore. I piani post-esecuzione mostrano zero righe emesse dalla scansione. Tutte le 102.400 righe sono state "aggregate localmente".
La SUM piano è mostrato di seguito come esempio:

Pushdown aggregato non riuscito
Ora rilascia e ricrea la tabella di test columnstore con l'offset diminuito di uno:
DROP TABLE IF EXISTS #T;
GO
CREATE TABLE #T (c1 bigint NOT NULL);
GO
DECLARE
-- Note this value has decreased by one
@Start bigint = CONVERT(bigint, -4611686018427387906);
INSERT #T (c1)
SELECT
c1 = @Start + N.n
FROM #Numbers AS N;
GO
CREATE CLUSTERED COLUMNSTORE INDEX c ON #T
WITH (MAXDOP = 1); Esegui esattamente le stesse query di test pushdown aggregate di prima:
SELECT
c = COUNT_BIG(*)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
m = MAX(T.c1)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
s = SUM(T.c1 + CONVERT(bigint, 4611686018427387904))
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
Questa volta, solo il COUNT_BIG aggregate ottiene il pushdown aggregato (solo SQL Server 2017). Il MAX e SUM gli aggregati no. Ecco il nuovo SUM piano di confronto con quello della prima prova:

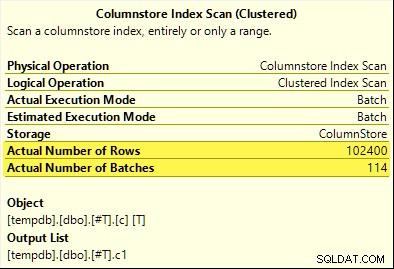
Tutte le 102.400 righe (in 114 batch) vengono emesse dalla Scansione dell'indice del Columnstore , elaborato da Compute Scalar e inviato all'Hash Aggregate .
Perché la differenza? Tutto ciò che abbiamo fatto è stato compensare di uno l'intervallo di numeri archiviati nella tabella columnstore!
Spiegazione
Ho menzionato nell'introduzione che non tutti i tipi di dati a otto byte possono adattarsi a 64 bit. Questo fatto è importante poiché molte ottimizzazioni delle prestazioni in modalità columnstore e batch funzionano solo con dati di dimensioni pari a 64 bit. Il pushdown aggregato è una di quelle cose. Ci sono molte altre caratteristiche prestazionali (non tutte documentate) che funzionano meglio (o per niente) solo quando i dati si adattano a 64 bit.
Nel nostro esempio specifico, il pushdown aggregato è disabilitato per un segmento columnstore quando ne contiene anche uno valore di dati che non rientra in 64 bit. SQL Server può determinarlo dai metadati del valore minimo e massimo associati a ciascun segmento senza controllare tutti i dati. Ogni segmento viene valutato separatamente.
Il pushdown aggregato funziona ancora per COUNT_BIG aggregare solo nella seconda prova. Questa è un'ottimizzazione aggiunta ad un certo punto in SQL Server 2017 (i miei test sono stati eseguiti su CU16). È logico non disabilitare il pushdown aggregato quando contiamo solo le righe e non facciamo nulla con i valori dei dati specifici. Non sono riuscito a trovare alcuna documentazione per questo miglioramento, ma non è così insolito di questi tempi.
Come nota a margine, ho notato che SQL Server 2017 CU16 abilita il pushdown aggregato per i tipi di dati precedentemente non supportati real , float , datetimeoffset e numeric con precisione maggiore di 18 — quando i dati rientrano in 64 bit. Anche questo non è documentato al momento della scrittura.
Ok, ma perché?
Potresti porre la domanda molto ragionevole:perché un insieme di bigint i valori di test apparentemente si adattano a 64 bit ma l'altro no?
Se hai indovinato il motivo era correlato a NULL , datti un segno di spunta. Anche se la colonna della tabella di test è definita come NOT NULL , SQL Server utilizza lo stesso layout di dati normalizzato per bigint se i dati consentono null o meno. Ci sono ragioni per questo, che scompatterò poco a poco.
Comincio con alcune osservazioni:
- Ogni valore di colonna in un batch viene archiviato esattamente in otto byte (64 bit) indipendentemente dal tipo di dati sottostante. Questo layout a dimensione fissa rende tutto più semplice e veloce. L'esecuzione in modalità batch è tutta una questione di velocità.
- Un batch ha una dimensione di 64 KB e contiene tra 64 e 900 righe, a seconda del numero di colonne proiettate. Ciò ha senso dato che le dimensioni dei dati delle colonne sono fissate a 64 bit. Più colonne significa che possono essere contenute meno righe in ogni batch da 64 KB.
- Non tutti i tipi di dati di SQL Server possono adattarsi a 64 bit, anche in linea di principio. Una lunga stringa (per fare un esempio) potrebbe non rientrare nemmeno in un intero batch da 64 KB (se consentito), per non parlare di una singola voce a 64 bit.
SQL Server risolve quest'ultimo problema archiviando un riferimento a 8 byte a dati superiori a 64 bit. Il valore dei dati "grande" viene archiviato altrove in memoria. Potresti chiamare questa disposizione di archiviazione "fuori riga" o "fuori batch". Internamente si parla di dati profondi .
Ora, i tipi di dati a otto byte non possono rientrare in 64 bit quando annullabili. Prendi bigint NULL Per esempio . L'intervallo di dati non nullo potrebbe richiedere tutti i 64 bit e abbiamo ancora bisogno di un altro bit per indicare null o meno.
Risolvere i problemi
La soluzione creativa ed efficiente a queste sfide è riservare il bit significativo più basso (LSB) del valore a 64 bit come flag. Il flag indica in batch memorizzazione dei dati quando l'LSB è clear (impostato a zero). Quando l'LSB è impostato (a uno), può significare una di queste due cose:
- Il valore è nullo; o
- Il valore viene memorizzato fuori batch (si tratta di dati profondi).
Questi due casi si distinguono per lo stato dei restanti 63 bit. Quando sono tutti zero , il valore è NULL . In caso contrario, il "valore" è un puntatore a dati profondi archiviati altrove.
Se visto come un numero intero, l'impostazione di LSB significa che i puntatori a dati profondi saranno sempre dispari numeri. I valori nulli sono rappresentati dal numero (dispari) 1 (tutti gli altri bit sono zero). I dati in batch sono rappresentati da pari numeri perché LSB è zero.
Questo non significa che SQL Server può memorizzare solo numeri pari all'interno di un batch! Significa solo che la rappresentazione normalizzata dei valori della colonna sottostante avrà sempre un LSB zero quando archiviato "in batch". Questo avrà più senso tra un momento.
Normalizzazione dei dati in batch
La normalizzazione viene eseguita in modi diversi, a seconda del tipo di dati sottostante. Per bigint il processo è:
- Se i dati sono nulli , memorizzare il valore 1 (solo LSB impostato).
- Se il valore può essere rappresentato in 63 bit , sposta tutti i bit di una posizione a sinistra e azzera l'LSB. Quando si considera il valore come intero, ciò significa raddoppio il valore. Ad esempio il
bigintil valore 1 è normalizzato al valore 2. In binario, cioè sette byte tutti zero seguiti da00000010. Il valore LSB zero indica che si tratta di dati archiviati in linea. Quando SQL Server ha bisogno del valore originale, sposta a destra il valore a 64 bit di una posizione (eliminando il flag LSB). - Se il valore non può essere rappresentato in 63 bit, il valore viene memorizzato fuori batch come dati profondi . Il puntatore in batch ha l'LSB impostato (che lo rende un numero dispari).
Il processo di test se un bigint il valore può rientrare in 63 bit è:
- Memorizza il grezzo*
bigintvalore nel registro del processore a 64 bitr8. - Memorizza il doppio del valore di
r8nel registrorax. - Sposta i bit di
raxun posto a destra. - Verifica se i valori in
raxer8sono uguali.
* Si noti che il valore grezzo non può essere determinato in modo affidabile per tutti i tipi di dati mediante una conversione T-SQL in un tipo binario. Il risultato T-SQL può avere un ordine di byte diverso e può contenere anche metadati, ad es. time precisione frazionaria di secondo.
Se il test al passaggio 4 ha esito positivo, sappiamo che il valore può essere raddoppiato e quindi dimezzato entro 64 bit, preservando il valore originale.
Una portata ridotta
Il risultato di tutto questo è che l'intervallo di bigint i valori che possono essere archiviati in batch sono ridotti di un bit (perché LSB non è disponibile). I seguenti intervalli inclusi di bigint i valori verranno archiviati fuori batch come dati approfonditi :
- -4.611.686.018.427.387.905 a -9.223.372.036.854.775.808
- +4.611.686.018.427.387.904 a +9.223.372.036.854.775.807
In cambio dell'accettazione che questi bigint limiti di intervallo, la normalizzazione consente a SQL Server di archiviare (la maggior parte) bigint valori, valori nulli e riferimenti a dati approfonditi in batch . Questo è molto più semplice ed efficiente in termini di spazio rispetto all'avere strutture separate per l'annullamento dei valori e riferimenti ai dati profondi. Inoltre, semplifica notevolmente l'elaborazione dei dati batch con le istruzioni del processore SIMD.
Normalizzazione di altri tipi di dati
SQL Server contiene la normalizzazione codice per ciascuno dei tipi di dati supportati dall'esecuzione in modalità batch. Ogni routine è ottimizzata per gestire in modo efficiente il layout binario in entrata e per creare dati approfonditi solo quando necessario. La normalizzazione comporta sempre che l'LSB venga riservato per indicare null o dati profondi, ma il layout dei restanti 63 bit varia in base al tipo di dati.
Sempre in batch
I dati normalizzati per i seguenti tipi di dati sono sempre archiviati in batch poiché non hanno mai bisogno di più di 63 bit:
datetime(n)– ridimensionato internamente atime(7)datetime2(n)– ridimensionato internamente adatetime2(7)integersmallinttinyintbit– usa iltinyintattuazione.smalldatetimedatetimerealfloatsmallmoney
Dipende
I seguenti tipi di dati possono essere archiviati in batch o deep data a seconda del valore dei dati:
bigint– come descritto in precedenza.money– stesso intervallo in batch dibigintma diviso per 10.000.numeric/decimal– 18 cifre decimali o meno in batch indipendentemente di precisione dichiarata. Ad esempio ildecimal(38,9)il valore -999999999.999999999 può essere rappresentato come numero intero a 8 byte -9999999999999999999 (f21f494c589c0001esadecimale), che può essere raddoppiato in -19999999999999999998 (e43e9298b1380002hex) in modo reversibile entro 64 bit. SQL Server sa dove va il punto decimale dalla scala del tipo di dati.datetimeoffset(n)– in batch se il valore di runtime rientrerà indatetimeoffset(2)indipendentemente della precisione dichiarata dei secondi frazionari.timestamp– il formato interno è diverso dal display. Ad esempio untimestampvisualizzato da T-SQL come0x000000000099449Aè rappresentato internamente come9a449900 00000000(in esadecimale). Questo valore viene archiviato come dati approfonditi perché non si adatta a 64 bit quando viene raddoppiato (spostato a sinistra di un bit).
Dati sempre approfonditi
I seguenti sono sempre archiviati come dati profondi (tranne i null) :
uniqueidentifiervarbinary(n)– incluso(max)binarychar/varchar(n)/nchar/nvarchar(n)/sysnameincluso(max)– questi tipi possono anche utilizzare un dizionario (se disponibile).text/ntext/image/xml– usa ilvarbinary(n)attuazione.
Per essere chiari, nulli per tutti i tipi di dati compatibili con la modalità batch vengono archiviati in batch come valore speciale "uno".
Pensieri finali
Ci si può aspettare di sfruttare al meglio le ottimizzazioni in modalità batch e columnstore disponibili quando si utilizzano tipi di dati e valori che si adattano a 64 bit. Avrai anche maggiori possibilità di beneficiare di miglioramenti incrementali del prodotto nel tempo, ad esempio gli ultimi miglioramenti al pushdown aggregato indicati nel testo principale. Non tutti i vantaggi in termini di prestazioni saranno così visibili nei piani di esecuzione, o addirittura documentati. Tuttavia, le differenze possono essere estremamente significative.
Dovrei anche menzionare che i dati vengono normalizzati quando un operatore del piano di esecuzione in modalità riga fornisce dati a un genitore in modalità batch o quando una scansione non columnstore produce batch (modalità batch su rowstore). È presente un adattatore da riga a batch invisibile che chiama la routine di normalizzazione appropriata su ogni valore di colonna prima di aggiungerlo al batch. Anche evitare tipi di dati con complicata normalizzazione e archiviazione profonda dei dati può produrre vantaggi in termini di prestazioni.