Al giorno d'oggi è abbastanza comune avere un database replicato in un altro server/data center, ed è anche un must in alcuni casi. Esistono diversi motivi per replicare i database in un ambiente completamente separato.
- Migra a un altro datacenter.
- Requisiti di aggiornamento (hardware/software).
- Mantieni un sistema operativo completamente sincronizzato in un sito di Disaster Recovery (DR) che può subentrare in qualsiasi momento
- Mantieni un database slave come parte di un piano di ripristino di emergenza a basso costo.
- Per i requisiti di geolocalizzazione (i dati devono essere localmente in un paese specifico).
- Disporre di un ambiente di test.
- Scopo di risoluzione dei problemi.
- Database di reporting.
E ci sono diversi modi per eseguire questa attività di replica:
- Backup/ripristino :il backup di un database di produzione e il ripristino in un nuovo server/ambiente è il modo classico per farlo, ma è anche un modo vecchio stile poiché non manterrai i tuoi dati aggiornati e dovrai aspettare per ogni processo di ripristino se hai bisogno di alcuni dati recenti. Se disponi di un cluster (master-slave, multi-master) e desideri ricrearlo, devi ripristinare il backup iniziale e quindi ricreare il resto dei nodi, operazione che potrebbe richiedere molto tempo.
- Clona Cluster :È simile al precedente, ma il processo di backup e ripristino riguarda l'intero cluster, non solo un server di database specifico. In questo modo, puoi clonare l'intero cluster nella stessa attività e non è necessario ricreare manualmente il resto dei nodi. Questo metodo ha ancora il problema di mantenere i dati aggiornati tra i cloni.
- Replica :In questo modo include l'opzione di backup/ripristino, ma dopo il ripristino iniziale, il processo di replica manterrà i tuoi dati sincronizzati con il nodo master. In questo modo, se hai un cluster di database, devi ripristinare il backup su un nodo e ricreare tutti i nodi manualmente.
In questo blog vedremo una nuova funzionalità ClusterControl 1.7.4 che consente di utilizzare un mix del metodo menzionato in precedenza per migliorare questa attività.
Che cos'è la replica da cluster a cluster?
La replica tra due cluster non è la stessa cosa dell'estensione di un cluster per l'esecuzione su due datacenter. Quando impostiamo la replica tra due cluster, abbiamo in realtà 2 sistemi separati che possono operare in modo autonomo. La replica viene utilizzata per mantenerli sincronizzati, in modo che il sistema slave abbia uno stato aggiornato e possa subentrare.
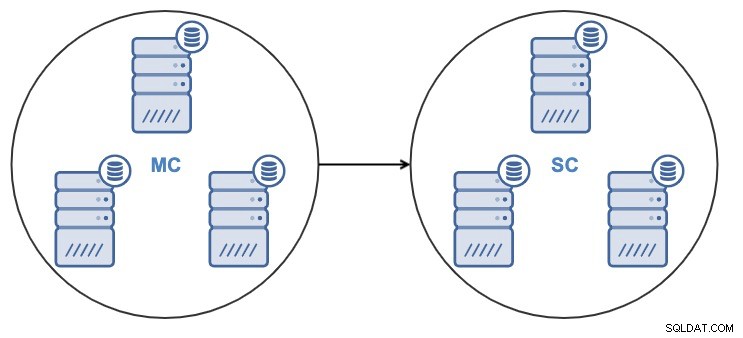
Da ClusterControl 1.7.4 è possibile creare un nuovo cluster clonando direttamente un cluster di origine in esecuzione o utilizzando un backup recente del cluster di origine.
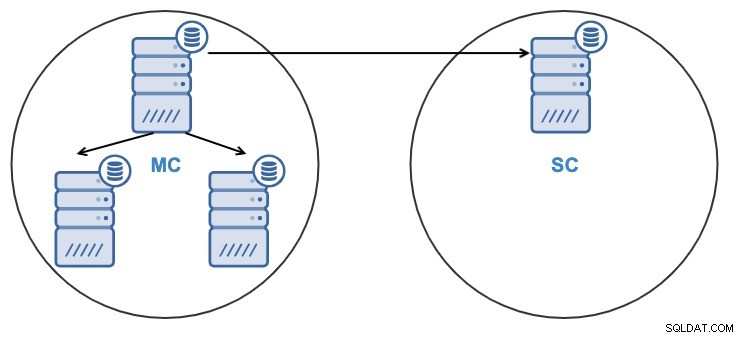
Dopo aver clonato il cluster, avrai uno Slave Cluster (SC) che riceve i dati e un Master Cluster (MC) che invierà le modifiche a quello slave.
ClusterControl supporta la replica da cluster a cluster per i seguenti tipi di cluster:
- Percona XtraDB Cluster versione 5.6.xe successive.
- MariaDB Galera Cluster versione 10.xe successive.
- PostgreSQL 9.6 e versioni successive.
Replica da cluster a cluster per Percona XtraDB / MariaDB Galera Cluster
Per i motori basati su MySQL, è necessario GTID per utilizzare questa funzione e verrà utilizzata la replica asincrona tra il cluster Master e Slave.
Ci sono un paio di azioni da eseguire per preparare il cluster corrente per questo lavoro. Innanzitutto, almeno un nodo nel cluster corrente deve avere i log binari abilitati. Quindi, è necessario aggiungere l'utente di backup configurato nel nodo del database nel file di configurazione di ClusterControl, che verrà utilizzato per le attività di gestione. Tutte queste azioni possono essere eseguite utilizzando l'interfaccia utente ClusterControl o ClusterControl CLI.
Ora sei pronto per creare la replica Percona XtraDB/MariaDB Galera Cluster-to-Cluster. Al termine del lavoro, avrai:
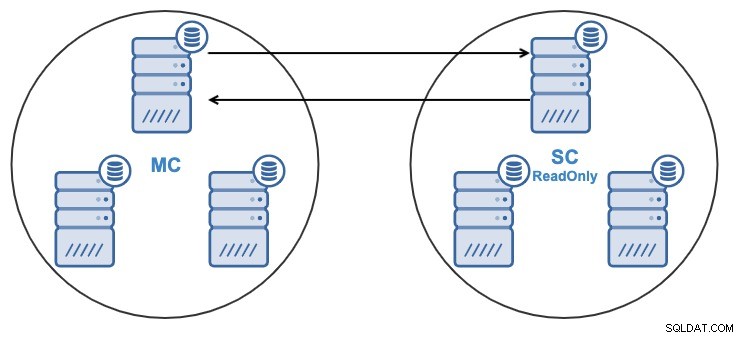
- Un nodo nel cluster slave verrà replicato da un nodo nel cluster master.
- La replica sarà bidirezionale tra i cluster.
- Tutti i nodi nel cluster slave saranno di sola lettura per impostazione predefinita. È possibile disabilitare uno per uno il flag di sola lettura sui nodi.
- Il clustering attivo-attivo è consigliato solo se le applicazioni toccano solo set di dati disgiunti su uno dei cluster poiché il motore non offre alcun rilevamento o risoluzione dei conflitti.
Da ClusterControl UI o ClusterControl CLI, sarai in grado di:
- Crea questo cluster di replica.
- Abilita la configurazione Attivo-Attivo.
- Cambia la topologia del cluster.
- Ricrea un cluster di replica.
- Arresta/avvia uno slave di replica.
- Reimposta lo slave di replica (implementato solo utilizzando ClusterControl CLI atm).
Considerazioni
- L'utente di backup deve essere aggiunto manualmente nel file di configurazione di ClusterControl.
- Le credenziali dell'utente di backup devono essere le stesse sia nel cluster corrente che in quello nuovo.
- La password di root MySQL specificata durante la creazione dello Slave Cluster deve essere la stessa della password di root utilizzata sul Master Cluster.
Limiti noti
- Il failover automatico non è ancora supportato. Se il master fallisce, è responsabilità dell'amministratore eseguire il failover su un altro master.
- È possibile solo "RESET" uno slave di replica dalla CLI ClusterControl poiché non è ancora implementato nell'interfaccia utente di ClusterControl.
- È possibile ricostruire solo un cluster in modalità di sola lettura. Tutti i nodi in un cluster devono essere di sola lettura per essere considerati cluster di sola lettura.
Replica da cluster a cluster per PostgreSQL
La replica da cluster a cluster di ClusterControl è supportata su PostgreSQL utilizzando la replica in streaming.
Come requisito, deve essere presente un server PostgreSQL con il ruolo ClusterControl 'master' e quando si configura il Cluster Slave, le credenziali di Admin devono essere identiche al Cluster Master.
Ora sei pronto per creare la replica PostgreSQL Cluster-to-Cluster. Al termine del lavoro, avrai:
- Un nodo nel cluster slave verrà replicato da un nodo nel cluster master.
- La replica sarà unidirezionale tra i cluster.
- Il nodo nel cluster slave sarà di sola lettura.
Da ClusterControl UI o ClusterControl CLI, sarai in grado di:
- Crea questo cluster di replica.
- Ricrea un cluster di replica.
- Arresta/avvia uno slave di replica.
Considerazione
- Le credenziali di amministratore devono essere identiche nel cluster master e slave.
Limiti noti
- La dimensione massima dello Slave Cluster è un nodo.
- Non è possibile eseguire lo stage del cluster slave da un backup.
- Le modifiche alla topologia non sono supportate.
- È supportata solo la replica unidirezionale.
Conclusione
Utilizzando questa nuova funzionalità ClusterControl, non è necessario eseguire ogni passaggio per creare una replica del cluster separatamente o manualmente e, di conseguenza, risparmierai tempo e fatica. Provalo!